sklearn_线性回归
1. 普通线性回归 Linear Regression

(1)目标:
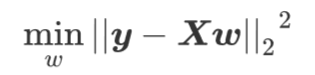

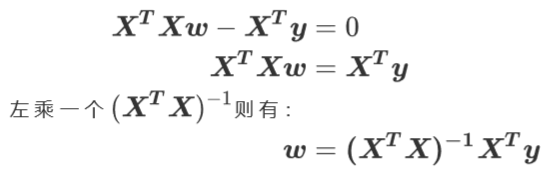
class sklearn.linear_model.LinearRegression (fit_intercept=True, normalize=False, copy_X=True, n_jobs=None)
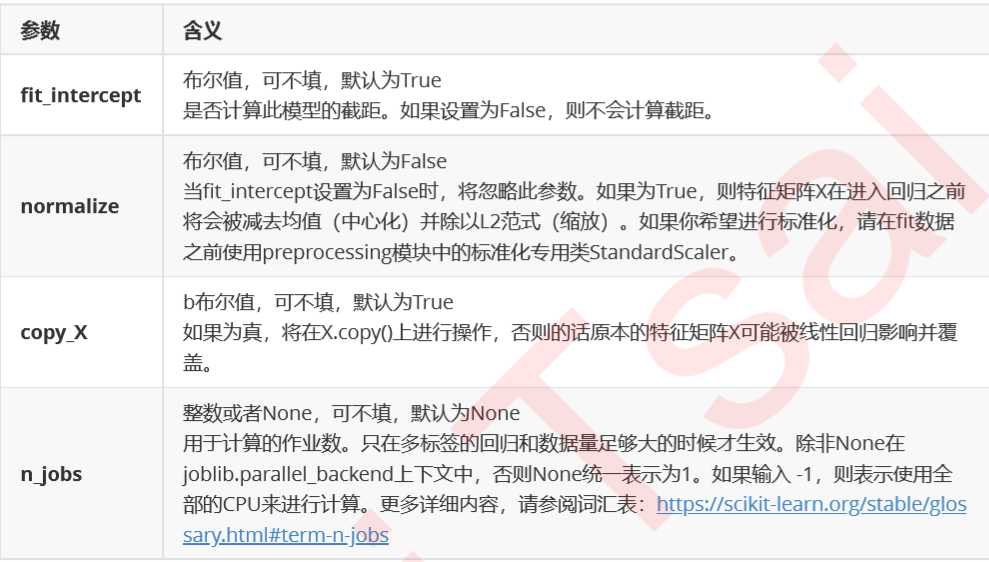
(2)参数:

(3)sklearn的三个坑
【1】均方误差为负
我们在决策树和随机森林中都提到过,虽然均方误差永远为正,但是sklearn中的参数scoring下,均方误差作为评 判标准时,却是计算”负均方误差“(neg_mean_squared_error)。这是因为sklearn在计算模型评估指标的时候, 会考虑指标本身的性质,均方误差本身是一种误差,所以被sklearn划分为模型的一种损失(loss)。在sklearn当中, 所有的损失都使用负数表示,因此均方误差也被显示为负数了。真正的均方误差MSE的数值,其实就是 neg_mean_squared_error去掉负号的数字。
除了MSE,我们还有与MSE类似的MAE(Mean absolute error,绝对均值误差)
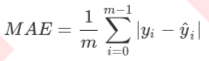
其表达的概念与均方误差完全一致,不过在真实标签和预测值之间的差异外我们使用的是L1范式(绝对值)。现实 使用中,MSE和MAE选一个来使用就好了。在sklearn当中,我们使用命令from sklearn.metrics import mean_absolute_error来调用MAE,同时,我们也可以使用交叉验证中的scoring = "neg_mean_absolute_error",以此在交叉验证时调用MAE。
【2】相同的评估指标不同的结果
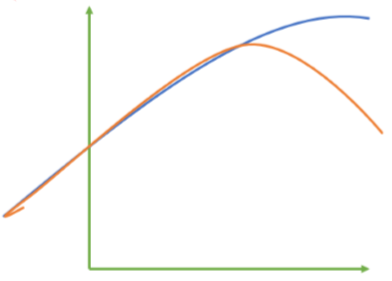
来看这张图,其中红色线是我们的真实标签,而蓝色线是我们的拟合模型。这是一种比较极端,但的确可能发生的 情况。这张图像上,前半部分的拟合非常成功,看上去我们的真实标签和我们的预测结果几乎重合,但后半部分的拟合却非常糟糕,模型向着与真实标签完全相反的方向去了。对于这样的一个拟合模型,如果我们使用MSE来对它 进行判断,它的MSE会很小,因为大部分样本其实都被完美拟合了,少数样本的真实值和预测值的巨大差异在被均分到每个样本上之后,MSE就会很小。但这样的拟合结果必然不是一个好结果,因为一旦我的新样本是处于拟合曲线的后半段的,我的预测结果必然会有巨大的偏差,而这不是我们希望看到的。所以,我们希望找到新的指标,除了判断预测的数值是否正确之外,还能够判断我们的模型是否拟合了足够多的,数值之外的信息。
在我们学习降维算法PCA的时候,我们提到我们使用方差来衡量数据上的信息量。如果方差越大,代表数据上的信 息量越多,而这个信息量不仅包括了数值的大小,还包括了我们希望模型捕捉的那些规律。为了衡量模型对数据上 的信息量的捕捉,我们定义了 和可解释性方差分数(explained_variance_score,EVS)来帮助我们
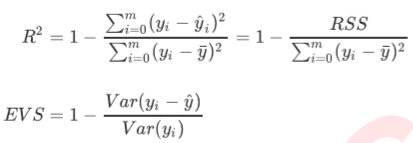
其中y是我们的真实标签, y^是我们的预测结果, y-是我们的均值,Var表示方差。方差的本质是任意一个y值和样本 均值的差异,差异越大,这些值所带的信息越多。在R2和EVS中,分子是真实值和预测值之差的差值,也就是我们的模型没有捕获到的信息总量,分母是真实标签所带的信息量,所以两者都衡量1 - 我们的模型没有捕获到的信息量占真实标签中所带的信息量的比例,所以,两者都是越接近1越好.

在我们的分类模型的评价指标当中,我们进行的是一种 if a == b的对比,这种判断和if b == a其实完全是一种概念,所以我们在进行模型评估的时候,从未踩到我们现在在的这个坑里。然而看R2的计算公式,R2明显和分类模型的指标中的accuracy或者precision不一样,R2涉及到的计算中对预测值和真实值有极大的区别,必须是预测值在分子,真实值在分母,所以我们在调用metrcis模块中的模型评估指标的时候,必须要检查清楚,指标的参数中,究竟是要求我们先输入真实值还是先输入预测值。
我们观察到,虽然我们在加利福尼亚房子价值数据集上的MSE相当小,但我们的R2却不高,这证明我们的模型比较好地拟合了数据的数值,却没有能正确拟合数据的分布。让我们与绘图来看看,究竟是不是这样一回事。我们可以绘制一张图上的两条曲线,一条曲线是我们的真实标签Ytest,另一条曲线是我们的预测结果yhat,两条曲线的交叠越多,我们的模型拟合就越好。
【3】负的R2
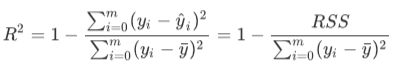
一直以来,众多的机器学习教材中都有这样的解读:
除了RSS之外,我们还有解释平方和ESS(Explained Sum of Squares,也叫做SSR回归平方和)以及总离差平方和 TSS(Total Sum of Squares,也叫做SST总离差平方和)。解释平方和ESS定义了我们的预测值和样本均值之间的 差异,而总离差平方和定义了真实值和样本均值之间的差异,两个指标分别写作:

而我们有公式: TSS = RSS + ESS
看我们的R2的公式,如果带入我们的TSS和ESS,那就有

而ESS和TSS都带平方,所以必然都是正数,那 怎么可能是负的呢?
好了,颠覆认知的时刻到来了——公式TSS = RSS + ESS不是永远成立的!就算所有的教材和许多博客里都理所当然这样写了大家也请抱着怀疑精神研究一下,你很快就会发现很多新世界。我们来看一看我们是如何证明(1)这个公 式的
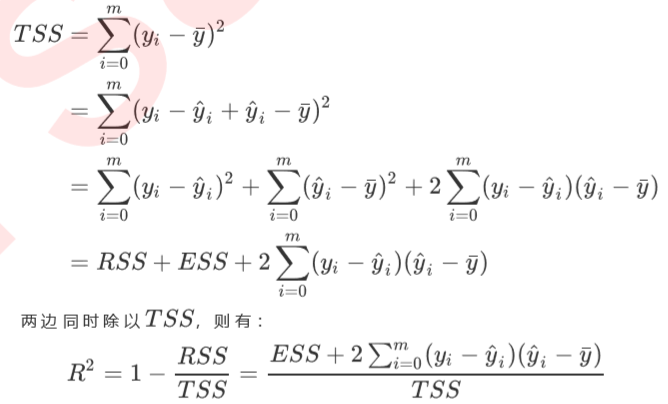

看下面这张图,蓝色的横线是我们的均值线y-,橙色的线是我们的模型y^,蓝色的点是我们的样本点。现在对于xi来说,我们的真实标签减预测值的值(yi-yi^)为正,但我们的预测值(yi^-y-)却是一个负数,这说明,数据本身的均值,比我们对数据的拟合模型本身更接近数据的真实值,那我们的模型就是废的,完全没有作用,类似于分类模 型中的分类准确率为50%,不如瞎猜.

也就是说,当我们的R2显示为负的时候,这证明我们的模型对我们的数据的拟合非常糟糕,模型完全不能使用。 所有,一个负的R2是合理的。当然了,现实应用中,如果你发现你的线性回归模型出现了负的 ,不代表你就要接受他了,首先检查你的建模过程和数据处理过程是否正确,也许你已经伤害了数据本身,也许你的建模过程是存在bug的。如果你检查了所有的代码,也确定了你的预处理没有问题,但你的R2也还是负的,那这就证明,线性回归模型不适合你的数据,试试看其他的算法吧.
(4)举例
def linear_regression(x_train,y_train,x_test):
model = LR()
reg = model.fit(x_train,y_train)
pred = reg.predict(x_test)
# print(reg.coef_)
print(pred)
2. 岭回归Ridge
(1)

(2)举例:
先找到最好的alpha,然后将alpha带入线性模型中训练
def find_min_alpha(x_train, y_train):
alphas = np.logspace(-2, 3, 200)
# print(alphas)
test_scores = []
alpha_score = []
for alpha in alphas:
clf = Ridge(alpha)
test_score = -cross_validation.cross_val_score(clf, x_train, y_train, cv=10, scoring='neg_mean_squared_error')
test_scores.append(np.mean(test_score))
alpha_score.append([alpha, np.mean(test_score)])
print("final test score:")
# print(test_scores)
# print(alpha_score) sorted_alpha = sorted(alpha_score, key=lambda x: x[1], reverse=False)
# print(sorted_alpha)
alpha = sorted_alpha[0][0]
print("best alpha:" + str(alpha))
return alpha
def linear_regression_with_Ridge(x_train,y_train,x_test,alpha):
clf = Ridge(alpha=alpha)
scores = -cross_validation.cross_val_score(clf,x_train,y_train,
cv=10,scoring='neg_mean_squared_error')
print('scores',scores)
print('mean score',scores.mean())
clf.fit(x_train,y_train)
# print(clf.coef_)
# print(clf.intercept_) ans = clf.predict(x_test)
# print('ans',ans.shape)
以Ridge线性回归为基回归器的随机森林
def create_model(x_train,y_train,alpha):
print('begin to train')
model = Ridge(alpha=alpha)
clf1 = ensemble.BaggingRegressor(model,n_jobs=1,n_estimators=900)
scores = -cross_validation.cross_val_score(model,x_train,y_train,cv=10,scoring='neg_mean_squared_error')
print('========================')
print('Scores:')
print(scores.mean())
clf1.fit(x_train,y_train)
print('Finish')
return clf1
3. LASSO

4. 弹性网
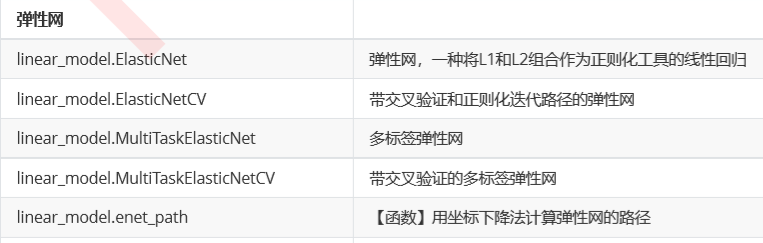
5. 最小角度回归
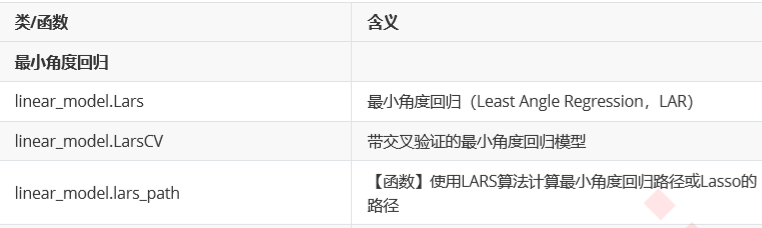
6.正交匹配追踪
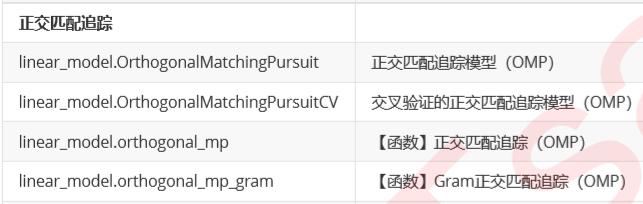
7.贝叶斯回归

8.其他回归
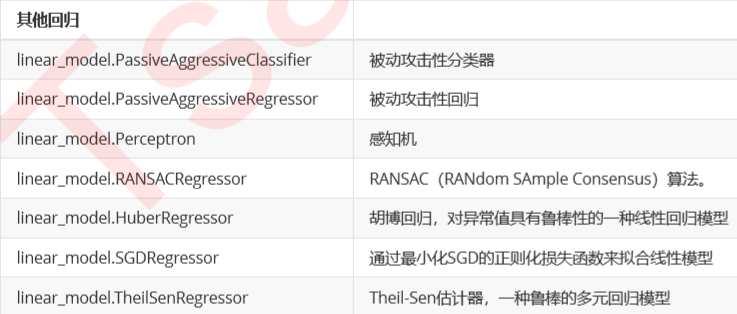
sklearn_线性回归的更多相关文章
- scikit-learn 线性回归算法库小结
scikit-learn对于线性回归提供了比较多的类库,这些类库都可以用来做线性回归分析,本文就对这些类库的使用做一个总结,重点讲述这些线性回归算法库的不同和各自的使用场景. 线性回归的目的是要得到输 ...
- 用scikit-learn和pandas学习线性回归
对于想深入了解线性回归的童鞋,这里给出一个完整的例子,详细学完这个例子,对用scikit-learn来运行线性回归,评估模型不会有什么问题了. 1. 获取数据,定义问题 没有数据,当然没法研究机器学习 ...
- 【scikit-learn】scikit-learn的线性回归模型
内容概要 怎样使用pandas读入数据 怎样使用seaborn进行数据的可视化 scikit-learn的线性回归模型和用法 线性回归模型的评估測度 特征选择的方法 作为有监督学习,分类问题是预 ...
- 线性回归 Linear Regression
成本函数(cost function)也叫损失函数(loss function),用来定义模型与观测值的误差.模型预测的价格与训练集数据的差异称为残差(residuals)或训练误差(test err ...
- 线性回归、梯度下降(Linear Regression、Gradient Descent)
转载请注明出自BYRans博客:http://www.cnblogs.com/BYRans/ 实例 首先举个例子,假设我们有一个二手房交易记录的数据集,已知房屋面积.卧室数量和房屋的交易价格,如下表: ...
- 回归分析法&一元线性回归操作和解释
用Excel做回归分析的详细步骤 一.什么是回归分析法 "回归分析"是解析"注目变量"和"因于变量"并明确两者关系的统计方法.此时,我们把因 ...
- R语言解读多元线性回归模型
转载:http://blog.fens.me/r-multi-linear-regression/ 前言 本文接上一篇R语言解读一元线性回归模型.在许多生活和工作的实际问题中,影响因变量的因素可能不止 ...
- R语言解读一元线性回归模型
转载自:http://blog.fens.me/r-linear-regression/ 前言 在我们的日常生活中,存在大量的具有相关性的事件,比如大气压和海拔高度,海拔越高大气压强越小:人的身高和体 ...
- deep learning 练习 多变量线性回归
多变量线性回归(Multivariate Linear Regression) 作业来自链接:http://openclassroom.stanford.edu/MainFolder/Document ...
随机推荐
- 宝宝刷 leetcode
12/3 1.Two Sum Given nums = [2, 7, 11, 15], target = 9, Because nums[0] + nums[1] = 2 + 7 = 9, retur ...
- ecshop安装后打开管理页面时报500错误
昨天给朋友安装ecshop,遇到如下问题: 1.PHP不支持mysql扩展 打开http://localhost/install/index.php,第二步时候,报不支持mysql. ecshop是前 ...
- [No0000163]卷福、神秘博士和一群老戏骨表演群口相声:To be or not to be该咋念,简直高潮迭起
'To be or not to be, that is the question',<哈姆雷特>中这句经典台词到底应该怎么念? 这是古今无数哈姆雷特演员最爱琢磨的问题,一千个人就 ...
- [No0000147]深入浅出图解C#堆与栈 C# Heap(ing) VS Stack(ing)理解堆与栈4/4
前言 虽然在.Net Framework 中我们不必考虑内在管理和垃圾回收(GC),但是为了优化应用程序性能我们始终需要了解内存管理和垃圾回收(GC).另外,了解内存管理可以帮助我们理解在每一个程 ...
- [DPDK] 转发 DPDK分析
前半部分,对于背景和需求的分析,写的相当好啊! 原文地址:https://www.jianshu.com/p/0ff8cb4deaef 背景分析 前10年中,网络程序性能优化的目标主要是为了解决C10 ...
- 深入hash
hash真的很好用,这些杂一点的知识点我觉得还是很有必要的,对还有离散化. 1<=N<=1,000,000,其它所有数据都在[0...1,000,000,000]范围内 看起来很简单一道水 ...
- 《Nginx - 指令》- Rewrite/If/Set
一:Rewrite - 概述 - flag 作用 - last / break 实现对 Url 的重写. - redirect / permanent 实现对 Url 的重定向. - 使用范围 - s ...
- Python开发【笔记】:接口压力测试
接口压力测试脚本 1.单进程多线程模式 # #!/usr/bin/env python # # -*- coding:utf-8 -*- import time import logging impo ...
- java 线程(六)死锁
package cn.sasa.demo4; public class ThreadDemo { public static void main(String[] args){ DeadLockRun ...
- 拦截器的作用之session认证登录和资源拦截
背景: 在项目中我使用了自定义的Filter 这时候过滤了很多路径,当然对静态资源我是直接放过去的,但是,还是出现了静态资源没办法访问到springboot默认的文件夹中得文件.另外,经常需要判断当前 ...