LSTM-自然语言建模
说到自然语言,我就会想到朴素贝叶斯,贝叶斯核心就是条件概率,而且大多数自然语言处理的思想也就是条件概率。
所以我用预测一个句子出现的概率为例,阐述一下自然语言处理的思想。
处理思想-概率
句子,就是单词的序列,句子出现的概率就是这个序列出现的概率
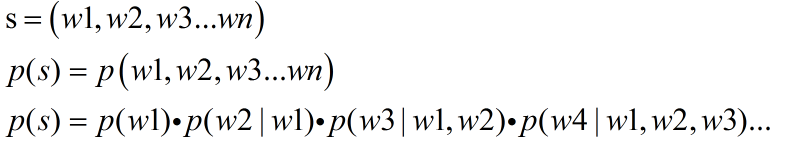
可以想象上面这个式子计算量有多大。
为了减少计算量,常常用一个估计值来代替上面的概率。估计该值常用的方法有
n-gram、决策树、最大熵模型、条件随机出、神经网络等。
以最简单的n-gram为例
n-gram模型有个假设:当前单词出现的概率仅与前面n-1个单词有关
于是,m个单词的句子出现的概率可以估计为
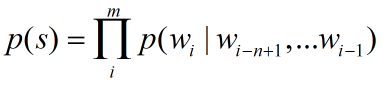
显然n取值越大,理论上这个估计越准确
但是因为计算量的问题,通常n取较小值,如 1,2,3,分别有对应的名字 unigram, bigram, trigram,最常用的是2
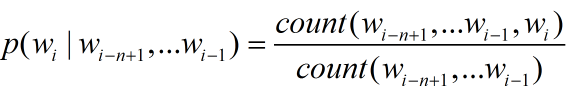
出现次数相比,很显然有个问题,如果没出现呢,比如语料库较小,那么这个单词出现的概率为0,,p(s)=0,
一个单词没出现导致整个句子出现概率为0,显然不合适
这也是自然语言处理中比较普遍的问题,常用的解决方法是拉普拉斯平滑,避免0的出现,比如

此时这个句子的概率就算出来了。
评价指标-复杂度
语言模型的好坏常用复杂度(perplexity)来评价。
如果一个句子在文档中确实出现了,那么我们的模型算出来的概率越大越好,
概率越大,就需要每个p的概率越大,
每个p越大,就意味着这某些单词出现的情况下,出现这个单词的概率很大,
也就是说,在某些单词出现时,下一个单词的可选择性很小,比如单词 “国”后面的单词很少,最常用的是“家”,此时“家”的概率就很大
这个可选择性就是复杂度。
其实可以理解为整个词语结构的复杂度,词语结构越简单,复杂度越低。图形表示如下
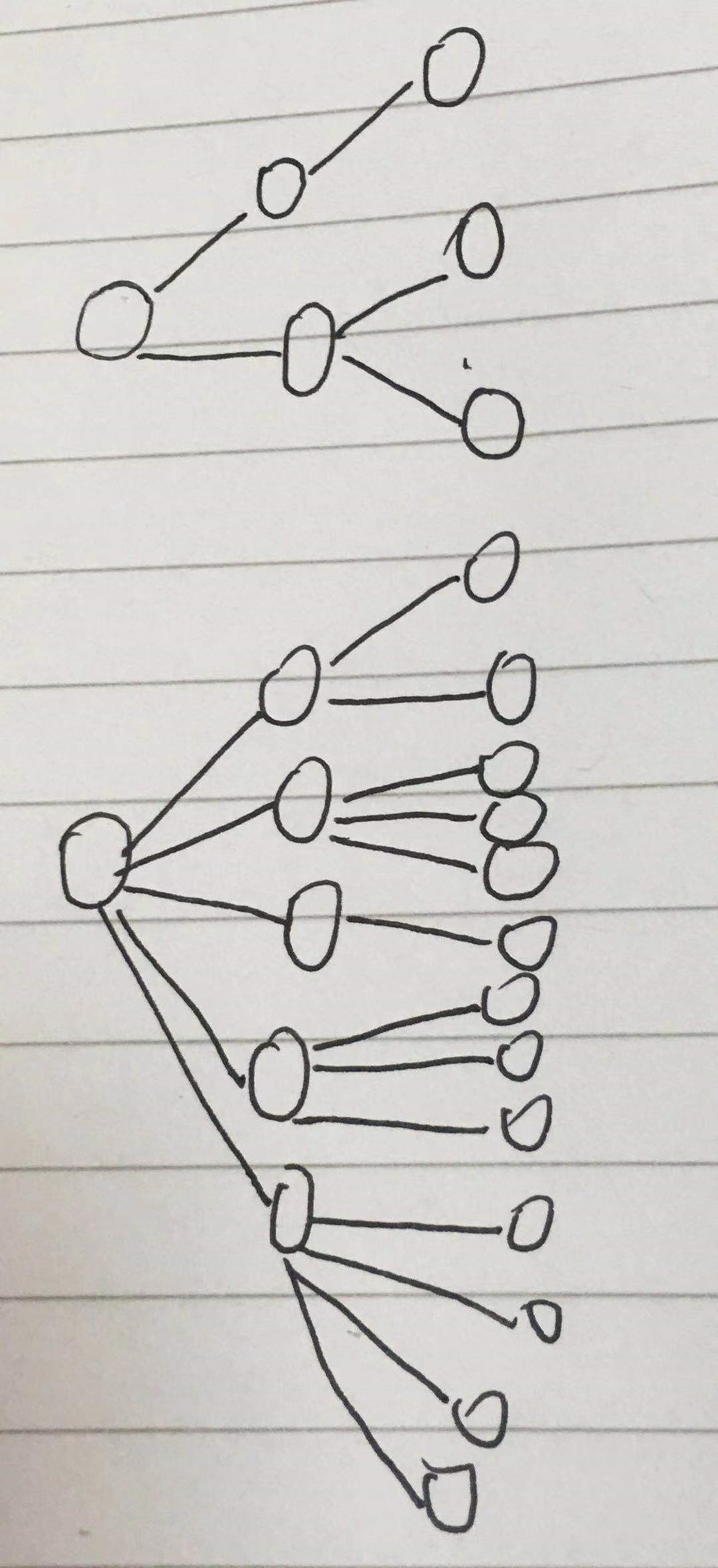
显然上面的结构简单。
可选择性可以用概率的倒数来表示。即概率越大,可选择性越小,复杂度越低。

可以两边取log简化运算。取log乘法变加法,也避免了一个为0结果为0的情况。
LSTM 语言模型
lstm 使得网络具有记忆功能,也就是记住了之前的词语,也就是在知道之前词语的情况下,训练或者预测下一个单词。这就是rnn处理自然语言的逻辑。
训练过程:输入x是单词,y是x的下一个单词,最终得到每个单词下一个单词的概率。
预测过程:取下一个单词中概率最大的单词。
图形表示如下
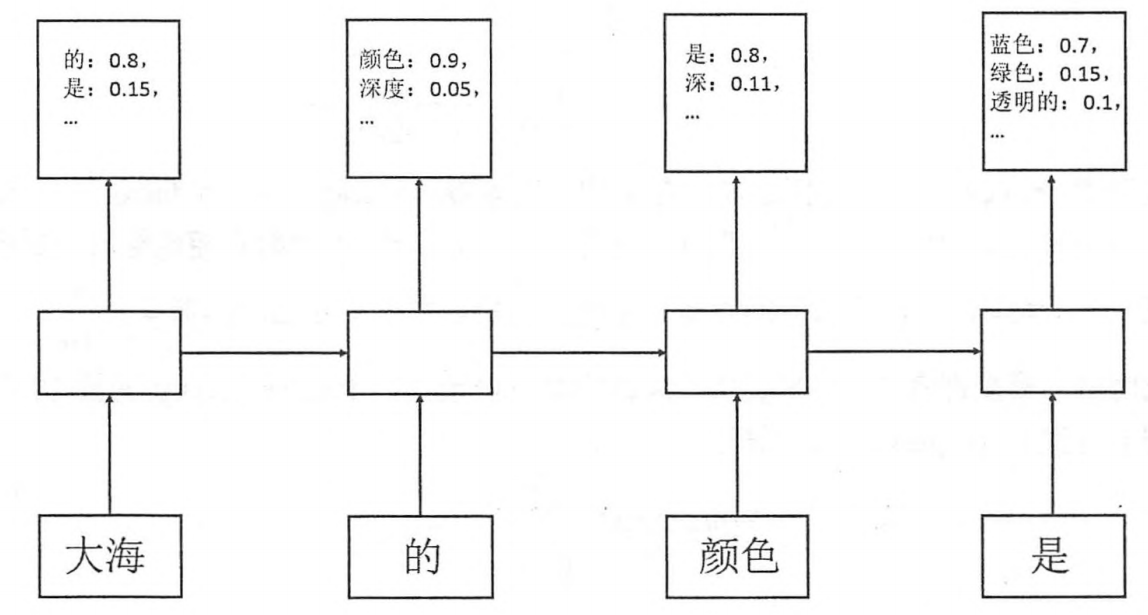
把训练样本 “大海的颜色是蓝色” 输入网络训练,可以得到在 “大海” 出现的情况下,后面是 “的” 的概率0.8,是 “是”的概率0.15,
在“大海的”出现的情况下,后面每个单词出现的概率,依次
最终预测时,在“大海的颜色是”出现的情况下,预测结果是“蓝色”的概率是0.7,预测正确。
LSTM-自然语言建模的更多相关文章
- LSTM UEBA异常检测——deeplog里其实提到了,就是多分类LSTM算法,结合LSTM预测误差来检测异常参数
结合CNN的可以参考:http://fcst.ceaj.org/CN/article/downloadArticleFile.do?attachType=PDF&id=1497 除了行为,其他 ...
- 学习笔记DL003:神经网络第二、三次浪潮,数据量、模型规模,精度、复杂度,对现实世界冲击
神经科学,依靠单一深度学习算法解决不同任务.视觉信号传送到听觉区域,大脑听学习处理区域学会“看”(Von Melchner et al., 2000).计算单元互相作用变智能.新认知机(Fukushi ...
- TensorFlow学习笔记(六)循环神经网络
一.循环神经网络简介 循环神经网络的主要用途是处理和预测序列数据.循环神经网络刻画了一个序列当前的输出与之前信息的关系.从网络结构上,循环神经网络会记忆之前的信息,并利用之前的信息影响后面节点的输出. ...
- NVIDIA深度架构
NVIDIA深度架构 本文介绍A100 GPU,NVIDIA Ampere架构GPU的重要新功能. 现代云数据中心中运行的计算密集型应用程序的多样性推动了NVIDIA GPU加速的云计算的爆炸式增长. ...
- A100 Tensor核心可加速HPC
A100 Tensor核心可加速HPC HPC应用程序的性能需求正在迅速增长.众多科学研究领域的许多应用程序都依赖于双精度(FP64)计算. 为了满足HPC计算快速增长的计算需求,A100 GPU支持 ...
- NVIDIA安培架构
NVIDIA安培架构 NVIDIA Ampere Architecture In-Depth 在2020年英伟达GTC主题演讲中,英伟达创始人兼首席执行官黄仁勋介绍了基于新英伟达安培GPU架构的新英伟 ...
- 论文笔记:A Structured Self-Attentive Sentence Embedding
A Structured Self-Attentive Sentence Embedding ICLR 2017 2018-08-19 14:07:29 Paper:https://arxiv.org ...
- 《A Structured Self-Attentive Sentence Embedding》(注意力机制)
Background and Motivation: 现有的处理文本的常规流程第一步就是:Word embedding.也有一些 embedding 的方法是考虑了 phrase 和 sentence ...
- 论文笔记:A Review on Deep Learning Techniques Applied to Semantic Segmentation
A Review on Deep Learning Techniques Applied to Semantic Segmentation 2018-02-22 10:38:12 1. Intr ...
- SAP成都研究院飞机哥: SAP C4C中国本地化之微信聊天机器人的集成
今天的文章仍然来自Jerry的老同事,SAP成都研究院的张航(Zhang Harry).关于他的背景介绍,请参考张航之前的文章:SAP成都研究院飞机哥:程序猿和飞机的不解之缘.下面是他的正文. 大家好 ...
随机推荐
- Mysql中Join用法及优化
Join的几种类型 笛卡尔积(交叉连接) 如果A表有n条记录,B表有m条记录,笛卡尔积产生的结果就会产生n*m条记录.在MySQL中可以为CROSS JOIN或者省略CROSS即JOIN,或者直接用f ...
- 2. 搭建DRF项目
企业项目开发流程 一.需求分析 1.企业的web项目类型: 商城 门户网站[企业站和门户站] 社交网络 资讯论坛 内部系统 个人博客 内容收费站 前端的静态页面制作,外界开发的时候,是照着psd/pn ...
- 58Ajax
Ajax 1 .客户端浏览器通过执行一段JS代码向服务器发送请求,服务器路由对应的视图函数返回一个json字符串作为响应, 浏览器接受响应后会触发该ajax请求的回调函数success,参数为响 ...
- Problem F. Grab The Tree HDU - 6324
题意:给出一棵n个节点的树,每个节点有一个权值,Q和T玩游戏,Q先选一些不相邻的节点,T选剩下的节点,每个人的分数是所选节点的权值的异或和,权值大的胜出,问胜出的是谁. 题解: 话说,这题后面的边跟解 ...
- TCP/UDP协议简要梳理
TCP/UDP协议简要梳理 TCP TCP,Transmission Control Protocol,传输控制协议是一种面向连接的.可靠的.基于字节流的传输层通信协议.在因特网协议族中,TCP所在的 ...
- 我的第一个C语言程序
从自学开始到现在应该有块一个月了,之前一直想要写博客一直没想好要自己建博客还是找平台来写.现在想想 其实都一样,不论在哪里,都可以记录自己学习的成长记录.这是我的第一篇关于C语言学习的博客,希望这只是 ...
- Oracle 三大范式
范式:数据库设计对数据的存储性能,还有开发人员对数据的操作都有莫大的关系.所以建立科学的,规范的的数据库是需要满足一些.规范的来优化数据数据存储方式.在关系型数据库中这些规范. 第一范式:数据库表中的 ...
- 剑指offer-调整数组内奇偶数顺序
题目描述 输入一个整数数组,实现一个函数来调整该数组中数字的顺序,使得所有的奇数位于数组的前半部分,所有的偶数位于位于数组的后半部分,并保证奇数和奇数,偶数和偶数之间的相对位置不变. 解题思路 时间换 ...
- vmplayer桥接以及nat配置nginx
1.环境 centos6.4 vm player nginx1.8 2.虚拟机的防火墙 参考http://blog.csdn.net/qilovehua/article/details/4550713 ...
- Oracle 12c新特性之——TABLE ACCESS BY INDEX ROWID BATCHED
Oracle12c开始,我们在获取SQL语句的执行计划时,也会经常看到"TABLE ACCESS BY INDEX ROWID BATCHED"操作,那么,这个操作到底是什么意思呢 ...