Go语言学习之4 递归&闭包&数组切片&map&锁
主要内容:
1. 内置函数、递归函数、闭包
2. 数组与切片
3. map数据结构
4. package介绍
5. 排序相关
1. 内置函数、递归函数、闭包
1)内置函数
(1). close:主要用来关闭channel
1). close函数是一个内建函数,用来关闭channel,这个channel要么是双向的, 要么是只写的(chan<- Type)。
2). 这个方法应该只由发送者调用, 而不是接收者。
3). 当最后一个发送的值都被接收者从关闭的channel(下简称为c)中接收时,接下来所有接收的值都会非阻塞直接成功,返回channel元素的零值。
channel(Go中channel可以是只读、只写、同时可读写的)
//定义只读的channel
read_only := make(<-chan int)
//定义只写的channel
write_only := make(chan<- int)
//可同时读写
read_write := make(chan int)
定义只读和只写的channel意义不大,一般用于在参数传递中,见代码:
package main import (
"fmt"
"time"
) func main() {
c := make(chan int)
go send(c)
go recv(c)
time.Sleep( * time.Second) //等待上面执行结束
}
//只能向chan里写数据
func send(c chan<- int) {
fmt.Println("write data to chan")
for i := ; i < ; i++ {
c <- i
}
}
//只能取channel中的数据
func recv(c <-chan int) {
fmt.Println("read data from chan")
for i := range c {
fmt.Println(i)
}
}
channel示例
close函数简介:
) close函数是一个内建函数, 用来关闭channel,这个channel要么是双向的, 要么是只写的(chan<- Type)。
) 这个方法应该只由发送者调用, 而不是接收者。
) 当最后一个发送的值都被接收者从关闭的channel(下简称为c)中接收时, 接下来所有接收的值都会非阻塞直接成功,返回channel元素的零值。
例如如下的代码:
如果c已经关闭(c中所有值都被接收), x, ok := <- c, 读取ok将会得到false。
package main
import "fmt"
func main() {
ch := make(chan int, )
for i := ; i < ; i++ {
ch <- i
}
close(ch) // 关闭ch
for i := ; i < ; i++ {
e, ok := <-ch //如果c已经关闭(c中所有值都被接收),再次读取 x, ok := <- c, 读取ok将会得到false
fmt.Printf("%v, %v\n", e, ok)
if !ok {
break
}
}
}
// 输出结果:
// 0, true
// 1, true
// 2, true
// 3, true
// 4, true
// 0, false
close函数使用注意事项:
对于值为nil的channel或者对同一个channel重复close,都会panic,关闭只读channel会报编译错误。
) 关闭值为nil的通道
var c4 chan int
// 运行时错误:panic: close of nil channel
close(c4) ) 重复关闭同一个通道
c3 := make(chan int, )
close(c3)
// 运行时错误:
// panic: close of closed channel
close(c3) ) 关闭只读通道
c3 := make(<-chan int, )
// 编译错误:
// invalid operation: close(c3) (cannot close receive-only channel)
close(c3) //正确的用法
c1 := make(chan int, ) // 双向通道 (bidirectional)
c2 := make(chan<- int, ) // 只写的 (send-only)
close(c1)
close(c2)
close函数使用注意事项
close的详细使用见链接: https://www.jianshu.com/p/d24dfbb33781
(2). len:用来求长度,比如string、array、slice、map、channel
(3). new:用来分配内存,主要用来分配值类型,比如int、struct。返回的是指针
(4). make:用来分配内存,主要用来分配引用类型,比如chan、map、slice
(5). append:用来追加元素到数组、slice中
package main
import "fmt"
func main() {
var a []int
a = append(a, , , )
a = append(a, a...)
fmt.Println(a) //[10 20 30 10 20 30]
var b []int
b = make([]int, ) //存放5个int型数
b = append(b, , , )
b = append(b, b...)
fmt.Println(b) //b扩容了,[0 0 0 0 0 10 20 30 0 0 0 0 0 10 20 30]
}
append使用
(6). panic和recover:用来做错误处理
panic:
、内建函数
、假如函数F中书写了panic语句,会终止其后要执行的代码,在panic所在函数F内如果存在要执行的defer函数列表,按照defer的逆序执行
、返回函数F的调用者G,在G中,调用函数F语句之后的代码不会执行,假如函数G中存在要执行的defer函数列表,按照defer的逆序执行,这里的defer 有点类似 try-catch-finally 中的 finally
、直到goroutine整个退出,并报告错误 recover:
、内建函数
、用来控制一个goroutine的panicking行为,捕获panic,从而影响应用的行为
、一般的调用建议
a). 在defer函数中,通过recever来终止一个gojroutine的panicking过程,从而恢复正常代码的执行
b). 可以获取通过panic传递的error
panic及recover介绍
package main import "fmt"
import "time"
import "errors" func initConfig() (err error) {
return errors.New("init config failed")
} func test() {
defer func() {
if err := recover(); err != nil {
fmt.Println(err)
}
}() //执行匿名函数 err := initConfig()
if err != nil {
panic(err) //在该处抛出一个panic的异常,然后在上面的defer中通过recover捕获这个异常,然后正常处理。
} fmt.Println("can not excute") //该行及以下的代码不会被执行
return
} func main() {
for {
test()
time.Sleep(time.Second)
}
}
panic及recover使用
总结:go中可以抛出一个panic的异常,然后在defer中通过recover捕获这个异常,然后正常处理。
(7). new和make的区别
new 的作用是初始化一个指向类型的指针(*T),make 的作用是为 slice,map 或 chan 初始化并返回引用(T)。
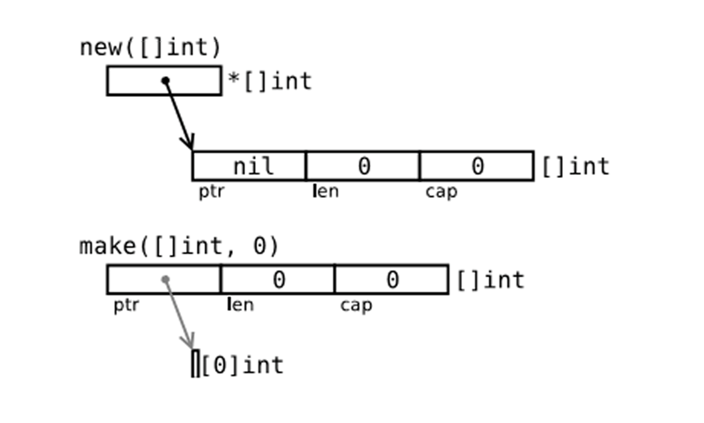
例如:
package main
import "fmt"
func test() {
s1 := new([]int)
fmt.Println(s1) //&[]
s2 := make([]int, )
fmt.Println(s2) // [0 0 0 0 0 0 0 0 0 0]
*s1 = make([]int, )
(*s1)[] =
s2[] =
fmt.Println(s1) // &[100 0 0 0 0]
return
}
func main() {
test()
}
new和make的区别
更详细的区别见链接: https://www.jb51.net/article/126703.htm
2)递归函数
递归定义:一个函数调用自己,就叫做递归。
例1:计算一个数的阶乘
package main
import "fmt"
func calcRecur(n int) int {
if n == {
return
}
return calcRecur(n-)*n
}
func main() {
res := calcRecur()
fmt.Println(res) //
}
example
例2:计算斐波那契数列
package main
import "fmt"
func calcFib(n int) int {
if n <= {
return
}
return calcFib(n - ) + calcFib(n - )
}
func main() {
for i := ; i <= ; i++ {
fmt.Println(calcFib(i))
}
}
example2
递归的设计原则:
1)一个大的问题能够分解成相似的小问题
2)定义好出口条件
3)闭包
闭包:一个函数和与其相关的引用环境组合而成的实体。
package main
import "fmt"
func Adder() func(int) int {
var x int
return func(delta int) int {
x += delta
return x
}
}
func main() {
var f = Adder() //x的值,只要Adder()还在调用,则x就在内存中
fmt.Println(f()) //
fmt.Println(f()) //21
fmt.Println(f()) //
}
闭包例子
package main import (
"fmt"
"strings"
) //该函数作用检查name是否以suffix结尾,如果不是则追加
func makeSuffixFunc(suffix string) func(string) string {
return func(name string) string {
if !strings.HasSuffix(name, suffix) {
return name + suffix
}
return name
}
} func main() {
func1 := makeSuffixFunc(".bmp")
func2 := makeSuffixFunc(".jpg")
fmt.Println(func1("test")) //test.bmp
fmt.Println(func2("test")) //test.jpg
}
闭包例子2
闭包更多了解详见链接:https://www.cnblogs.com/cxying93/p/6103375.html 和 https://www.cnblogs.com/hzhuxin/p/9199332.html
2. 数组与切片
1.数组
(1). 数组:是同一种数据类型的固定长度的序列。
(2). 数组定义:var a [len]int,比如:var a[5]int,一旦定义,长度不能变
(3). 长度是数组类型的一部分,因此,var a[5] int和var a[10]int是不同的类型
(4). 数组可以通过下标进行访问,下标是从0开始,最后一个元素下标是:len-1
方法1:
for i := ; i < len(a); i++ {
} 方法2:
for index, v := range a {
}
数组访问的两种方式
(5). 访问越界,如果下标在数组合法范围之外,则触发访问越界,会panic
(6). 数组是值类型,因此改变副本的值,不会改变本身的值
arr2 := arr1
arr2[2] = 100 //arr1的值不会发生改变
package main import (
"fmt"
) func modify(arr []int) { //arr是a的副本
arr[] =
return
} func main() {
var a []int //var a []int
//a = make([]int, 5) // cannot use a (type []int) as type [5]int in argument to modify //modify(a[:]) //cannot use a[:] (type []int) as type [5]int in argument to modify
modify(a) //a的值不会发生改变
for i := ; i < len(a); i++ {
fmt.Println(a[i])
}
}
不会改变数组的值
package main import (
"fmt"
) func modify(arr *[]int) {
//fmt.Printf("%p\n", arr) //0xc0420481b0
(*arr)[] =
(*arr)[] =
return
} func main() {
var a []int
//fmt.Printf("%p\n", &a) //0xc0420481b0
modify(&a) //a的值改变了
for i := ; i < len(a); i++ {
fmt.Println(a[i]) // a[0]=100 a[1]=200
}
}
改变数组的值
注意下面例子:
package main import (
"fmt"
) func modify(arr []int) { //arr是a的副本
arr[] =
} func test() {
var b []int = []int{, , , , }
//fmt.Printf("%p\n", &b)
modify(b)
fmt.Println(b) //[1 2 3 4 5] 未改变数组b的值
} func modifySlice(a []int) {
fmt.Printf("%p\n", a) //0xc042042440
a[] =
} func testSlice() {
var b []int = []int{, , , }
fmt.Printf("%p\n", b) //0xc042042440
modifySlice(b) //地址的传递
fmt.Println(b) //[1 1000 3 4] 改变了b的值
} func main() {
test()
testSlice()
}
数组与切片区别
练习:使用非递归的方式实现斐波那契数列,打印前10个数。
package main
import "fmt"
func fab(n int) {
var a []uint64
a = make([]uint64, n) //初始化数组 a
a[] =
a[] =
for i := ; i < n; i++ {
a[i] = a[i-] + a[i-]
}
for _, v := range a {
fmt.Println(v)
}
}
func main() {
fab()
}
斐波拉切
1). 数组初始化
a. var age0 []int = []int{,,}
b. var age1 = []int{,,,,}
c. var age2 = […]int{,,,,,}
d. var str = []string{:”hello world”, :”tom”}
数组初始化
2). 多维数组
a. var age [][]int
b. var f [][]int = [...][]int{{, , }, {, , }}
多维数组
3). 多维数组遍历
package main import (
"fmt"
) func main() { var f[][]int = [...][]int{{, , }, {, , }} for k1, v1 := range f {
for k2, v2 := range v1 {
fmt.Printf("(%d,%d)=%d ", k1, k2, v2)
}
fmt.Println()
}
}
多维数组遍历
2. 数组切片
(1). 切片:切片是数组的一个引用,因此切片是引用类型
(2). 切片的长度可以改变,因此,切片是一个可变的数组
(3). 切片遍历方式和数组一样,可以用len()求长度
(4). cap可以求出slice最大的容量,0 <= len(slice) <= cap(array),其中array是slice引用的数组
(5). 切片的定义:var 变量名 []类型,比如 var str []string, var arr []int
切片引用:
(1). 切片初始化:var slice []int = arr[start:end]包含start到end之间的元素,但不包含end
(2). var slice []int = arr[0:end]可以简写为 var slice []int=arr[:end]
(3). var slice []int = arr[start:len(arr)] 可以简写为 var slice[]int = arr[start:]
(4). var slice []int = arr[0, len(arr)] 可以简写为 var slice[]int = arr[:]
(5). 如果要切片最后一个元素去掉,可以这么写: Slice = slice[:len(slice)-1]
练习:写一个程序,演示切片的各个用法
package main import (
"fmt"
) func main() {
var slice []int
var arr []int = [...]int{, , , , } slice = arr[:]
fmt.Println(slice) //[1 2 3 4 5]
slice = slice[:]
fmt.Println(len(slice)) //
slice = slice[:len(slice)-]
fmt.Println(cap(slice)) // slice = slice[:]
fmt.Println(len(slice)) //
fmt.Println(cap(slice)) //
}
切片例子
切片的内存布局:
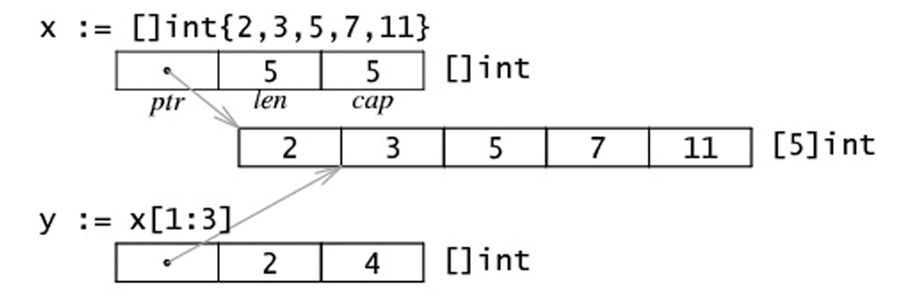
练习: 写一个程序,演示切片的内存布局(注意和上图的联系)
package main import "fmt" //自定义切片类型
type slice struct {
ptr *[]int //为了测试方便,定义ptr指向具有固定大小10个字节内存地址
len int //数组长度
cap int //数组容量
} //初始化切片
func make1(s slice, cap int) slice {
s.ptr = new([]int)
s.cap = cap
s.len =
return s
} //修改切片内的数组值
func modify(s slice) {
s.ptr[] =
} func testSlice1() {
var s1 slice
s1 = make1(s1, ) s1.ptr[] =
modify(s1) fmt.Println(s1.ptr) //&[100 1000 0 0 0 0 0 0 0 0]
} func modify1(a []int) {
a[] =
} func testSlice2() {
var b []int = []int{, , , }
modify1(b)
fmt.Println(b) //[1 1000 3 4]
} func testSlice3() {
var a = []int{, , , } b := a[:]
fmt.Printf("%p\n", b) //0xc042058058
fmt.Printf("%p\n", &a[]) //0xc042058058
} func main() {
//testSlice1()
//testSlice2()
testSlice3()
}
练习
(6). 通过make来创建切片
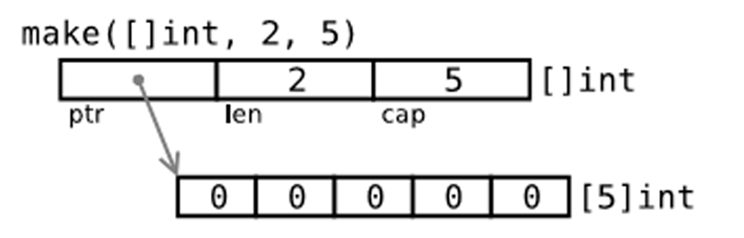
var slice []type = make([]type, len)
slice := make([]type, len)
slice := make([]type, len, cap)
make创建切片
(7). 用append内置函数操作切片
slice = append(slice, )
var a = []int{,,}
var b = []int{,,}
a = append(a, b…)
append操作切片
(8). For range 遍历切片
for index, val := range slice {}
遍历切片
(9). 切片resize
var a = []int {,,,}
b := a[:]
b = b[:]
resize
(10). 切片拷贝
s1 := []int{,,,,}
s2 := make([]int, )
copy(s2, s1)
s3 := []int{,,}
s3 = append(s3, s2…)
s3 = append(s3, , , )
copy
(11). string与slice
string底层就是一个byte的数组,因此,也可以进行切片操作
str := "hello world"
s1 := str[:]
fmt.Println(s1)
s2 := str[:]
fmt.Println(s2)
string与slice
(12). string的底层布局
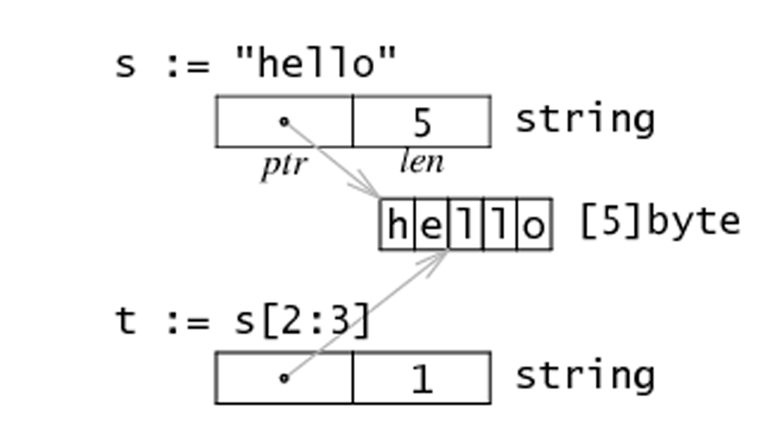
(13). 如何改变string中的字符值?
string本身是不可变的,因此要改变string中字符,需要如下操作:
str := "hello world"
s := []byte(str)
s[] = 'O'
str = string(s)
改变string中的值
(14). 排序和查找操作
排序操作主要都在 sort包中,导入就可以使用了
import("sort")
sort.Ints对整数进行排序,sort.Strings对字符串进行排序, sort.Float64s对
浮点数进行排序.
sort.SearchInts(a []int, b int) 从数组a中查找b,前提是a必须有序
sort.SearchFloats(a []float64, b float64) 从数组a中查找b,前提是a必须有序
sort.SearchStrings(a []string, b string) 从数组a中查找b,前提是a必须有序
sort
package main import (
"fmt"
"sort"
) func testIntSort() {
var a = [...]int{, , , , , }
sort.Ints(a[:]) fmt.Println(a) //[1 2 8 38 348 484]
} func testStrings() {
var a = [...]string{"abc", "efg", "b", "A", "eeee"}
sort.Strings(a[:]) fmt.Println(a) //[A abc b eeee efg]
} func testFloat() {
var a = [...]float64{2.3, 0.8, 28.2, 392342.2, 0.6}
sort.Float64s(a[:]) fmt.Println(a) //[0.6 0.8 2.3 28.2 392342.2]
} func testIntSearch() {
var a = [...]int{, , , , , }
//sort.Ints(a[:])
index := sort.SearchInts(a[:], ) //SearchInts该函数内部会先排序然后查找
fmt.Println(index) //
fmt.Println(a) //[1 8 38 2 348 484] 未改变a的值
} func main() {
testIntSort()
testStrings()
testFloat()
testIntSearch()
}
example
注意:sort.Ints,sort.Strings,sort.Float64s会改变源数组的值。
切片,copy及字符串修改测试:
package main
import "fmt"
func testSlice() {
var a []int = [...]int{, , , , }
s := a[:]
fmt.Printf("before len[%d] cap[%d]\n", len(s), cap(s)) //before len[4] cap[4]
s[] = //改变s[1](a[1])值
fmt.Printf("s=%p a[1]=%p\n", s, &a[]) //s=0xc0420481b8 a[1]=0xc0420481b8
fmt.Println("before a:", a) //before a: [1 2 100 4 5]
s = append(s, )
s = append(s, )
fmt.Printf("after len[%d] cap[%d]\n", len(s), cap(s)) //after len[6] cap[8]
s = append(s, )
s = append(s, )
s = append(s, )
s[] = //s扩容之后s和a[1]的地址不同,因此改变s[1]的值a[1]的值不发生变化
fmt.Println("after a:", a) //after a: [1 2 100 4 5]
fmt.Println(s) //[2 1000 4 5 10 10 10 10 10]
fmt.Printf("s=%p a[1]=%p\n", s, &a[]) //s=0xc042014200 a[1]=0xc0420481b8
}
func testCopy() {
var a []int = []int{, , , , , }
b := make([]int, )
copy(b, a) //拷贝的大小以b为准
fmt.Println(b) //[1]
}
func testString() {
s := "hello world"
s1 := s[:]
s2 := s[:]
fmt.Println(s1) //hello
fmt.Println(s2) //world
}
func testModifyString() {
s := "我hello world"
s1 := []rune(s)
s1[] = '你'
s1[] = 'z'
s1[] = 'z'
str := string(s1)
fmt.Println(str) //你zzllo world
}
func main() {
//testSlice()
//testCopy()
//testString()
testModifyString()
}
example
3. map数据结构
(1). map简介
key-value的数据结构,又叫字典或关联数组
声明:
var map1 map[keytype]valuetype
var a map[string]string
var a map[string]int
var a map[int]string
var a map[string]map[string]string
注意:声明是不会分配内存的,初始化需要make
(2). map相关操作
var a map[string]string = map[string]string{"hello": "world"} 定义并初始化map a
a := make(map[string]string, 10)
a["hello"] = "world" 插入和更新
val, ok := a["hello"] 查找
for k, v := range a {
fmt.Println(k,v) 遍历
}
delete(a, "hello") 删除
len(a) 长度
(3). map是引用类型
func modify(a map[string]int) {
a["one"] = 134
}
(4). slice of map
items := make([]map[int][int], 5)
for i := 0; I < 5; i++ {
items[i] = make(map[int][int])
}
(5). map排序
a. 先获取所有key,把key进行排序
b. 按照排序好的key,进行遍历
(6). Map反转
初始化另外一个map,把key、value互换即可
package main
import "fmt"
func testMap() {
var a map[string]string = map[string]string {
"key": "value",
}
//a := make(map[string]string, 10)
a["abc"] = "efg"
a["abc"] = "efg"
a["abc1"] = "efg"
fmt.Println(a) //map[key:value abc:efg abc1:efg]
}
func testMap2() {
a := make(map[string]map[string]string, ) //value是一个map
a["key1"] = make(map[string]string)
a["key1"]["key2"] = "abc"
a["key1"]["key3"] = "abc"
a["key1"]["key4"] = "abc"
a["key1"]["key5"] = "abc"
fmt.Println(a) //map[key1:map[key2:abc key3:abc key4:abc key5:abc]]
}
func modify(a map[string]map[string]string) {
_, ok := a["zhangsan"]
if !ok {
a["zhangsan"] = make(map[string]string)
}
a["zhangsan"]["passwd"] = ""
a["zhangsan"]["nickname"] = "pangpang"
return
}
func testMap3() {
a := make(map[string]map[string]string, )
modify(a)
fmt.Println(a) //map[zhangsan:map[passwd:123456 nickname:pangpang]]
}
func trans(a map[string]map[string]string) {
for k, v := range a {
fmt.Println(k)
for k1, v1 := range v {
fmt.Println("\t", k1, v1)
}
}
}
func testMap4() {
a := make(map[string]map[string]string, )
a["key1"] = make(map[string]string)
a["key1"]["key2"] = "abc"
a["key1"]["key3"] = "abc"
a["key1"]["key4"] = "abc"
a["key1"]["key5"] = "abc"
a["key2"] = make(map[string]string)
a["key2"]["key2"] = "abc"
a["key2"]["key3"] = "abc"
trans(a)
delete(a, "key1") //删除"key1"
fmt.Println()
trans(a)
fmt.Println(len(a))
}
func testMap5() {
var a []map[int]int
a = make([]map[int]int, )
if a[] == nil {
a[] = make(map[int]int)
}
a[][] =
fmt.Println(a) //[map[10:10] map[] map[] map[] map[]]
}
func main() {
//testMap()
//testMap2()
//testMap3()
//testMap4()
testMap5()
}
Map操作示例
package main import (
"fmt"
"sort"
) func testMapSort() {
var a map[int]int
a = make(map[int]int, ) a[] =
a[] =
a[] =
a[] =
a[] = var keys []int
for k, _ := range a {
keys = append(keys, k)
//fmt.Println(k, v)
} sort.Ints(keys) for _, v := range keys {
fmt.Println(v, a[v])
}
// 1 10
// 2 10
// 3 10
// 8 10
// 18 10
} func testMapSort1() {
var a map[string]int
var b map[int]string a = make(map[string]int, )
b = make(map[int]string, ) a["abc"] =
a["efg"] = for k, v := range a {
b[v] = k
} fmt.Println(b)
} func main() {
//testMapSort()
testMapSort1()
}
Map sort示例
4. 包
(1). golang中的包
a. golang目前有150个标准的包,覆盖了几乎所有的基础库
b. golang.org有所有包的文档,没事都翻翻
(2). 线程同步
a. import("sync")
b. 互斥锁, var mu sync.Mutex
c. 读写锁, var mu sync.RWMutex
1)锁的概念:
什么是锁呢?就是某个协程(线程)在访问某个资源时先锁住,防止其它协程的访问,等访问完毕解锁后其他协程再来加锁进行访问。
2)互斥锁:
每个资源都对应于一个可称为 “互斥锁” 的标记,这个标记用来保证在任意时刻,只能有一个协程(线程)访问该资源。其它的协程只能等待。
注意:在使用互斥锁时,一定要注意:对资源操作完成后,一定要解锁,否则会出现流程执行异常,死锁等问题。通常借助defer。锁定后,立即使用defer语句保证互斥锁及时解锁。如下所示:
var mutex sync.Mutex // 定义互斥锁变量 mutex
func write() {
mutex.Lock( )
defer mutex.Unlock( )
}
互斥锁释放
3)读写锁:
互斥锁的问题:互斥锁的本质是当一个goroutine访问的时候,其他goroutine都不能访问。这样在资源同步,避免竞争的同时也降低了程序的并发性能。程序由原来的并行执行变成了串行执行。真正的互斥应该是读取和修改、修改和修改之间,读和读是没有互斥操作的必要的。因此,衍生出另外一种锁,叫做读写锁。因此,读写锁是针对于读写操作的互斥锁。
基本遵循两大原则:
1、可以随便读。多个goroutin同时读。
2、写的时候,啥都不能干。不能读,也不能写。
package main import (
"fmt"
"math/rand"
"sync"
"sync/atomic"
"time"
) var lock sync.Mutex
var rwLock sync.RWMutex func testMap() {
var a map[int]int
a = make(map[int]int, ) a[] =
a[] =
a[] =
a[] =
a[] = for i := ; i < ; i++ {
go func(b map[int]int) {
lock.Lock()
b[] = rand.Intn()
lock.Unlock()
}(a)
} lock.Lock()
fmt.Println(a)
lock.Unlock() time.Sleep(time.Second)
} func testRWLock() {
var a map[int]int
a = make(map[int]int, )
var count int32
a[] =
a[] =
a[] =
a[] =
a[] = for i := ; i < ; i++ {
go func(b map[int]int) {
//rwLock.Lock()
lock.Lock()
b[] = rand.Intn()
time.Sleep( * time.Millisecond)
lock.Unlock()
//rwLock.Unlock()
}(a)
} for i := ; i < ; i++ {
go func(b map[int]int) {
for {
lock.Lock()
//rwLock.RLock()
time.Sleep(time.Millisecond)
//fmt.Println(a)
//rwLock.RUnlock()
lock.Unlock()
atomic.AddInt32(&count, )
}
}(a)
}
time.Sleep(time.Second * )
fmt.Println(atomic.LoadInt32(&count))
} func main() {
//testMap()
testRWLock()
}
互斥锁及读写锁示例
(3). go get安装第三方包
go get 可以借助代码管理工具通过远程拉取或更新代码包及其依赖包,并自动完成编译和安装。整个过程就像安装一个 App 一样简单。
使用 go get 前,需要安装与远程包匹配的代码管理工具,如 Git、SVN、HG 等,参数中需要提供一个包名。
go get+远程包
默认情况下,go get 可以直接使用。例如,想获取 go 的源码并编译,使用下面的命令行即可:
$ go get github.com/davyxu/cellnet
注意:获取前,请确保 GOPATH 已经设置。Go 1.8 版本之后,GOPATH 默认在用户目录的 go 文件夹下。
5. 排序相关
1). 实现一个冒泡排序
package main
import "fmt"
func bsort(a []int) {
for i := ; i < len(a); i++ {
for j := ; j < len(a)-i; j++ {
if a[j] < a[j-] {
a[j], a[j-] = a[j-], a[j]
}
}
}
}
func main() {
b := [...]int{, , , , , , }
bsort(b[:])
fmt.Println(b)
}
bsort
2). 实现一个选择排序
package main
import "fmt"
func ssort(a []int) {
for i := ; i < len(a); i++ {
var min int = i
for j := i + ; j < len(a); j++ {
if a[min] > a[j] {
min = j
}
}
a[i], a[min] = a[min], a[i]
}
}
func main() {
b := [...]int{, , , , , , }
ssort(b[:])
fmt.Println(b)
}
ssort
3). 实现一个插入排序
package main
import "fmt"
func isort(a []int) {
for i := ; i < len(a); i++ {
for j := i; j > ; j-- {
if a[j] > a[j-] {
break
}
a[j], a[j-] = a[j-], a[j]
}
}
}
func main() {
b := [...]int{, , , , , , }
isort(b[:])
fmt.Println(b)
}
isort
4). 实现一个快速排序
package main
import "fmt"
func qsort(a []int, left, right int) {
if left >= right {
return
}
val := a[left]
k := left
//确定val所在的位置
for i := left + ; i <= right; i++ {
if a[i] < val {
a[k] = a[i]
a[i] = a[k+]
k++
}
}
a[k] = val
qsort(a, left, k-)
qsort(a, k+, right)
}
func main() {
b := [...]int{, , , , , , }
qsort(b[:], , len(b)-)
fmt.Println(b)
}
qsort
参考文献:
- https://www.jianshu.com/p/0cbc97bd33fb(Go语言 异常panic和恢复recover用法)
- https://blog.csdn.net/weixin_42927934/article/details/82533940(读写锁、互斥锁)
- http://c.biancheng.net/view/123.html (go get命令——一键获取代码、编译并安装)
Go语言学习之4 递归&闭包&数组切片&map&锁的更多相关文章
- Go语言学习笔记(三)数组 & 切片 & map
加 Golang学习 QQ群共同学习进步成家立业工作 ^-^ 群号:96933959 数组 Arrays 数组是同一种数据类型的固定长度的序列. 数组是值类型,因此改变副本的值,不会改变本身的值: 当 ...
- golang(4):函数 & 数组 & 切片 & map & 锁
内置函数 // 1. close:主要用来关闭channel // 2. len:用来求长度,比如string.array.slice.map.channel // 3. new:用来分配内存,主要用 ...
- C语言学习018:strdup复制字符串数组
在C语言学习005:不能修改的字符串中我们知道字符串是存储在常量区域的,将它赋值给数组实际是将常量区的字符串副本拷贝到栈内存中,如果将这个数组赋值给指针,我们可以改变数组中的元素,就像下面那样 int ...
- go语言学习-数组-切片-map
数组 go语言中数组的特点: 数组的长度是固定的,并且长度也是数组类型的一部分 是值类型,在赋值或者作为参数传递时,会复制整个数组,而不是指针 定义数组的语法: var arr1 = [5]int{1 ...
- Dart语言学习(六) Dart 列表List数组
创建List : var list = [1,2,3,"Dart",true]; 创建不可变List : var list = const [1,2,3,"Dart&qu ...
- 【C语言学习】-05 二维数组、字符串数组、多维数组
⼆二维数组.字符串数组.多维数组
- R语言学习笔记:矩阵与数组(array)
元素可以保存在多个维度的对象中,数组存储的是多维数据元素,矩阵的是数组的特殊情况,它具有两维. 创建数组的几种方法. 1. > m<-c(45,23,66,77,33,44,56,12,7 ...
- C语言学习笔记 (005) - 二维数组作为函数参数传递剖析
前言 很多文章不外乎告诉你下面这几种标准的形式,你如果按照它们来用,准没错: //对于一个2行13列int元素的二维数组 //函数f的形参形式 f(int daytab[2][13]) {...} / ...
- C语言学习笔记(五) 数组
数组 数组的出现就是为了解决大量同类型数据的存储和使用的问题: 数组的分类:一维数组.二维数组. 一维数组:为多个变量连续分配存储控件:所有的变量的数据类型必须相同:所有变量所占的字节大小必须相等: ...
随机推荐
- SqlBulkCopy类(将一个表插入到数据库)
利用SqlBulkCopy类一次插入多条数据,即将一个表直接插入数据库. 首先,新建一个表,要保证表中的列名与数据库表的字段保持一致. 如果数据库一张TableMenuRole表,ID自增,MenuI ...
- mint-ui之toast使用(messagebox,indicator同理)
toast为消息提示框,支持自定义位置.持续时间和样式. 一,注意事项 方法1 引入整个 Mint UI 组件,并需要再次单独引入Toast组件 Toast,它并不是一个全局变量,需要先引入 im ...
- 【Python56--爬取妹子图】
爬取网站的思路 第一步:首先分析爬取网站的连接地址特性,发现翻页图片的时候连接:http://www.mmjpg.com/mm/1570 ,http://www.mmjpg.com/mm/1569, ...
- [WARNING]: Could not match supplied host pattern, ignoring: servers
Centos7.5 ansible执行命令报错 问题: [root@m01 ~]# ansible servers -a "hostname" [WARNING]: provide ...
- Btrfs管理及应用
一.btrfs基本概念 btrfs文件系统是2007年Oracle开发,支持GPL协议,为了取代Linux早期的ext系列文件系统. btrfs核心特性: 多物理卷支持:btrfs可由多个底层物理卷组 ...
- 牛客竞赛&&mjt的毒瘤赛
题目链接 https://ac.nowcoder.com/acm/contest/368/F 思路 询问可以离线. 然后每个节点上建32个权值线段树(权值不大,其实只要20颗) 记录每一位权值为x(如 ...
- UVA 10382 Watering Grass(区间覆盖,贪心)题解
题意:有一块草坪,这块草坪长l 米,宽 w 米,草坪有一些喷头,每个喷头在横坐标为 p 处,每个喷头的纵坐标都是(w/2) ,并且喷头的洒水范围是一个以喷头为圆心,半径为 r 米的圆.每次最少需要打开 ...
- Concepts-->Migrations
https://flywaydb.org/documentation/migrations Overview With Flyway all changes to the database are c ...
- Video Frame Synthesis using Deep Voxel Flow 论文笔记
Video Frame Synthesis using Deep Voxel Flow 论文笔记 arXiv 摘要:本文解决了模拟新的视频帧的问题,要么是现有视频帧之间的插值,要么是紧跟着他们的探索. ...
- 五、IO编程
input/output:输入.输出 Stream(流):Input Stream就是数据从外面(磁盘.网络)流进内存,Output Stream就是数据从内存流到外面去.(流:相当于管道) 由于CP ...