Hadoop学习笔记之四:HDFS客户端
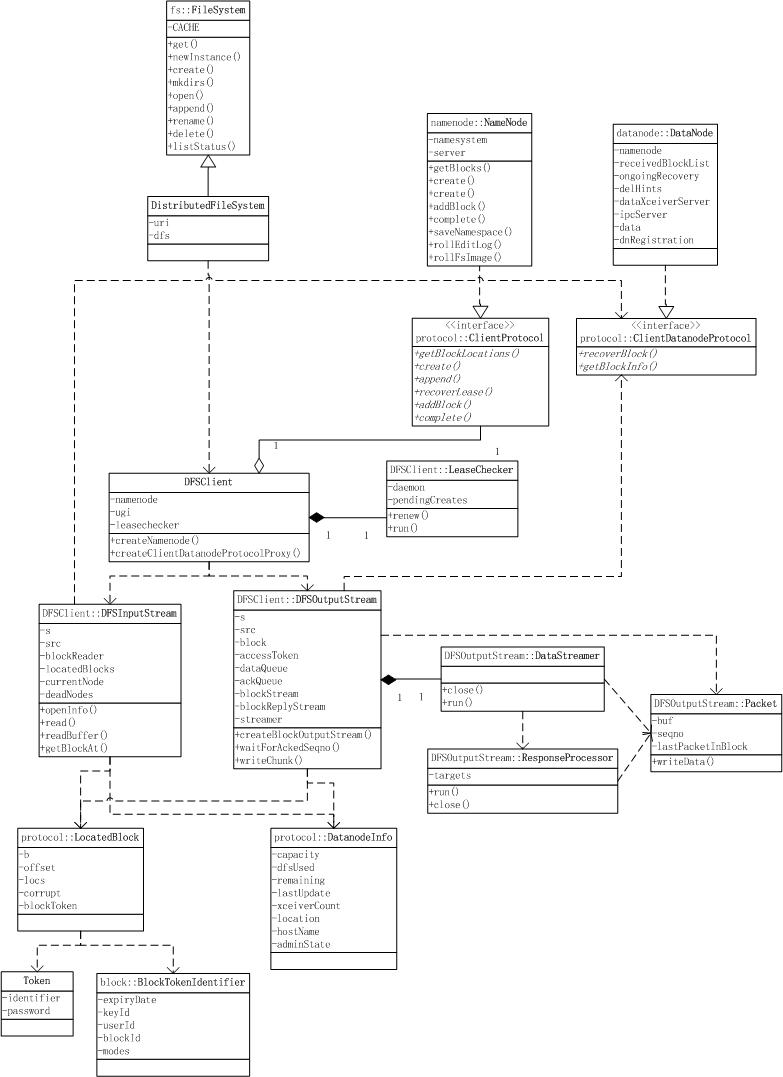
HDFS的客户端核心是DFSClient类,所有使用HDFS的客户端都会持有一个DFSClient对象,或通过持有一个DistributedFileSystem对象间接使用DFSClient;
DFSClient通过ClientProtocol向NameNode进行元数据请求;
当需要进行数据请求时,DFSClient会通过访问的类型(读、写)分别构造DFSInputStream、DFSOutputStream对象;这两个类通过ClientDatanodeProtocol与Datanode进行RPC通信,并通过DatanodeInfo、LocatedBlock对象访问某个Datanode上的某个Block;
写数据前,DFSClient生成相应的Lease信息,添加到LeaseChecker中,由LeaseChecker定期(LEASE_SOFTLIMIT_PERIOD / 2,默认半分钟)进行renew,保证写操作可持续进行;
写数据时,DFSOutputStream通过DataStreamer线程将数据pipeline到指定的多个Datanode上;DataStreamer以Packet为单位进行数据写请求,并通过ResponseProcessor线程处理对Datanode返回的相应Packet的响应;
HDFS写详解
block、packet与chunk
在DFSClient写HDFS的过程中,有三个需要搞清楚的单位:block、packet与chunk;
- block是最大的一个单位,它是最终存储于DataNode上的数据粒度,由dfs.block.size参数决定,默认是64M;注:这个参数由客户端配置决定;
- packet是中等的一个单位,它是数据由DFSClient流向DataNode的粒度,以dfs.write.packet.size参数为参考值,默认是64K;注:这个参数为参考值,是指真正在进行数据传输时,会以它为基准进行调整,调整的原因是一个packet有特定的结构,调整的目标是这个packet的大小刚好包含结构中的所有成员,同时也保证写到DataNode后当前block的大小不超过设定值;
- chunk是最小的一个单位,它是DFSClient到DataNode数据传输中进行数据校验的粒度,由io.bytes.per.checksum参数决定,默认是512B;注:事实上一个chunk还包含4B的校验值,因而chunk写入packet时是516B;数据与检验值的比值为128:1,所以对于一个128M的block会有一个1M的校验文件与之对应;
写过程中的三层buffer
写过程中会以chunk、packet及packet queue三个粒度做三层缓存;
- 首先,当数据流入DFSOutputStream时,DFSOutputStream内会有一个chunk大小的buf,当数据写满这个buf(或遇到强制flush),会计算checksum值,然后填塞进packet;
- 当一个chunk填塞进入packet后,仍然不会立即发送,而是累积到一个packet填满后,将这个packet放入dataqueue队列;
- 进入dataqueue队列的packet会被另一线程按序取出发送到datanode;(注:生产者消费者模型,阻塞生产者的条件是dataqueue与ackqueue之和超过一个block的packet上限)
用图表示如下: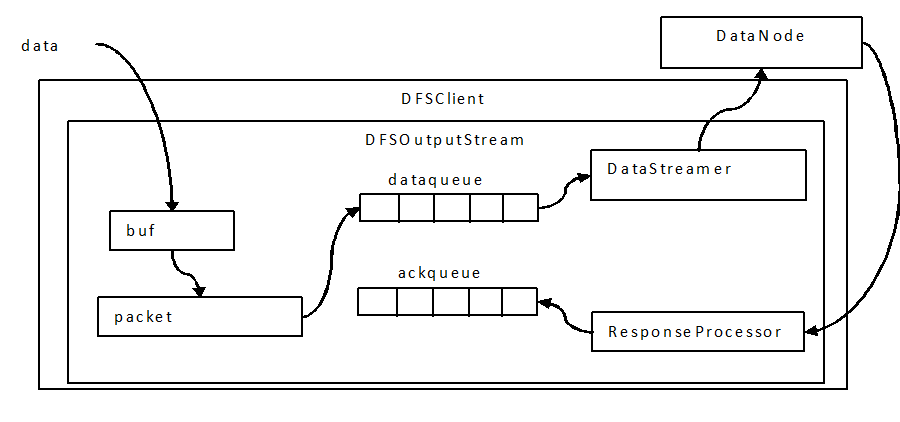
文件的可见性
写一个新文件时,文件元数据在NameNode上以一个临时的INode结构(INodeFileUnderConstruction)存储,这种文件是不可见的,即进行list操作不会被显示。
如果开始写入数据,即产生了block,则这个文件也不能被其它客户端创建。但这是一种临时状态,如果当前创建这个文件的客户端出现异常,该文件迟早会离开不可见状态,该名字空间不会被浪费。
在以下几种情况下,文件会变得可见:
- 文件创建完成,关闭文件;
- 文件写完了一个block;这时虽然文件可见,但数据仅可见已经完成的block;
- 客户端异常关闭,1小时(见Lease(租约)的“租约释放”部分)后该文件可见;或在1分钟后,虽然该文件仍不可见,但可以进行追加数据;此后文件的可见性由新的客户端行为决定;
注:未关闭、已经写入数据但未完成一个block的文件,在原客户端异常关闭后的1分钟内处于不可见不可写状态;
数据可见性与sync
DFSOutputStream提供sync接口,然而其无法做到通常sync需要达到的数据可见性要求,即语义不同,为此,hadoop 0.23以后该接口改名为hflush。
在写数据过程中,上层的写请求数据不断进入三层缓存;如果这时上层请求了一个sync操作,则当前缓存内的所有数据会要求立即向下flush,这个意思是:
- buf中的数据立即完结成一个chunk,填塞到当前正在写的packet中;
- 当前的packet立即进入dataqueue队列,等待被发送;
每个packet都有一个递增的序列号,sync请求会阻塞等待直到ackqueue中包含了该序列号,即该packet得到了应答才会返回;如果当前正在写的block还没有被NameNode记录过(在edits中),则请求返回前还会要求NameNode将该block进行记录。
因为没有要求DataNode做任何的数据刷新操作,因而不保证数据可见;
Hadoop学习笔记之四:HDFS客户端的更多相关文章
- Hadoop学习笔记: HDFS
注:该文内容部分来源于ChinaHadoop.cn上的hadoop视频教程. 一. HDFS概述 HDFS即Hadoop Distributed File System, 源于Google发表于200 ...
- Hadoop学习笔记(2)-HDFS的基本操作(Shell命令)
在这里我给大家继续分享一些关于HDFS分布式文件的经验哈,其中包括一些hdfs的基本的shell命令的操作,再加上hdfs java程序设计.在前面我已经写了关于如何去搭建hadoop这样一个大数据平 ...
- hadoop学习笔记贰 --HDFS及YARN的启动
1.初始化HDFS :hadoop namenode -format 看到如下字样,说明初始化成功. 启动HDFS,start-dfs.sh 终于启动成功了,原来是core-site.xml 中配置 ...
- Hadoop学习笔记(三) ——HDFS
参考书籍:<Hadoop实战>第二版 第9章:HDFS详解 1. HDFS基本操作 @ 出现的bug信息 @-@ WARN util.NativeCodeLoader: Unable to ...
- hadoop学习笔记(四):HDFS文件权限,安全模式,以及整体注意点总结
本文原创,转载注明作者和原文链接! 一:总结注意点: 到现在为止学习到的角色:三个NameNode.SecondaryNameNode.DataNode 1.存储的是每一个文件分割存储之后的元数据信息 ...
- Hadoop学习笔记—22.Hadoop2.x环境搭建与配置
自从2015年花了2个多月时间把Hadoop1.x的学习教程学习了一遍,对Hadoop这个神奇的小象有了一个初步的了解,还对每次学习的内容进行了总结,也形成了我的一个博文系列<Hadoop学习笔 ...
- Hadoop学习笔记(2)
Hadoop学习笔记(2) ——解读Hello World 上一章中,我们把hadoop下载.安装.运行起来,最后还执行了一个Hello world程序,看到了结果.现在我们就来解读一下这个Hello ...
- Hadoop学习笔记(2) ——解读Hello World
Hadoop学习笔记(2) ——解读Hello World 上一章中,我们把hadoop下载.安装.运行起来,最后还执行了一个Hello world程序,看到了结果.现在我们就来解读一下这个Hello ...
- [转帖]hadoop学习笔记:hadoop文件系统浅析
hadoop学习笔记:hadoop文件系统浅析 https://www.cnblogs.com/sharpxiajun/archive/2013/06/15/3137765.html 1.什么是分布式 ...
随机推荐
- 查看win10版本方法,及win10升级方法
点击左下角开始图标. 找到并点击左下方设置(齿轮形的图案). 点左上方的系统(笔记本电脑图案). 在左下方 点击关于.找到windows规格. 带大家解读Windows10的规格: 专业版功能较多 ...
- vue/cli3 配置vux
安装各插件 试过 安装“必须安装”的部分亦可 1.安装vuex npm install vuex --save-dev 2.在项目里面安装vux[必须安装] npm install vux --sav ...
- 遮罩层出现后不能滚动 添加事件@touchmove.prevent
<div class="maskshow" @click="hidden_video" @touchmove.prevent></div> ...
- 【Redis】持久化
Redis提供了为持久化提供了两种方法:第一种是快照:他可以将存在某一时刻的所有数据都写入硬盘里面.第二种是只追加文件(AOF):它会在执行命令时,将被执行的写命令复制到硬盘里面. Redis支持持久 ...
- Selenium基础知识(七)弹出框处理
使用switch_to.alert方法来处理弹页面弹出的警告框 页面常见警告框种类:alert/confirm 确认框/prompt switch_to.alert().accept() switch ...
- Ireport第一张web项目报表。
原先项目里面的统计分析报表都是和普通的系统页面一样开发的,SSM架构,从数据库一层一层往前面传数据,最后通过jsp表现出来,这次在领导的建议下使用IReport进行报表开发,果然还是要使用工具啊,社会 ...
- Css预处理器---Less(二)
三.Less语法 (1)变量 //less代码 @nice-blue : #5B83AD; @light-blue : @nice-blue + #111; #header { color : @li ...
- SQL Server数据库(时间戳timestamp)类型
1.公开数据库中自动生成的唯一二进制数字的数据类型. 2.timestamp 通常用作给表行加版本戳的机制. 3.存储大小为 8 个字节. 不可为空的 timestamp 列在语义上等价于 binar ...
- VS编译后直接复制DLL库文件到其他目录下
项目目录:SourceCode\公共组件\KApiClient\ 要复制的目的目录: SourceCode\公共组件\DllLibrary\ApiClient 则在项目 KApiClient下添加如下 ...
- 一 js数据类型
一.简单的数据对象 ------1.小数 var fNum = 1.02; ------2.整数 var iNum = 1; ------3.逻辑变量 var bNum = true; 二.复杂的数据 ...