进程表示之进程ID号
UNIX进程总是会分配一个号码用于在其命名空间总唯一地标识它们,该号码称作进程ID号,简称PID。
1、进程ID
但每个进程除了PID外,还有其他的ID,有下列几种可能的类型:
(1)处于某个线程组中的所有进程都有统一的线程组ID(TGID)。若进程没有使用线程,则其PID和TGID相同。线程组中主进程被称作组长(group leader)。通过clone创建的所有线程的task_struct的group_leader成员,会指向组长task_struct实例。
(2)独立进程可以合并为进程组(使用setpgrp系统调用)。进程组简化了向组的所有成员发送信号的操作,有助于各种系统程序设计应用,用管道连接的进程包含在同一个进程组。
(3)几个进程组可以合并为一个会话。会话中所有进程都有同样的会话ID,保存在task_struct的session中。SID可通过setsid系统调用设置。用于终端程序设计。
2、全局ID和局部ID
PID Namespace使得父命名空间可以看见所有子命名空间PID,但子命名空间无法看到父命名空间的PID,这意味着某些进程具有多个PID,凡可以看到该进程的命名空间,都会为其分配一个PID,由此需要区分全局ID和局部ID:
(1)全局ID:在内核本身和初始命名空间的唯一ID号,在系统启动期间开始的init进程即属于初始命名空间。对每个ID类型,都有一个给定的全局ID,保证在整个系统中是唯一的。
(2)局部ID:属于某个特定命名空间,不具备全局有效性。
3、数据结构
首先给出一个总图,其中红线是结构描述,黑线是指向。其中进程A,B,C是一个进程组的,A是组长进程,所以B和C的task_struct结构体中的pid_link成员的node字段就被邻接到进程A对应的struct pid中的tasks[1]。
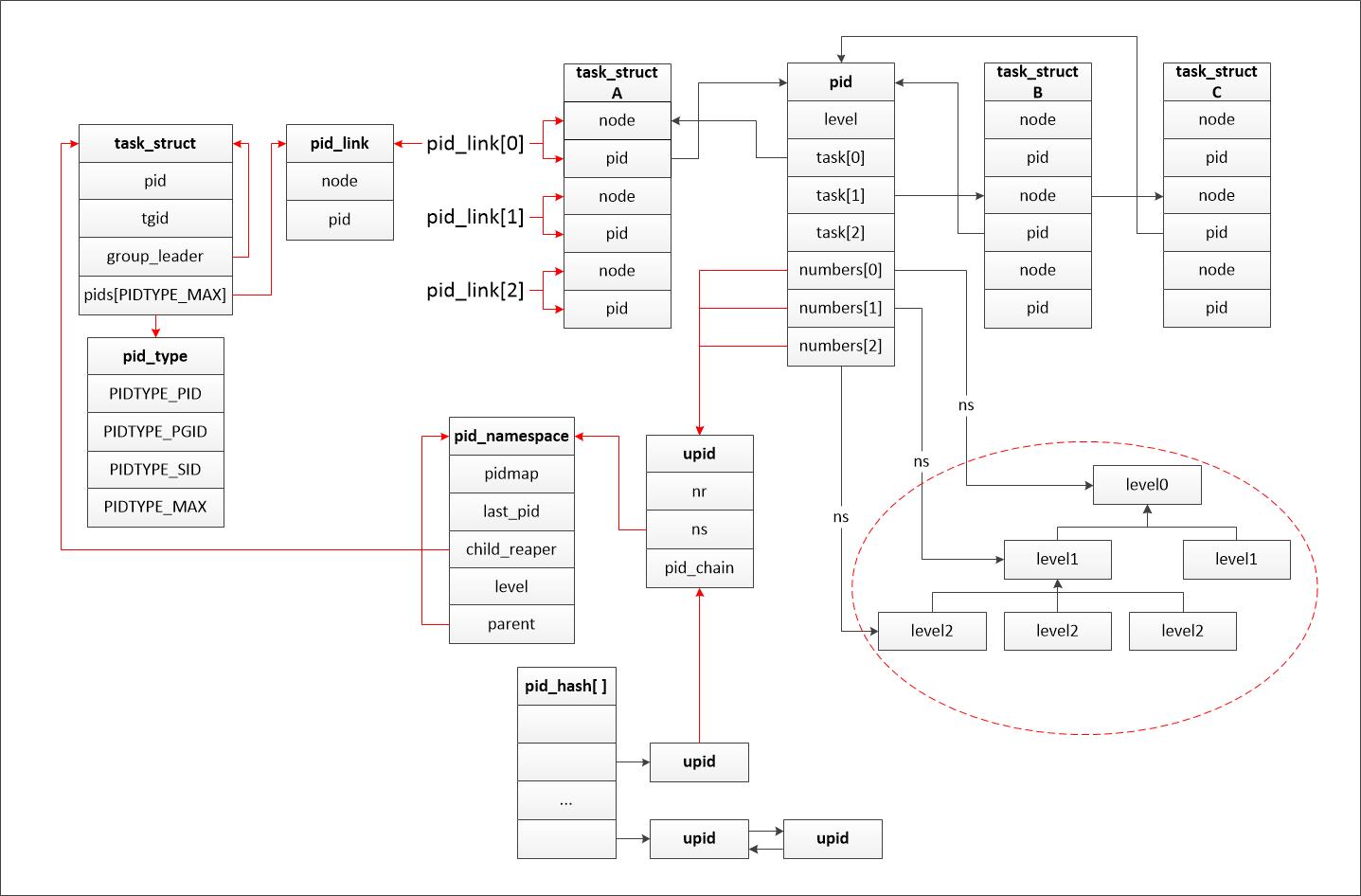
以下用ID指代提到的任何进程ID。
struct task_struct {
...
pid_t pid; //全局PID
pid_t tgid; //线程组ID
struct task_struct *group_leader; //指向线程组组长task_struct实例
struct pid_link pids[PIDTYPE_MAX]; //PID和PID散列表的联系,将所有共享同一ID的task_struct实例都按进程存储在一个散列表中
...
};
其中PIDTYPE_MAX表示ID类型的数目,枚举类型中定义的ID类型不包括线程组ID,因为线程组ID即为线程组组长的PID:
enum pid_type
{
PIDTYPE_PID,
PIDTYPE_PGID,
PIDTYPE_SID,
PIDTYPE_MAX
};
task_struct中的辅助结构pid_link可以将task_struct连接到表头在struct pid中的散列表上:
struct pid_link
{
struct hlist_node node; //散列表元素
struct pid *pid; //指向进程所属pid结构实例
};
为了在给定命名空间中查找对应于指定PID数值的pid结构实例,使用了一个散列表:static struct hlist_head *pid_hash; hlist_head是内核标准数据结构,用于建立双链散列表。
假如已经分配了struct pid的一个新实例,并设置用于给定的ID类型。它会通过如下附加到task_struct(kernel/pid.c):
void attach_pid(struct task_struct *task, enum pid_type type,
struct pid *pid)
{
struct pid_link *link; link = &task->pids[type];
link->pid = pid;
hlist_add_head_rcu(&link->node, &pid->tasks[type]);
}
这里建立双向链表:task_struct可以通过task_struct->pids[type]->pid访问pid实例;而从pid实例开始,可以遍历task[type]散列表找到task_struct。hlist_add_head_rcu是遍历散列表的标准函数。
PID的管理围绕两个数据结构:struct pid是内核对PID的内部表示,struct upid表示特定的命名空间中可见的信息:
struct pid
{ //内核对PID的内部表示
atomic_t count; //引用计数
unsigned int level; //这个pid所在的层级
/* 使用该pid的进程的列表 */
struct hlist_head tasks[PIDTYPE_MAX]; //每个数组项都是一个散列表表头,对应一个ID类型。因为一个ID可能用于几个进程,所有共享同一给定ID的task_struct实例,都通过该列表连接起来
struct rcu_head rcu;
struct upid numbers[]; //这个pid对应的命名空间,一个pid不仅要包含当前的pid,还要包含父命名空间,默认大小为1,所以就处于根命名空间中,可添加附加项扩充
};
struct upid { //包装命名空间所抽象出来的一个结构体
/* Try to keep pid_chain in the same cacheline as nr for find_vpid */
int nr; //pid在该命名空间中的pid数值
struct pid_namespace *ns; //对应的命名空间
struct hlist_node pid_chain; //通过pidhash将一个pid对应的所有的命名空间连接起来(所有upid实例被保存在一个散列表中)
};
struct pid_namespace {
struct kref kref;
struct pidmap pidmap[PIDMAP_ENTRIES]; //一个pid命名空间应该有其独立的pidmap
int last_pid; //上次分配的pid
unsigned int nr_hashed;
struct task_struct *child_reaper; //每个PID命名空间都需要一个作用相当于全局init进程的进程,init的一个目的是对孤儿进程调用wait4,此保存了指向该进程的task_struct的指针
struct kmem_cache *pid_cachep;
unsigned int level; //所在的命名空间层次,初始为0,子空间level为1。level较高命名空间的PID对level较低的命名空间的PID是可见的,从给定level设置,可知进程会关联多少个PID
struct pid_namespace *parent; //指向父命名空间,构建命名空间的层次关系
...
};
4、函数操作
本质上内核需要完成两个任务:
(1)给出局部数字ID和对应命名空间,查找此二元组描述的task_struct。
(2)给出task_struct、ID类型、命名空间,取得命名空间局部数组ID。
对于(1)分解为两步:
a.由局部PID和ns,确定pid实例。内核采用标准散列方式,首先,根据PID和ns指针计算在pid_hash数组中索引,然后遍历散列表直至找到所要的upid实例,而由于这些实例直接包含在struct pid中,所以通过使用container_of机制可推断出pid实例(kernel/pid.c):
struct pid *find_pid_ns(int nr, struct pid_namespace *ns)
{
struct upid *pnr; hlist_for_each_entry_rcu(pnr,
&pid_hash[pid_hashfn(nr, ns)], pid_chain)
if (pnr->nr == nr && pnr->ns == ns)
return container_of(pnr, struct pid,
numbers[ns->level]); return NULL;
}
b.pid_task取出pid->task[type]散列表中的第一个task_struct实例(kernel/pid.c):
struct task_struct *find_task_by_pid_ns(pid_t nr, struct pid_namespace *ns)
{
rcu_lockdep_assert(rcu_read_lock_held(),
"find_task_by_pid_ns() needs rcu_read_lock()"
" protection");
return pid_task(find_pid_ns(nr, ns), PIDTYPE_PID);
}
对于(2)也分为两步:
a.获得与task_struct关联的pid实例:
static inline struct pid *task_pid(struct task_struct *task)
{
return task->pids[PIDTYPE_PID].pid;
}
还可通过task_tgid、task_pgrp和task_session分别用于取得不同类型的ID:
static inline struct pid *task_tgid(struct task_struct *task)
{
return task->group_leader->pids[PIDTYPE_PID].pid;
}
static inline struct pid *task_pgrp(struct task_struct *task)
{
return task->group_leader->pids[PIDTYPE_PGID].pid;
}
b.从struct pid的numbers数组中upid信息,即可获得数字ID:
pid_t pid_nr_ns(struct pid *pid, struct pid_namespace *ns)
{
struct upid *upid;
pid_t nr = ; if (pid && ns->level <= pid->level) { //由于父ns可以看到子ns的PID,反过来不行,内核必须确保当前ns的level小于或等于产生局部ID的ns的level
upid = &pid->numbers[ns->level];
if (upid->ns == ns)
nr = upid->nr;
}
return nr;
}
以下函数用于返回该ID所属的ns所看到的局部PID:
pid_t pid_vnr(struct pid *pid)
{
return pid_nr_ns(pid, task_active_pid_ns(current));
}
5、生成唯一PID
在建立一个新进程时,进程可能在多个ns中可见,对每个这样的ns,都需要生成一个局部ID:
struct pid *alloc_pid(struct pid_namespace *ns)
{ //pid分配要依赖与pid namespace,也就是说这个pid是属于哪个pid namespace
struct pid *pid;
enum pid_type type;
int i, nr;
struct pid_namespace *tmp;
struct upid *upid; pid = kmem_cache_alloc(ns->pid_cachep, GFP_KERNEL); //分配一个pid结构
if (!pid)
goto out; tmp = ns;
pid->level = ns->level; //初始化level
for (i = ns->level; i >= ; i--) { //递归到上面的层级进行pid的分配和初始化
nr = alloc_pidmap(tmp); //从当前pid namespace开始直到全局pid namespace,每一个层级都分配一个pid
if (nr < )
goto out_free; pid->numbers[i].nr = nr; //初始化upid结构
pid->numbers[i].ns = tmp;
tmp = tmp->parent; //递归到父亲pid namespace
} if (unlikely(is_child_reaper(pid))) { //如果是init进程需要做一些设定,为其准备proc目录
if (pid_ns_prepare_proc(ns))
goto out_free;
} get_pid_ns(ns);
atomic_set(&pid->count, );
for (type = ; type < PIDTYPE_MAX; ++type) //初始化pid中的hlist结构
INIT_HLIST_HEAD(&pid->tasks[type]); upid = pid->numbers + ns->level; //定位到当前namespace的upid结构
spin_lock_irq(&pidmap_lock);
if (!(ns->nr_hashed & PIDNS_HASH_ADDING))
goto out_unlock;
for ( ; upid >= pid->numbers; --upid) {
hlist_add_head_rcu(&upid->pid_chain,
&pid_hash[pid_hashfn(upid->nr, upid->ns)]); //建立pid_hash,让pid和pid namespace关联起来
upid->ns->nr_hashed++;
}
spin_unlock_irq(&pidmap_lock); out:
return pid; out_unlock:
spin_unlock_irq(&pidmap_lock);
out_free:
while (++i <= ns->level)
free_pidmap(pid->numbers + i); kmem_cache_free(ns->pid_cachep, pid);
pid = NULL;
goto out;
}
参考:
linux-3.10.1内核源码
《深入Linux内核架构》
https://blog.csdn.net/zhangyifei216/article/details/49926459
进程表示之进程ID号的更多相关文章
- Win32进程创建、进程快照、进程终止用例
进程创建: 1 #include <windows.h> #include <stdio.h> int main() { // 创建打开系统自带记事本进程 STARTUPINF ...
- [并发编程 - socketserver模块实现并发、[进程查看父子进程pid、僵尸进程、孤儿进程、守护进程、互斥锁、队列、生产者消费者模型]
[并发编程 - socketserver模块实现并发.[进程查看父子进程pid.僵尸进程.孤儿进程.守护进程.互斥锁.队列.生产者消费者模型] socketserver模块实现并发 基于tcp的套接字 ...
- Linux进程ID号--Linux进程的管理与调度(三)【转】
Linux 内核使用 task_struct 数据结构来关联所有与进程有关的数据和结构,Linux 内核所有涉及到进程和程序的所有算法都是围绕该数据结构建立的,是内核中最重要的数据结构之一. 该数据结 ...
- Linux进程ID号--Linux进程的管理与调度(三)
转自:http://blog.csdn.net/gatieme/article/category/6225543 日期 内核版本 架构 作者 GitHub CSDN 2016-05-12 Linux- ...
- pidof---查找指定名称的进程的进程号id号。
pidof命令用于查找指定名称的进程的进程号id号. 语法 pidof(选项)(参数) 选项 -s:仅返回一个进程号: -c:仅显示具有相同“root”目录的进程: -x:显示由脚本开启的进程: -o ...
- python获取进程id号:
python获取进程id号: os.getpid()获取当前进程id os.getppid()获取父进程id
- Linux进程的实际用户ID和有效用户ID
转自:https://blog.csdn.net/hulifangjiayou/article/details/47400943 在Linux中,每个文件都有其所属的用户和用户组,默认情况下是文件的创 ...
- Linux下2号进程的kthreadd--Linux进程的管理与调度(七)
2号进程 内核初始化rest_init函数中,由进程 0 (swapper 进程)创建了两个process init 进程 (pid = 1, ppid = 0) kthreadd (pid = 2, ...
- 进程的基本属性:进程ID、父进程ID、进程组ID、会话和控制终端
摘要:本文主要介绍进程的基本属性,基本属性包含:进程ID.父进程ID.进程组ID.会话和控制终端. 进程基本属性 1.进程ID(PID) 函数定义: #include <sys/typ ...
随机推荐
- 如何将文章列表用<li>分两列显示
我们平时用ul或ol标签来罗列文章列表时默认是一列,为了美观起见,想把它们两列显示要如何操作呢?怎么用css定义它们? 其实相对比较简单,用几行css样式定义一下就够了,可以用div + css来控制 ...
- Python3学习之路~5.5 sys模块
用于提供对解释器相关的操作 sys.argv 命令行参数List,第一个元素是程序本身路径 sys.exit(n) 退出程序,正常退出时exit(0) sys.version 获取Python解释程序 ...
- 【C++问题整理】
一.static 1.作用: 静态变量/函数:在整个文件内可见,不会被其他文件所用:静态变量:会被自动初始化为0: 类中的静态变量:类的成员,类对象公用 类中的静态函数:只能访问静态变量 2 ...
- NYOJ 方案数量
1.递归求解(直接递归会超时,要用备忘录法) # include<iostream> # include<stdio.h> #include <map> using ...
- [django]restfulapi请求规范
http://www.ruanyifeng.com/blog/2014/05/restful_api.html 方法及作用: GET(SELECT) :从服务器取出资源(一项或多项). POST(CR ...
- IOP知识点(2)
1 URL资源访问不足时,需要添加URL权限 2 重定向问题解决办法:3 cloud-service-factory 项目 gradlew方法 1 URL资源访问不足时,需要添加URL权 ...
- Centos7系统防火墙上开端口
//permanent 永久生效 没有此参数重启失效 firewall -cmd --zone=public --add -port=80/tcp --permanent //开 ...
- JS通过类名判断是否都必填
//判断class='required' 是否都必填 function required() { var flag = true; $(".required").each(func ...
- max_execution_time with sleep
Under Linux, sleeping time is ignored, but under Windows, it counts as execution time. Note The set_ ...
- Xcode 常用命令
一些自己在开发过程中总结的命令,并不是完整的,会不断的更新. 1.图片转png格式 sips -s format png start.jpg --out StartBg.png 转换时,先cd 当前图 ...