dense prediction
Dense prediction
- fully convolutional network for sementic segmentation
先用feature extractor 提特征,然后再使用加入upsample层,得到dense prediction。
这里的‘deconvolution’其实不是真正的反卷积。 作者给出了几种方案, 实际中使用‘transposed convolution’(在matconvnet 中就叫convtranspose),转置卷积只是恢复了其形状,并未对其值进行恢复,这也是为什么将其称为反卷积不合适的原因了
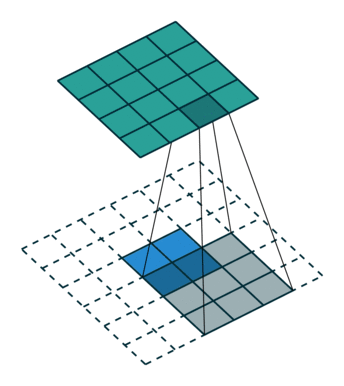
No zero padding,uint stride: 理解为正向卷积padding 为0.转置卷积为full padding
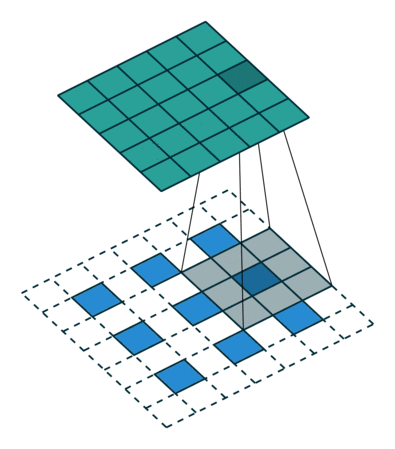
Fractional Strided Convolution:使用大于1的stride(对于正向卷积) 来upsampleing,fractional stride convolution 微步卷积。带洞是为了使转置卷积的步长变为正向卷积的1/i倍。
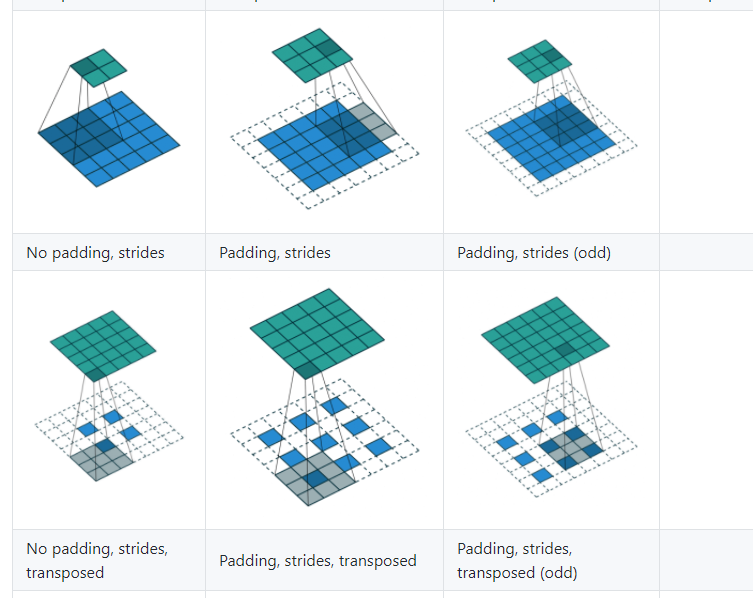
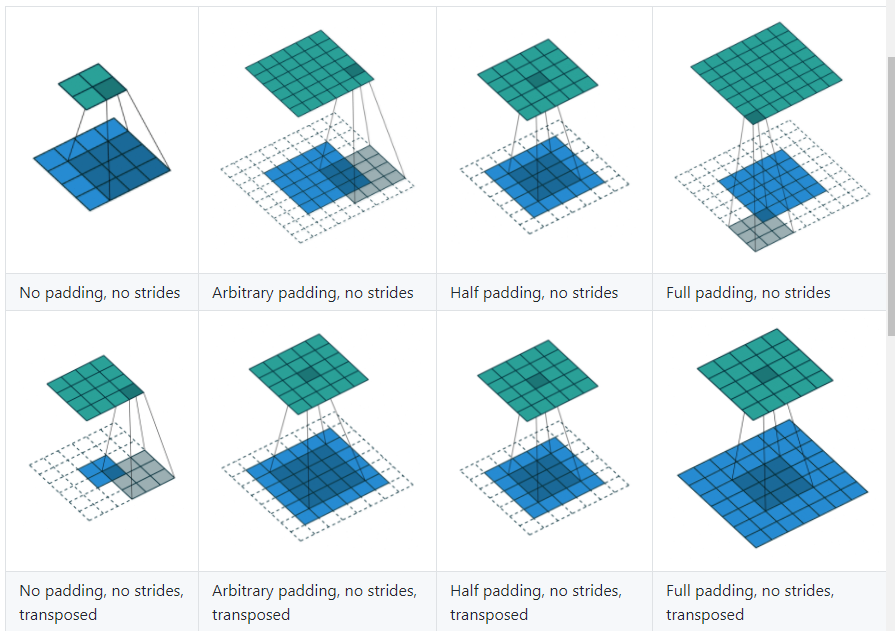
参考: https://github.com/vdumoulin/conv_arithmetic

什么是真正的deconvolution?
针对直接upsample的结果不好的情况,使用浅层特征进行辅助。但是对于小的目标依然有检测不到的情况,对于大目标又检测不对。
- accurate image super-resolution using very deep convolutional network
网络中全部使用卷积层,只用了一个尺度。可能对于超分辨还行,因为每个像素只与周围的几个像素有关(其实不太懂)
dense prediction的更多相关文章
- dense prediction问题
dense prediction 理解:标注出图像中每个像素点的对象类别,要求不但给出具体目标的位置,还要描绘物体的边界,如图像分割.语义分割.边缘检测等等. 基于深度学习主要的做法有两种: 基于图 ...
- Anchor-free目标检测综述 -- Dense Prediction篇
早期目标检测研究以anchor-based为主,设定初始anchor,预测anchor的修正值,分为two-stage目标检测与one-stage目标检测,分别以Faster R-CNN和SSD作 ...
- 论文阅读(Xiang Bai——【arXiv2016】Scene Text Detection via Holistic, Multi-Channel Prediction)
Xiang Bai--[arXiv2016]Scene Text Detection via Holistic, Multi-Channel Prediction 目录 作者和相关链接 方法概括 创新 ...
- Fully Convolutional Networks for semantic Segmentation(深度学习经典论文翻译)
摘要 卷积网络在特征分层领域是非常强大的视觉模型.我们证明了经过端到端.像素到像素训练的卷积网络超过语义分割中最先进的技术.我们的核心观点是建立"全卷积"网络,输入任意尺寸,经过有 ...
- 大规模视觉识别挑战赛ILSVRC2015各团队结果和方法 Large Scale Visual Recognition Challenge 2015
Large Scale Visual Recognition Challenge 2015 (ILSVRC2015) Legend: Yellow background = winner in thi ...
- 论文笔记:Fast Neural Architecture Search of Compact Semantic Segmentation Models via Auxiliary Cells
Fast Neural Architecture Search of Compact Semantic Segmentation Models via Auxiliary Cells 2019-04- ...
- OSVOS 半监督视频分割入门论文(中文翻译)
摘要: 本文解决了半监督视频目标分割的问题.给定第一帧的mask,将目标从视频背景中分离出来.本文提出OSVOS,基于FCN框架的,可以连续依次地将在IMAGENET上学到的信息转移到通用语义信息,实 ...
- 论文阅读笔记六:FCN:Fully Convolutional Networks for Semantic Segmentation(CVPR2015)
今天来看一看一个比较经典的语义分割网络,那就是FCN,全称如题,原英文论文网址:https://people.eecs.berkeley.edu/~jonlong/long_shelhamer_fcn ...
- 人工智能必须要知道的语义分割模型:DeepLabv3+
图像分割是计算机视觉中除了分类和检测外的另一项基本任务,它意味着要将图片根据内容分割成不同的块.相比图像分类和检测,分割是一项更精细的工作,因为需要对每个像素点分类,如下图的街景分割,由于对每个像素点 ...
随机推荐
- SAP字体调节大小
登陆SAP 之后,菜单下面一行,最右边的那个彩色按钮(SAP GUI),点击“选项”-可视设计-字体设计-固定狂赌字体设计,点击:选择字体 即可.
- loadrunner基础学习笔记三
运行时设置: 打开运行时设置:任务窗格中-选择回放-点击运行时设置按钮 1 重复执行次数:=2 2 步:控制迭代时间间隔 3 日志设置:指出要在运行测试期间记录的信息量 4 思考时间:可以在cont ...
- 今天看到了一篇文档 app 测试内容记录下来
1 APP测试基本流程 1.1流程图 1.2测试周期 测试周期可按项目的开发周期来确定测试时间,一般测试时间为两三周(即15个工作日),根据项目情况以及版本质量可适当缩短或延长测试时间.正式测试前先向 ...
- html的表格 table
創建表格: 每一個表格以table開始: 每一個表格行以tr開始: 每一個數據以td開始:td的內容可以文本.圖像.表格.表單.段落等. 表格邊框: border設置邊框的粗細,但無法設置行間距,也無 ...
- 使用pygal_maps_world.i18n中数据画各大洲地图
源码: # 使用pygal_maps_world.i18n中数据画各大洲地图 from pygal_maps_world.i18n import ASIA from pygal_maps_world ...
- Gulp实现静态网页模块化的方法详解
前言: 在做纯静态页面开发的过程中,难免会遇到一些的尴尬问题.比如:整套代码有50个页面,其中有40个页面顶部和底部模块相同.那么同样的两段代码我们复制了40遍(最难受的方法).然后,这个问题就这样解 ...
- 51nod 1092(lcs)回文字符串
题目:给你一个字符串,问添加最少的字符数目,使之成为回文串 解题思路:将字符串倒置,求出字符串和倒置串的最长公共子序列,字符串的长度减去lcs的长度就是了.. 代码:#include<iostr ...
- 构建squid代理服务器
基本概念 本文使用squid代理服务 软件介绍:百度百科 作为应用层的代理服务软件,Squid主要提供缓存加速.应用层过滤控制的功能: 工作机制:缓存网页对象,减少重复请求(HTTP代理的缓存加速对象 ...
- Maven整理
第一章 Maven安装 1.1 下载Maven库 下载地址:http://maven.apache.org/download.cgi 1.2 解压下载的库,认识Maven库目录 备注: 解压文件尽量不 ...
- tmux的使用
tmux的使用 1: tmux的介绍 tmux是一个优秀的终端多路复用软件,类似GNU Screen,但来自于OpenBSD,采用BSD授权.使用它最直观的好处就是,通过一个终端登录远程主机并 ...