scrapy-redis(一)
安装scrapy-redis
pip install scrapy-redis
从GitHub 上拷贝源码:
clone github scrapy-redis源码文件 git clone https://github.com/rolando/scrapy-redis.git
scrapy-redis的工作流程
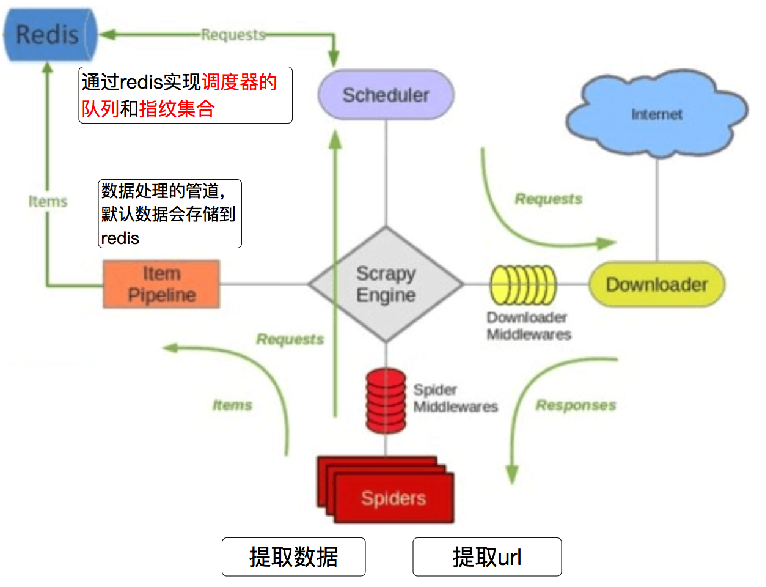
Scrapy_redis之domz 例子分析
1.domz爬虫:

2.配置中:

3.执行domz的爬虫,会发现redis中多了一下三个键

redispipeline中仅仅实现了item数据存储到redis的过程,我们可以新建一个pipeline(或者修改默认的ExamplePipeline),可以让数据存储到任意地方。
scrapy-redis 的源码分析
1.Scrapy_redis之RedisPipeline

2.Scrapy_redis之RFPDupeFilter

3.Scrapy_redis之Scheduler

domz相比于之前的spider多了持久化和request去重的功能,setting中的配置都是可以自己设定的,
意味着我们的可以重写去重和调度器的方法,包括是否要把数据存储到redis(pipeline)
1.Scrapy_redis之RedisSpider

2. Scrapy_redis之RedisCrawlSpider

scrapy-redis 配置:
在爬虫项目的settings.py文件中,可以做一下配置
# ####################### redis配置文件 #######################
REDIS_HOST = '192.168.11.81' # 主机名
REDIS_PORT = 6379 # 端口
# REDIS_URL = 'redis://user:pass@hostname:9001' # 连接URL(优先于以上配置)
# REDIS_PARAMS = {} # Redis连接参数 默认:REDIS_PARAMS = {'socket_timeout': 30,'socket_connect_timeout': 30,'retry_on_timeout': True,'encoding': REDIS_ENCODING,})
# REDIS_PARAMS['redis_cls'] = 'myproject.RedisClient' # 指定连接Redis的Python模块 默认:redis.StrictRedis
REDIS_ENCODING = "utf-8" # redis编码类型 默认:'utf-8' # df
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter" # 也可以自定义自己的去重规则 from scrapy_redis.scheduler import Scheduler
SCHEDULER = "scrapy_redis.scheduler.Scheduler" # 调度器 from scrapy_redis.queue import PriorityQueue
from scrapy_redis import picklecompat
SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.PriorityQueue' # 默认使用优先级队列(默认),其他:PriorityQueue(有序集合),FifoQueue(列表)、LifoQueue(列表)
SCHEDULER_QUEUE_KEY = '%(spider)s:requests' # 调度器中请求存放在redis中的key
SCHEDULER_SERIALIZER = "scrapy_redis.picklecompat" # 对保存到redis中的数据进行序列化,默认使用pickle
SCHEDULER_PERSIST = True # 是否在关闭时候保留原来的调度器和去重记录,True=保留,False=清空
SCHEDULER_FLUSH_ON_START = False # 是否在开始之前清空 调度器和去重记录,True=清空,False=不清空
SCHEDULER_IDLE_BEFORE_CLOSE = 10 # 去调度器中获取数据时,如果为空,最多等待时间(最后没数据,未获取到)。
SCHEDULER_DUPEFILTER_KEY = '%(spider)s:dupefilter' # 去重规则,在redis中保存时对应的key
SCHEDULER_DUPEFILTER_CLASS = 'scrapy_redis.dupefilter.RFPDupeFilter' # 去重规则对应处理的类 from scrapy_redis.pipelines import RedisPipeline ITEM_PIPELINES = {
'scrapy_redis.pipelines.RedisPipeline': 300,
}
REDIS_ITEMS_KEY = '%(spider)s:items'
REDIS_ITEMS_SERIALIZER = 'json.dumps'
Crontab爬虫定时执行


Scrapy-redis 中的知识总结
request对象什么时候入队
dont_filter = True ,构造请求的时候,把dont_filter置为True,该url会被反复抓取(url地址对应的内容会更新的情况)
一个全新的url地址被抓到的时候,构造request请求
url地址在start_urls中的时候,会入队,不管之前是否请求过
构造start_url地址的请求时候,dont_filter = True
def enqueue_request(self, request):
if not request.dont_filter and self.df.request_seen(request):
# dont_filter=False Ture True request指纹已经存在 #不会入队
# dont_filter=False Ture False request指纹已经存在 全新的url #会入队
# dont_filter=Ture False #会入队
self.df.log(request, self.spider)
return False
self.queue.push(request) #入队
return True
scrapy_redis去重方法
使用sha1加密request得到指纹
把指纹存在redis的集合中
下一次新来一个request,同样的方式生成指纹,判断指纹是否存在reids的集合中
生成指纹
fp = hashlib.sha1()
fp.update(to_bytes(request.method)) #请求方法
fp.update(to_bytes(canonicalize_url(request.url))) #url
fp.update(request.body or b'') #请求体
return fp.hexdigest()
判断数据是否存在redis的集合中,不存在插入
added = self.server.sadd(self.key, fp)
return added != 0
scrapy-redis(一)的更多相关文章
- 基于Python,scrapy,redis的分布式爬虫实现框架
原文 http://www.xgezhang.com/python_scrapy_redis_crawler.html 爬虫技术,无论是在学术领域,还是在工程领域,都扮演者非常重要的角色.相比于其他 ...
- Scrapy+redis实现分布式爬虫
概述 什么是分布式爬虫 需要搭建一个由n台电脑组成的机群,然后在每一台电脑中执行同一组程序,让其对同一网络资源进行联合且分布的数据爬取. 原生Scrapy无法实现分布式的原因 原生Scrapy中调度器 ...
- scrapy+redis去重实现增量抓取
class ProjectnameDownloaderMiddleware(object): # Not all methods need to be defined. If a method is ...
- 爬虫--scrapy+redis分布式爬取58同城北京全站租房数据
作业需求: 1.基于Spider或者CrawlSpider进行租房信息的爬取 2.本机搭建分布式环境对租房信息进行爬取 3.搭建多台机器的分布式环境,多台机器同时进行租房数据爬取 建议:用Pychar ...
- Redis与Scrapy
Redis与Scrapy Redis与Scrapy Redis is an open source, BSD licensed, advanced key-value cache and store. ...
- python - scrapy 爬虫框架 ( redis去重 )
1. 使用内置,并加以修改 ( 自定义 redis 存储的 keys ) settings 配置 # ############### scrapy redis连接 ################# ...
- Python分布式爬虫打造搜索引擎完整版-基于Scrapy、Redis、elasticsearch和django打造一个完整的搜索引擎网站
Python分布式爬虫打造搜索引擎 基于Scrapy.Redis.elasticsearch和django打造一个完整的搜索引擎网站 https://github.com/mtianyan/Artic ...
- scrapy简单分布式爬虫
经过一段时间的折腾,终于整明白scrapy分布式是怎么个搞法了,特记录一点心得. 虽然scrapy能做的事情很多,但是要做到大规模的分布式应用则捉襟见肘.有能人改变了scrapy的队列调度,将起始的网 ...
- 第三百六十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本查询
第三百六十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本查询 1.elasticsearch(搜索引擎)的查询 elasticsearch是功能 ...
- 四十四 Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本查询
1.elasticsearch(搜索引擎)的查询 elasticsearch是功能非常强大的搜索引擎,使用它的目的就是为了快速的查询到需要的数据 查询分类: 基本查询:使用elasticsearch内 ...
随机推荐
- CSS的进一步深入(更新中···)
在之前我们学了6种选择器和三种CSS样式的引入,学习选择器就是为了更好的选择文本,学习CSS的引入是为了使文本增加各种样式和属性, 下面我们简单来学习一下为文本加样式和一些属性和属性值: 1.文本的样 ...
- linux下如何使make只输出执行过程中的命令序列
答: make -n (-n.--just-print.--dry-run.--recon等价)
- Asp.net 之 window 操作命令
命令:cmd 打开执行窗口 命令:inetmgr.打开iis管理器 命令:dcomcnfg 打开组件服务 命令:regedit 打开注册表
- sqlserver 触发器的运行关键字
触发器执行顺序根据 before 和 after 关键字决定. 使用before 关键字:触发器的执行是在数据的插入.更新或删除之前执行的.使用after关键字:触发器的执行是在数据的插入.更新或删除 ...
- C#获取文件MD5值方法
https://www.cnblogs.com/Ruiky/archive/2012/04/16/2451663.html private static string GetMD5HashFromFi ...
- extends 扩展选项
通过外部增加对象的形式,对构造器进行扩展.它和混入非常的类似. 就是在调用时候,extends是extends:bbb mixins混入是 mixns:[bbb] 还有一点vue里面一般带s的都是局部 ...
- React组件导入的两种方式(动态导入组件的实现)
一. react组件两种导入方式 React组件可以通过两种方式导入另一个组件 import(常用) import component from './component' require const ...
- chrome浏览器的SwitchyOmega插件使用方法
对于有某些特殊需求的人来讲,应该对这个插件不陌生,但是很多人不了解这插件的工作原理,百度的老教程又很烂,在刚开始用的时候我也不知道怎么办,去百度搜出来的教程基本都是让下载个规则文件让你去导入,但一般这 ...
- python 安装pip
https://pip.pypa.io/en/stable/installing/
- oracle的批量操作sql语句
1.批量删除/批量更新 mapper: <update id="updatePrjStateByFPrjId" parameterType="string" ...