论文阅读(Xiang Bai——【TIP2014】A Unified Framework for Multi-Oriented Text Detection and Recognition)
Xiang Bai——【TIP2014】A Unified Framework for Multi-Oriented Text Detection and Recognition
目录
- 作者和相关链接
- 方法概括
- 创新点和贡献
- 方法细节
- 实验结果
- 问题讨论
- 总结与收获点
- 参考文献
作者和相关链接
- 作者

方法概括
- 方法简述
- 这篇文章是作者CVPR2012(参考文献1,专门做检测,可以看看我之前的这篇博客)的方法的扩展,本文做的是端到端的问题(检测+识别)。
- 采用的框架是传统的方法——用swt检测候选字符区域,字符级分类器(随机森林)过滤非字符噪声,再将字符进行合并成字符串,再切成单词(合并切分算法用的是参考文献2)。
- 这篇文章改进的地方重点主要有三点,第一,改造random forest,通过“特征和分类器共享”使得识别和检测用个是同样的特征和分类器(同一个树);第二,字符识别时利用了基于字典搜索的误差矫正方法(按Bing搜索引擎的检索顺序建立的字典);第三,考虑了各种方向的文本(倒立,纵向,从右往左的文字)。
- 另外两个比较小的点在于:第一,在component linking 和word partition的方法换成了参考文献5的方法;第二,大小写判断上采用了一定策略区分了全大写,全小写,首字母大写的情况。
- 方法的简单框架
- 方法简述

创新点和贡献
- 贡献
- 解决任意方向的文字识别问题(曲线,纵向,上下颠倒,从右往左的文字)
- 证明了检测和识别可以用同样的特征和分类器
- 字符识别时利用了基于字典搜索的误差矫正方法
- 新的数据库Hust-TR400
- 提出了一个完整的端到端文字识别算法
- “特征和分类器共享”的出发点
- 以前的“特征共享”大多用在不同类别上(多类分类问题),本文对它进行迁移,用在了任务的不同级上。二类问题,用到的是coarse level的特征,而多类问题,用到是更加fine leve的特征。这两个task进行“特征共享”(文字的固有特征是不变的,无论是用来做二类还是做多类分类问题)
- 随机森林树的节点分支具有类似于“聚类”的功能,会把相似的字符落在同一节点上,例如,"i,j,l"这些可能落在同一个正节点上,因此,不同的正节点字符的概率分布是不一样的,也就是说,每个节点自带了类似于“字符识别”这样的功能(通过落在该节点上的所有样本字符lable的直方图统计来估计),因此检测和识别可以进行分类器共享(如下图)
- 贡献

Fig. 3. Illustration of character distribution histograms. Since the trees are exhaustively grown, each leaf node is either positive (red) or negative (blue).
For each positive leaf node, a character distribution histogram is computed using the examples falling into it and stored for future use.
- 对CVPR2012(参考文献1)的修改点
- 修改:二类RF→二类RF+多类RF,component linking和word partition方法换成新方法,加入后面的识别模块
- 扩展:基于字典搜索的误差矫正的字符识别方法 + 多方向
- 对CVPR2012(参考文献1)的修改点
方法细节
- 整体框架的修改

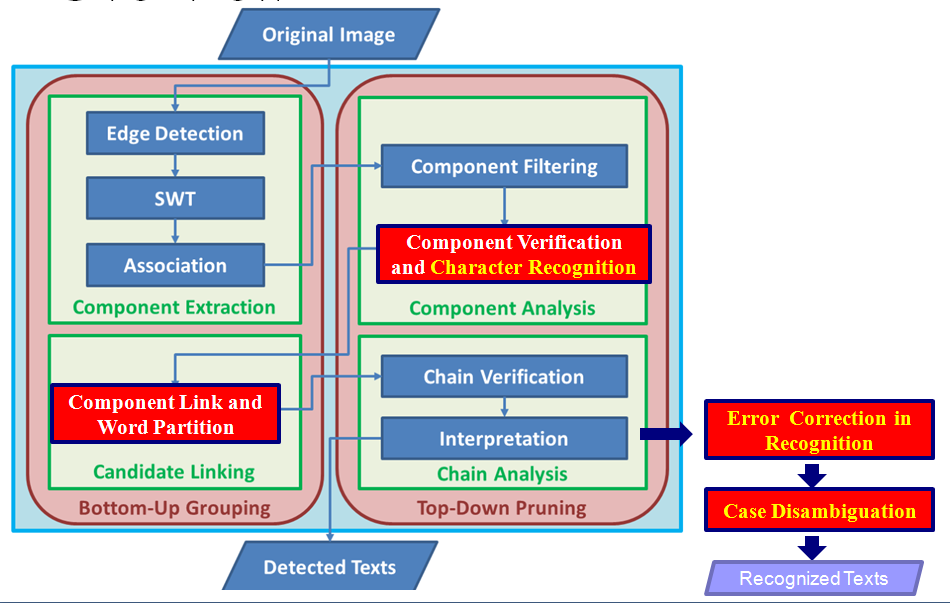
左图为原来的框架(参考文献1), 右图为这篇文章的框架
- random forest分类器的改造
- 基本思想:训练RF的时候,只用二类的label来建树。识别的时候,每个叶子节点的label(62类)的判断是根据落在该节点上的样本的label分布得到的(实际上,就是没用多类的label训练!!!)
- 分类策略
- random forest分类器的改造


- 字符识别的误差矫正方法
- 矫正的动机:有些字符本身特别像('I' 和'l'),或者依靠字符分类器根本分不开('S'和's','C'和'c'),如下图所示,则需要联系上下文(是否构成单词),进行矫正
- 字符识别的误差矫正方法

- 采用的思路:给一个字典,把识别出的结果与字典里的每一个词进行对比,取相似度最大的词作为校正后的识别结果
- 字典的选择:不用传统字典,而是用按Bing搜索引擎的检索顺序建立的字典,因为实际应用中图像里的文字更经常出现正是大家平时生活中使用频率更高的,而不是按一个“完备”(实际也不完备,很多地名,人名并没有被收录)的字典规规矩矩按字母顺序搜索相匹配的单词,这种把实际使用的频率也考虑进去应用性会更强。此外,由于字典的通用性,在任何一个库上都可以用该字典。
- 编辑距离:Levenshtein 编辑距离(替换,删除,插入)
- 替换的权重与插入,删除不一样,而且不同字符互换的权重也应该不同。Θ替换为v的概率取决于样本x经分类器判断可能是v的概率与可能是Θ的概率的比值。即认为,分类器判断一个待测样本是'l'的概率(0.3)与是'j'的概率(0.28)相近,而与'z'的概率(0.01)相差很大,所以,'l'替换成'j'的代价更小,替换成'z'的代价更大。即越相似的样本替换的代价越小→编辑距离越小→相似性越大。(问题是,分类器对'l'和'j'的得分越相近,就代表'l'和'j'越相似这个想法对么?可能的情况是'l'得分0.1,'k'的得分也是0.1,但是'l'和'k'实际上并不相同?)
- 采用的思路:给一个字典,把识别出的结果与字典里的每一个词进行对比,取相似度最大的词作为校正后的识别结果

- 相似度度量:考虑了编辑距离d(参考文献3)和字典中的排序r(λ值通过实验调整)

- 考虑多方向:首先字符一定是按顺序排列的,要么是第一个开始链到最后一个(正序),要么是最后一个开始链到第一个(反序)。其次,考虑的时候,把两个顺序都要考虑进去,选择相似性更高的一个方向作为最终单词的形成方向O(L)
- L为字符串,N为L中的单词数,s(wi)表示第i个单词与字典里的单词的最大相似值,s(L)为正序链的总相似性,s←(L)表示反序链的相似性,O(L)表示最终确定的方向
- 考虑多方向:首先字符一定是按顺序排列的,要么是第一个开始链到最后一个(正序),要么是最后一个开始链到第一个(反序)。其次,考虑的时候,把两个顺序都要考虑进去,选择相似性更高的一个方向作为最终单词的形成方向O(L)

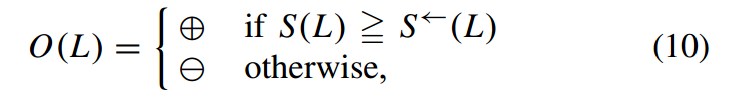

Fig. 5. Probabilities of character classes (only top choices are shown). The word in the image is “Wood”.
Certain characters can be very confusing. For example, after rotation the letter ‘d’ is very similar to ‘p’.
- 大小写歧义性如何解决
- “都是”应该指的是大写比例比较大
- “相近”的定义比较难把握,例如,'g,f,d',这类可能和后面的'oor'差异也比较大
- 大小写歧义性如何解决

- 训练数据
- 正样本:合成库,100k,图像来源(Wang的方法合成的,参考文献4),除了随机平移变换,高斯噪声和模糊,还加入了各种方向的变化
- 负样本:真实的自然场景图像库,30k, 图像来源(没有任何文字的图像,6个库,Berkeley Segmentation Data Set and Benchmarks 500 (BSDS500),Zurich Building Image Database5, Oxford Buildings Dataset6, MIT-CBCL StreetScenes Dataset7, CASIA Tampered Image Detection Evaluation Database (CAISA TIDE) V2.08, and PASCAL VOC 2011 Dataset9)
- 训练数据

实验结果
检测
- ICDAR2011

- MSRA-TD500

字符识别
- CHARS74K

端到端
- ICDAR 2011

- HUST-TR400

问题讨论
- 已有的端到端方法的问题
- 大多是isolated stages(把检测,识别分开,且分成多个步骤) → 问题: 结果受限于每一步的性能,误差积累,无法用后续步骤的信息来修正前面的结果,信息冗余和浪费
- 一般接已有现成的OCR → 问题:整体的性能和速度受限于OCR(一般用于做文档图像)
- 大部分只考虑(近似)水平的文字 → 问题: 实用范围受限
- 识别带字典,但字典一般针对某个库 → 问题: 通用性不强
- 对于上下翻转,竖直,各种旋转了的文字,如何保证分类器不会当做噪声过滤掉?(特征选择具有旋转不变性的,样本中加入旋转的样本?)
- 在编辑距离的"替换"的权重中,作者认为如果分类器给出的分数相同,比如,'l'和'v'的得分都是0.3分,则表示两个字符越相似,替换的权重应该越小,但这样通过得分算相似性的方法是否好?
- 已有的端到端方法的问题
总结与收获点
- 白翔老师他们组做文字有一点我很佩服, 就是他们无论是选择问题的角度还是解决问题的思路都是跟实际应用需求相关联,简单的两个例子就能看出来,1. 大家都在ICDAR2003/2011库上刷指标时,他们提出这个库上的文字大部分是(近)水平的,实际生活中的文字则是各种方向的,然后他们开始自己建库,把多方向的文字检测问题变得越来越潮流;2. 本文的字典选择也很有意思,不用传统的字典,而是用按Bing搜索引擎的检索顺序建立的字典,因为实际应用中图像里的文字更经常出现正是大家平时生活中使用频率更高的,而不是按一个“完备”(实际也不完备,很多地名,人名并没有被收录)的字典规规矩矩按字母顺序搜索相匹配的单词,这种把实际使用的频率也考虑进去应用性会更强。
- 文章中提到了很多细节,说明了一个问题应该要做的很细,想得多一些,逐步优化才能做得更好。比如,在选择正样本的时候的字符串是随机采样得到的,而不是从字典里的单词直接选择,这是为了防止加入人为的先验信息对字符造成影响——有些字母会更倾向于组合在一起,例如,“ea”就比“zj”更经常出现在一起。再比如,因为有些人工材料(砖块,窗户)和植被(草,叶子)很容易被当做误检,所以在选择负样本的时候也尽量多加入这样的样本。
参考文献
- C. Yao, X. Bai, W. Liu, Y. Ma, and Z. Tu, “Detecting texts of arbitrary orientations in natural images,” in Proc. IEEE CVPR, Jun. 2012, pp. 1083–1090.
- X. C. Yin, X. Yin, K. Huang, and H. Hao, “Robust text detection in natural scene images,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 36, no. 5, pp. 970–983, May 2014.
- Y. Li and B. Liu, “A normalized Levenshtein distance metric,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 29, no. 6, pp. 1091–1095, Jun. 2007.
- K. Wang, B. Babenko, and S. Belongie, “End-to-end scene text recognition,” in Proc. IEEE ICCV, Nov. 2011, pp. 1457–1464.
- X. C. Yin, X. Yin, K. Huang, and H. Hao, “Robust text detection in natural scene images,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 36, no. 5, pp. 970–983, May 2014.
论文阅读(Xiang Bai——【TIP2014】A Unified Framework for Multi-Oriented Text Detection and Recognition)的更多相关文章
- 【论文阅读】Sliding Line Point Regression for Shape Robust Scene Text Detection
一.整体网络结构 二.细节 n=7,(7+7)*2+4=32个channel 三.结果 ...
- 【论文阅读】CVPR2021: MP3: A Unified Model to Map, Perceive, Predict and Plan
Sensor/组织: Uber Status: Reading Summary: 非常棒!端到端输出map中间态 一种建图 感知 预测 规划的通用框架 Type: CVPR Year: 2021 引用 ...
- 论文阅读之 A Convex Optimization Framework for Active Learning
A Convex Optimization Framework for Active Learning Active learning is the problem of progressively ...
- 论文阅读笔记五十二:CornerNet-Lite: Efficient Keypoint Based Object Detection(CVPR2019)
论文原址:https://arxiv.org/pdf/1904.08900.pdf github:https://github.com/princeton-vl/CornerNet-Lite 摘要 基 ...
- 论文阅读(Chenyi Chen——【ACCV2016】R-CNN for Small Object Detection)
Chenyi Chen--[ACCV2016]R-CNN for Small Object Detection 目录 作者和相关链接 方法概括 创新点和贡献 方法细节 实验结果 总结与收获点 参考文献 ...
- 论文阅读笔记五十六:(ExtremeNet)Bottom-up Object Detection by Grouping Extreme and Center Points(CVPR2019)
论文原址:https://arxiv.org/abs/1901.08043 github: https://github.com/xingyizhou/ExtremeNet 摘要 本文利用一个关键点检 ...
- 【CV论文阅读】+【搬运工】LocNet: Improving Localization Accuracy for Object Detection + A Theoretical analysis of feature pooling in Visual Recognition
论文的关注点在于如何提高bounding box的定位,使用的是概率的预测形式,模型的基础是region proposal.论文提出一个locNet的深度网络,不在依赖于回归方程.论文中提到locne ...
- 论文阅读(Xiang Bai——【PAMI2017】An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition)
白翔的CRNN论文阅读 1. 论文题目 Xiang Bai--[PAMI2017]An End-to-End Trainable Neural Network for Image-based Seq ...
- 论文阅读(Zhuoyao Zhong——【aixiv2016】DeepText A Unified Framework for Text Proposal Generation and Text Detection in Natural Images)
Zhuoyao Zhong--[aixiv2016]DeepText A Unified Framework for Text Proposal Generation and Text Detecti ...
随机推荐
- ZeroMQ接口函数之 :zmq_msg_get - 获取消息的性质
ZeroMQ 官方地址 :http://api.zeromq.org/4-1:zmq_msg_get zmq_msg_get(3) ØMQ Manual - ØMQ/3.2.5 Name zmq_m ...
- ZeroMQ接口函数之 :zmq_msg_set - 设置消息的性质
ZeroMQ 官方地址 :http://api.zeromq.org/4-1:zmq_msg_set zmq_msg_set(3) ØMQ Manual - ØMQ/3.2.5 Name zmq_m ...
- 关于rc.local
1.rc.loacl的启动 /etc/rc.d/rc.local
- 【PostgreSQL】PostGreSQL数据库,时间数据类型
---"17:10:13.236"time without time zone:时:分:秒.毫秒 ---"17:10:13.236+08"time with t ...
- java并发编程:阻塞队列
一.几种主要的阻塞队列 自从Java 1.5之后,在java.util.concurrent包下提供了若干个阻塞队列,主要有以下几个: ArrayBlockingQueue:基于数组实现的一个阻塞队列 ...
- 重新用delphi7写东西
晚上开始写通讯录的程序,又对表进行点修改.重新开始用delphi7很不习惯,太不好用了. TArecord=record Const UserName=’YHName’; ..... End; 这个在 ...
- php上传大文件时,服务器端php.ini文件中需要额外修改的选项
几个修改点: 1.upload_max_filesize 上传的最大文件 2.post_max_size 上传的最大文件 3.max_execution_time 修改为0表示无超时,一直等待 4.m ...
- SqlServer 笔记一 某表中每个月的产品数量(DATENAME() 与 DATEPART()、YEAR())
1.使用 DATENAME() 函数 SELECT DATENAME(yyyy, [columnName]) + '/' + DATENAME(mm, [columnName]) AS monthDa ...
- Nginx 和 Apache 开启目录浏览功能
1.Nginx 在相应项目的 Server 段中的 location 段中,添加 autoindex on.例如: server { listen ; server_name www.dee.prac ...
- Apache服务器性能监控
Apache服务器性能监控 1.使用自带mod_status模块监控 1)加载mod_status.so 模块 在httpd.conf中打开LoadModule status_module modul ...