44、NLP的其他分词功能测试
1、 命名实体识别功能测试
@Test
public void testNer(){
if (NER.create("ltp_data/ner.model")<0) {
System.err.println("load failed");
return;
}
List<String> words = new ArrayList<String>();
List<String> tags = new ArrayList<String>();
List<String> ners = new ArrayList<String>();
words.add("中国");
tags.add("ns");
words.add("国际");
tags.add("n");
words.add("广播");
tags.add("n");
words.add("电台");
tags.add("n");
words.add("创办");
tags.add("v");
words.add("于");
tags.add("p");
words.add("1941年");
tags.add("m");
words.add("12月");
tags.add("m");
words.add("3日");
tags.add("m");
words.add("。");
tags.add("wp");
NER.recognize(words, tags, ners);
for (int i = 0; i < words.size(); i++) {
System.out.println(ners.get(i));
}
NER.release();
}
结果如下所示

2、句法分析功能测试
/**
* 句法分析功能测试
*/
@Test
public void testParser(){
if (Parser.create("ltp_data/parser.model") < 0) {
System.err.println("loadfailed");
return;
}
List<String> words = new ArrayList<String>();
List<String> tags = new ArrayList<String>();
words.add("一把手");
tags.add("n");
words.add("亲自");
tags.add("d");
words.add("过问");
tags.add("v");
words.add("。");
tags.add("wp");
List<Integer> heads = new ArrayList<Integer>();
List<String> deprels = new ArrayList<String>(); int size = Parser.parse(words, tags, heads, deprels); for (int i = 0; i < size; i++) {
System.out.print(heads.get(i) + ":" + deprels.get(i));
if (i == size - 1) {
System.out.println();
} else {
System.out.print(" ");
}
}
Parser.release();
}
结果:

4、语义角色标注功能测试
@Test
public void testSrl(){
SRL.create("ltp_data/srl");
ArrayList<String> words = new ArrayList<String>();
words.add("一把手");
words.add("亲自");
words.add("过问");
words.add("。");
ArrayList<String> tags = new ArrayList<String>();
tags.add("n");
tags.add("d");
tags.add("v");
tags.add("wp");
ArrayList<String> ners = new ArrayList<String>();
ners.add("O");
ners.add("O");
ners.add("O");
ners.add("O");
ArrayList<Integer> heads = new ArrayList<Integer>();
heads.add(2);
heads.add(2);
heads.add(-1);
heads.add(2);
ArrayList<String> deprels = new ArrayList<String>();
deprels.add("SBV");
deprels.add("ADV");
deprels.add("HED");
deprels.add("WP");
List<Pair<Integer, List<Pair<String, Pair<Integer, Integer>>>>> srls = new ArrayList<Pair<Integer, List<Pair<String, Pair<Integer, Integer>>>>>();
SRL.srl(words, tags, ners, heads, deprels, srls);
for (int i = 0; i < srls.size(); ++i) {
System.out.println(srls.get(i).first + ":");
for (int j = 0; j < srls.get(i).second.size(); ++j) {
System.out.println(" tpye = "
+ srls.get(i).second.get(j).first + " beg = "
+ srls.get(i).second.get(j).second.first + " end = "
+ srls.get(i).second.get(j).second.second);
}
}
SRL.release();
}
结果如下图所示:

下面插入一段原网站的分词示例
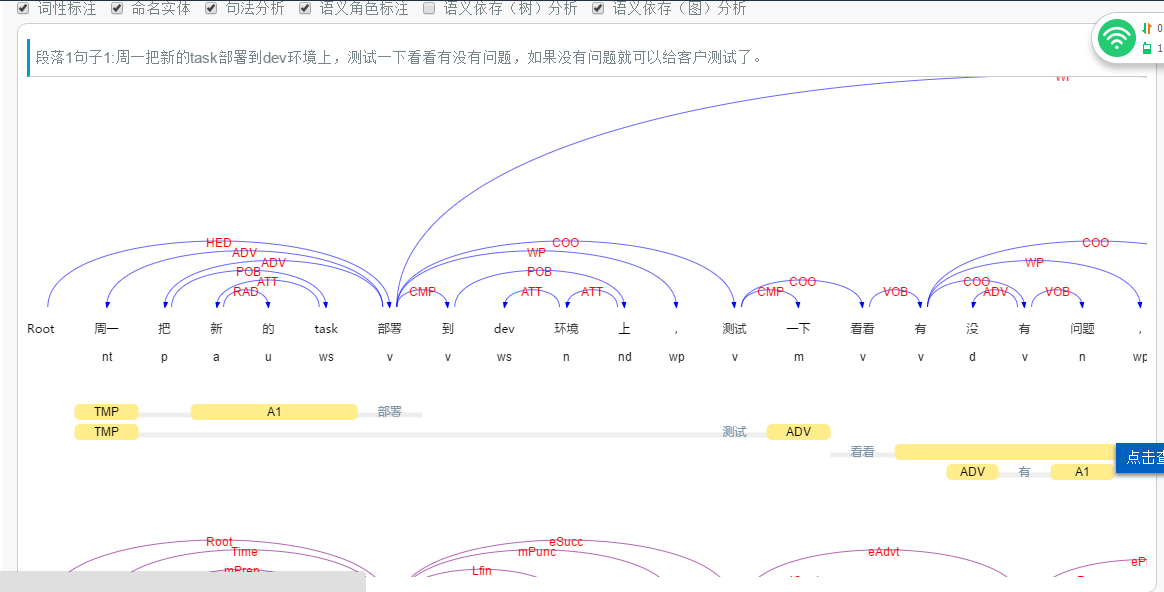
分词依据
http://www.ltp-cloud.com/intro/#pos_how 具体大家可以来前边这个网址中查看分类依据,感觉哈工大讲得很牛呀!
词性标注
词性标注(Part-of-speech Tagging, POS)是给句子中每个词一个词性类别的任务。 这里的词性类别可能是名词、动词、形容词或其他。 下面的句子是一个词性标注的例子。 其中,v代表动词、n代表名词、c代表连词、d代表副词、wp代表标点符号。
国务院/ni 总理/n 李克强/nh 调研/v 上海/ns 外高桥/ns 时/n 提出/v ,/wp 支持/v 上海/ns 积极/a 探索/v 新/a 机制/n 。/wp
词性作为对词的一种泛化,在语言识别、句法分析、信息抽取等任务中有重要作用。 比方说,在抽取“歌曲”的相关属性时,我们有一系列短语:
儿童歌曲
欢快歌曲
各种歌曲
悲伤歌曲








44、NLP的其他分词功能测试的更多相关文章
- HanLP vs LTP 分词功能测试
文章摘自github,本次测试选用 HanLP 1.6.0 , LTP 3.4.0 测试思路 使用同一份语料训练两个分词库,同一份测试数据测试两个分词库的性能. 语料库选取1998年01月的人民日报语 ...
- NLP实现文本分词+在线词云实现工具
实现文本分词+在线词云实现工具 词云是NLP中比较简单而且效果较好的一种表达方式,说到可视化,R语言当仍不让,可见R语言︱文本挖掘——词云wordcloud2包 当然用代码写词云还是比较费劲的,网上也 ...
- 【nlp】中文分词基础原则及正向最大匹配法、逆向最大匹配法、双向最大匹配法的分析
分词算法设计中的几个基本原则: 1.颗粒度越大越好:用于进行语义分析的文本分词,要求分词结果的颗粒度越大,即单词的字数越多,所能表示的含义越确切,如:“公安局长”可以分为“公安 局长”.“公安局 长” ...
- NLP系列-中文分词(基于统计)
上文已经介绍了基于词典的中文分词,现在让我们来看一下基于统计的中文分词. 统计分词: 统计分词的主要思想是把每个词看做是由字组成的,如果相连的字在不同文本中出现的次数越多,就证明这段相连的字很有可能就 ...
- NLP系列-中文分词(基于词典)
中文分词概述 词是最小的能够独立活动的有意义的语言成分,一般分词是自然语言处理的第一项核心技术.英文中每个句子都将词用空格或标点符号分隔开来,而在中文中很难对词的边界进行界定,难以将词划分出来.在汉语 ...
- 【NLP】中文分词:原理及分词算法
一.中文分词 词是最小的能够独立活动的有意义的语言成分,英文单词之间是以空格作为自然分界符的,而汉语是以字为基本的书写单位,词语之间没有明显的区分标记,因此,中文词语分析是中文信息处理的基础与关键. ...
- NLP自然语言处理 jieba中文分词,关键词提取,词性标注,并行分词,起止位置,文本挖掘,NLP WordEmbedding的概念和实现
1. NLP 走近自然语言处理 概念 Natural Language Processing/Understanding,自然语言处理/理解 日常对话.办公写作.上网浏览 希望机器能像人一样去理解,以 ...
- 43、哈工大NLP自然语言处理,LTP4j的测试+还是测试
1.首先需要构建自然语言处理的LTP的框架 (1)需要下载LTP的源码包即c++程序(https://github.com/HIT-SCIR/ltp)下载完解压缩之后的文件为ltp-master (2 ...
- nlp词性标注
nlp词性标注 与分词函数不同,jieba库和pyltp库词性标注函数上形式相差极大. jieba的词性标注函数与分词函数相近,jieba.posseg.cut(sentence,HMM=True)函 ...
随机推荐
- 读取DBF文件数据
#region 返回DBF表 public static System.Data.DataTable getDTFromDBF(string fullPath) { string pDir = Sys ...
- js获取ModelAndView值的问题
Springmvc中使用ModelAndView传值 return new ModelAndView(url).addObject(CommonConstant.PAGE_KEY, page) .ad ...
- bzoj1091: [SCOI2003]切割多边形
Description 有一个凸p边形(p<=8),我们希望通过切割得到它.一开始的时候,你有一个n*m的矩形,即它的四角的坐标分别为(0,0), (0,m), (n,0), (n,m).每次你 ...
- <<软件测试实战>>读书笔记
软件测试基础 软件的复杂度已经超越了人的理解能力 1. 虽然高抽象的层次语言,程序框架,程序库等提高了人的生产力,但是还是需要开发者深入理解细节,可以减少开发时间,但是无法减少开发者学习整个技术栈的时 ...
- Linux的nm查看动态和静态库中的符号
功能 列出.o .a .so中的符号信息,包括诸如符号的值,符号类型及符号名称等.所谓符号,通常指定义出的函数,全局变量等等. 使用 nm [option(s)] [file(s)] 有用的optio ...
- pythonbrew, pythonz, virtualenv
Python 的虛擬環境及多版本開發利器─Virtualenv 與 Pythonbrewhttp://www.openfoundry.org/tw/tech-column/8516-pythons-v ...
- cookie禁用了,session还能用吗?
Cookie与 Session,一般认为是两个独立的东西,Session采用的是在服务器端保持状态的方案,而Cookie采用的是在客户端保持状态的方案.但为什么禁用Cookie就不能得到Session ...
- 多个Python环境的构建:基于virtualenv 包
假如一台计算中安装多个Python版本,而不同版本可能会pip安装不同的包,为了避免混乱,可以使用virtualenv包隔离各个Python环境,实现一个Python版本对应一套开发环境. 本地概况: ...
- ajaxReturn
controller:$info=array('error'=>0,'msg'=>'');if($user_info){ if($user_info['is_lock']){ ...
- caffe-mnist别手写数字
[来自:http://www.cnblogs.com/denny402/p/5685909.html] 整个工作目录建在:/home/ubunt16041/caffe/examples/abc_mni ...