在SQL Server 2014里可更新的列存储索引 (Updateable Column Store Indexes)
传统的关系数据库服务引擎往往并不是对超大量数据进行分析计算的最佳平台,为此,SQL Server中开发了分析服务引擎去对大笔数据进行分析计算。当然,对于数据的存放平台SQL Server数据库引擎而言,也是需要强大的数据处理能力的。
在SQL Server 2012时,SQL Server 引入了列存储索引,用以显著提供高传统数据仓库类型语句的性能,并在SQL Server 2014中做了进一步加强。本文将在对SQL Server 2012列存储索引简单介绍的基础上,进一步解释SQL Server 2014中列存储索引发生的变化。
顾名思义,列存储会将一个列的数据单独存放在一起,因此主要会有以下两个优点。
- 同一个列中的数据的相似性比较高,因此压缩比例会更高。磁盘操作时,磁盘的IO也会相应的降低。当然,当压缩的数据读取到内存后解压会需要额外的CPU。
- 由于数据是按照列进行存储和读取的,因此如果某些列在访问中并不需要,那么实际的操作时也会不访问这些列,那么磁盘IO会进一步降低。
我们知道,CPU,memory和磁盘三者中磁盘的速度最慢。因此往往磁盘是性能问题的主要瓶颈。通过使用列存储索引,会大大减少磁盘的IO操作,加之SQL Server会使用一些特殊的执行模式等等,大批量的数据聚合访问等会较以往的行存储更快,用户可以得到显著地性能提升。
但是如果仅仅是需要查找某一行或者某些行,通过传统的index seek即可直接完成的话,那么反而是传统行存储中的index seek更佳。
SQL Server 2012的列索引主要有以下特性
- 当加载了列存储索引以后,不但索引本事是只读的,无法修改,底层的堆表或者聚集索引的数据也无法修改
- 创建列存储索引时需要的内存往往会比传统的索引需要的更多
- 与indexed views, filtered indexes, sparse columns, computed columns不兼容
- 支持常见的数据类型,但是例如varchar(max),uniqueidentifier等是不支持的
- 数据压缩比很高
- 数据预读比例很高
- 操作的数据单元称之为 batch
- 语句执行是基于矢量(Vector-based)的
- 语句在被编译时会自动考虑到使用列存储索引
SQL Server 2014的列索引主要有以下特性
=========================================
在SQL Server2014时,SQL Server对列存储索引进行了进一步的开发,使得其能够支持更新操作。主要的进步如下。
- 支持数据的读和写
- 在打破了数据只读的限制后,列存储索引使用的范围和场景大大增加
- 相比传统的ad-hoc的增删改操作,在SQL Server2014还是推荐使用bulk insert和分区交换来进行大批次数据的更新,效率更高,维护成本也会降低
- 支持更多的数据类型
- 添加了更多的数据类型支持:(n)varchar(max), varbinary(max), XML, Spatial, CLR
- 基本说来,SQL Server2014的列存储支持所有的non-blob数据类型
- 整个表可建立并且只能建立一个聚集列存储索引。传统的行存储会需要非聚集索引帮助提高访问效率,但是列存储无需这样。并且由于只有一份数据,因此存储需要的磁盘空间大大降低
- 非聚集列索引仍然支持,并且还是只读的结构。
当我们有了聚集列存储索引后,就不需要非聚集列索引了,因为此时所有的数据都是按照列存储了。但是如果表上需要添加Constraints或者工作负载仍然需要B-tree形式的非聚集索引,那么我们还是只能考虑使用非聚集列存储索引。
- 语句的执行上有以下改进
- 基于矢量的计算方式得到改
- 支持更多的语法
- 所有的join方式(包括OUTER, HASH, SEMI (NOT IN, IN)
- UNION ALL
- Scalar aggregates
- “Mixed mode” plans
- 对bitmap和spill操作有进一步的改进
- 对hash join有所改进
可以看出,无论是功能性的角度还是性能的角度,SQL Server2014的columnstore index都是有巨大的进步的。
下面的就SQL Server2014 如何实现列存储索引的数据修改操作加以简单描述
==========================================
首先我们来认识下存储索引中设计的概念:
- Column store – 数据逻辑上组织为一个包含行和列的表,但是实际的数据是按照列进行存储的。
- Row store – 数据在逻辑上组织为一个包含行和列的表,并且物理上也是一行一行数据进行存储。
- Row groups and column segments - 列存储时,整个表中数据会首先按照一定的行数对表进行切割,分成几组,称之为row group。对每一个row group中的数据,会单独存储每一列。Row group中的每一个列称之为一个column segment。
- nonclustered columnstore index – 非聚集列存储索引基于堆表或者聚集索引而创建的只读索引,因此索引包含的列中数据实际存储两份,底层表也是出于只读模式。
上述的概念在SQL Server 2012、2014中的列存储索引中是一样的。
SQL Server 2014的列存储索引添加了下面新的内容:
- Clustered columnstore inde - 整个表都按照列存储进行组织,直接替代了传统的堆表或者聚集索引,可以自由的进行增删改操作。
- Delta store -
聚集列存储索引虽然相对于非聚集列存储索引在column store这块组织架构基本一样,但是它可以进行增删改操作。原因是它多了一块或者多块行存储部分,这部分称之为delta tore。
新插入的数据是直接加载到delta store中的删除操作只是将数据标识为删除,实际的删除需要在rebuild时完成。
更新操作会拆分为一个删除操作和一个插入合并完成。
如果一个bulk insert的批次插入的量小于100000,那么数据会加载到delta store中,否则会加载到columnstore中。
当delta store中数据量超过100 0000后,“Tuple mover” 会将其中数据进行归总放置到column store中。
下图是聚集列存储索引的一个示意图。
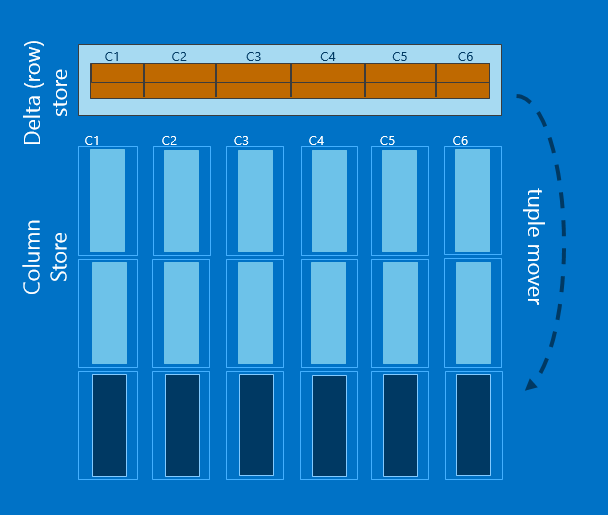
原文链接:http://blogs.msdn.com/b/apgcdsd/archive/2015/01/02/sql-2014-8-updateable-column-store-indexes.aspx
在SQL Server 2014里可更新的列存储索引 (Updateable Column Store Indexes)的更多相关文章
- SQL Server 2014里的性能提升
在这篇文章里我想小结下SQL Server 2014引入各种惊艳性能提升!! 缓存池扩展(Buffer Pool Extensions) 缓存池扩展的想法非常简单:把页文件存储在非常快的存储上,例如S ...
- SQL Server 2014里的缓存池扩展
在今天的文章里我想谈下SQL Server 2014里引入的缓存池扩展(Buffer Pool Extensions).我们都知道,在SQL Server里,缓存池是主要的内存消耗者.当你从你存储里读 ...
- 在SQL Server 2014里,如何用资源调控器压制你的存储?
在今天的文章里,我想谈下SQL Server 2014里非常酷的提升:现在你终于可以根据需要的IOPS来压制查询!资源调控器(Resource Governor)自SQL Server 2008起引入 ...
- SQL Server 2014里的针对基数估计的新设计(New Design for Cardinality Estimation)
对于SQL Server数据库来说,性能一直是一个绕不开的话题.而当我们去分析和研究性能问题时,执行计划又是一个我们一直关注的重点之一. 我们知道,在进行编译时,SQL Server会根据当前的数据库 ...
- SQL Server 2014里的IO资源调控器
在本文中,我们将来看看SQL Server 2014在资源调控器方面增加了哪些新的功能.资源调控器(Resource Governor)是从SQL Server 2008开始出现的一项功能.它是用于管 ...
- Sql Server中一次更新多列数据
UPATE yourTableName SET column1 = xx, column2 = yy , column3 = zz WHERE yourCondition 举个例子,比如有这样一张表: ...
- sql server 2014预览版发布
MSDN发布sql server2014预览版,如下图: SQL Server 2014新特性: 微软SQL Server部门主管Eron Kelly介绍,通过将交易处理放到内存中进行,新的SQL S ...
- [SQL Server 2014] 微软将于年底发布新版数据库SQL Server 2014
在今年的TechEd大会上,微软宣布SQL Server 2014的第一个技术预览版.SQL Server 2014的重点包括内存OLTP.实时的大数据分析.支持混合云端,以及提供更完整的商业智能(B ...
- SQL Server 2014 聚集列存储
SQL Server 自2012以来引入了列存储的概念,至今2016对列存储的支持已经是非常友好了.由于我这边线上环境主要是2014,所以本文是以2014为基础的SQL Server 的列存储的介绍. ...
随机推荐
- linux OS install oracle database
#!/bin/bash#Purpose:Create and config oracle install.#Usage:Log on as the superuser('root') #1.creat ...
- Linux常用目录
- git 撤销提交的文件
一.问题 近期在使用git时遇到一个问题,就是在git上传文件时,将一个100兆的大文件添加到了git,并执行了push操作,这时在上传完毕后,会提示这个错误 Large files detected ...
- 何必苦等VS2015?来看看VS2013下实现移动端的跨平台开发
前一天准备下载VS2015预览版,到VisualStudio官网一看,发现微软发布了VisualStudio2013的插件——Visual Studio Tools for Apache Cordov ...
- Linux cat命令
200 ? "200px" : this.width)!important;} --> 介绍 cat命令经常会用来查看一个文件的内容,并且结合它本身的一些参数经常可以用来做一 ...
- 自制Unity小游戏TankHero-2D(4)关卡+小地图图标+碰撞条件分析
自制Unity小游戏TankHero-2D(4)关卡+小地图图标+碰撞条件分析 我在做这样一个坦克游戏,是仿照(http://game.kid.qq.com/a/20140221/028931.htm ...
- vmware安装ubuntu12.04嵌套安装xen server(实现嵌套虚拟化)
环境准备 软件:vmware workstation 9.0 ubuntu-12.04.2-server-amd64(官方下载) 硬件:确认CPU支持虚拟化VM-T vmware设置 vmwar ...
- [_CN] Eclipse精要与高级开发技术 note
一 eclipse是基于java的 ide ,但根据其体系结构,开发插件,也可拓展到其他语言———————— 尽管如此,但还是很少听说用eclipse来写php或者c的 跨os 三个项目:eclips ...
- VUE 意淫笔记
caihg Vue.js 递归组件实现树形菜单 最近看了 Vue.js 的递归组件,实现了一个最基本的树形菜单. 项目结构: main.js 作为入口,很简单: 1 2 3 4 5 6 7 8 9 i ...
- Netty权威指南
Netty权威指南(异步非阻塞通信领域的经典之作,国内首本深入剖析Netty的著作,全面系统讲解原理.实战和源码,带你完美进阶Netty工程师.) 李林锋 著 ISBN 978-7-121-233 ...