Textrank算法介绍
先说一下自动文摘的方法。自动文摘(Automatic Summarization)的方法主要有两种:Extraction和Abstraction。其中Extraction是抽取式自动文摘方法,通过提取文档中已存在的关键词,句子形成摘要;Abstraction是生成式自动文摘方法,通过建立抽象的语意表示,使用自然语言生成技术,形成摘要。由于生成式自动摘要方法需要复杂的自然语言理解和生成技术支持,应用领域受限。所以本人学习的也是抽取式的自动文摘方法。
目前主要方法有:
- 基于统计:统计词频,位置等信息,计算句子权值,再简选取权值高的句子作为文摘,特点:简单易用,但对词句的使用大多仅停留在表面信息。
- 基于图模型:构建拓扑结构图,对词句进行排序。例如,TextRank/LexRank
- 基于潜在语义:使用主题模型,挖掘词句隐藏信息。例如,采用LDA,HMM
- 基于整数规划:将文摘问题转为整数线性规划,求全局最优解。
textrank算法
TextRank算法基于PageRank,用于为文本生成关键字和摘要。
PageRank
PageRank最开始用来计算网页的重要性。整个www可以看作一张有向图图,节点是网页。如果网页A存在到网页B的链接,那么有一条从网页A指向网页B的有向边。
构造完图后,使用下面的公式: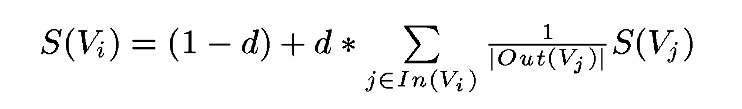
S(Vi)是网页i的中重要性(PR值)。d是阻尼系数,一般设置为0.85。In(Vi)是存在指向网页i的链接的网页集合。Out(Vj)是网页j中的链接存在的链接指向的网页的集合。|Out(Vj)|是集合中元素的个数。
PageRank需要使用上面的公式多次迭代才能得到结果。初始时,可以设置每个网页的重要性为1。上面公式等号左边计算的结果是迭代后网页i的PR值,等号右边用到的PR值全是迭代前的。
举个例子:
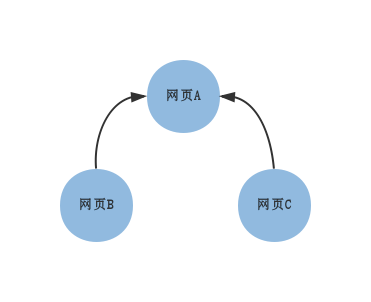
上图表示了三张网页之间的链接关系,直觉上网页A最重要。可以得到下面的表:
| 结束\起始 | A | B | C |
| A | 0 | 1 | 1 |
| B | 0 | 0 | 0 |
| C | 0 | 0 | 0 |
横栏代表其实的节点,纵栏代表结束的节点。若两个节点间有链接关系,对应的值为1。
根据公式,需要将每一竖栏归一化(每个元素/元素之和),归一化的结果是:
| 结束\起始 | A | B | C |
| A | 0 | 1 | 1 |
| B | 0 | 0 | 0 |
| C | 0 | 0 | 0 |
上面的结果构成矩阵M。我们用matlab迭代100次看看最后每个网页的重要性:
M = [0 1 1
0 0 0
0 0 0];
PR = [1; 1 ; 1];
for iter = 1:100
PR = 0.15 + 0.85*M*PR;
disp(iter);
disp(PR);
end运行结果(省略部分):
......
95
0.4050
0.1500
0.1500
96
0.4050
0.1500
0.1500
97
0.4050
0.1500
0.1500
98
0.4050
0.1500
0.1500
99
0.4050
0.1500
0.1500
100
0.4050
0.1500
0.1500最终A的PR值为0.4050,B和C的PR值为0.1500。
如果把上面的有向边看作无向的(其实就是双向的),那么:
M = [0 1 1
0.5 0 0
0.5 0 0];
PR = [1; 1 ; 1];
for iter = 1:100
PR = 0.15 + 0.85*M*PR;
disp(iter);
disp(PR);
end运行结果(省略部分):
.....
98
1.4595
0.7703
0.7703
99
1.4595
0.7703
0.7703
100
1.4595
0.7703
0.7703依然能判断出A、B、C的重要性。
TextRank
TextRank算法是一种用于文本的基于图的排序算法。其基本思想来源于谷歌的 PageRank算法, 通过把文本分割成若干组成单元(单词、句子)并建立图模型, 利用投票机制对文本中的重要成分进行排序, 仅利用单篇文档本身的信息即可实现关键词提取、文摘。和 LDA、HMM 等模型不同, TextRank不需要事先对多篇文档进行学习训练, 因其简洁有效而得到广泛应用。
TextRank 一般模型可以表示为一个有向有权图 G =(V, E), 由点集合 V和边集合 E 组成, E 是V ×V的子集。图中任两点 Vi , Vj 之间边的权重为 wji , 对于一个给定的点 Vi, In(Vi) 为 指 向 该 点 的 点 集 合 , Out(Vi) 为点 Vi 指向的点集合。点 Vi 的得分定义如下:
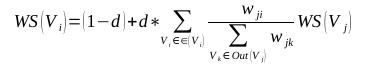
其中, d 为阻尼系数, 取值范围为 0 到 1, 代表从图中某一特定点指向其他任意点的概率, 一般取值为 0.85。使用TextRank 算法计算图中各点的得分时, 需要给图中的点指定任意的初值, 并递归计算直到收敛, 即图中任意一点的误差率小于给定的极限值时就可以达到收敛, 一般该极限值取 0.0001。
1. 基于TextRank的关键词提取
关键词抽取的任务就是从一段给定的文本中自动抽取出若干有意义的词语或词组。TextRank算法是利用局部词汇之间关系(共现窗口)对后续关键词进行排序,直接从文本本身抽取。其主要步骤如下:
(1)把给定的文本T按照完整句子进行分割,即aaarticlea/png;base64,iVBORw0KGgoAAAANSUhEUgAAAKkAAAAVCAIAAACyv1l2AAADx0lEQVR4nO2aWyhsURjHTZyHUUhCLiXx5k4pyaUkSuRWSrlMMi80PPDAw8jtAZO8KDIK5ZYkNUVePEhIrpEXY4pyS5moKRHnf2Z3dqeZ2XvP7LVmz3Dm9zCt9p79/dfnv3zrWzafr68vLw//JT7OCy2TyZiBZ3m5Fi4jnOi9tZgHl8C4wK4AFud678GdsfReoVBMTU1Zfy8oKOjp6YmW6vz8vEajMRgMJpMJkVNSUnQ6Ha3gLhGSElpJWXp/e3t7c3MTGho6Ozu7ubmp1Wrf39+NRmNtbS2Naf9hZWVldXV1eno6Jibm9fV1b29PrVbTCu4SISmhmJSl92FhYZGRkRgcHR2lpaX9MuPr6xsVFUU66780NTWdn58HBgZiLJfLi4uLl5eXaQV3iZCUUEzK0nu24MP7yspK9vrk5CQ7Pjs7S0hI4IpYVVW1sLDAI+nt7Y2i0tzcbC1KF8mEpIRiUrZ7PXSGp6enSUlJNu/Gx8eTNPD9/f0NDQ1ra2tdXV3p6emi47iPkJRQTMq293q9Pjg42N/fnyQ0F2gd8vLy5ubmsrOzS0tLx8fHAwICvqlQZmbm9va2o1dIoJiUbe9R8NE9EsxQgIiIiPb29rq6uqGhIaVSubi4+E2FrE215wohtJJyjfcMISEhjY2N6Ch/jJCUkCfF6X1LSwvXM6J7PSxVHE7+vYLOBZsLM76+vi4rKzs4OBCetRA8QnFxcVdXVxh3d3crFApyLcng/+mJgNP75ORkrmdE93o4jGo0moqKChwjX15e9vf3Ozo6Ojs7cevy8rK3t/fw8NCeOIWFhTs7OxcXF+Hh4Y4K+fn5GY1GPJubmyvovaAQRUiSEoel9ygjOp3u4eEhNTUVY/xyiA5tTXV1NUrC4ODg8/MzGknUq56eHpxQcSs2NhaLemZmRjCIwWDY2NjIz8/n8YNHaHd318v8ZwzUTHIhWhAmBYqKij4+Pkwm0/DwsEqlwteysrL4RS29n5iYIEyDB7UZwiDwrKSkZHR0lEQIR+SRkRFyIVqQJ1VTUzM2NoalANfLy8vRYDrsvZvz+fmJRT0wMIBeV3SQpaWlDDPOFrITKlrHx8dYPXd3d8jr8fExJydH8BHnes+8N6T4Jvft7a2vrw8VW3QE7CzYL/mNpyJkP1S04H1bW9v6+npBQQHagtbWVvaW9dtbBid675DlW1tbzOui6Oho7Ppc9UpuhmRW9fX19syQXMh+qGjB+8TExJOTE3xijO0DvTNziytNd6n5MBv9jgRCP/XfSe7v7/GJJp0dC+Iu3nuQnt95RllXzy3V5AAAAABJRU5ErkJggg==" alt="" name="Object1" align="absmiddle" hspace="8" />
(2)对于每个句子aaarticlea/png;base64,iVBORw0KGgoAAAANSUhEUgAAADAAAAAVCAIAAACPAfpVAAACt0lEQVR4nGP5//8/w2ACLAPtAHQw6iBCAKeDli9f3tPTc//+/W/fvgkLCxsaGm7ZsgWryh8/fqxevfr06dOvX7+GpEhVVdXm5mZkNYmJiQsWLMDUCzT5zZs3hB20fv36jRs3Lly4UFlZ+fPnzydPnqyrq8Oq8vjx42FhYUCnmJubi4qKQgT//v2LpuzZs2ePHz8WFxdfunTp/v3758yZ8/v37w8fPsTFxaGpxO6g7Ozsq1evCgoKAtmcnJy+vr5r167FVHbr1i13d3cHBwegBWJiYliNggBJSUkZGRkg4/z588bGxqxgwMXFJS8vT5SDmJmZgV7JycmBi2AN8JKSEnV1daBbgabjcQ2ydqCDQkJC4OJz584lykGtra3Jycnbt2+vr683MzPDqgYYlVu3bl21ahVB18ABMIVdunRJX18fjxrsDgJGrbOz87Jly+zs7AICAmbOnMnPz4+mBpgm/v37h+xdOACmpxMnTmCK3717F5jO+Pj4SHYQEEhLS5eWlsbHx3d3d6elpa1cuRJNASSFVVVV6erqokmJiIhgNRMYX8Dcisc1+BwEAcCkmpqaCkyGmFLAdKqpqQnMXxEREfgNochBwCAB5nZkEWACh+dnW1vbw4cPw6WAZUFUVJSNjQ1m7sXloPz8fNIcBCxygOVhcHAwMJd++vQJWNxVVlYC4wUii+waIACGDTCRAv0ATNo+Pj7wmAIWd46OjlgdZGBgQJqDgD5esWJFV1fX+/fvgakPGFlNTU3AcogBHDzAhAWURVbf1tYGTPgTJ06sqal5+/YtRBAzUQPjHVjQv3z50sjICMhubGwk1kF1YIBVaUZGBjBnYYp7gAEuCyBg9uzZ+BXgdBAecPHiRScnJ+LVkwdIc1BRURHtnAIBpDkImLrnzZtHO9cwkOSgFy9e0M4dcDDoGmgA9CATy1d+XhEAAAAASUVORK5CYII=" alt="" name="Object2" align="absmiddle" hspace="8" />,进行分词和词性标注处理,并过滤掉停用词,只保留指定词性的单词,如名词、动词、形容词,即aaarticlea/png;base64,iVBORw0KGgoAAAANSUhEUgAAALQAAAAVCAIAAABg71MuAAAEA0lEQVR4nO2aSyh8URzHR2xm4ZUoj43YeU5K/UckUjKNxqMU5ZE8CrMgCxbjvcAsUBYshBpME5NSylYekwh5pGTCxgqZUhT+v+bWdLtzH+ecOffO+P/ns5jOnDn39z2/zvfe8zszE/bz86MKEoSPMLkFQkJCmEbQhYEM7zLJbg5V0Ba/AWaNPBZhUMIcQX4pguZYXV01m81Op/P9/T0mJkaj0WxtbSk5syB+h98cdrt9c3NzaWkpJSXF5XI5HA6TyURRta6urqKiorq6mmLMwBRVEuoJ8pujo6Pj8vIyOjoa2mq1Wq/Xr6+v05IErq6u+vr6KAYMWFEloZ4gvzlCQ0MtFktnZ6enZ3FxkT3g4uIiIyNDKGhNTc3a2prQpzqd7vT0FC4H8z0/P2NPmQi/iCqJHAnym2NsbKy5uXl7e3tgYCA3N9d7QHp6OvEZZHp6+ubm5vb2luzyXySqJHIkyG+O+vr64uLilZWVgoICg8EwNzcXGRlJSxIMnp2dTStaIIvm5eXt7e3h9pAhR4KCp5XExMTe3t6GhobJycnW1lar1UpL8uzsTPl18ouo96qj9JAhR4IS33PExcW1tLTk5ORQlASPt7W1UQwYsKJKIkeCXHPAowJOsOweKE5jY2OZdn5+/u7ursq3gvT8/Fyj0bB7PGHZPDw8wMHs+PgYIQtpEEXT0tLu7u4g36GhoaamJirSyoCYIBZcczgcDrPZXFVVlZSU9Pb2dnR0BKej/v5+5lOPmC8Fqcvl+vz8ZPd45wCF1cjIyMnJCUrA0tLSg4OD6+vrhIQEX0SB8PDw19dXCFVYWChuDhRRikjKISaIBdcctbW1cNNPTEy8vLxERETAhjI8PKzX61VuJ0IhIvJIQGRjYyMzMxMKMQgVFRXFGzY1NRUeYMvLy5LRnE7nzs5OSUmJ+CKhiAKHh4fwGh8fD/up76K0QJFDTLCsrOzr6wsasAdVVlaK63LNYXLDO7S9vf3x8VE6FSngpgSb0woLq1heXj47O0tR1GKxTE1N+S5KCxQ5xAThHDozM9PV1QUnDGxziAD1cFFREfp4BcJ+f38bjcbx8XG4S2iJ2my2P26oi5JBJieUINStUDNAwZCVlSUZBM8c3d3d6OM9MD8EC9UoxGGBj4+P0dFR2AVwLxQShb0Mii0RZ/giSgaZnFCCYI6enh673a7T6dj9nB/rGfDMAZXpwsIC1iwl61ZOWK1Wu7+/D8UUPADhbXJyMlQesIPyXqt2gzUfEVFoNDY2Ss6cWJQMMjnvxWJyBHNAaTI4OHh/f8/2B2+yGOZ4enrCnSJuWJgxnINU7uIXqjA55EREVf/Q/5I4i+XJkelH/OYtsP7sYzAY5ufn/wdRhSHL8S992WFn2WXCWwAAAABJRU5ErkJggg==" alt="" name="Object3" align="absmiddle" hspace="8" />,其中aaarticlea/png;base64,iVBORw0KGgoAAAANSUhEUgAAADkAAAAVCAIAAABzFNGfAAAC/ElEQVR4nGP5//8/wxABLAPtABLAqFtpA2ji1h8/fqxevfr06dOvX7+G5AdVVdXm5mZMlcuXL+/p6bl///63b9+EhYUNDQ23bNlCglujo6MDAwNDQkLIc+jx48fDwsKArjQ3NxcVFYUI/v37F1Pl+vXrN27cuHDhQmVl5c+fP588ebKurg6PyVjceu3atcrKSvIceuvWLXd3dwcHhzlz5oiJieFXnJ2dffXqVUFBQSCbk5PT19d37dq1JLjV29v7woULurq6QCPevXtHqltLSkrU1dWBVrKyshJUzMzMvHTp0pycHLjIggULSHDrxIkTb968eefOHVJdCQTAeNy6deuqVauIcSgQtLa2Jicnb9++vb6+3szMjKB6dLcCA9XAwIAMhwLB48eP//37hzWhA9PuiRMn0ATj4uKcnZ2XLVtmZ2cXEBAwc+ZMfn5+Etx68eJFst0KSXlVVVXAJIQmJSIiglWLtLR0aWlpfHx8d3d3WlraypUrSXArMFzT09PJc6ukpKSmpiawBIiIiCBJIzAXpqamGhsb41eG7tZLly4BCzlkEVtb28OHD2PVjCkFLHSioqJsbGyA8YvHVmBAAosqZBFgPoMXcLgMR3crMH/8+vULWQSXQ7FKAUMU6FugU4A5zMfHBx71wHLe0dERrgxYlAKrgODgYBkZmU+fPgFrDWApCUw8+A1Hd+u6dev09PSsra1XrFghICAA9BwwSQHZmA4Flm5Ajx06dAhNvK2tDZhXgOVJTU3N27dvIYJoeQsY9kAzu7q63r9/z8fHB4z9pqYmYPmK33B0twKLcaAiODcjIwOYuzEdCgR5eXnAWgerlAcYYJWCgDowwKMAq+EE2gPAYsHJyQmrFDAetbW18WsnG2A1nLBbi4qKsEqdOnUKWNxQx2nEGU7YrcAkP2/ePAjXysrq2LFjEDYwQ9AuXLEaTsCtL168gLMfPnyoo6MDYe/YsQNYxOAq4SkEuAwnof0KrAZnzZoFZKioqABbqIsXL6amA2EAj+EAEJBIFUFDdeoAAAAASUVORK5CYII=" alt="" name="Object4" align="absmiddle" hspace="8" />是保留后的候选关键词。
(3)构建候选关键词图G = (V,E),其中V为节点集,由(2)生成的候选关键词组成,然后采用共现关系(co-occurrence)构造任两点之间的边,两个节点之间存在边仅当它们对应的词汇在长度为K的窗口中共现,K表示窗口大小,即最多共现K个单词。
(4)根据上面公式,迭代传播各节点的权重,直至收敛。
(5)对节点权重进行倒序排序,从而得到最重要的T个单词,作为候选关键词。
(6)由(5)得到最重要的T个单词,在原始文本中进行标记,若形成相邻词组,则组合成多词关键词。例如,文本中有句子“Matlab code for plotting ambiguity function”,如果“Matlab”和“code”均属于候选关键词,则组合成“Matlab code”加入关键词序列。
TextRank源码解析
1.读入文本,并切词,对切词结果统计共现关系,窗口默认为5,保存大cm中
cm = defaultdict(int)
#切词
words = tuple(self.tokenizer.cut(sentence))
for i, wp in enumerate(words): #(enumerate枚举的方式进行)
#过滤词性,停用词等
if self.pairfilter(wp):
for j in xrange(i + 1, i + self.span):
if j >= len(words):
break
if not self.pairfilter(words[j]):#过滤
continue
#保存到字典中
if allowPOS and withFlag:
cm[(wp, words[j])] += 1
else:
cm[(wp.word, words[j].word)] += 1
Textrank算法介绍的更多相关文章
- 基于TextRank算法的文本摘要
本文介绍TextRank算法及其在多篇单领域文本数据中抽取句子组成摘要中的应用. TextRank 算法是一种用于文本的基于图的排序算法,通过把文本分割成若干组成单元(句子),构建节点连接图,用句子之 ...
- TextRank算法及生产文本摘要方法介绍
TextRank 算法是一种用于文本的基于图的排序算法,其基本思想来源于谷歌的 PageRank算法,通过把文本分割成若干组成单元(句子),构建节点连接图,用句子之间的相似度作为边的权重,通过循环迭代 ...
- TextRank算法
TextRank是一种用来做关键词提取的算法,也可以用于提取短语和自动摘要.因为TextRank是基于PageRank的,所以首先简要介绍下PageRank算法. (1)PageRank PageRa ...
- 【原创】机器学习之PageRank算法应用与C#实现(1)算法介绍
考虑到知识的复杂性,连续性,将本算法及应用分为3篇文章,请关注,将在本月逐步发表. 1.机器学习之PageRank算法应用与C#实现(1)算法介绍 2.机器学习之PageRank算法应用与C#实现(2 ...
- TextRank算法提取关键词的Java实现
转载:码农场 » TextRank算法提取关键词的Java实现 谈起自动摘要算法,常见的并且最易实现的当属TF-IDF,但是感觉TF-IDF效果一般,不如TextRank好. TextRank是在 G ...
- KNN算法介绍
KNN算法全名为k-Nearest Neighbor,就是K最近邻的意思. 算法描述 KNN是一种分类算法,其基本思想是采用测量不同特征值之间的距离方法进行分类. 算法过程如下: 1.准备样本数据集( ...
- ISP基本框架及算法介绍
什么是ISP,他的工作原理是怎样的? ISP是Image Signal Processor的缩写,全称是影像处理器.在相机成像的整个环节中,它负责接收感光元件(Sensor)的原始信号数据,可以理解为 ...
- Python之常见算法介绍
一.算法介绍 1. 算法是什么 算法是指解题方案的准确而完整的描述,是一系列解决问题的清晰指令,算法代表着用系统的方法描述解决问题的策略机制.也就是说,能够对一定规范的输入,在有限时间内获得所要求的输 ...
- RETE算法介绍
RETE算法介绍一. rete概述Rete算法是一种前向规则快速匹配算法,其匹配速度与规则数目无关.Rete是拉丁文,对应英文是net,也就是网络.Rete算法通过形成一个rete网络进行模式匹配,利 ...
随机推荐
- java.map使用
Map以按键/数值对的形式存储数据,和数组非常相似,在数组中存在的索引,它们本身也是对象. Map的接口 Map---实现Map Map.Entry--Map的内部 ...
- JAVA IO 学习
Java流的分类 1.输入/输出流 输入流:只能向其读数据,不能写. 输出流:只能向其写数据,不能读. 所谓的输入输出都是相对应用程序而言的. 2.字节流/字符流 单位不同,字节流操作8位,字符流操作 ...
- Row_Number()显示行号
SELECT *, Row_Number() OVER (partition by deptid ORDER BY salary desc) rank FROM employee Row_Number ...
- 通过Robocopy+DOS 命令+Windows排程实现自动备份(将特定文件/目录备份至自动创建的以年月日命名的目标目录)
1. Software Requirement: 1.1.mirror.bat .mirror_SERVICE_BEGIN.mirror_SERVICE_END.robocopy.exe 1.2. C ...
- CString转string
如题,找了半天... //CString转string USES_CONVERSION; CString temp; temp = _T("kjdsaflkjdlfkj"); ch ...
- JS中offsetTop、clientTop、scrollTop、offsetTop各属性介绍
这里是javascript中制作滚动代码的常用属性 页可见区域宽: document.body.clientWidth;网页可见区域高: document.body.clientHeight;网页可见 ...
- jQuery学习笔记(在js中增加、删除及定位控件的操作)
代码内容很多都是从amazeui直接copy过来的,先声明,请不要说在下抄袭- - <!-------------------- HTML代码 ----------------------> ...
- thinkPHP--SQL连贯操作
一.连贯入门 连贯操作使用起来非常简单,比如查找到 id 为 1,2,3,4 中按照创建时间的倒序的前两 位. //连贯操作入门 $user = M('User'); var_dump($user-& ...
- 如何优雅的实现INotifyPropertyChanged接口
INotifyPropertyChanged接口在WPF或WinFrom程序中使用还是经常用到,常用于通知界面属性变更.标准写法如下: class NotifyObject : INotifyProp ...
- 第二次C语言作业
实验一:判断成绩等级. 给定一百分制成绩,要求输出成绩的等级.90以上为A,80-89为B,70-79为C,60-69为D,60分以下为E,输入大于100或小于0时输出"输入数据错误&quo ...