Java使用正则表达式取网页中的一段内容(以取Js方法为例)
关于正则表达式:
| 代码 | 说明 |
|---|---|
| . | 匹配除换行符以外的任意字符 |
| \w | 匹配字母或数字或下划线或汉字 |
| \s | 匹配任意的空白符 |
| \d | 匹配数字 |
| \b | 匹配单词的开始或结束 |
| ^ | 匹配字符串的开始 |
| $ | 匹配字符串的结束 |
| 代码/语法 | 说明 |
|---|---|
| * | 重复零次或更多次 |
| + | 重复一次或更多次 |
| ? | 重复零次或一次 |
| {n} | 重复n次 |
| {n,} | 重复n次或更多次 |
| {n,m} | 重复n到m次 |
| 代码/语法 | 说明 |
|---|---|
| \W | 匹配任意不是字母,数字,下划线,汉字的字符 |
| \S | 匹配任意不是空白符的字符 |
| \D | 匹配任意非数字的字符 |
| \B | 匹配不是单词开头或结束的位置 |
| [^x] | 匹配除了x以外的任意字符 |
| [^aeiou] | 匹配除了aeiou这几个字母以外的任意字符 |
| 分类 | 代码/语法 | 说明 |
|---|---|---|
| 捕获 | (exp) | 匹配exp,并捕获文本到自动命名的组里 |
| (?<name>exp) | 匹配exp,并捕获文本到名称为name的组里,也可以写成(?'name'exp) | |
| (?:exp) | 匹配exp,不捕获匹配的文本,也不给此分组分配组号 | |
| 零宽断言 | (?=exp) | 匹配exp前面的位置 |
| (?<=exp) | 匹配exp后面的位置 | |
| (?!exp) | 匹配后面跟的不是exp的位置 | |
| (?<!exp) | 匹配前面不是exp的位置 | |
| 注释 | (?#comment) | 这种类型的分组不对正则表达式的处理产生任何影响,用于提供注释让人阅读 |
| 代码/语法 | 说明 |
|---|---|
| *? | 重复任意次,但尽可能少重复 |
| +? | 重复1次或更多次,但尽可能少重复 |
| ?? | 重复0次或1次,但尽可能少重复 |
| {n,m}? | 重复n到m次,但尽可能少重复 |
| {n,}? | 重复n次以上,但尽可能少重复 |
| 名称 | 说明 |
|---|---|
| IgnoreCase(忽略大小写) | 匹配时不区分大小写。 |
| Multiline(多行模式) | 更改^和$的含义,使它们分别在任意一行的行首和行尾匹配,而不仅仅在整个字符串的开头和结尾匹配。(在此模式下,$的精确含意是:匹配\n之前的位置以及字符串结束前的位置.) |
| Singleline(单行模式) | 更改.的含义,使它与每一个字符匹配(包括换行符\n)。 |
| IgnorePatternWhitespace(忽略空白) | 忽略表达式中的非转义空白并启用由#标记的注释。 |
| ExplicitCapture(显式捕获) | 仅捕获已被显式命名的组。 |
| 代码/语法 | 说明 |
|---|---|
| \a | 报警字符(打印它的效果是电脑嘀一声) |
| \b | 通常是单词分界位置,但如果在字符类里使用代表退格 |
| \t | 制表符,Tab |
| \r | 回车 |
| \v | 竖向制表符 |
| \f | 换页符 |
| \n | 换行符 |
| \e | Escape |
| \0nn | ASCII代码中八进制代码为nn的字符 |
| \xnn | ASCII代码中十六进制代码为nn的字符 |
| \unnnn | Unicode代码中十六进制代码为nnnn的字符 |
| \cN | ASCII控制字符。比如\cC代表Ctrl+C |
| \A | 字符串开头(类似^,但不受处理多行选项的影响) |
| \Z | 字符串结尾或行尾(不受处理多行选项的影响) |
| \z | 字符串结尾(类似$,但不受处理多行选项的影响) |
| \G | 当前搜索的开头 |
| \p{name} | Unicode中命名为name的字符类,例如\p{IsGreek} |
| (?>exp) | 贪婪子表达式 |
| (?<x>-<y>exp) | 平衡组 |
| (?im-nsx:exp) | 在子表达式exp中改变处理选项 |
| (?im-nsx) | 为表达式后面的部分改变处理选项 |
| (?(exp)yes|no) | 把exp当作零宽正向先行断言,如果在这个位置能匹配,使用yes作为此组的表达式;否则使用no |
| (?(exp)yes) | 同上,只是使用空表达式作为no |
| (?(name)yes|no) | 如果命名为name的组捕获到了内容,使用yes作为表达式;否则使用no |
| (?(name)yes) | 同上,只是使用空表达式作为no |
这几个表引自http://www.jb51.net/tools/zhengze.html#getstarted
下面以获取淘宝登录页面(https://login.taobao.com/member/login.jhtml)的一个js方法为例:
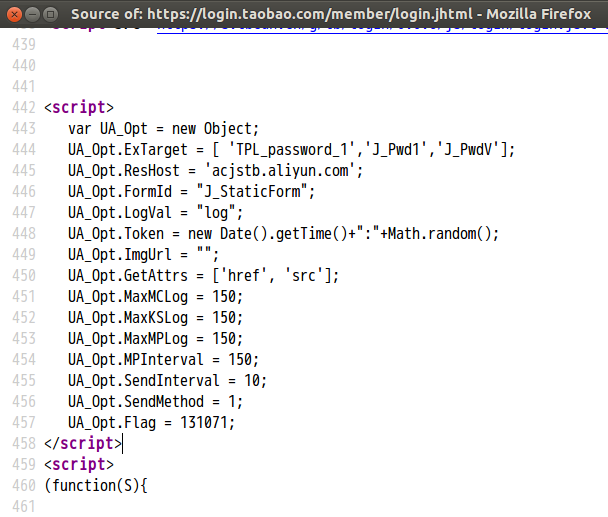
如下所示,取UA_Opt的定义这一段内容.
package com.amos; import org.apache.http.HttpResponse;
import org.apache.http.client.HttpClient;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.DefaultHttpClient;
import org.apache.http.util.EntityUtils; import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class Test{
//main方法:
public static void main(String args[]){
HttpClient httpClient = new DefaultHttpClient();
String loginURL = "https://login.taobao.com/member/login.jhtml"; HttpGet httpGet = new HttpGet(loginURL);
HttpResponse loginResponse = httpClient.execute(httpGet);
String loginString = EntityUtils.toString(loginResponse.getEntity());
System.out.println("loginString:\n"+loginString);
Matcher matcher = Pattern.compile("var UA_Opt =(.*?)</script>").matcher(loginString.replaceAll("\\r|\\t|\\n|\\a","")); while(matcher.find()){
System.out.println(matcher.group(1));
}
httpGet.releaseConnection();
}
}
注意上面的表格4的内容,这里用的就是上面的方法.
使用java截取js方法,首先,将换行符制表符回车符报警符都替换掉(loginString.replaceAll("\\r|\\t|\\n|\\a","")),这样在截取时就不会出问题了
截取的时候"var UA_Opt =(.*?)</script>",中间的(.*?)表示匹配任何内容,然后是以var UA_Opt=开的头,然后以</script>标签结尾,取到的内容,再以matcher.group(1),即取到了我们所需要的内容.
注意空格不要被替换掉了,不然一堆字符串就看的眼花了,最终的结果为:

new Object; UA_Opt.ExTarget = [ 'TPL_password_1','J_Pwd1','J_PwdV']; UA_Opt.ResHost = 'acjstb.aliyun.com'; UA_Opt.FormId = "J_StaticForm"; UA_Opt.LogVal = "log"; UA_Opt.Token = new Date().getTime()+":"+Math.random(); UA_Opt.ImgUrl = ""; UA_Opt.GetAttrs = ['href', 'src']; UA_Opt.MaxMCLog = 150; UA_Opt.MaxKSLog = 150; UA_Opt.MaxMPLog = 150; UA_Opt.MPInterval = 150; UA_Opt.SendInterval = 10; UA_Opt.SendMethod = 1; UA_Opt.Flag = 131071;
Java使用正则表达式取网页中的一段内容(以取Js方法为例)的更多相关文章
- Java 抓取网页中的内容【持续更新】
背景:前几天复习Java的时候看到URL类,当时就想写个小程序试试,迫于考试没有动手,今天写了下,感觉还不错 内容1. 抓取网页中的URL 知识点:Java URL+ 正则表达式 import jav ...
- php抓取网页中的内容
以下就是几种常用的用php抓取网页中的内容的方法.1.file_get_contentsPHP代码代码如下:>>>>>>>>>>>&g ...
- Java中用正则表达式截取字符串中
Java中用正则表达式截取字符串中第一个出现的英文左括号之前的字符串.比如:北京市(海淀区)(朝阳区)(西城区),截取结果为:北京市.正则表达式为() A ".*?(?=\\()" ...
- 利用Crowbar抓取网页异步加载的内容 [Python俱乐部]
利用Crowbar抓取网页异步加载的内容 [Python俱乐部] 利用Crowbar抓取网页异步加载的内容 在做 Web 信息提取.数据挖掘的过程中,一个关键步骤就是网页源代码的获取.但是出于各种原因 ...
- 如何在浏览器网页中显示word文件内容
如何在浏览器网页中显示word文件内容 把word文件读到byte[]中,再Response.OutputStream.Write(bytes)到客户端去 Page_Load事件中写: //FileS ...
- 怎样把报表放到网页中显示(Web页面与报表简单集成样例)
1.问题描写叙述 如今用户开发的系统基本上趋向于BS架构的浏览器/server模式.这些系统可能由不同的语言开发.如HTML.ASP.JSP.PHP等.因此须要将制作好的报表嵌入到这些页面中. Fin ...
- linux中快速清空文件内容的几种方法
这篇文章主要介绍了linux中快速清空文件内容的几种方法,需要的朋友可以参考下 $ : > filename $ > filename $ echo "" > f ...
- WinForm中嵌入WebBrowser,并且支持C#和JS方法的相互调用
纯粹WinForm界面不够友好,实现数据复杂度高的处理有些力不从心,所以看了看api以后决定用html来做. 我的wlw的代码插件不是很好用,大家凑合看吧 类前说明引用和权限 1: [Permissi ...
- 一个简单java爬虫爬取网页中邮箱并保存
此代码为一十分简单网络爬虫,仅供娱乐之用. java代码如下: package tool; import java.io.BufferedReader; import java.io.File; im ...
随机推荐
- python多进程提高cpu利用率
cpu参数: 1个物理cpu,2个逻辑cpu(超线程),单核 具体 http://blog.csdn.net/dba_waterbin/article/details/8644626 物理CPU. ...
- java.lang.IllegalArgumentException: template not initialized; call afterPropertiesSet() before using
在使用spring-data-redis时使用junit测试报错: java.lang.IllegalArgumentException: template not initialized; call ...
- clientWidth、offsetWidth和scrollWidth的区分
scrollWidth:对象的实际内容的宽度,不包边线宽度,会随对象中内容超过可视区后而变大. clientWidth:对象内容的可视区的宽度,不包滚动条等边线,会随对象显示大小的变化而改变. off ...
- [python学习] 介绍python的property,以及为什么要用setter,一个小栗子
python中的property是比较好用的. 先来一段代码 #-*- coding:utf-8 -*- class C(object): status_dict = { 1: 'accept', 2 ...
- PIC32MZ tutorial -- Core Timer
Core Timer is a very popular feature of PIC32 since it is a piece of the MIPS M4K core itself and is ...
- JUC.Lock(锁机制)学习笔记[附详细源码解析]
锁机制学习笔记 目录: CAS的意义 锁的一些基本原理 ReentrantLock的相关代码结构 两个重要的状态 I.AQS的state(int类型,32位) II.Node的waitStatus 获 ...
- spi can't create GMem lock
管理员身份启动cmd,输入下方命令 netsh winsock reset Successfully之后重启电脑就解决了
- c#的dllimport使用方法详解,调试找不到dll的方法
DllImport会按照顺序自动去寻找的地方: 1.exe所在目录 2.System32目录 3.环境变量目录所以只需要你把引用的DLL 拷贝到这三个目录下 就可以不用写路径了 或者可以这样serve ...
- htnl5中设置文本单行显示,超出部分打省略号,鼠标移到文本时alt出全部文本内容
Html代码: 1.<span class="my-span" title="无数无数无数无数无数">机构</span> Css样式: ...
- C# ADO.NET (sql语句连接方式)(增,删,改)
using System; using System.Collections.Generic; using System.Linq; using System.Web; using System.We ...