15_K-近邻算法之入住位置预测
案例:本次大赛的目的是预测一个人想签入到哪个地方。对于本次比赛的目的,Facebook的创建一 个人造的世界,包括位于10公里的10平方公里超过10万米的地方。对于一个给定的坐标,你的任务是返回最有可能的地方的排名列表。数据制作出类似于来自移动设备的位置的信号,给你需要什么与不准确的,嘈杂的价值观复杂的真实数据工作一番风味。不一致的和错误的位置数据可能破坏,如Facebook入住服务经验。
分析:表中数据代表的含义
row_id:登记时间的ID
xy:坐标
accuracy:定位准确性
time:时间戳
place_id:业务的ID,这是您预测的目标
思路:由于总数据量过大(上千万条数据),可以选取其中一小部分数据来进行预测,就是在10平方公里,挑一小块地方来进行预测。
因此要对x,y来进行范围的限制,通过data = data.query("x > 1.0 & x < 1.25 & y > 2.5 & y < 2.75")
对于time也要处理成我们熟悉的格式:time_value = pd.to_datetime(data["time"], unit='s'),
得到是一个日期格式,因此还要将日期格式转换成字典格式,便于我们后续的操作,time_value = pd.DatetimeIndex(time_value)
转换成字典之后就可以把按照年月日的格式,把里面的值取出来,然后添加到表中去,并且要把以前的time列给删除掉, 注意删除列的时候,axis=1!!!
data['day'] = time_value.day
data['hour'] = time_value.hour
data['weekday'] = time_value.weekday # 把时间特征戳删除
data = data.drop(['time'], axis=1)
下面对place_id进行处理,可以想象一下,在现实的入住中,一般会pass掉入住人数很少、评分很低的酒店等等
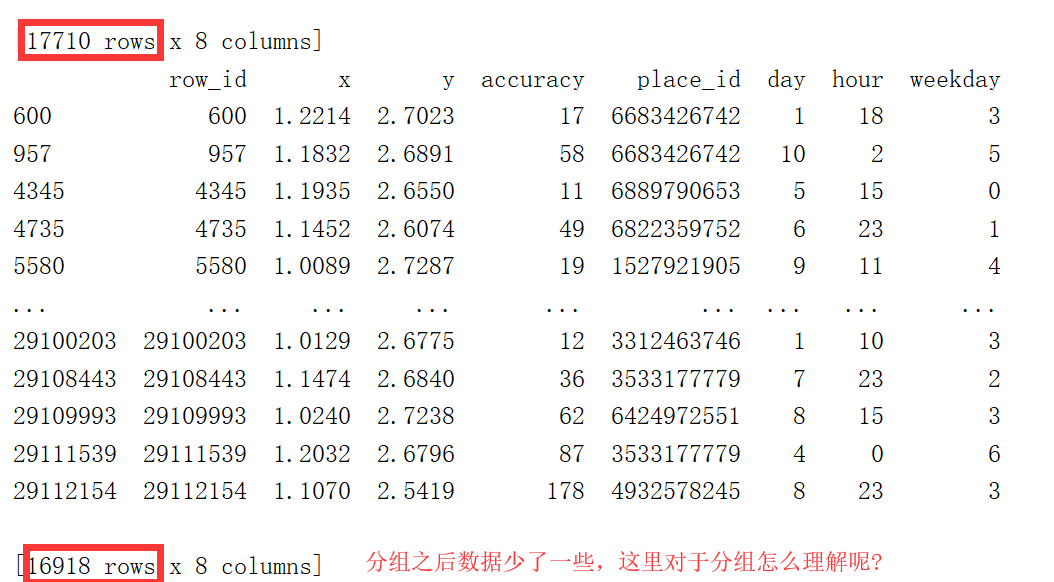
这三步有些不好理解,数据库中的分组?
# 把签到数量少于n个目标位置删除
place_count = data.groupby('place_id').count()
tf = place_count[place_count.row_id > 3].reset_index()
data = data[data['place_id'].isin(tf.place_id)]
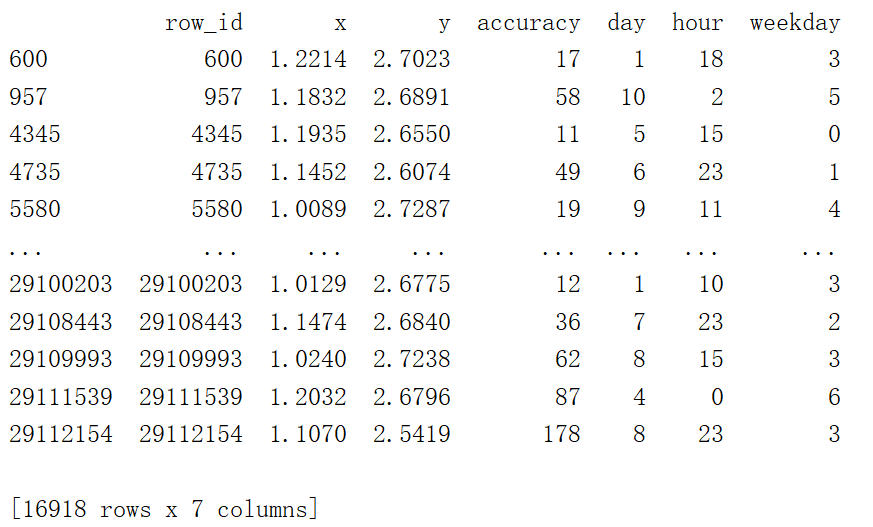
删除place_id,因为place_id作为目标值
# 取出数据当中的特征值和目标值
y = data['place_id']
x = data.drop(['place_id'], axis=1)
print(x)
案例步骤分解
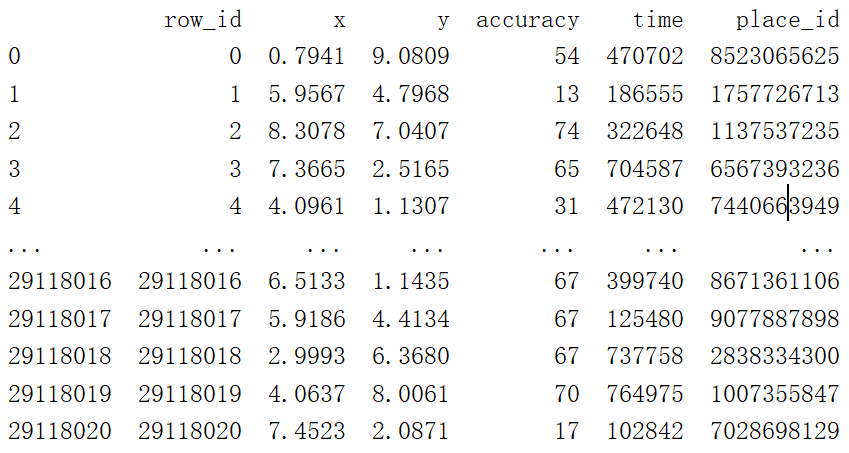
读取到最原始的数据
data = pd.read_csv("./predict/train.csv")
print(data)
结果:
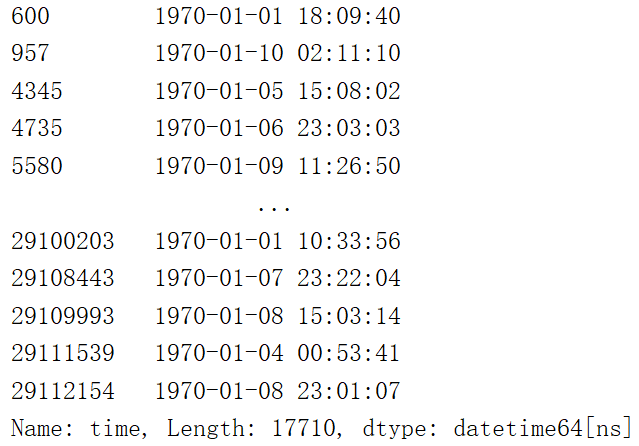
将时间戳转换为我们习惯上的时间,年月日时分秒
time_value = pd.to_datetime(data["time"],unit='s')
print(time_value)
结果:
# 把日期格式转换成字典格式
time_value = pd.DatetimeIndex(time_value) # 构造一些特征
data['day'] = time_value.day
data['hour'] = time_value.hour
data['weekday'] = time_value.weekday # 把时间特征戳删除
data = data.drop(['time'], axis=1)
print(data)
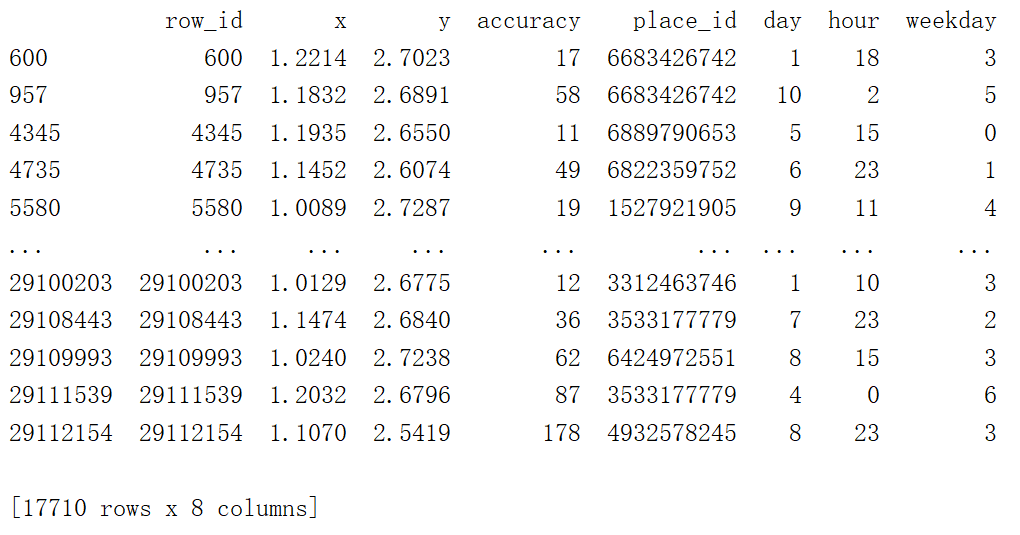
这是拿到了原始数据,未做特征化工程,直接进行预测
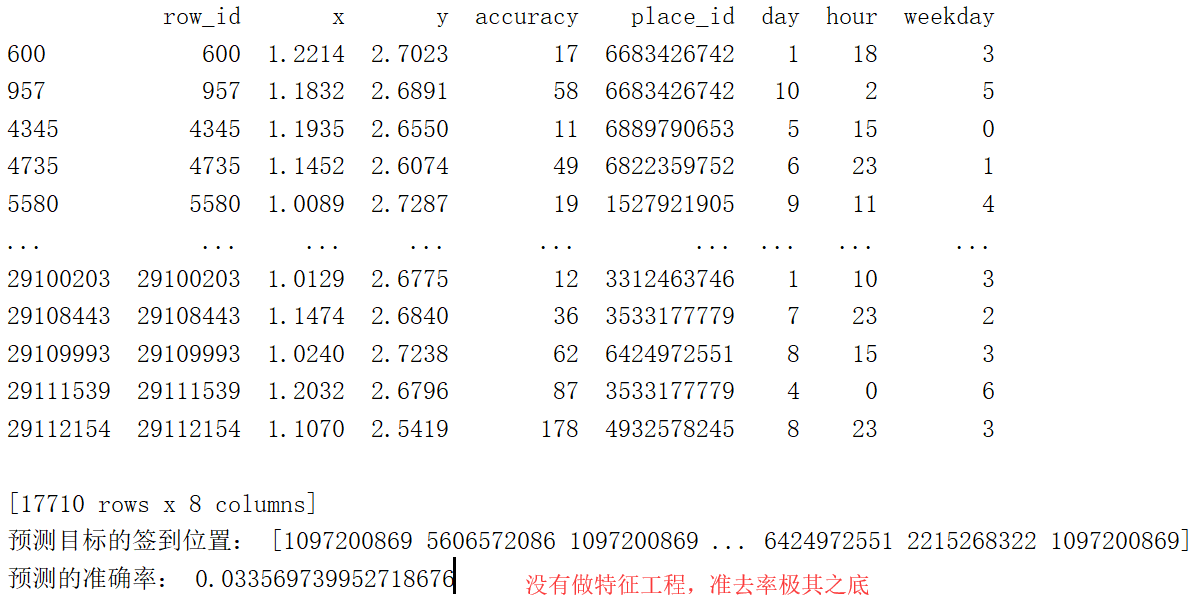
进行了特征工程化之后,准确率得到了提高。特征化工程可以简单的理解为消除一些范围相差很大的数据,对结果造成很大的影响,也就是避免结果仅有一小部分值来决定的情况。
# 特征工程(标准化)
std = StandardScaler()
# 对测试集和训练集的特征值进行标准化
x_train = std.fit_transform(x_train)
x_test = std.transform(x_test)
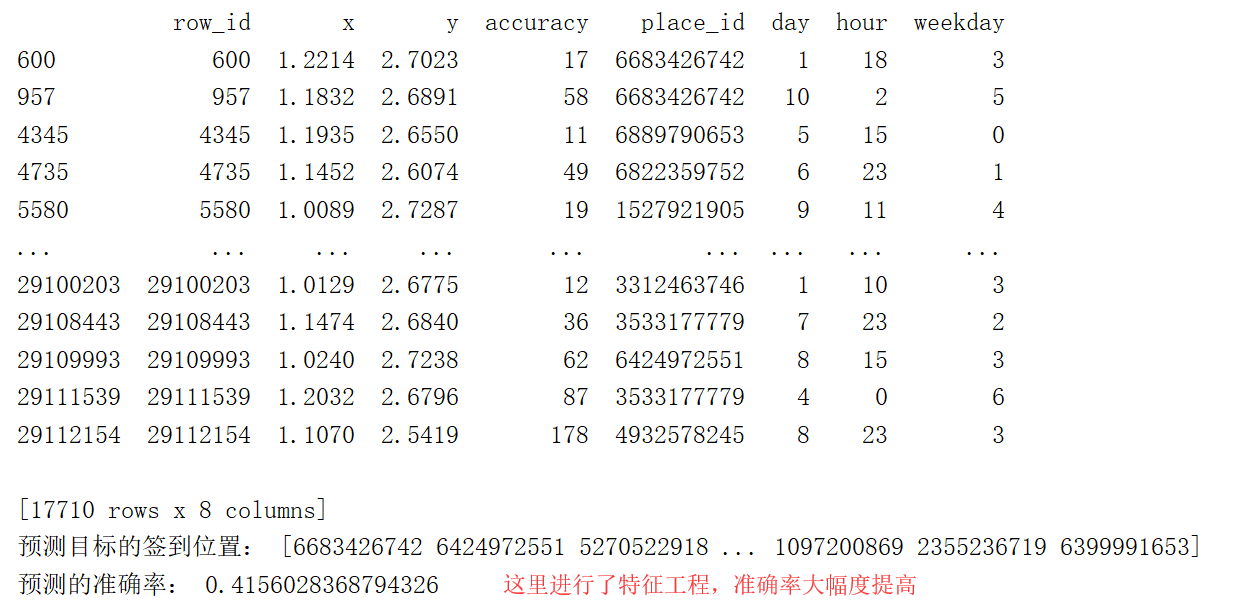
完整的案例:准确率70%
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.preprocessing import StandardScaler def knncls():
"""
K-近邻算法预测用户签到位置
:return:
""" # 读取数据
data = pd.read_csv("./predict/train.csv")
# print(data)
# 处理数据
# 1.缩小数据,查询数据筛选
data = data.query("x > 1.0 & x < 1.25 & y > 2.5 & y < 2.75")
# 2.处理日期数据
time_value = pd.to_datetime(data["time"], unit='s')
# print(time_value) # 把日期格式转换成字典格式
time_value = pd.DatetimeIndex(time_value) # 构造一些特征
data['day'] = time_value.day
data['hour'] = time_value.hour
data['weekday'] = time_value.weekday # 把时间特征戳删除
data = data.drop(['time'], axis=1)
print(data)
# 在sklearn中列axis=1(记住) # 把签到数量少于n个目标位置删除
place_count = data.groupby('place_id').count()
tf = place_count[place_count.row_id > 3].reset_index()
data = data[data['place_id'].isin(tf.place_id)] # 取出数据当中的特征值和目标值
y = data['place_id']
x = data.drop(['place_id'], axis=1)
x = data.drop(['row_id'], axis=1)
# 进行数据的分割训练集合测试集
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.25)
# 特征工程(标准化)
std = StandardScaler()
# 对测试集和训练集的特征值进行标准化
x_train = std.fit_transform(x_train)
x_test = std.transform(x_test)
# 进行算法流程
knn = KNeighborsClassifier(n_neighbors=5) # fit, predict, score
knn.fit(x_train, y_train)
# 得出预测结果
y_predict = knn.predict(x_test) print("预测目标的签到位置:", y_predict) # 训练集中的测试值和目标值中的测试值来进行验证,从而得出准确率
print("预测的准确率:", knn.score(x_test, y_test)) if __name__ == '__main__':
knncls()
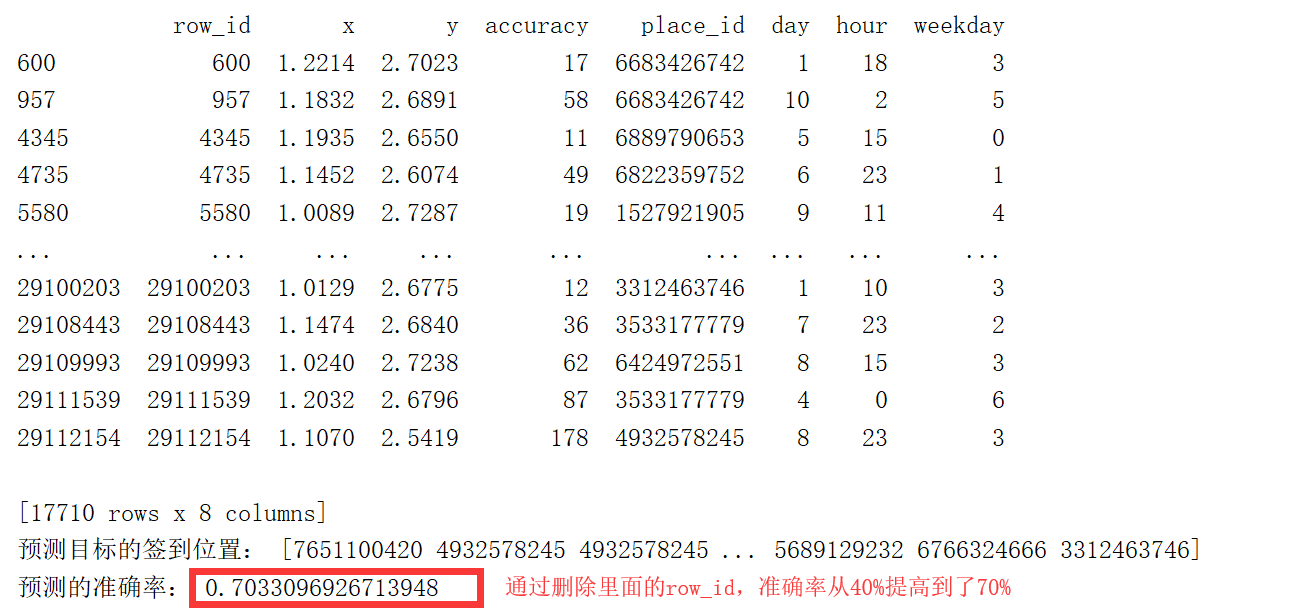
这里是只预测到了70%的准确率,因为k-means算法不是很常用,所以就先预测到这里,大家可以根据自己的想法,对表中的数据进行一些拆分、删除等。
15_K-近邻算法之入住位置预测的更多相关文章
- 机器学习之利用KNN近邻算法预测数据
前半部分是简介, 后半部分是案例 KNN近邻算法: 简单说就是采用测量不同特征值之间的距离方法进行分类(k-Nearest Neighbor,KNN) 优点: 精度高.对异常值不敏感.无数据输入假定 ...
- python 机器学习(二)分类算法-k近邻算法
一.什么是K近邻算法? 定义: 如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别. 来源: KNN算法最早是由Cover和Hart提 ...
- 机器学习实战笔记(Python实现)-01-K近邻算法(KNN)
--------------------------------------------------------------------------------------- 本系列文章为<机器 ...
- 从K近邻算法谈到KD树、SIFT+BBF算法
转自 http://blog.csdn.net/v_july_v/article/details/8203674 ,感谢july的辛勤劳动 前言 前两日,在微博上说:“到今天为止,我至少亏欠了3篇文章 ...
- 机器学习之K近邻算法(KNN)
机器学习之K近邻算法(KNN) 标签: python 算法 KNN 机械学习 苛求真理的欲望让我想要了解算法的本质,于是我开始了机械学习的算法之旅 from numpy import * import ...
- 【学习笔记】分类算法-k近邻算法
k-近邻算法采用测量不同特征值之间的距离来进行分类. 优点:精度高.对异常值不敏感.无数据输入假定 缺点:计算复杂度高.空间复杂度高 使用数据范围:数值型和标称型 用例子来理解k-近邻算法 电影可以按 ...
- <转>从K近邻算法、距离度量谈到KD树、SIFT+BBF算法
转自 http://blog.csdn.net/likika2012/article/details/39619687 前两日,在微博上说:“到今天为止,我至少亏欠了3篇文章待写:1.KD树:2.神经 ...
- k近邻算法(KNN)
k近邻算法(KNN) 定义:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别. from sklearn.model_selection ...
- 分类算法----k近邻算法
K最近邻(k-Nearest Neighbor,KNN)分类算法,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一.该方法的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的 ...
随机推荐
- Java oop第08章_JDBC01(入门)
一. JDBC的概念: JDBC(Java Database Connectivity)java数据库链接,是SUN公司为了方便我们Java程序员使用Java程序操作各种数据库管理系统制定的一套标准( ...
- Git创建本地库过程
- 2019-4-29-WPF-如何判断一个控件在滚动条的里面是用户可见
title author date CreateTime categories WPF 如何判断一个控件在滚动条的里面是用户可见 lindexi 2019-4-29 9:42:2 +0800 2019 ...
- Hive HA基本原理
- stelller插件与background-attachment配合使用,制作滚动页面
stelller插件与background-attachment:fixed配合使用,制作滚动页面
- CSS——用户界面样式
所谓的界面样式, 就是更改一些用户操作样式, 比如 更改用户的鼠标样式, 表单轮廓等.但是比如滚动条的样式改动受到了很多浏览器的抵制,因此我们就放弃了. 防止表单域拖拽 鼠标样式cursor 设置或检 ...
- thinkphp 空控制器
空控制器的概念是指当系统找不到请求的控制器名称的时候,系统会尝试定位空控制器(EmptyController),利用这个机制我们可以用来定制错误页面和进行URL的优化. 大理石平台价格表 现在我们把前 ...
- VC 复制移动删除重命名文件文件
说明: 1.以下封装了4个函数_CopyFile,_DeleteFile,_MoveFile,_ReNameFile 2.每个函数都先拷贝了原来的路径,保证了路径是以2个\0\0结尾.(如果不以2个\ ...
- LUOGU P4394 [BOI2008]Elect 选举 (背包)
传送门 解题思路 一眼看上去就像个背包,然后就是\(0/1\)背包改一改,结果发现过不了样例.后来想了一下发现要按\(a\)从大到小排序,因为如果对于一个>=总和的一半但不满足的情况来说,把最小 ...
- 浅谈简单实现file控件的图片预览,裁剪和上传。
1.图片预览之FileReader对象 FileReader 对象允许Web应用程序异步读取存储在用户计算机上的文件(或原始数据缓冲区)的内容,使用File或Blob对象指定要读取的文件或数据 ...