asp.net中正则表达式使用
一、限定符:限定符提供了一种简单方法,用于指定允许特定字符或字符集自身重复出现的次数。限定符始终引用限定符前(左边)的模式,通常是单个字符,除非使用括号创建模式组。
(一)非显示限定符
|
1、 |
*,描述“出现 0 或多次”。 |
|
2、 |
+,描述“出现 1 或多次”。 |
|
3、 |
?,描述“出现 0 或 1 次”。 |
(二)显式限定符
显式限定符使用花括号 {n,m} 及其中的数字值表示模式出现次数的上下限。
如果仅指定一个数字,则表示次数上限,例如,x{5} 将准确匹配 5 个 x 字符 (xxxxx),如果数字后跟一个逗号,如 x{5,},表示匹配任何出现次数大于 4 的 x 字符。
二、元字符
.(句点或点)元字符是最简单但最常用的一个字符。它可匹配任何单字符。如果要指定某些模式可包含任意组合的字符,使用句点非常有用,但一定要在特定长度范围内。
^ 元字符可指定字符串(或行)的开始。
$ 元字符可指定字符串(或行)的结束。通过将这些字符添加到模式的开始和结束处,可强制模式仅匹配精确匹配的输入字符串。如果 ^ 元字符用在方括号 [ ] 指定的字符类的开头,将有特殊的含义。具体内容后。
\ (反斜杠)元字符既可根据特殊含义“转义”字符,也可指定预定义集合元字符的实例。同样,具体内容见下。为了在正则表达式中包括文字样式的元字符,必须使用反斜杠进行“转义”。例如,如果要匹配以“c:\”开始的字符串,可使用:^c:\\。注意,要使用 ^ 元字符指出字符串必须以此模式作为开始,然后用反斜杠元字符转义文字反斜杠。
|(管道)元字符用于交替指定,特别用于在模式中指定“此或彼”。例如,a|b 将匹配包含“a”或“b”的任何输入内容,这与字符类 [ab] 非常类似。
( ) 括号用于给模式分组。它允许使用限定符让一个完整模式出现多次。为了便于阅读,或分开匹配特定的输入部分,可能允许分析或重新设置格式。
三、字符类:
字符类是正则表达式中的“迷你”语言,在方括号 [ ] 中定义。在表达式中使用字符类时,可在模式的此位置使用其中任何一个字符(但只能使用一个字符,除非使用了限定符)。请注意,不能使用字符类定义单词或模式,只能定义单个字符。
通过在括号中使用连字符 - 来定义字符的范围。连字符在字符类中有特殊的含义(不是在正则表达式中,因此,准确地说它不能叫正则表达式元字符),且仅在连字符不是第一个字符时,连字符才在字符类中有特殊含义。要使用连字符指定任何数值数字,可以使用 [0-9]。小写字母也一样,可以使用 [a-z],大写字母可以使用[a-z]。连字符定义的范围取决于使用的字符集。因此,字符在(例如)ascii 或 unicode 表中出现的顺序确定了在范围中包括的字符。如果需要在范围中包括连字符,将它指定为第一个字符。例如:[-.?] 将匹配 4 个字符中任何一个字符(注意,最后的字符是个空格)。另请注意,正则表达式元字符在字符类中不做特殊处理,所以这些元字符不需要转义。考虑到字符类是与其他正则表达式语言分开的一种语言,因此字符类有自己的规则和语法。
如果使用字符 ^ 作为字符类的第一个字符来否定此类,也可以匹配字符类成员以外的任何字符。因此,要匹配任何非元音字符,可以使用字符类 [^aaeeiioouu]。注意,如果要否定连字符,应将连字符作为字符类的第二个字符,如 [^-]。记住,^ 在字符类中的作用与它在正则表达式模式中的作用完全不同。
四、预定义的集合元字符
| 元字符 | 等效字符类 |
|
\a |
匹配铃声(警报);\u0007 |
|
\b |
匹配字符类外的字边界,它匹配退格字符,\u0008 |
|
\t |
匹配制表符,\u0009 |
|
\r |
匹配回车符,\u000d |
|
\w |
匹配垂直制表符,\u000b |
|
\f |
匹配换页符,\u000c |
|
\n |
匹配新行,\u000a |
|
\e |
匹配转义符,\u001b |
|
\040 |
匹配 3 位 8 进制 ascii 字符。\040 表示空格(十进制数 32)。 |
|
\x20 |
使用 2 位 16 进制数匹配 ascii 字符。此例中,\x2- 表示空格。 |
|
\cc |
匹配 ascii 控制字符,此例中是 ctrl-c。 |
|
\u0020 |
使用 4 位 16 进制数匹配 unicode 字符。此例中 \u0020 是空格。 |
|
\* |
不代表预定义字符类的任意字符都只作为该字符本身对待。因此,\* 等同于 \x2a(是文字 *,不是 * 元字符)。 |
|
\p{name} |
匹配已命名字符类“name”中的任意字符。支持名称是 unicode 组和块范围。例如,ll、nd、z、isgreek、isboxdrawing 和 sc(货币)。 |
|
\p{name} |
匹配已命名字符类“name”中不包括的文本。 |
|
\w |
匹配任意单词字符。对于非 unicode 和 ecmascript 实现,这等同于 [a-za-z_0-9]。在 unicode 类别中,这等同于 [\p{ll}\p{lu}\p{lt}\p{lo}\p{nd}\p{pc}]。 |
|
\w |
\w 的否定,等效于 ecmascript 兼容集合 [^a-za-z_0-9] 或 unicode 字符类别[^\p{ll}\p{lu}\p{lt}\p{lo}\p{nd}\p{pc}]。 |
|
\s |
匹配任意空白区域字符。等效于 unicode 字符类 [\f\n\r\t\v\x85\p{z}]。如果使用 ecmascript 选项指定 ecmascript 兼容方式,\s 等效于 [ \f\n\r\t\v] (请注意前导空格)。 |
|
\S |
匹配任意非空白区域字符。等效于 unicode 字符类别 [^\f\n\r\t\v\x85\p{z}]。如果使用 ecmascript 选项指定 ecmascript 兼容方式,\s 等效于 [^ \f\n\r\t\v] (请注意 ^ 后的空格)。 |
|
\d |
匹配任意十进制数字。在 ecmascript 方式下,等效于 unicode 的 [\p{nd}]、非 unicode 的 [0-9]。 |
|
\d |
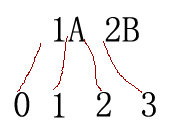
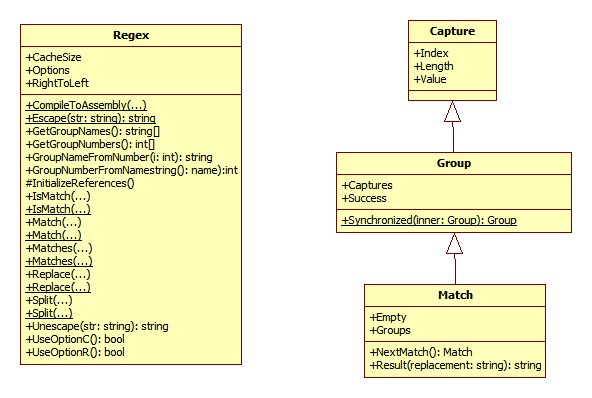
匹配任意非十进制数字。在 ecmascript 方式下,等效于 unicode 的 [\p{nd}]、非 unicode 的 [^0-9]。 C#正则表达式编程(一):C#中有关正则的类正则表达式是一门灵活性非常强的语言,匹配同样的字符串可能在不同的开发人员那里会得到不同的结果,在平常的时候也是用的时候看看相关资料,不用的时候就丢在脑后了,尽管在处理大部分情况下都能迅速处理,但是处理一些复杂的情况效率仍是不高,借着前阵子做过的一个项目涉及到正则表达式的机会,将有关资料阅读了一遍并结合了自己的体会,整理了几篇利用 C# 进行正则表达式编程的文章,一来加深自己的印象和理解,二来供博客上的读者学习借鉴。 在 .NET 中提供了对正则表达式的支持,并且提供了相关的类,分别有: Regex 、 Match 、 Group 、 Capture 、 RegexOptions 、 MatchCollection 、 GroupCollection 、 CaptureCollection 。它们之间的关联如下: 对它们描述如下: Regex :正则表达式类,代表了一个不可变的正则表达式。 Match :代表了 Regex 类的实例的一次匹配结果,可以通过 Regex 的 Match() 实例方法返回一个 Match 的实例。 MatchCollection :代表了 Regex 类的实例的所有匹配结果,可以通过 Regex 的 Matches() 实例方法返回一个 MatchCollection 的实例。 Group :表示单个捕获组的结果。由于一次匹配可能包含 0 个、 1 个或多个分组,所以 Match 的实例中返回的是捕获组集合的结果,即 GroupCollection 。 GroupCollection :表示单个匹配中的多个捕获组的集合,可以通过 Match 的 Groups 实例属性返回 GroupCollection 的实例。 Capture :表示单个捕获中的一个子字符串。同 Group 一样,由于一个捕获中可能包含 0 个、 1 个或多个子字符串,所以 Group 的实例中返回的是子字符串集合的结果,即 CaptureCollection 。 CaptureCollection :默认表示按照从里到外、从左到右的顺序由捕获组匹配到的所有子字符串集合,可以通过 Group 或者 Match 的 Captures 实例属性返回 CaptureCollection 的实例。注意,可以使用 RegexOptions.RightToLeft 来改变这种匹配顺序。 RegexOptions :提供用于设置正则表达式选项的枚举值。 像上面提到的 RightToLeft 就是它的一个枚举值之一,除此之外还有 None 、 IgnoreCase 、 Multiline 、 ExplicitCapture 、 Compiled 、 Singleline 、 IgnorePatternWhitespace 、 RightToLeft 、 ECMAScript 及 CultureInvariant 。 RegexOptions 枚举值可以相加,比如我们想匹配不区分大小写的字符串“ abc ”并且还想提高一下执行速度,那么可以写如下代码: RegexOptions options=RegexOptions.IgnoreCase|RegexOptions.Compiled; Regex regex=new Regex("abc",options); Regex 、 Match 、 Group 及 Capture 的关系及成员 从上图可以看出 Regex 类提供了许多静态方法,很多方法还提供了多种重载方式(在图中对存在多种参数重载的方法都以“ ... ”表示),除此之外我们还会发现 Capture 、 Group及 Match 之间存在继承关系(说实在话刚开始用的时候我发现它们之间存在着很多相同的字段,这让我当时迷惑不已,希望大家看到这个图后不要再像我当初那样迷惑了)。 在使用 C# 中的正则表达式进行文本处理之前先花点时间了解一下 .NET 中有关正则表达式的类和它们之间的关系是有必要的,这篇就算是预热篇了,在开始学习正则表达式之前做做热身运动。虽然在 C# 中有关正则表达式的类不多,但是对于初学者来说还是容易引起混淆,从而出现不知道该用哪些类的哪些方法或者属性的情况,这篇算是做个初步介绍吧。下一篇就先讲述 Regex 类,利用 Regex 可以用来替换、分割和处理字符串。 C#正则表达式编程(二):Regex类用法 对于正则表达式的应用,基本上可以分为验证、提取、分割和替换。仅仅利用Regex类就可以实现验证和简单替换。 输出结果:字符串中包含有敏感词:孙权! view plaincopy to clipboardprint? 输出结果:字符串中包含有敏感词:def! 在上面的例子中,实例化Regex时采用了两个带参数的构造函数,其中第二个参数就是上一篇中提到的RegexOptions枚举,RegexOptions.IgnoreCase表示匹配字符串的时候不管大小写是否一致。 view plaincopy to clipboardprint? 其实在.NET Framework中很多类都有这样类似的情况,在System.IO命名空间下还有File及FileInfo这样的静态类和非静态类的情况,其实它们提供了相似的功能,用小沈阳的话说“这是为什么呢”?有部分是出自效率的考虑,并且也有出自让代码编写方便和看起来简洁的因素。对于偶尔一半次为之的情况,建议使用静态方法,这样有可能会提高效率(因为采用静态方法调用的正则表达式会被内部缓存,默认情况下会缓存15个,可以通过设置Regex类的CacheSize属性来更改缓存个数),如果是要在循环中多次使用,那就采用实例方法吧。 view plaincopy to clipboardprint? view plaincopy to clipboardprint?
|
 C#正则表达式编程(三):Match类和Group类用法
C#正则表达式编程(三):Match类和Group类用法 
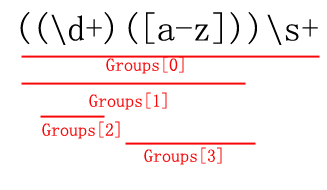
asp.net中正则表达式使用的更多相关文章
- ASP.NET中的XML和JSON
一.DOM简介 1.XML 定义:XML是一种跨语言.跨平台的数据储存格式 2.什么是DOM DOM(document object model)文档对象模型:是一种允许程序或脚本动态的访问更新文档内 ...
- UrlRewrite(URL重写)--ASP.NET中的实现
概述 今天看了下URL重写的实现,主要看的是MS 的URL Rewrite. URL重写的优点有:更友好的URL,支持老版本的URL URL重写的缺点有:最主要的缺点是性能低下,因为如果要支持无后缀的 ...
- asp.net 验证正则表达式
基本元字符: . 任意的一个非换行字符 [] 集合匹配,匹配一个[]中出现的字符. 是在多个字符中取一个. () 调整优先级的作用. 还有一个分组的作用 | 或的意思,测试|一下. 注意,或的优先级最 ...
- ASP.NET中的指令:
来源:http://www.cnblogs.com/zhuisha/archive/2008/07/02/1234222.html ASP.NET中的指令: @Page指令: @Page指令只能在.a ...
- ASP.NET中JSON的序列化和反序列化
JSON是专门为浏览器中的网页上运行的JavaScript代码而设计的一种数据格式.在网站应用中使用JSON的场景越来越多,本文介绍 ASP.NET中JSON的序列化和反序列化,主要对JSON的简单介 ...
- 转载MSDN 在ASP.NET 中执行 URL 重写
转载文章原网址 http://msdn.microsoft.com/zh-cn/library/ms972974.aspx 摘要:介绍如何使用 Microsoft ASP.NET 执行动态 URL 重 ...
- ASP.NET中验证控件的使用
转自:http://www.cnblogs.com/yangmingming/archive/2010/03/09/1682006.html 前言: 前几日,无奈用JS判断控件的有效性,发现的确是一件 ...
- 在asp.net中如何实现伪静态页 [转]
我在这里就不过多讨论静态页.伪静态页.动态页的长短利弊了.只是单纯的讲解如何在asp.net中如何实现伪静态页,以帮助有这方面有需求的朋友,快速解决boss派下来的任务.(拿奖金的时候,记得有我一份功 ...
- ASP.NET中 RegularExpressValidator(正则验证)的使用
原文:ASP.NET中 RegularExpressValidator(正则验证)的使用 ylbtech-ASP.NET-Control-Validator: RegularExpressValida ...
随机推荐
- 后端跨域的N种方法
简单来说,CORS是一种访问机制,英文全称是Cross-Origin Resource Sharing,即我们常说的跨域资源共享,通过在服务器端设置响应头,把发起跨域的原始域名添加到Access-Co ...
- 网站SEO中服务器优化的三个问题
网站做好之后,站长第一件事就是想到去做SEO,但是有一些网站在做优化的时候,出现一些奇怪的情况,比如说优化已经不错的网站,排名突然就掉下来了:还有一些网站各项优化工作都是非常认真,但是排名却一直不上来 ...
- 洛谷P4526 【模板】自适应辛普森法2
P4526 [模板]自适应辛普森法2 洛谷传送门 题目描述 计算积分 保留至小数点后5位.若积分发散,请输出"orz". 输入格式 一行,包含一个实数,为a的值 输出格式 一行,积 ...
- Spring Aop和Spring Ioc(一)
Spring Aop Aop: 面向切面编程的本质:面向切面编程,指扩展功能不修改源代码,将功能代码从业务逻辑代码中分离出来. 1:主要功能:日志记录,性能统计,安全控制,事务处理,异常处理等等. 2 ...
- JavaSE学习笔记(5)---内部类和String类
JavaSE学习笔记(5)---内部类和String类 一.内部类基础 转自菜鸟教程 在 Java 中,可以将一个类定义在另一个类里面或者一个方法里面,这样的类称为内部类.广泛意义上的内部类一般来 ...
- 什么是json? 什么是xml?JSON与XML的区别比较
JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式.它使得人们很容易的进行阅读和编写.同时也方便了机器进行解析和生成.它是基于 JavaScript Prog ...
- SpringJpa CRUD 代码生成器
利用业余时间撸了一个Spring Jpa代码生成器jpa-codegen. 简介 这是一款基于Freemarker模板驱动的代码生成器. 依据现有的实体类代码,自动生成CRUD代码,解放双手,加快开发 ...
- latex技巧:弧AB
\usepackage{yhmath} $\wideparen{ABCDEFG}$
- C#调用C++类库例子
一.新建一个解决方案,并在解决方案下添加一个.netframework的项目,命名为FrameworkConsoleTest.再添加一个C++的动态链接库DLL项目,命名为EncryptBase. 二 ...
- vue项目常用方法封装,持续更新中。。。
vue项目中可以直接使用 1.常用工具类untils.js中 /* * 验证手机号是否合格 * true--说明合格 */ export function isPhone(phoneStr){ let ...