基于python的二分搜索和例题
二分搜索
二分概念
二分搜索是一种在有序数组中查找某一特定元素的搜索算法。
搜索过程从数组的中间元素开始,如果中间元素正好是要查找的元素,则搜索过程结束;
如果某一特定元素大于或者小于中间元素,则在数组大于或小于中间元素的那一半中查找,而且跟开始一样从中间元素开始比较。
如果在某一步骤数组为空,则代表找不到。这种搜索算法每一次比较都使搜索范围缩小一半。
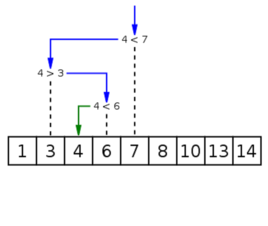
注意
二分搜索或者说二分查找应该注意的几个点:
- 区间的开闭:左闭右闭,还是左闭右开
- 循环条件:left<right,还是left<=right,实际和第一点是呼应的
- 更新条件:左右区间的更新,同样要对应开闭原则,维持区间的循环不变性
- 返回值:返回left或right,还是需要再判断
- 搜索条件:大于,等于,小于,大于等于,小于等于
例题
以下是一些二分搜索的一些例题,请细品!
01. 在旋转之后的列表查找最小值
假设有一个升序排列的数列在某个未知节点处被前后调换,请找到数列中的最小值
例如:[4, 5, 6, 7, 1, 2, 3]
def search_min(li):
if len(li) == 0:
return -1 left, right = 0, len(li) - 1
while left + 1 < right:
# 左边小于右边,证明有序直接返回左边元素
if li[left] < li[right]:
return li[left] mid = left + (right - left) // 2
if li[mid] > li[left]:
left = mid + 1
else:
right = mid return li[left] if li[left] < li[right] else li[right] li= [4, 5, 6, 7, 1, 2, 3]
print(search_min(li)) #
02. 旋转列表查找数值
假设有一个升序排列的数列在某个未知节点处被前后调换,请找到数列中的item
例如:在[4, 5, 6, 7, 8, 1, 2, 3] 找 1 返回index 5
def search_item(li, item):
if len(li) == 0:
return -1 left, right = 0, len(li)-1
while left+1 < right:
mid = left + (right-left) //2 if li[mid] == item:
return mid if li[mid] > li[left]:
if li[mid] >= item and li[left] <= item:
right = mid
else:
left = mid
else:
if li[mid] <= item and li[right] >= item:
left = mid
else:
right = mid if li[left] == item:
return left
elif li[right] == item:
return right
else:
return -1 li= [4, 5, 6, 7, 1, 2, 3]
print(search_item(li, 3)) #
03. 搜索插入位置
给定有序数组和一个目标值,如果在数组中找到此目标值则返回目标值的index,
如果没有找到,则返回目标值按顺序应该被插入的位置index.
注:可以假设数组中不存在重复数。
def search_insert_position(li, item):
if len(li) == 0:
return 0 left, right = 0, len(li) - 1
while left + 1 < right:
mid = left + (right - left) // 2
if li[mid] == item:
return mid if li[mid] < item:
left = mid
else:
right = mid if li[left] >= item:
return left
if li[right] >= item:
return right return right+1 li= [1, 2, 3, 4, 5, 6, 7]
print(search_insert_position(li, 3)) #
04. 搜索区间
找给定的目标值的开始和结束的位置
例如 给定列表[1, 2, 3, 3, 4, 4, 5, 5, 5, 5, 6, 7, 8, 9], 目标值5,返回(6,9)
def search_range(li, item):
if len(li) == 0:
return -1, -1 # 搜索左边边界
left, right = 0, len(li) - 1
while left + 1 < right:
mid = left + (right - left) // 2
if li[mid] == item:
right = mid
elif li[mid] < item:
left = mid
else:
right = mid if li[left] == item:
left_bound = left
elif li[right] == item:
left_bound = right
else:
return -1, -1 # 搜索右边边界
left, right = 0, len(li) - 1
while left + 1 < right:
mid = left + (right - left) // 2
if li[mid] == item:
left = mid
elif li[mid] < item:
left = mid
else:
right = mid if li[right] == item:
right_bound = right
elif li[left] == item:
right_bound = left
else:
return -1, -1 return left_bound, right_bound li = [1, 2, 3, 3, 4, 4, 5, 5, 5, 5, 6, 7, 8, 9]
print(search_range(li, 5)) # (6, 9)
05. 再有空字符串的列表中查找数值
给定一个有序的字符串序列,这个序列中的字符串用空字符隔开,请写出找到给定字符串位置的方法
例如:["", "", 1, "", 3, 4, "", "", "", 5, "", 6, 7, 8, "", ""]
def search_item(li, item):
if len(li) == 0:
return -1 left, right = 0, len(li) - 1 while left + 1 < right:
# 去除右边的空字符串
while left + 1 < right and li[right] == "":
right -= 1 if li[right] == "":
right -= 1 if right < left:
return -1 # 获取mid
mid = left + (right - left) // 2
while li[mid] == "":
mid += 1 if li[mid] == item:
return mid if li[mid] < item:
left = mid + 1
else:
right = mid - 1 if li[left] == item:
return left
elif li[right] == item:
return right
else:
return -1 li = ["", "", 1, "", 3, 4, "", "", "", 5, "", 6, 7, 8, "", ""]
print(search_item(li, 5)) #
06. 查找某个元素第一次出现的位置
在数据流中常用, 不知道列表长度
例如:[0, 1, 2, 3, 4, 4, 4, 5, 5, 6, 7, 8, 9] 查找5, 返回index 7
def search_first(li, item):
left, right = 0, 1 while li[right] < item:
left = right
right *= 2 if right > len(li):
right = len(li) - 1
break while left + 1 < right:
mid = left + (right - left) // 2 if li[mid] == item:
right = mid
elif li[mid] < item:
left = mid
else:
right = mid if li[left] == item:
return left
elif li[right] == item:
return right
else:
return -1 li = [0, 1, 2, 3, 4, 4, 4, 5, 5, 6, 7, 8, 9]
print(search_first(li, 5)) #
07. 供暖设备
冬季来临!你的首要任务是设计一款有固定供暖半径的供暖设备来给所有的房屋供暖。
现在你知道所有房屋以及供暖设备在同一水平线上的位置分布,请找到能给所有房屋供暖的供暖设备的最小供暖半径。
你的输入是每个房屋及每个供暖设备的位置,输出应该是供暖设备的最小半径。
from bisect import bisect # 找到可以插入的位置
def search_insert_position(li, item):
if len(li) == 0:
return 0 left, right = 0, len(li) - 1
while left + 1 < right:
mid = left + (right - left) // 2
if li[mid] == item:
return mid if li[mid] < item:
left = mid
else:
right = mid if li[left] >= item:
return left
if li[right] >= item:
return right return right + 1 def findRadius(houses, heaters):
# 时间复杂度(nlogn)
heaters.sort()
ans = 0
for house in houses:
# 查找房子可插入供暖设备中的位置, 返回index
# index = bisect(heaters, h)
index = search_insert_position(heaters, house)
# 左边界大于等于0,否则为负无穷
left = heaters[index - 1] if index - 1 >= 0 else float('-inf')
right = heaters[index] if index < len(heaters) else float('inf')
# 先求房子与每一个供暖设备距离的最小值,再求其中的最大值
ans = max(ans, min(house-left, right-house))
return ans houses = [1,2,3,6]
heaters = [1,4]
print(findRadius(houses, heaters)) #
08. 求平方根
例如 输入40,输出6, 6*6<40<7*7
def sqrt(item):
if item == 0:
return 0 left, right = 1, item
while left <= right:
mid = left + (right-left) // 2
if item // mid == mid:
return mid if item // mid > mid:
left = mid + 1
else:
right = mid -1 return right print(sqrt(80)) #
09. 找重复数
给定一个包含n+1个整数的数组,其中每个元素为1到n闭区间的整数值,请证明至少存在一个重复数。
假设只有一个重复数,请找到这个重复数。
def find_duplicate(li):
left = 0
right = len(li) - 1 while left < right:
mid = left + (right - left) // 2
count = 0
for i in li:
if i <= mid:
count += 1
if count <= mid:
left = mid + 1
else:
right = mid return left li = [3, 5, 6, 3, 1, 4, 2]
print(find_duplicate(li)) #
10. 合并区间
给定一个区间的集合,将所有存在交叉范围的区间进行合并。
输入: [[1,3],[2,6],[8,10],[15,18]]
输出: [[1,6],[8,10],[15,18]]
说明: 因为区间 [1,3] 和 [2,6] 存在交叉范围, 所以将他们合并为[1,6]
# 定义区间
class Interval:
def __init__(self, s=0, e=0):
self.start = s
self.end = e def __str__(self):
return f"[{self.start}, {self.end}]" def __repr__(self):
return "[%s, %s]" % (self.start, self.end) def merge(intervals):
# 区间按照第一个元素排序
intervals.sort(key=lambda x: x.start) # 定义一个新的列表存放区间
merged = []
for interval in intervals:
# 如果合并区间列表为空或当前区间与上一个区间不重叠,只需附加它即可。
if not merged or merged[-1].end < interval.start:
merged.append(interval)
else:
# 有重叠将当前区间和上一个区间合并
merged[-1].end = max(merged[-1].end, interval.end) return merged intervals1 = Interval(1, 3)
intervals2 = Interval(2, 6)
intervals3 = Interval(8, 10)
intervals4 = Interval(15, 18)
intervals = [intervals1, intervals2, intervals3, intervals4]
print(merge(intervals)) # [[1, 6], [8, 10], [15, 18]]
11. 插入区间
给定一个没有交叉范围的区间集合,在这个集合中插入一个新的区间(如果需要,请进行合并)。
你可以认为这些区间已经初始时根据他们的头元素进行过排序
输入:区间集合=[[1,3],[6,9]], 新区间 = [2,5]
输出:[[1,5],[6,9]]
# 定义区间
class Interval:
def __init__(self, s=0, e=0):
self.start = s
self.end = e def __str__(self):
return f"[{self.start}, {self.end}]" def __repr__(self):
return "[%s, %s]" % (self.start, self.end) def insert(intervals, newInterval):
merged = []
for i in intervals:
if newInterval is None or i.end < newInterval.start:
merged += i,
elif i.start > newInterval.end:
merged += newInterval,
merged += i,
newInterval = None
else:
newInterval.start = min(newInterval.start, i.start)
newInterval.end = max(newInterval.end, i.end)
if newInterval is not None:
merged += newInterval,
return merged intervals1 = Interval(1, 3)
intervals2 = Interval(6, 9)
intervals = [intervals1, intervals2]
new = Interval(2, 5)
print(insert(intervals, new)) # [[1, 5], [6, 9]]
解法..
# 定义区间
class Interval:
def __init__(self, s=0, e=0):
self.start = s
self.end = e def __str__(self):
return f"[{self.start}, {self.end}]" def __repr__(self):
return "[%s, %s]" % (self.start, self.end) def insert2(intervals, newInterval):
if len(intervals) == 0:
intervals += newInterval, startPos = searchPosition(intervals, newInterval.start)
endPos = searchPosition(intervals, newInterval.end) newStart = 0 # case 1:
# startPos
# A
# |____| |____| |____|
# <-
# startPos is less than A
# and intervals[startPos].end >= newInterval.start
# then
# new A
# |____| |____| |____|
# <-
# newInterval starts within ONE interval
# so newStart = intervals[startPos].start
if (startPos >= 0 and intervals[startPos].end >= newInterval.start):
newStart = intervals[startPos].start
else:
# case 2:
# startPos = -1
# A
# |____| |____| |____|
# newInterval starts before 1st interval
# so newStart = newInterval.start # case 3:
# startPos >= 0
# A B
# |____| |____| |____|
# newInterval starts between A and B
# so NOT intervals[startPos].end >= newInterval.start
# so newStart = newInterval.start
newStart = newInterval.start
startPos += 1 newEnd = 0
# case 1:
# endPos >= 0
# endPos
# A
# |____| |____| |____|
# <-
# endPos is less than A
# so newEnd = Math.max(newInterval.end, intervals.get(endPos).end)
if (endPos >= 0):
newEnd = max(newInterval.end, intervals[endPos].end)
else:
# case 2:
# endPos < 0
# endPos
# A
# |____| |____| |____|
#
# endPos is before 1st interval
# create a new interval
newEnd = newInterval.end for i in range(startPos, endPos + 1):
intervals.pop(startPos) # note: NOT i, but startPos, since one element is removed. intervals.insert(startPos, Interval(newStart, newEnd))
return intervals # return (actual insertion position - 1)
def searchPosition(intervals, x):
start = 0
end = len(intervals) - 1
while (start <= end):
mid = start + (end - start) // 2
if (intervals[mid].start == x):
return mid
if (intervals[mid].start < x):
start = mid + 1
else:
end = mid - 1 return end
2
~>.<~
基于python的二分搜索和例题的更多相关文章
- 基于python的分治法和例题
分治法 分治法的核心 分:将一个复杂的问题分成两个或更多的相同或相似的子问题,再把子问题分成更小的子问题 治:最后的子问题,可以很容易的直接求解 合:所有子问题的解合并起来就是原问题的解 分治法的特征 ...
- 【Machine Learning】决策树案例:基于python的商品购买能力预测系统
决策树在商品购买能力预测案例中的算法实现 作者:白宁超 2016年12月24日22:05:42 摘要:随着机器学习和深度学习的热潮,各种图书层出不穷.然而多数是基础理论知识介绍,缺乏实现的深入理解.本 ...
- 基于Python+Django的Kubernetes集群管理平台
➠更多技术干货请戳:听云博客 时至今日,接触kubernetes也有一段时间了,而我们的大部分业务也已经稳定地运行在不同规模的kubernetes集群上,不得不说,无论是从应用部署.迭代,还是从资源调 ...
- 关于《selenium2自动测试实战--基于Python语言》
关于本书的类型: 首先在我看来技术书分为两类,一类是“思想”,一类是“操作手册”. 对于思想类的书,一般作者有很多年经验积累,这类书需要细读与品位.高手读了会深有体会,豁然开朗.新手读了不止所云,甚至 ...
- psutil一个基于python的跨平台系统信息跟踪模块
受益于这个模块的帮助,在这里我推荐一手. https://pythonhosted.org/psutil/#processes psutil是一个基于python的跨平台系统信息监视模块.在pytho ...
- 一次完整的自动化登录测试-基于python+selenium进行cnblog的自动化登录测试
Web登录测试是很常见的测试!手动测试大家再熟悉不过了,那如何进行自动化登录测试呢!本文作者就用python+selenium结合unittest单元测试框架来进行一次简单但比较完整的cnblog自动 ...
- 搭建基于python +opencv+Beautifulsoup+Neurolab机器学习平台
搭建基于python +opencv+Beautifulsoup+Neurolab机器学习平台 By 子敬叔叔 最近在学习麦好的<机器学习实践指南案例应用解析第二版>,在安装学习环境的时候 ...
- 《Selenium2自动化测试实战--基于Python语言》 --即将面市
发展历程: <selenium_webdriver(python)第一版> 将本博客中的这个系列整理为pdf文档,免费. <selenium_webdriver(python)第 ...
- 从Theano到Lasagne:基于Python的深度学习的框架和库
从Theano到Lasagne:基于Python的深度学习的框架和库 摘要:最近,深度神经网络以“Deep Dreams”形式在网站中如雨后春笋般出现,或是像谷歌研究原创论文中描述的那样:Incept ...
随机推荐
- BZOJ1085 luogu2324骑士精神题解
没有什么特别好的办法,只好用搜索去做 因为一次移动最多归位一个骑士 所以可以想到用IDA*,为了简化状态 我们用k,x,y,sum来表示移动了k步,空格在x,y,还用sum个没有归位的情况 然后枚举转 ...
- 阿里云OSS同城冗余存储正式商业化,提供云上同城容灾能力
近日,阿里云正式发布OSS同城冗余存储产品.这是国内目前提供同城多AZ冗余部署能力覆盖最广的云上对象存储产品,可以实现云存储的同城双活,满足企业级客户对于“发生机房级灾难事件时数据不丢失,业务不中断” ...
- Java面向对象----String对象的声明和创建
String a="abcd" 相等 String b="abcd" String a=new String("abcd") 不等于 ...
- SQL语法之DDL和DML
SQL语法之DDL和DML DDL数据库定义语言 create 创建 alter 修改 drop 删除 drop和delete的区别 truncate DML 数据操作语言 insert ...
- [BZOJ3064][Tyvj1518] CPU监控
题目:[BZOJ3064][Tyvj1518] CPU监控 思路: 线段树专题讲的.以下为讲课时的课件: 给出序列,要求查询一些区间的最大值.历史最大值,支持区间加.区间修改.序列长度和操作数< ...
- iOS 设计
APP引导页设计经验分享 http://www.cocoachina.com/design/20150615/12126.html 获取app安装的进度,6种不同的加载指示 http://www.co ...
- 你真的知道你看到的UTF-8字符是什么吗?
翻译自http://www.pixelstech.net/article/1397877200-You-know-what-UTF-8-is-when-you-see-it- Source : son ...
- oracle函数 LOWER(c1)
[功能]:将字符串全部转为小写 [参数]:c1,字符表达式 [返回]:字符型 [示例] SQL> select lower('AaBbCcDd')AaBbCcDd from dual; AABB ...
- @codeforces - 117C@ Cycle
目录 @description@ @solution@ @accepted code@ @details@ @description@ 给定一个竞赛图(有向完全图),请找出里面的某个三元环,或者判断不 ...
- saltStack_Pillar
Pillar是Salt非常重要的一个组件,它用于给特定的minion定义任何你需要的数据,这些数据可以被Salt的其他组件使用.这里可以看出Pillar的一个特点,Pillar数据是与特定minion ...