mysql优化---in型子查询,exists子查询,from 型子查询
in型子查询引出的陷阱:(扫更少的行,不要临时表,不要文件排序就快) 题: 在ecshop商城表中,查询6号栏目的商品, (注,6号是一个大栏目)
最直观的: mysql> select goods_id,cat_id,goods_name from goods where cat_id in (select cat_id from category where parent_id=6); 误区: 给我们的感觉是, 先查到内层的6号栏目的子栏目,如7,8,9,11
然后外层, cat_id in (7,8,9,11) 事实: 如下图, goods表全扫描, 并逐行与category表对照,看parent_id=6是否成立
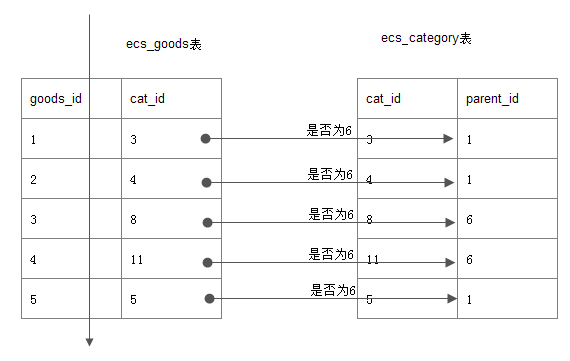
原因: mysql的查询优化器,针对In型做优化,被改成了exists的执行效果.
当goods表越大时, 查询速度越慢. 改进: 用连接查询来代替子查询
explain select goods_id,g.cat_id,g.goods_name from goods as g
inner join (select cat_id from category where parent_id=6) as t
using(cat_id) \G 内层 select cat_id from ecs_category where parent_id=6 ; 用到Parent_id索引, 返回4行
+--------+
| cat_id |
+--------+
| 7 |
| 8 |
| 9 |
| 11 |
+--------+ 形成结果,设为t *************************** 3. row ***************************
id: 2
select_type: DERIVED
table: ecs_category
type: ref
possible_keys: parent_id
key: parent_id
key_len: 2
ref:
rows: 4
Extra:
3 rows in set (0.00 sec) 第2次查询,
t和 goods 通过 cat_id 相连,
因为cat_id在 goods表中有索引, 所以相当于用7,8,911,快速匹配上 goods的行.
*************************** 2. row ***************************
id: 1
select_type: PRIMARY
table: g
type: ref
possible_keys: cat_id
key: cat_id
key_len: 2
ref: t.cat_id
rows: 6
Extra: 第1次查询 :
是把上面2次的中间结果,直接取回.
*************************** 1. row ***************************
id: 1
select_type: PRIMARY
table: <derived2>
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 4
Extra:
exists子查询:
题: 查询有商品的栏目.
按上面的理解,我们用join来操作,如下:
mysql> select c.cat_id,cat_name from ecs_category as c inner join goods as g
on c.cat_id=g.cat_id group by cat_name; (见36) 优化1: 在group时, 用带有索引的列来group, 速度会稍快一些,另外,
用int型 比 char型 分组,也要快一些.(见37) 优化2: 在group时, 我们假设只取了A表的内容,group by 的列,尽量用A表的列,
会比B表的列要快.(见38) 优化3: 从语义上去优化
select cat_id,cat_name from ecs_category where exists(select *from goods where goods.cat_id=ecs_category.cat_id) (见40) | 36 | 0.00039075 | select c.cat_id,cat_name from ecs_category as c inner
join goods as g on c.cat_id=g.cat_id group by cat_name
|
| 37 | 0.00038675 | select c.cat_id,cat_name from ecs_category as c inner
join goods as g on c.cat_id=g.cat_id group by cat_id
|
| 38 | 0.00035650 | select c.cat_id,cat_name from ecs_category as c inner
join goods as g on c.cat_id=g.cat_id group by c.cat_id
|
| 40 | 0.00033500 | select cat_id,cat_name from ecs_category where exists
(select * from goods where goods.cat_id=ecs_category.cat_id)
| from 型子查询:
注意::内层from语句查到的临时表, 是没有索引的.因为是一个临时形成的结果。
所以: from的返回内容要尽量少.
mysql优化---in型子查询,exists子查询,from 型子查询的更多相关文章
- 8.2.1.2 How MySQL Optimizes WHERE Clauses MySQL 优化WHERE 子句
8.2.1.2 How MySQL Optimizes WHERE Clauses MySQL 优化WHERE 子句 本节讨论优化用于处理WHERE子句, 例子是使用SELECT 语句,但是相同的优化 ...
- MySQL 子查询 EXISTS 和 NOT EXISTS(转)
MySQL EXISTS 和 NOT EXISTS 子查询 MySQL EXISTS 和 NOT EXISTS 子查询语法如下: SELECT ... FROM table WHERE EXISTS ...
- MySql优化子查询
用子查询语句来影响子查询中产生结果rows的数量和顺序. For example: SELECT * FROM t1 WHERE t1.column1 IN (SELECT column1 FROM ...
- MYSQL优化派生表(子查询)在From语句中的
Mysql 在5.6.3中,优化器更有效率地处理派生表(在from语句中的子查询): 优化器推迟物化子查询在from语句中的子查询,知道子查询的内容在查询正真执行需要时,才开始物化.这一举措提高了性能 ...
- MySQL开发——【联合查询、多表连接、子查询】
联合查询 所谓的联合查询就是将满足条件的结果进行拼接在同一张表中. 基本语法: select */字段 from 数据表1 union [all | distinct] select */字段 fro ...
- MySQL之多表查询一 介绍 二 多表连接查询 三 符合条件连接查询 四 子查询 五 综合练习
MySQL之多表查询 阅读目录 一 介绍 二 多表连接查询 三 符合条件连接查询 四 子查询 五 综合练习 一 介绍 本节主题 多表连接查询 复合条件连接查询 子查询 首先说一下,我们写项目一般都会建 ...
- SQL 子查询 EXISTS 和 NOT EXISTS
MySQL EXISTS 和 NOT EXISTS 子查询语法如下: SELECT … FROM table WHERE EXISTS (subquery) 该语法可以理解为:将主查询的数据,放到子查 ...
- (5)MySQL的查询:模糊查询(通配符查询like)、限制符查询(limit)、排序查询(order by)、分组查询(group by)、(子查询)
注意事项 指令语法的优先级: where > group by >order by > limit 例:select count(id) as cnt,age from tablen ...
- Mysql优化系列之——优化器对子查询的处理
根据子查询的类型和位置不同,mysql优化器会对查询语句中的子查询采取不同的处理策略,其中包括改写为连接(join),改写为半连接(semi-join)及进行物化处理等. 标量子查询(Scalar S ...
随机推荐
- [luoguP3159] [CQOI2012]交换棋子(最小费用最大流)
传送门 好难的网络流啊,建图真的超难. 如果不告诉我是网络流的话,我估计就会写dfs了. 使用费用流解决本题,设点 $p[i][j]$ 的参与交换的次数上限为 $v[i][j]$ ,以下为建图方式: ...
- Bzoj2007 [Noi2010]海拔(平面图最短路)
2007: [Noi2010]海拔 Time Limit: 20 Sec Memory Limit: 552 MBSubmit: 2742 Solved: 1318[Submit][Status] ...
- 开店 BZOJ 4012
开店 [问题描述] 风见幽香有一个好朋友叫八云紫,她们经常一起看星星看月亮从诗词歌赋谈到人生哲学.最近她们灵机一动,打算在幻想乡开一家小店来做生意赚点钱.这样的想法当然非常好啦,但是她们也发现她们面临 ...
- eq=等于gt=大于lt=小于的英文全称
EQ: Equal GT: Greater Than LT: Less than 知道全称就不会忘记
- LeetCode OJ--Search in Rotated Sorted Array
http://oj.leetcode.com/problems/search-in-rotated-sorted-array/ 转换了一次的有序数组,进行类似二分查找. 从begin到mid和从mid ...
- SELinux 服务检查与关闭
查看SELinux状态: 1./usr/sbin/sestatus -v ##如果SELinux status参数为enabled即为开启状态 SELinux status: ...
- BZOJ——1614: [Usaco2007 Jan]Telephone Lines架设电话线
Time Limit: 5 Sec Memory Limit: 64 MBSubmit: 1930 Solved: 823[Submit][Status][Discuss] Description ...
- Windows Phone 8.1 开发实例 网络编程 天气预报
首先感谢林政老师的博客,给了我很大的指导. 准备工作 我的开发环境: - Visual Studio 2013(With Update 4) - Windows Phone 8.1 - Windows ...
- JStorm学习
一.简介 JStorm是一个分布式实时计算引擎.JStorm是一个类似于Hadoop MapReduce的系统,用户按照指定的接口实现一个任务,然后将这个任务交给JStorm系统,JStorm将这个任 ...
- 管理weblogic服务的启动和停止
2012-11-10 12:58 26036人阅读 评论(4) 收藏 举报 分类: WebLogic(10) 版权声明:本文为博主原创文章,未经博主允许不得转载. 目录(?)[+] 介绍 Weblog ...