《StackGAN: Text to Photo-realistic Image Synthesis with Stacked GAN》论文笔记
出处:arxiv 2016 尚未出版
Motivation
根据文字描述来合成相片级真实感的图片是一项极具挑战性的任务。现有的生成手段,往往只能合成大体的目标,而丢失了生动的细节信息。StackGAN分两步来完成生成目标:Stage-I从文字中生成低分辨率的大体框架和基本色彩,Stage-II以文字和Stage-I中生成的基本框架图为输入,生成高分辨率的具体细节。运用StackGAN可以生成当前state_of_art的256*256分辨率的文字转换图像。训练数据集采用了CUB and Oxford-102。
Introduction
现有工作中,[20][22]可以利用GAN根据文字描述生成低分辨率64*64的图片。为了克服这一困难,作者描述了StackGAN怎样将任务分解为两步来达到目标。
Model
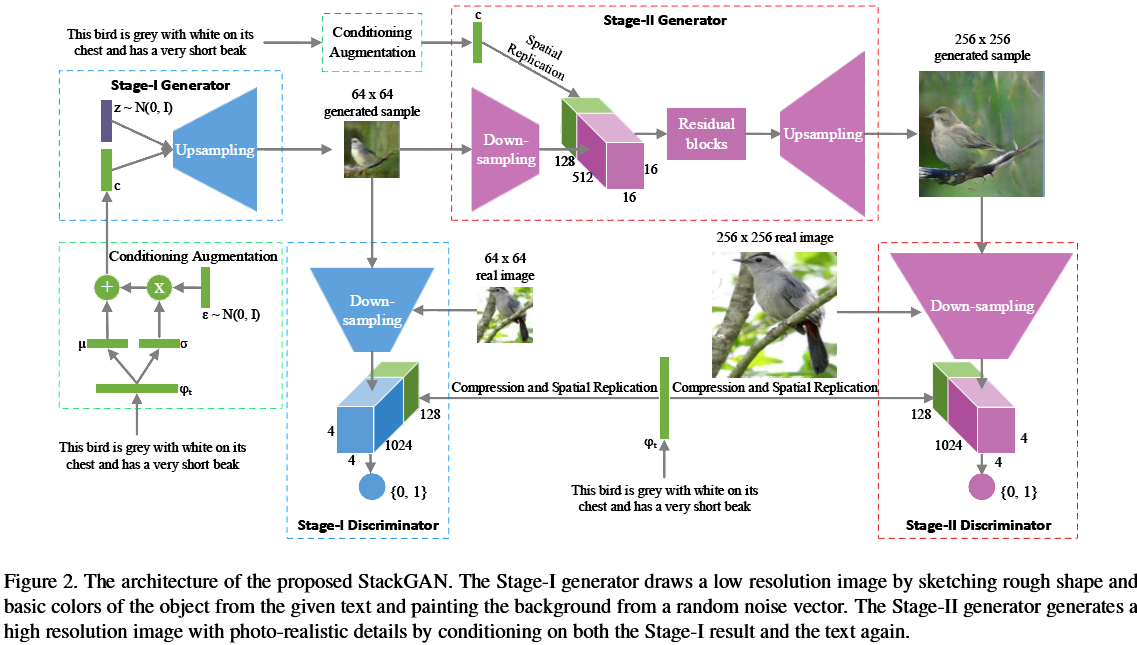
Stage-I GAN
对G来说,输入的文字描述被一个训练好的非线性转换器(nonlinearly transformed)Encoder $\phi$转化为隐变量(text-embeding),通常来说,该隐变量的维度相当高,通常大于100维,在G学习时对连续性有影响。因此作者提出一种扩张机制(augmentation),来为G产生更多的条件变量。作者构建一个特殊的高斯分布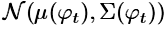 ,从中进行随机采样,The proposed formulation encourages robustness to small perturbations along the conditioning manifold, and
,从中进行随机采样,The proposed formulation encourages robustness to small perturbations along the conditioning manifold, and
thus yields more training pairs given a small number of image-text pairs。并且在训练过程中,作者使用KL距离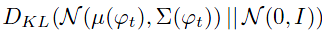
作为正则项来增强流型的平滑性同时避免overfitting。
损失函数:
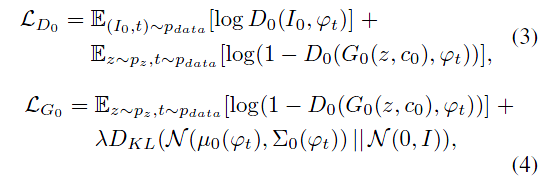
stage-II GAN:
把前一阶段生成的低分辨率图像和文字描述作为输入,模型致力于弥补上阶段丢失的细节信息
损失函数:
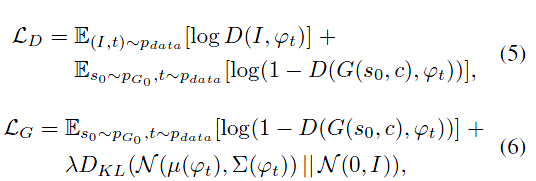
其中$S_0$是上阶段生成的低分辨率图,随机变量Z没有出现在这个一生成阶段中。两个阶段都共享了训练好的词向量encoder,但是后面接的连接层不同,产生的平均数和方差数不同,因此能比1阶段生成更详细的信息(这段转得很生硬,我也不懂为什么这样就能产生更丰富的信息)。
其他:
数据集:CUB and Oxford-102采用了【21】提供的标签,每张图片提供10个标注
评估指标:使用了【26】推荐的Inception score 来评价生成质量
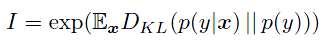
其中,x是生成的样本,y是label predicted by the Inception model【28】
不足之处:个人认为没有对多目标生成进行研究,这方面如果有所突破将会是篇好的paper。
pytoch 源码地址:https://github.com/hanzhanggit/StackGAN
后续论文:
StackGAN++: Realistic Image Synthesis with Stacked Generative Adversarial Networks
AttnGAN: Fine-Grained Text to Image Generation with Attentional Generative Adversarial Networks
[20] S. Reed, Z. Akata, S. Mohan, S. Tenka, B. Schiele, and
H. Lee. Learning what and where to draw. In NIPS, 2016. 1,
2, 3, 5, 6, 7
[21]S. Reed, Z. Akata, B. Schiele, and H. Lee. Learning deep
representations of fine-grained visual descriptions. In CVPR,
2016.
[22] S. Reed, Z. Akata, X. Yan, L. Logeswaran, B. Schiele, and
H. Lee. Generative adversarial text-to-image synthesis. In
ICML, 2016. 1, 2, 3, 5, 6, 7
[26] T. Salimans, I. J. Goodfellow, W. Zaremba, V. Cheung,
A. Radford, and X. Chen. Improved techniques for training
gans. In NIPS, 2016. 2, 5
[28] C. Szegedy, V. Vanhoucke, S. Ioffe, J. Shlens, and Z. Wojna.
Rethinking the inception architecture for computer vision. In
CVPR, 2016. 5
《StackGAN: Text to Photo-realistic Image Synthesis with Stacked GAN》论文笔记的更多相关文章
- 《Vision Permutator: A Permutable MLP-Like ArchItecture For Visual Recognition》论文笔记
论文题目:<Vision Permutator: A Permutable MLP-Like ArchItecture For Visual Recognition> 论文作者:Qibin ...
- [place recognition]NetVLAD: CNN architecture for weakly supervised place recognition 论文翻译及解析(转)
https://blog.csdn.net/qq_32417287/article/details/80102466 abstract introduction method overview Dee ...
- 论文笔记系列-Auto-DeepLab:Hierarchical Neural Architecture Search for Semantic Image Segmentation
Pytorch实现代码:https://github.com/MenghaoGuo/AutoDeeplab 创新点 cell-level and network-level search 以往的NAS ...
- 论文笔记——Rethinking the Inception Architecture for Computer Vision
1. 论文思想 factorized convolutions and aggressive regularization. 本文给出了一些网络设计的技巧. 2. 结果 用5G的计算量和25M的参数. ...
- 论文笔记:Fast Neural Architecture Search of Compact Semantic Segmentation Models via Auxiliary Cells
Fast Neural Architecture Search of Compact Semantic Segmentation Models via Auxiliary Cells 2019-04- ...
- 论文笔记:ProxylessNAS: Direct Neural Architecture Search on Target Task and Hardware
ProxylessNAS: Direct Neural Architecture Search on Target Task and Hardware 2019-03-19 16:13:18 Pape ...
- 论文笔记:DARTS: Differentiable Architecture Search
DARTS: Differentiable Architecture Search 2019-03-19 10:04:26accepted by ICLR 2019 Paper:https://arx ...
- 论文笔记:Progressive Neural Architecture Search
Progressive Neural Architecture Search 2019-03-18 20:28:13 Paper:http://openaccess.thecvf.com/conten ...
- 论文笔记:Auto-DeepLab: Hierarchical Neural Architecture Search for Semantic Image Segmentation
Auto-DeepLab: Hierarchical Neural Architecture Search for Semantic Image Segmentation2019-03-18 14:4 ...
- 论文笔记系列-DARTS: Differentiable Architecture Search
Summary 我的理解就是原本节点和节点之间操作是离散的,因为就是从若干个操作中选择某一个,而作者试图使用softmax和relaxation(松弛化)将操作连续化,所以模型结构搜索的任务就转变成了 ...
随机推荐
- bzoj 1701 [Usaco2007 Jan]Cow School牛学校
[Usaco2007 Jan]Cow School牛学校 Time Limit: 5 Sec Memory Limit: 64 MBSubmit: 175 Solved: 83[Submit][S ...
- unbuntu下安装多个JAVA JDK版本及如何切换
当前环境已经安装过jdk1.6.0_45安装JDK 1.7.x时,若安装错误,可执行以下步骤:sudo add-apt-repository ppa:openjdk-r/ppa sudo apt-ge ...
- hdu 2438 Turn the corner [ 三分 ]
传送门 Turn the corner Time Limit: 3000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Othe ...
- php之memcache学习
php之memcache学习 简介: memcache是一个分布式高速缓存系统. 分布式是说可以部署在多台服务器上,实现集群效果: 高速是因为数据都是维护在内存中的: 特点和使用场景: 1.非持久化存 ...
- Python()- 面向对象三大特性----继承
继承: 继承是一种创建新类的方式,在python中,新建的类可以继承一个或多个父类(基类或超类),新建的类是所继承的类的(派生类或子类) 人类和狗 有相同的属性, 提取了一个__init__方法,在这 ...
- OpenWrt 安装python-sqlite3失败
https://dev.openwrt.org/ticket/12239 #12239 reopened defect Sqlite3 missing in python 汇报人: dgspai@- ...
- 初始VueJS视频
本视频简单的介绍的使用. 初始VueJS视频
- 蚂蜂窝VS穷游最世界-自由行类App分析
很多其它内容请关注博客: http://www.china10s.com/blog/? p=150 一.产品概述 体验环境: 机型:iPhone 6 型号:64G版 系统:iOS9.2 蚂蜂窝APP版 ...
- ASP.NET Web Pages - 教程
ASP.NET Web Pages - 教程 ASP.NET 是一个使用 HTML.CSS.JavaScript 和服务器脚本创建网页和网站的开发框架. ASP.NET 支持三种不同的开发模式:Web ...
- js获取get传递的值
<script language="javascript" src="js/jquery-1.9.0.min.js"></script> ...