第1节 flume:9、flume的多个agent串联(级联)
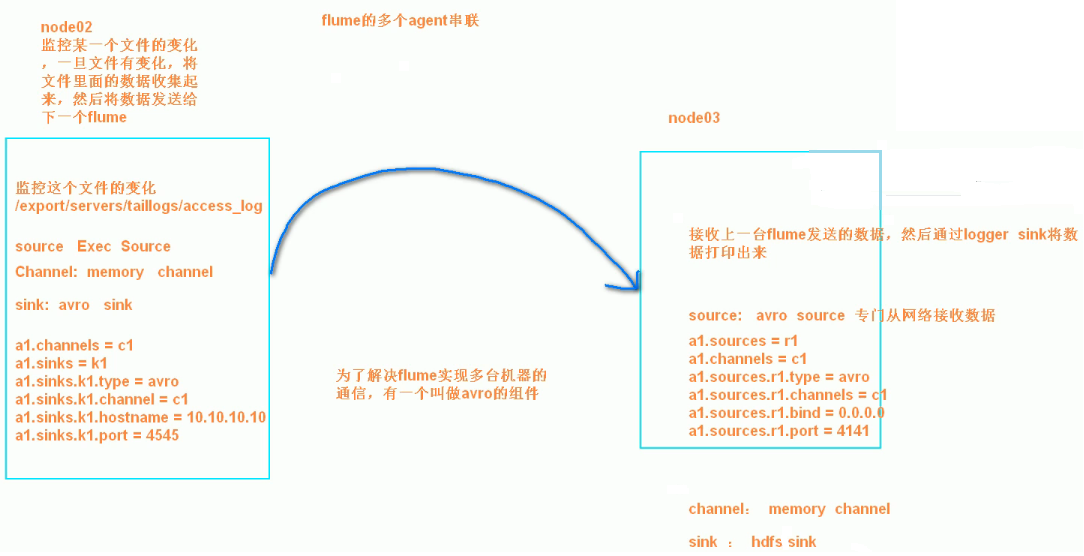
3、两个agent级联

需求分析:
第一个agent负责收集文件当中的数据,通过网络发送到第二个agent当中去,第二个agent负责接收第一个agent发送的数据,并将数据保存到hdfs上面去
第一步:node02安装flume
将node03机器上面解压后的flume文件夹拷贝到node02机器上面去
cd /export/servers
scp -r apache-flume-1.6.0-cdh5.14.0-bin/ node02:$PWD

第二步:node02配置flume配置文件
在node02机器配置我们的flume
cd /export/servers/apache-flume-1.6.0-cdh5.14.0-bin/conf
vim tail-avro-avro-logger.conf
##################
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /export/servers/taillogs/access_log
a1.sources.r1.channels = c1
# Describe the sink
##sink端的avro是一个数据发送者
a1.sinks = k1
a1.sinks.k1.type = avro
a1.sinks.k1.channel = c1
a1.sinks.k1.hostname = 192.168.52.120
a1.sinks.k1.port = 4141
a1.sinks.k1.batch-size = 10
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
第三步:node02开发脚本文件,往文件写入数据
直接将node03下面的脚本和数据拷贝到node02即可,node03机器上执行以下命令
cd /export/servers
scp -r shells/ taillogs/ node02:$PWD
第五步:node03开发flume配置文件
在node03机器上开发flume的配置文件
cd /export/servers/apache-flume-1.6.0-cdh5.14.0-bin/conf
vim avro-hdfs.conf
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
##source中的avro组件是一个接收者服务
a1.sources.r1.type = avro
a1.sources.r1.channels = c1
a1.sources.r1.bind = 192.168.52.120
a1.sources.r1.port = 4141
# Describe the sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://node01:8020/avro/hdfs/%y-%m-%d/%H%M/
a1.sinks.k1.hdfs.filePrefix = events-
a1.sinks.k1.hdfs.round = true
a1.sinks.k1.hdfs.roundValue = 10
a1.sinks.k1.hdfs.roundUnit = minute
a1.sinks.k1.hdfs.rollInterval = 3
a1.sinks.k1.hdfs.rollSize = 20
a1.sinks.k1.hdfs.rollCount = 5
a1.sinks.k1.hdfs.batchSize = 1
a1.sinks.k1.hdfs.useLocalTimeStamp = true
#生成的文件类型,默认是Sequencefile,可用DataStream,则为普通文本
a1.sinks.k1.hdfs.fileType = DataStream
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
第六步:顺序启动
node03机器启动flume进程
cd /export/servers/apache-flume-1.6.0-cdh5.14.0-bin
bin/flume-ng agent -c conf -f conf/avro-hdfs.conf -n a1 -Dflume.root.logger=INFO,console
node02机器启动flume进程
cd /export/servers/apache-flume-1.6.0-cdh5.14.0-bin/
bin/flume-ng agent -c conf -f conf/tail-avro-avro-logger.conf -n a1 -Dflume.root.logger=INFO,console
node02机器启shell脚本生成文件
cd /export/servers/shells
sh tail-file.sh
第1节 flume:9、flume的多个agent串联(级联)的更多相关文章
- 整体认识flume:Flume介绍、分布式安装、常见问题及解决方案
问题导读 1.什么是flume? 2.flume包含哪些组件? 3.Flume在读取utf-8格式的文件时会出现解析不了时间戳,该如何解决? Flume是一个分布式.可靠.和高可用的海量日志采集.聚合 ...
- 日志采集框架Flume以及Flume的安装部署(一个分布式、可靠、和高可用的海量日志采集、聚合和传输的系统)
Flume支持众多的source和sink类型,详细手册可参考官方文档,更多source和sink组件 http://flume.apache.org/FlumeUserGuide.html Flum ...
- Flume篇---Flume安装配置与相关使用
一.前述 Copy过来一段介绍Apache Flume 是一个从可以收集例如日志,事件等数据资源,并将这些数量庞大的数据从各项数据资源中集中起来存储的工具/服务,或者数集中机制.flume具有高可用, ...
- [Flume][Kafka]Flume 与 Kakfa结合例子(Kakfa 作为flume 的sink 输出到 Kafka topic)
Flume 与 Kakfa结合例子(Kakfa 作为flume 的sink 输出到 Kafka topic) 进行准备工作: $sudo mkdir -p /flume/web_spooldir$su ...
- [Flume]使用 Flume 来传递web log 到 hdfs 的例子
[Flume]使用 Flume 来传递web log 到 hdfs 的例子: 在 hdfs 上创建存储 log 的目录: $ hdfs dfs -mkdir -p /test001/weblogsfl ...
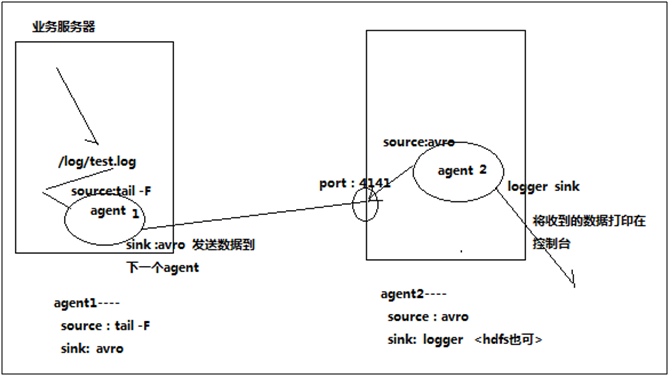
- Flume 多个agent串联
多个agent串联 采集需求:比如业务系统使用log4j生成的日志,日志内容不断增加,需要把追加到日志文件中的数据实时采集到hdfs,使用agent串联 根据需求,首先定义以下3大要素 第一台flum ...
- 【Flume】Flume基础之安装与使用
1.Flume简介 (1) Flume提供一个分布式的,可靠的,对大数据量的日志进行高效收集.聚集.移动的服务,Flume只能在Unix环境下运行. (2) Flume基于流式架构,容错性强, ...
- flume到flume消息传递
环境:两台虚拟机( 每台都有flume) 第一台slave作为消息的产生者 第二台master作为消息的接收者 IP(192.168.83.133) 原理:通过监听slave中文件的变化,获取变 ...
- Flume学习——Flume中事务的定义
首先要搞清楚的问题是:Flume中的事务用来干嘛? Flume中的事务用来保证消息的可靠传递. 当使用继承自BasicChannelSemantics的Channel时,Flume强制在操作Chann ...
随机推荐
- std::unique
类属性算法unique的作用是从输入序列中“删除”所有相邻的重复元素. 该算法删除相邻的重复元素,然后重新排列输入范围内的元素,并且返回一个迭代器(容器的长度没变,只是元素顺序改变了),表示无重复的值 ...
- Eclipse中,Open Type(Ctrl+Shift+T)失效后做法。
好几天ctrl shift T都不好用了,一直认为是工程的问题,没太在意,反正ctrl shift R也可也,今天看同事的好用,于是到网上查了一下解决的方法,刚才试了一下,应该是这个问题,明天就去公司 ...
- C++笔试题(四)
华为从事通信网络技术与产品的研究.开发.生产与销售,是中国电信市场的主要供应商之一,并已成功进入全球电信市场.每年华为都要在各大高校招聘大批的应界生,特别是华中科技大学.公司网址是:http://ww ...
- POJ2718【DFS】
题意: 给你0到9之间的数,然后让你搞成两个数,求一个最小差异值(被组合的数不允许出现前导0) 思路:最小差异那么肯定是有一个整数长n/2,另一个长n-n/2,搜一下就好了. code: #inclu ...
- WPF 加载 WINFORM控件 异常: 调度程序进程已挂起,但消息仍在处理中
在加载TradeAtServer的统计中的 单个合约盈亏情况 异常:,调度程序进程已挂起,但消息仍在处理中 发现可能是属性设置引发的问题 比如DateTimePikcer.Value+= set, g ...
- IT兄弟连 JavaWeb教程 经典面试题3
1.简述什么是重定向? 服务器向浏览器发送—个302状态码及一个Location消息头(该消息头的值是一个地址,称之为重定向地址),浏览器收到后会立即向重定向地址发出请求. 2.简述什么是转发?怎么实 ...
- 【Python】Python3.4+Matplotlib详细安装教程
网上找了很多教程,这个还不错. 传送门:https://blog.csdn.net/xqf1528399071/article/details/52233895
- SpringAOP和Spring事物管理
Spring AOP : Pointcut表达式: designators-指示器 wildcards-通配符 operators-操作符 wildcards: * -- 匹配任意数量的字符 + -- ...
- CentOS下查看网络状态
查看网络状态:lsof -Pnl +M -i4 显示ipv4服务及监听端情况netstat -anp 所有监听端口及对应的进程netstat -tlnp 功能同上 网络基本命令 (1)network ...
- Pursuit For Artifacts CodeForces - 652E
https://vjudge.net/problem/CodeForces-652E 边双啊,就是点双那个tarjan里面,如果low[v]==dfn[v](等同于low[v]>dfn[u]), ...