元祖、hash了解、字典、集合
元祖:
元组跟列表差不多,也是存一组数,只是它一旦创建,便不能再修改,所以又叫只读列表。
创建:
names = ('neo', 'mike', 'eric')
特性:
# 1.可存放多个值
# 2. 不可变。 元祖本身不可变,但,如果元祖中还包含其他可变元素,这些可变元素还可以改变。
# 3. 按照从左到右的顺序定义元组元素,下标从0开始顺序访问,有序
功能:
1. index
2. count
3. slice(切片)
改变可变元素示例:
n = ( 1,2,5,8,[ 'a', 'b'], 9)
n[4][2] = 'B'
# 则n就变成了 (1,2,5,8,[ 'a', 'B'], 9)
使用场景:
1. 显示的告知别人,此处数据不可修改
2. 数据连接配置信息等
Hash:
hash,被叫做“散列”或者“哈希”,就是把任意长度的输入,通过散列算法,变换成固定长度的输出,该输出就是散列值。 这种转换是一种压缩映射,也就是,散列值的空间通常远小于输入的空间,不同的输入可能会散列成相同的输出,所以不可能从散列值来唯一地确定输入值。简单来说,就是一种将任意长度的消息压缩到某一固定长度的消息摘要的函数。
特征:
hash值的计算过程是依据这个值的一些特征计算的,这就要求被hash的值必须固定,因此被hash的值必须是不可变的
不可变类型:数字、字符串、元祖
可变类型: 列表、字典
语法: hash('abc')
用途:
文件签名、
md5加密(密码明文变密文,md5的特性是无法反解)
密码验证
字典:
字典是一种key - value的数据类型,通过前面的key能够找出后面的value。
创建:
{key1:value1,key2:value2} 1、键与值用冒号“:”分开;
2、项与项用逗号“,”分开;
3. key的值不能重复
查询字典的某条信息:
info[key值]
修改字典某条信息:
dic = { 'neo': ['a','b','c'], 'alex': [ 'c', 'm','n']}
dic['neo'][1] = 'B'
# 则字典dic就变成了 {'neo': ['a', 'B', 'c'], 'alex': ['c', 'm', 'n']}
特性:
1. key-value结构
2. key必须可hash,必须为不可变数据类型、必须唯一
3. 可以存放任意多个值,值可以修改,可以不唯一
4. 无序
5. 查找速度快
key必须可hash和查找速度快:计算机需要先利用hash把key值转化成一个数字,然后再利用“折半查找”(二分查找,算法的一种)的方式去找key的hash值,查询次数大概是2的n次方。(字典不是利用二分法)
字典添加:
dic[ key ] = value #value可以是任意类型
info = {'student1': ' Tenglan Wu', 'student2': 'Cangjingkou', 'student3': 'Jiatengying'}
info[ ' student4' ] = 'abc' # 则字典info变成: {'student1': ' Tenglan Wu', 'student2': 'Cangjingkou', 'student3': 'Jiatengying', ' student4': 'abc'}
修改:
info[student2] = '苍井空'
# 字典info变成: {'student1': ' Tenglan Wu', 'student2': 'Cangjingkou', 'student3': 'Jiatengying', ' student2': '苍井空'} #添加的顺序是随机的,因为字典的无序性。
查找:
# 1. 标准用法:
'student2' in info # in是新的语法,用于判断字典info里面是否有'student2'这个key值,输出" True" 或者" False "。
# 如:
if 'student2' in info: # 如果student2是info的key值 # 2. 获取用法1:
info.get('student2') # 如果有该键值则获取键值对应的value, 如果没有则输出None;推荐使用这种 # 3. 获取用法2:
info['student2'] # 有该键值则获取该键值,没有则会报错。 所以通常使用 info.get()
删除:
# 方式1:
info.pop(键值) #删除该键值及其对应的值,并将其返回。# Remove the item at the given position in the list, and return it. If no index is specified, a.pop() removes and returns the last item in the list.
# 方式2:
info.popitem() # 随机删除字典里的某个元素
# 方式3:
del info[ 键值 ]
修改:
字典多层嵌套修改:
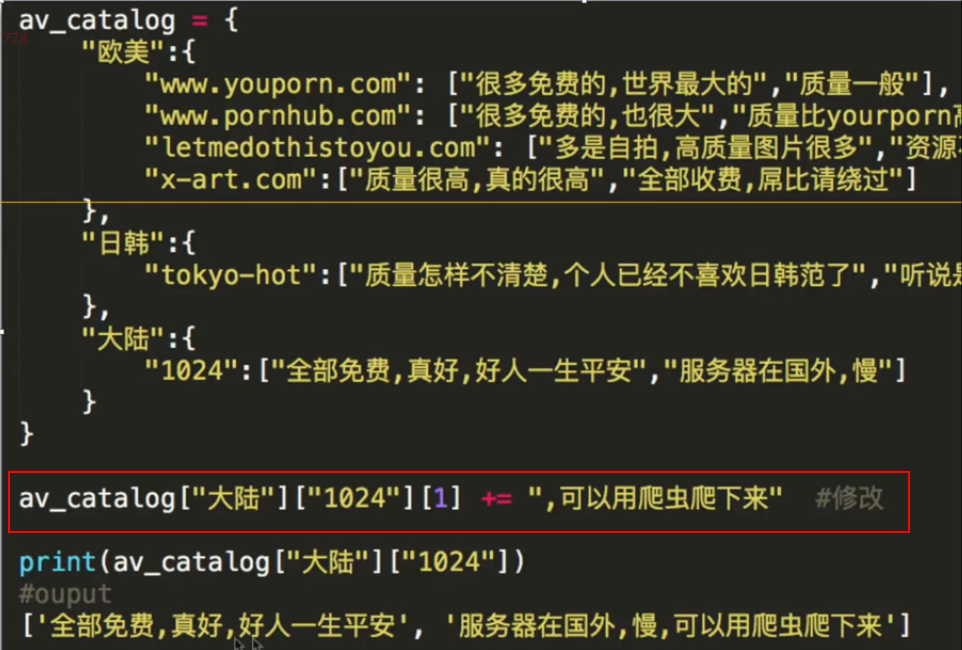
方法: 多层嵌套就是找到一级之后,再一层一层往下找,一个key一个key往下找。
其他方法:
info.clear() # 清空字典
info.copy() # 跟列表的copy一模一样
info.keys() # 获取所有的key值,放到一个列表里面
info.values() # 获取所有的value,放到一个列表里面
info.items() #是把info所有的key和value放到一个小元祖里面。
# 例: info.items() 为 dict_items([('student1', ' Tenglan Wu'), ('student2', 'Cangjingkou'), ('student3', 'Jiatengying')]) #把这些元祖再放到一个列表里面 dic1.update(dic2) #效果类似于列表里面list1.extend(list2)。 把dic2和dic1合并起来, 如果dic2和dic1有重复的key值, 就用dic2 key值所对应的value 覆盖 dic1 key值所对应的value,也就是所谓的update(更新)。 # 注:列表里的list1.extend( list2) 的效果 类似于 list1 += list2 info.setdefault( key1, value1) # 如果key这个键值在info字典里面本来就存在,那么info没有变化; 如果key这个键值在info里面不存在, 就把键值为key1、value值为value1的元素添加到字典info里面 info.fromkeys( ['key1', 'key2', 'key3'] , value1] # 批量往info字典里面添加“键值为key1,value值为value1”、“键值为key2,value值为value1”和“键值为key3,value值为value1”的元素, 如果不输入“ ,value ” , 则往info里面就只添加了键值分别为key1、 key2和 key3但value值为None的元素。 """
classmethod fromkeys(seq[, value])
Create a new dictionary with keys from seq and values set to value.
fromkeys()is a class method that returns a new dictionary. value defaults to None.
"""
dict.fromkeys 的用法:https://zhuanlan.zhihu.com/p/38440589
字典的循环:
for k in info:
print(k) # 注意: 打印的只是键值key。 只是键值在循环。 for k in info:
print( k, info[k] ) # 这种方式能把键值、value值都打印出来
集合类型:
示例:
iphone7 = [ 'alex', 'rain', 'jack', 'old_driver' ]
iphone8 = [ 'alex', 'shanshan', 'jack', 'old_boy' ]
如何找出同时买了iPhone7和8的人 ?
常规做法: 循环列表iphone7里面的人, 然后判断7里面的人是否在 iphone8里面 (交集)
iphone7 = [ 'alex', 'rain', 'jack', 'old_driver' ]
iphone8 = [ 'alex', 'shanshan', 'jack', 'old_boy' ] #定义一个空列表:同时买了7和8的人
both_list = [ ] #循环7里面的人,一个个判断这些人是否也在8里面,在的话就添加到both_list
for name in iphone7:
if name in iphone8: #if ...in.. 语法
both_list.append(name) print(both_list) #打印结果:
['alex', 'jack']
找出只买了iPhone7的人? (差集)
iphone7 = [ 'alex', 'rain', 'jack', 'old_driver' ]
iphone8 = [ 'alex', 'shanshan', 'jack', 'old_boy' ] only7 = [ ] for name in iphone7:
if name not in iphone8: #if...not in...语法
only7.append(name)
print(only7) #打印结果:
['rain', 'old_driver']
集合定义:
集合是一个无序的、不重复的数据组合,它的作用如下:
# 集合作用:
1. 去重,把一个列表变成集合,就自动去重了;
2. 关系测试,测试两组数据之间的交集、并集、差集等关系。
语法:
s = {1,2,3,4,'a','b'} #中间没有冒号(:)
# 空集合的类型是“字典”, 但按照集合的语法定义后,类型就是“集合”了 。
假如我定义了如下集合:
s = { 1, 2, 2, 2, 2, 3}
它会自动变成 s = { 1, 2, 3 }

列表(元祖也可以转)转成集合:
set( list)
# 如:
list1 = [ 1,2,3]
# set(list1) 就成了 { 1, 2, 3 }
添加:
s.add(元素) # 如果添加的元素原集合中已存在,就添加不进去。 # 只能添加一个元素
删除:
s.pop( ) # 随机删除集合元素
s.remove( 元素 ) #删除该元素, 如果该元素不存在则会报错
s.discard(元素) #删除该元素, 如果该元素不存在也不会报错
合并:
s1.update( s2) # 表面上看是s1和s2的合并, 其实是把s2 update到s1中, 所以最后的结果是: s2不变, 但s1变成了s2和原先s1的合并。效果类似于 s1 += s2
# 也可以利用 s.update() 往集合里面添加列表, 如:
s1 = { 1,2,3, 'a'}
s1.update( ['A','B','C' ] )
# s1就变成了 : {1, 2, 3, 'A', 'C', 'B', 'a'} #利用这种方式可以向集合里面批量 添加元素
清空:
s.clear( ) # 清空
判断集合关系:
交集:
# 交集1:
s1.intersection( s2 )
# 并集2:
s1 & s2
如上面的同时买了iPhone7和8的人:
iphone7 = [ 'alex', 'rain', 'jack', 'old_driver' ]
iphone8 = [ 'alex', 'shanshan', 'jack', 'neo' ] print(set(iphone7).intersection(set(iphone8)))
# 或者 print( iphone7 & iphone8 )
#输出结果: {'jack', 'alex'}
差集:
# 差集1:
s1.difference(s2) # s1对s2的差集 #s1和s2的位置不能互换
# 差集2:
s1 - s2 # s1对s2的差集
如上面只买了iphone7的人:
iphone7 = {'alex', 'rain', 'jack', 'old_driver' }
iphone8 = { 'alex', 'shanshan', 'jack', 'neo' }
print(set(iphone7).difference(set(iphone8)))
# 或者 print(iphone7 - iphone8)
#输出结果: {'old_driver', 'rain'}
并集:
# 并集1:
s1.union( s2 ) #会自动去重
# 并集2:
s1 | s2
示例:
iphone7 = {'alex', 'rain', 'jack', 'old_driver' }
iphone8 = { 'alex', 'shanshan', 'jack', 'neo' }
print(set(iphone8).union(set(iphone7)))
#输出结果:
{'old_driver', 'neo', 'shanshan', 'jack', 'rain', 'alex'}
对称差集:
s1.symmetric_difference( s2 ) # 相当于s1和s2的并集 减去 s1和s2的交集 #s1和s2的位置互换不会影响最后结果
如: 只购买了 iphone7和iphone8中 一个型号的人 :
iphone7 = {'alex', 'rain', 'jack', 'old_driver' }
iphone8 = { 'alex', 'shanshan', 'jack', 'neo' }
print(set(iphone7).symmetric_difference(set(iphone8)))
#输出结果为:{'neo', 'shanshan', 'rain', 'old_driver'}
子集关系:
# 子集1:
s1.issubset( s2 ) #判断s1是否为s2的子集,
# 子集2: s1<=s2;
超集(父集):
# 超集1:
s1.issuperset( s2 ) # 判断s1是否为s2的超集(父集)
# 超集2:
s1>= s2
判断关系:
s1.isdisjoint( s2) # 判断两个集合是否不相交
in,,not in: # 判断某元素是否在集合内
== ,!= : # 判断两个集合是否相等
补充:
s1.difference_update(s2) # 把s1和s2差集的结果赋值给s1。
s1.intersection_update( s2 ) #把s1和s2交集的结果赋值给s1。
元祖、hash了解、字典、集合的更多相关文章
- PYTHON-基本数据类型-元祖类型,字典类型,集合类型
内容: 1. 元组 2. 字典 3. 集合=========================== 元祖类型什么是元组: 元组就是一个不可变的列表============================ ...
- day007 列表类型、元祖类型、 字典类型、 集合类型的内置方法
目录 列表数据类型的内置方法 作用 定义方式 优先掌握的方法 需要掌握的方法 元祖类型的内置方法 作用 定义方式 优先掌握的方法(参考列表方法) 字典类型的内置方法 作用 定义方式 优先掌握的方法 需 ...
- 学习python的第十天(内置算法:列表数据类型,元祖数据类型,字典数据类型)
5.8自我总结 1.列表类型内置算法 1.必须掌握 1.按索引取值(正向取值+反向取值),即可存也可以取 #用于取其中一个值 name = ['yang','wen','yi'] ##正方向取wen, ...
- swift_简单值 | 元祖 | 流程控制 | 字符串 | 集合
//: Playground - noun: a place where people can play import Cocoa var str = "Hello, playground& ...
- python数据类型之 元祖、列表字典
Python中元祖,列表,字典 Python中有3种內建的数据结构:列表.元祖和字典: 1.列表 list是处理一组有序项目的数据结构,即你可以在一个列表中存储一个序列的项目. 列表中的项目应该包 ...
- python基础二(list,tuple元祖、dic字典,字符串)
一.列表list 1.list定义 列表即数组 ,list或array..列表中的每个元素都有自己的编号,从0开始,编号也可叫做下标,角标,索引.最后一个元素的下标也可用-1表示.: list定义时, ...
- PYTHON-基本数据类型-元祖类型,字典类型,集合类型-练习
# 1 有如下值集合 [11,22,33,44,55,66,77,88,99,90...],# 将所有大于 66 的值保存至字典的第一个key中,将小于 66 的值保存至第二个key的值中## 即: ...
- Python dict 将元祖转成字典
dict 关键字 dict3=dict(((),(),())) #dict 只有一个参数 输出:{'a': 97, 'b': 98, 'c': 99}
- Python 中列表、元祖、字典
1.元祖: 对象有序排列,通过索引读取读取, 对象不可变,可以是数字.字符串.列表.字典.其他元祖 2.列表: 对象有序排列,通过索引读取读取, 对象是可变的,可以是数字.字符串.元祖.其他列表.字典 ...
- 数据类型:list列表[]、元祖tuple()、dict字典{}
List 列表[] 可变的 lst = [1,2,3,4] #改 lst[(元素下标)] = '需要修改的' #通过下表修改 lst[下标:下标] = '需要修改的' #通过范围修改 #加 lst.a ...
随机推荐
- 教你如何在实战项目中使用WCF
我们都知道调用WCF直接在Service References中引用可以远程调用的WCF Url就行了. 但是我们想过没,在Development环境中可以这样做,但是QA.UAT.Productio ...
- 老式浏览器支持html5和css3
在IE页面的head标签里面加入 <!-[if IE]> <script src="http://html5shiv.googlecode.com/svn/trunk/ ...
- lua centos 安装报错
yum install libtermcap-devel ncurses-devel libevent-devel readline-devel
- ReactJS-3-组件生命周期
简介 普通的UI应用生命周期一般包括Birth, Growth, Death, React中Component的生命周期也是如此,这是一个持续的过程,贯穿整个应用的生命历程. 阶段 1.mountin ...
- Elasticsearch--集群&时光之门和恢复控制
节点发现 启动一个Elasticsearch节点时,该节点会开始寻找具有相同集群名字并且可见的主节点.如果找到主节点,该节点加入一个已经组成了的集群:如果没有找到,该节点成为主节点(如果配置允许).形 ...
- Linux下Eclipse连接小米手机真机调试
以前用Ubuntu 12.04可以真机调试,连上手机就可以了,上次看pear os 好看于是下了个玩玩(界面风格像mac 买不起,仿得起),这次想开发安卓发现真机调试不了了...于是乎各种找资料,各种 ...
- InChatter系统开源聊天模块前奏曲
最近在研究WCF,又因为工作中的项目需要,要为现有的系统增加一个聊天模块以及系统消息提醒等,因此就使用WCF做服务器端开发了一个简单的系统. 开发最初学习了东邪孤独大哥的<传说的WCF系列> ...
- asp IIS网站的配置(Win7下启用IIS7配置ASP运行环境)
其实win7下的IIS7配置过程是非常简单的.下面让seo博客来详细的介绍一下win7下配置IIS7环境运行ASP网站的方法,以供初接触者参考 第一次在windows7下配置IIS,虽然有丰富的x ...
- Node.js——Buffer
介绍 JavaScript没有读取和操作二进制数据流的机制,但是 node.js 引入了Buffer 类型,可以操作TCP流或者文件流 使用Buffer可以用来对临时数据(二进制数据)进行存储,当我们 ...
- vb,wps,excel 分裂
Sub 分列() '以空格为分隔符,连续空格只算1个.对所选中的单元格进行处理 Dim m As Range, tmpStr As String, s As String Dim x As Integ ...