登录日志的访问日志的 统计 MapReduce
登录日志的访问日志的 统计 MapReduce
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-common -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.9.1</version>
</dependency> <!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-client -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.9.1</version>
</dependency>
java -jar MyAid-1.0.0-jar-with-dependencies.jar inputMyHadoop outputMyHadoop
2018 七月 10 20:17:52,502 - INFO [main] (Job.java:1665) - Counters: 30
File System Counters
FILE: Number of bytes read=88467124
FILE: Number of bytes written=89801796
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
Map-Reduce Framework
Map input records=1
Map output records=11
Map output bytes=106
Map output materialized bytes=125
Input split bytes=94
Combine input records=11
Combine output records=10
Reduce input groups=10
Reduce shuffle bytes=125
Reduce input records=10
Reduce output records=10
Spilled Records=20
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=7
Total committed heap usage (bytes)=456130560
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=64
File Output Format Counters
Bytes Written=91
2018 七月 10 20:17:52,504 - DEBUG [main] (UserGroupInformation.java:1916) - PrivilegedAction as:root (auth:SIMPLE) from:org.apache.hadoop.mapreduce.Job.updateStatus(Job.java:328)
2018 七月 10 20:17:52,508 - DEBUG [Thread-3] (ShutdownHookManager.java:85) - ShutdownHookManger complete shutdown.
[root@hadoop3 myBg]# ll -as
总用量 43316
0 drwxr-xr-x 7 root root 226 7月 10 20:17 .
0 drwxr-xr-x. 9 root root 196 7月 10 19:54 ..
4 -rw-r--r-- 1 root root 64 7月 10 20:00 inputMyHadoop
12 -rw-r--r-- 1 root root 11090 7月 10 15:46 javaDM.iml
0 drwxr-xr-x 2 root root 99 7月 10 19:54 logs
43200 -rw-r--r-- 1 root root 44233209 7月 10 20:16 MyAid-1.0.0-jar-with-dependencies.jar
0 drwxr-xr-x 4 root root 57 7月 10 19:54 nls-service-sdk-1.0.0
88 -rw-r--r-- 1 root root 89657 11月 20 2017 nls-service-sdk-1.0.0.jar
0 drwxr-xr-x 2 root root 88 7月 10 20:17 outputMyHadoop
12 -rw-r--r-- 1 root root 8947 7月 10 15:31 pom.xml
0 drwxr-xr-x 3 root root 18 7月 10 19:54 src
0 drwxr-xr-x 5 root root 131 7月 10 19:54 target
[root@hadoop3 myBg]# ll -as outputMyHadoop/
总用量 12
0 drwxr-xr-x 2 root root 88 7月 10 20:17 .
0 drwxr-xr-x 7 root root 226 7月 10 20:17 ..
4 -rw-r--r-- 1 root root 79 7月 10 20:17 part-r-00000
4 -rw-r--r-- 1 root root 12 7月 10 20:17 .part-r-00000.crc
0 -rw-r--r-- 1 root root 0 7月 10 20:17 _SUCCESS
4 -rw-r--r-- 1 root root 8 7月 10 20:17 ._SUCCESS.crc
[root@hadoop3 myBg]# cat outputMyHadoop/part-r-00000
173 1
Overflow 1
Q&A 1
Stack 1
communities. 1
is 1
network 1
of 2
part 1
the 1
[root@hadoop3 myBg]# cat inputMyHadoop
Stack Overflow is part of the network of 173 Q&A communities.
[root@hadoop3 myBg]#
package com.mycom; import java.io.IOException;
import java.util.StringTokenizer; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class WordCount {
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text(); public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
} public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable(); public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
} public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}

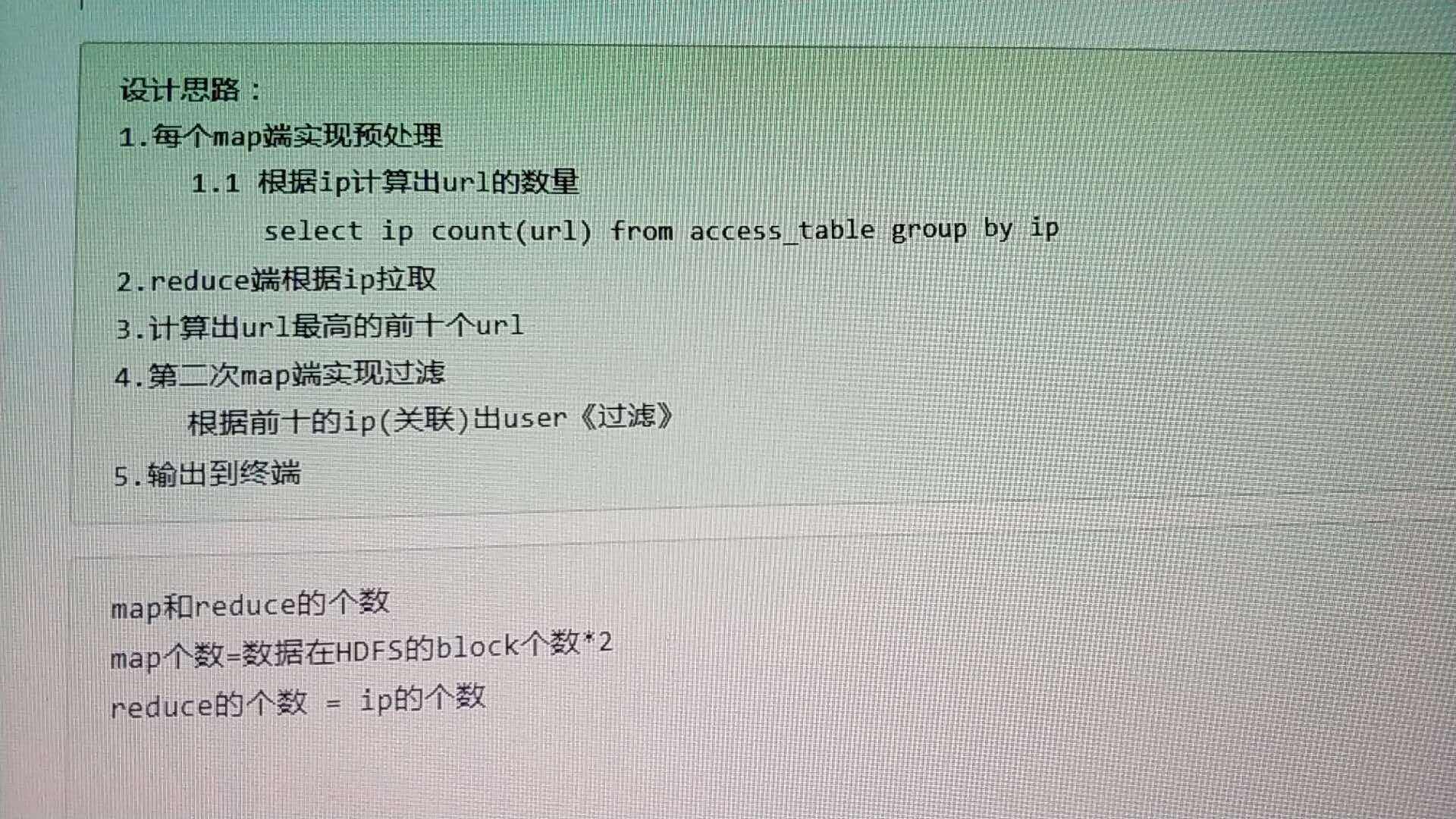
【情景】
统计时间:1号0:00-24:00
用户U1在0-1仅对URL1访问100次,ip1
用户U1在1-2仅对URL2访问100次,ip2
用户U1在2-3仅对URL3访问100次,ip3
用户U1在3-4仅对URL4访问100次,ip4
、、、、、、
用户U1在9-10仅对URL10访问100次,ip10
其他时间用户U1无访问行为;而其他用户在且仅在剩余时间访问,访问详情:
对任意URL11-URLn仅仅其中指定的10个URL-i1~URL-i10分别访问大于1次小于100次
【求独立用户数最多的前10个URL】
正确的答案是
URL-i1~URL-i10
【错误的答案】
URL1~URL10
1-map
(user,ip,time,1),(user,ip,time,2) (ip,time,url)
得到各个user的访问url的清单
2-reduce
得到各个user的访问url的清单去重后的结果
3-map
得到各个url下的访问user的清单
4-reduce
得到各个url下的访问user的清单去重后的结果
5-reduce
对各个url按照user个数排序,取前10
<user,(ip,time)>
<user,(ip,time,URL)>
<user,(URLlist)>
<n,URL>
package com.mycom; import org.apache.hadoop.io.IntWritable; import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
import java.net.URI;
import java.util.Set;
import java.util.ArrayList;
import java.util.StringTokenizer;
import java.util.HashSet;
import java.util.List; import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Counter;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
import org.apache.hadoop.util.StringUtils; public class WordCountImprove {
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
static enum CountersEnum {INPUT_WORDS} ;
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
private boolean caseSensitive;
private Set<String> patternsToSkip = new HashSet<String>(); private Configuration conf;
private BufferedReader fis; @Override
public void setup(Context context) throws IOException, InterruptedException {
conf = context.getConfiguration();
caseSensitive = conf.getBoolean("wordcount.case.sensitive", true);
if (conf.getBoolean("wordcount.skip.patterns", false)) {
URI[] patternsURIs = Job.getInstance(conf).getCacheFiles();
for (URI patternsURI : patternsURIs) {
Path patternsPath = new Path(patternsURI.getPath());
String patternsFileName = patternsPath.getName().toString();
parseSkipFile(patternsFileName);
}
}
} private void parseSkipFile(String fileName) {
try {
fis = new BufferedReader(new FileReader(fileName));
String pattern = null;
while ((pattern = fis.readLine()) != null) {
patternsToSkip.add(pattern);
}
} catch (IOException ioe) {
System.err.println("Caught exception while parsing the cached file" + StringUtils.stringifyException(ioe));
}
} @Override
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
String line = (caseSensitive) ? value.toString() : value.toString().toLowerCase();
for (String pattern : patternsToSkip) {
line = line.replaceAll(pattern, "");
}
StringTokenizer itr = new StringTokenizer(line);
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
Counter counter = context.getCounter(CountersEnum.class.getName(), CountersEnum.INPUT_WORDS.toString());
counter.increment(1);
}
} } public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable(); public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
} public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
GenericOptionsParser optionsParser = new GenericOptionsParser(conf, args);
String[] remainingArgs = optionsParser.getRemainingArgs(); if ((remainingArgs.length != 2) && (remainingArgs.length != 4)) {
System.err.println("Usage: wordcount <in> <out> [-skip skipPatternFile]");
System.exit(2);
} Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCountImprove.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class); List<String> otherArgs = new ArrayList<String>();
for (int i = 0; i < remainingArgs.length; i++) {
if ("-skip".equals(remainingArgs[i])) {
job.addCacheFile(new Path(remainingArgs[++i]).toUri());
} else {
otherArgs.add(remainingArgs[i]);
}
}
FileInputFormat.addInputPath(job, new Path(otherArgs.get(0)));
FileOutputFormat.setOutputPath(job, new Path(otherArgs.get(1))); System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
2018 七月 11 16:03:51,320 - INFO [main] (Job.java:1665) - Counters: 31
File System Counters
FILE: Number of bytes read=388340260
FILE: Number of bytes written=392345686
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
Map-Reduce Framework
Map input records=35
Map output records=185
Map output bytes=2672
Map output materialized bytes=2594
Input split bytes=184
Combine input records=185
Combine output records=144
Reduce input groups=144
Reduce shuffle bytes=2594
Reduce input records=144
Reduce output records=144
Spilled Records=288
Shuffled Maps =2
Failed Shuffles=0
Merged Map outputs=2
GC time elapsed (ms)=0
Total committed heap usage (bytes)=894959616
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
com.mycom.WordCountImprove$TokenizerMapper$CountersEnum
INPUT_WORDS=185
File Input Format Counters
Bytes Read=1949
File Output Format Counters
Bytes Written=2028
2018 七月 11 16:03:51,321 - DEBUG [main] (UserGroupInformation.java:1916) - PrivilegedAction as:root (auth:SIMPLE) from:org.apache.hadoop.mapreduce.Job.updateStatus(Job.java:328)
2018 七月 11 16:03:51,323 - DEBUG [Thread-3] (ShutdownHookManager.java:85) - ShutdownHookManger complete shutdown.
[root@hadoop3 myBg]# ll -as outputDir/
总用量 12
0 drwxr-xr-x 2 root root 88 7月 11 16:03 .
0 drwxr-xr-x 9 root root 279 7月 11 16:03 ..
4 -rw-r--r-- 1 root root 2004 7月 11 16:03 part-r-00000
4 -rw-r--r-- 1 root root 24 7月 11 16:03 .part-r-00000.crc
0 -rw-r--r-- 1 root root 0 7月 11 16:03 _SUCCESS
4 -rw-r--r-- 1 root root 8 7月 11 16:03 ._SUCCESS.crc
[root@hadoop3 myBg]# cat outputDir/part-r-00000
! 1
(RDD). 1
(in 1
- 2
2.0, 2
3516条评价 1
API 1
After 1
Dataset 1
Dataset, 2
Dataset. 1
Distributed 1
HDFS, 1
Hadoop. 1
However, 1
Java, 1
Note 1
PC6下载 1
Python 1
Python. 1
RDD 2
RDD, 1
RDD. 1
RDDs 1
Resilient 1
SQL 1
Scala), 1
Scala, 1
See 1
Since 1
Spark 5
Spark. 1
Spark’s 1
The 1
This 1
To 1
We 1
a 4
about 1
along 1
an 1
and 2
any 1
applications 1
are 1
at 1
be 1
before 1
better 1
but 1
by 1
can 2
complete 1
download 2
first 2
follow 1
for 1
from 1
get 2
guide 1
guide, 1
guide. 1
hao123下载 1
has 1
highly 1
hood. 1
how 1
in 1
information 1
interactive 1
interface 2
introduce 1
introduction 1
is 2
like 1
main 1
more 2
of 3
optimizations 1
or 1
package 1
packaged 1
performance 1
programming 3
provides 1
quick 1
recommend 1
reference 1
release 1
replaced 1
richer 1
shell 1
show 1
still 1
strongly-typed 1
supported, 1
switch 1
than 1
that, 1
the 7
then 1
this 1
through 1
to 5
tutorial 1
under 1
use 1
using 2
version 1
was 1
we 2
website. 1
weibo.com/ 1
which 2
will 1
with 2
won’t 1
write 1
you 3
【 1
【公告】微博客服热线服务号码调整啦 1
【公告】忘记帐号信息怎么办? 1
中关村在线下载 1
企业微博注册 1
企业版立即开通企业微博任何企业微博注册认证问题,请私信@企业认证 1
你的行为有些异常,请输入验证码: 1
天极下载 1
微博- 1
微博-随时随地发现新鲜事官网 1
微博开放平台 1
微博开放平台为移动应用提供了便捷的合作模式,满足了多元化移动终端用户 1
微博搜索 2
微博桌面 2
微博桌面官方微博 1
搜索 1
新浪微博客服 1
新浪微博登录网页版 1
用户在你的网站上点击"用微博帐号登录"按钮,弹出Oauth授权页面 1
用户输入 1
百度为您找到相关结果约69,700,000个 1
百度快照 1
看不清 1
综合找人文章视频 1
随时随地发现新鲜事!微博带你欣赏世界上每一个精彩瞬间,了解每一个幕后故事。分享你想表达的,让全世界都能听到你的心声! 1
[root@hadoop3 myBg]# java -jar MyAid-1.0.0-jar-with-dependencies.jar inputDir outputDir
[root@hadoop3 myBg]# cat inputDir/i*
This tutorial provides a quick introduction to using Spark. We will first introduce the API through Spark’s interactive shell (in Python or Scala), then show how to write applications in Java, Scala, and Python. To follow along with this guide, first download a packaged release of Spark from the Spark website. Since we won’t be using HDFS, you can download a package for any version of Hadoop. Note that, before Spark 2.0, the main programming interface of Spark was the Resilient Distributed Dataset (RDD). After Spark 2.0, RDDs are replaced by Dataset, which is strongly-typed like an RDD, but with richer optimizations under the hood. The RDD interface is still supported, and you can get a more complete reference at the RDD programming guide. However, we highly recommend you to switch to use Dataset, which has better performance than RDD. See the SQL programming guide to get more information about Dataset. 百度为您找到相关结果约69,700,000个 微博-随时随地发现新鲜事官网 随时随地发现新鲜事!微博带你欣赏世界上每一个精彩瞬间,了解每一个幕后故事。分享你想表达的,让全世界都能听到你的心声! weibo.com/ - 百度快照 - 3516条评价 微博搜索
微博搜索 综合找人文章视频 搜索 你的行为有些异常,请输入验证码: 看不清 新浪微博登录网页版
用户在你的网站上点击"用微博帐号登录"按钮,弹出Oauth授权页面 用户输入 微博开放平台
微博开放平台为移动应用提供了便捷的合作模式,满足了多元化移动终端用户 微博桌面
微博桌面官方微博 hao123下载 中关村在线下载 天极下载 PC6下载 微博桌面 新浪微博客服
【公告】微博客服热线服务号码调整啦 ! 【公告】忘记帐号信息怎么办? 【 企业微博注册
微博- 企业版立即开通企业微博任何企业微博注册认证问题,请私信@企业认证 [root@hadoop3 myBg]# ll -as inputDir/
总用量 8
0 drwxr-xr-x 2 root root 26 7月 11 15:57 .
0 drwxr-xr-x 9 root root 279 7月 11 16:03 ..
4 -rw-r--r-- 1 root root 923 7月 11 15:57 i1
4 -rw-r--r-- 1 root root 1026 7月 11 15:57 i2
登录日志的访问日志的 统计 MapReduce的更多相关文章
- 可视化分析 web 访问日志
内容目录 Python 基础 使用模块介绍 可视化组件 echarts 介绍 Web 访问日志 代码解读 讲师:KK 多语言混搭开发工程师,多年 PHP.Python 项目开发经验,曾就职 360.绿 ...
- centos LAMP第二部分apache配置 下载discuz!配置第一个虚拟主机 安装Discuz! 用户认证 配置域名跳转 配置apache的访问日志 配置静态文件缓存 配置防盗链 访问控制 apache rewrite 配置开机启动apache tcpdump 第二十节课
centos LAMP第二部分apache配置 下载discuz!配置第一个虚拟主机 安装Discuz! 用户认证 配置域名跳转 配置apache的访问日志 配置静态文件缓存 配置防盗链 ...
- apache2.4配置访问日志分割并过滤图片CSS等无用内容
相关信息 1.apache日志有访问日志和错误日志,错误日志根据日志级别来输出错误信息,而访问日志根据定义的日志格式来记录访问动作 2.访问日志格式在httpd.conf文件里面定义,在虚拟主机里面引 ...
- 机器数据的价值 - Web 访问日志和数据库审计日志
计算机数据 大量的数据流,不断增长的来源,蕴含着巨大的价值 在 Splunk,我们大量谈及计算机数据.这些数据是指在数据中心.“物联网”和互联设备世界中运行的所有系统产生的数据.其中包括支撑组织的应用 ...
- Nginx访问日志、 Nginx日志切割、静态文件不记录日志和过期时间
1.Nginx访问日志 配制访问日志:默认定义格式: log_format combined_realip '$remote_addr $http_x_forwarded_for [$time_loc ...
- 03 . Nginx日志配置及日志切割
Nginx日志 日志对于统计排错来说是非常有利的,Nginx日志主要分为两种: access_log(访问日志)和error_log(错误日志),通过访问日志可以得到用户的IP地址.浏览器的信息,请求 ...
- Tomcat日志与Log4j日志
一:日志作用 更好的调试,分析问题. 普通的一个请求处理10秒钟,日志10秒钟,总共就得20秒钟,这肯定是不行的,因为日志严重影响了性能.所以,我们就有必要了解日志的实现方式,以及它是如何降低IO的时 ...
- Hadoop第8周练习—Pig部署及统计访问日志例子
:搭建Pig环境 :计算每个IP点击次数 内容 运行环境说明 1.1 硬软件环境 线程,主频2.2G,6G内存 l 虚拟软件:VMware® Workstation 9.0.0 build- ...
- Python开发程序:生产环境下实时统计网站访问日志信息
日志实时分析系统 生产环境下有需求:要每搁五分钟统计下这段时间内的网站访问量.UV.独立IP等信息,用直观的数据表格表现出来 环境描述: 网站为Nginx服务,系统每日凌晨会对日志进行分割,拷贝到其他 ...
随机推荐
- 虚拟机安装centos6.5
最近想搞一下代码覆盖率的jacoco,需要在linux环境下部署一套jenkins.故需要装一个centos的虚拟机. 一.安装虚拟机. 下载后安装一个虚拟机,我选择的是VMware虚拟机 二.安装c ...
- BZOJ 2179 FFT快速傅立叶 ——FFT
[题目分析] 快速傅里叶变换用于高精度乘法. 其实本质就是循环卷积的计算,也就是多项式的乘法. 两次蝴蝶变换. 二进制取反化递归为迭代. 单位根的巧妙取值,是的复杂度成为了nlogn 范德蒙矩阵计算逆 ...
- day1之校花网小试牛刀
一 利用生成器来完成爬去校花网视频 import requests import re import os import hashlib import time DOWLOAD_PATH=r'D:\D ...
- JavaScript 数组操作函数--转载+格式整理
JavaScript 数组操作函数(部分)--转载+格式整理 今天看了一篇文章,主要讲的对常用的Js操作函数:push,pop,join,shift,unshift,slice,splice,conc ...
- XPath用法详解
1.XPath是什么 XPath 是一门在 XML 文档中查找信息的语言.XPath 用于在 XML 文档中通过元素和属性进行导航(你可以理解为一种类似正则表达式的方法) 2.XPath的语法 表达式 ...
- noj 2069 赵信的往事 [yy题 无限gcd]
njczy2010 2069 Accepted 31MS 224K 1351Byte G++ 2014-11-13 13:32:56.0 坑爹的无限gcd,,,尼玛想好久,原来要x对y算一次,y再 ...
- (45)C#网络3 socket
一.TCP传输 using System.Net.Sockets; 1.最基本客户端连服务器 服务端运行后一直处于监听状态,客户端每启动一次服务端就接收一次连接并打印客户端的ip地址和端口号.(服务端 ...
- 2015多校联合训练赛 Training Contest 4 1008
构造题: 比赛的时候只想到:前面一样的数,后面 是类似1,2,3,4,5,6....t这 既是:t+1,t+1...,1,2,3,...t t+1的数目 可能 很多, 题解时YY出一个N 然后对N ...
- 社会信息化环境下的IT新战略
我们现在所处的信息化环境正在发生改变,技术已经成为影响组织的最重要的外部力量,传统的正金字塔的结构被移动互联网深深改变:员工能够更加自由的获取信息,变成更多的信息链接,这种链接不光连接人和组织,还连接 ...
- 【String】String.format(format,args...)的使用解析
String.format(format,args...)的使用解析 使用kotlin 中使用示例 ================================================== ...