转】[1.0.2] 详解基于maven管理-scala开发的spark项目开发环境的搭建与测试
场景
好的,假设项目数据调研与需求分析已接近尾声,马上进入Coding阶段了,辣么在Coding之前需要干马呢?是的,“统一开发工具、开发环境的搭建与本地测试、测试环境的搭建与测试” - 本文详细记录实际Spark项目开发环境的搭建。
分析
开发工具
操作系统:win 10
JDK 版本 :jdk1.8.0_91
Scala版本:2.10.6
MAVEN版本:apache-maven-3.3.9
集成开发工具:IntelliJ IDEA 2016.1.3
开发主要语言:scala
开发环境的搭建与测试
一. 搭建过程文档
1、新建一个Maven工程
这里以新建一个名称为fantasia的maven工程为例加以说明。

设置完了,选择下一步

设置完了,选择下一步
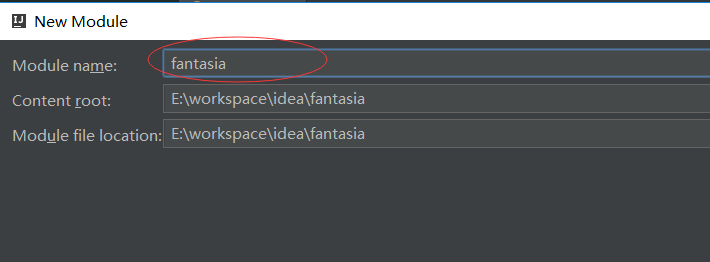
点击 finish 后idea会加载maven与junit等相关的插件,可能需要30分钟左右的时间(网速决定)。
2、自定义maven的repository目录
idea内置了maven插件,且默认repository目录为C:\Users\${username}\.m2\repository ,这里我们为项目指定一个新的repository,以方便管理依赖的jar包:

3、在pom.xml文件中配置相关依赖包
这里一次性导入项目可能用到的jar包,具体内容如下:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.pl.bdeu.bigdata</groupId>
<artifactId>fantasia</artifactId>
<version>1.0-SNAPSHOT</version>
<inceptionYear>2008</inceptionYear>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<scala.version>2.10.6</scala.version>
<spark.version>1.6.2</spark.version>
<hadoop.version>2.6.0</hadoop.version>
</properties>
<repositories>
<repository>
<id>scala-tools.org</id>
<name>Scala-Tools Maven2 Repository</name>
<url>http://scala-tools.org/repo-releases</url>
</repository>
</repositories>
<pluginRepositories>
<pluginRepository>
<id>scala-tools.org</id>
<name>Scala-Tools Maven2 Repository</name>
<url>http://scala-tools.org/repo-releases</url>
</pluginRepository>
</pluginRepositories>
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.specs</groupId>
<artifactId>specs</artifactId>
<version>1.2.5</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.10</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.10</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.10</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.10</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_2.10</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka_2.10</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.6</version>
</dependency>
<dependency>
<groupId>org.json</groupId>
<artifactId>json</artifactId>
<version>20090211</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-core</artifactId>
<version>2.4.3</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.4.3</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-annotations</artifactId>
<version>2.4.3</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.1.41</version>
</dependency>
<dependency>
<groupId>fastutil</groupId>
<artifactId>fastutil</artifactId>
<version>5.0.9</version>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
<testSourceDirectory>src/test/scala</testSourceDirectory>
<plugins>
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
<configuration>
<scalaVersion>${scala.version}</scalaVersion>
<args>
<arg>-target:jvm-1.5</arg>
</args>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-eclipse-plugin</artifactId>
<configuration>
<downloadSources>true</downloadSources>
<buildcommands>
<buildcommand>ch.epfl.lamp.sdt.core.scalabuilder</buildcommand>
</buildcommands>
<additionalProjectnatures>
<projectnature>ch.epfl.lamp.sdt.core.scalanature</projectnature>
</additionalProjectnatures>
<classpathContainers>
<classpathContainer>org.eclipse.jdt.launching.JRE_CONTAINER</classpathContainer>
<classpathContainer>ch.epfl.lamp.sdt.launching.SCALA_CONTAINER</classpathContainer>
</classpathContainers>
</configuration>
</plugin>
</plugins>
</build>
<reporting>
<plugins>
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<configuration>
<scalaVersion>${scala.version}</scalaVersion>
</configuration>
</plugin>
</plugins>
</reporting>
</project>
4、项目基础架构
新建两个子包:collector与 core
collector:存放 数据采集相关spark作业
core:存放核心业务类spark作业
resource目录下存放相关配置文件:数据库连接信息,kafka环境信息等,
其他的后续根据具体模块功能个再自行定义。

5、本地环境测试
编写 FrameworkExeTest类对框架可用性进行测试
package com.pl.bdeu.bigdata
import org.apache.commons.logging.LogFactory
import org.apache.spark.{SparkConf, SparkContext}
/**
* author pengych@pl.com
* date 2016/7/24
* function 框架可用性测试
*
执行结果:
(hello,2)
(pl,1)
(fantasia,1)
*/
object FrameworkExeTest {
def main(args: Array[String]) {
val log = LogFactory.getLog("FrameworkExeTest")
val conf = new SparkConf().setMaster("local[*]").setAppName("fantasia framework test")
val sc = new SparkContext(conf)
if(log.isDebugEnabled){
log.debug(" SparkContext initialized")
}
val linesRDD= sc.textFile("E:\\wordcount.txt")
linesRDD.flatMap(line => line.split(" ") ).map( word => (word,1) ).reduceByKey(_+_).
collect.foreach(println)
sc.stop()
}
}
总结
耐心很重要,因为网速很可能很慢
别在idea加载依赖包的时候手动干掉正在加载的进程,这样很可能导致各种找不到包的情况.在maven的安装目录: ~\apache-maven-3.3.9\conf\settings.xml的标签里自定义repository路径
本文指定repository的路径为:E:\apache-maven-3.3.9\repository
<settings xmlns="http://maven.apache.org/SETTINGS/1.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/SETTINGS/1.0.0 http://maven.apache.org/xsd/settings-1.0.0.xsd">
<localRepository>E:\apache-maven-3.3.9\repository</localRepository>
藏经阁技术资料分享群二维码
转】[1.0.2] 详解基于maven管理-scala开发的spark项目开发环境的搭建与测试的更多相关文章
- SSM框架集成及配置详解(Maven管理)
一.pom.xml(依赖管理) <?xml version="1.0" encoding="UTF-8"?> <project xmlns=& ...
- Vue1.0用法详解
Vue.js 不支持 IE8 及其以下版本,因为 Vue.js 使用了 IE8 不能实现的 ECMAScript 5 特性. 开发环境部署 可参考使用 vue+webpack. 基本用法 1 2 3 ...
- Android消息传递之EventBus 3.0使用详解
前言: 前面两篇不仅学习了子线程与UI主线程之间的通信方式,也学习了如何实现组件之间通信,基于前面的知识我们今天来分析一下EventBus是如何管理事件总线的,EventBus到底是不是最佳方案?学习 ...
- Cocos2d-x 3.0坐标系详解(转载)
Cocos2d-x 3.0坐标系详解 Cocos2d-x坐标系和OpenGL坐标系相同,都是起源于笛卡尔坐标系. 笛卡尔坐标系 笛卡尔坐标系中定义右手系原点在左下角,x向右,y向上,z向外,OpenG ...
- HashMap实现详解 基于JDK1.8
HashMap实现详解 基于JDK1.8 1.数据结构 散列表:是一种根据关键码值(Key value)而直接进行访问的数据结构.采用链地址法处理冲突. HashMap采用Node<K,V> ...
- nrf52——DFU升级USB/UART升级方式详解(基于SDK开发例程)
摘要:在前面的nrf52--DFU升级OTA升级方式详解(基于SDK开发例程)一文中我测试了基于蓝牙的OTA,本文将开始基于UART和USB(USB_CDC_)进行升级测试. 整体升级流程: 整个过程 ...
- [转载]AxureRP 7.0部件详解(一)
本文为Axure RT7.0教程,本章主要介绍menu菜单.table表格.Tree Widget 树部件三个部件,后续将持续更新...... Menu 菜单 常用案例 网站导航菜单部件通常用于母板之 ...
- NPOI2.2.0.0实例详解(十)—设置EXCEL单元格【文本格式】 NPOI 单元格 格式设为文本 HSSFDataFormat
NPOI2.2.0.0实例详解(十)—设置EXCEL单元格[文本格式] 2015年12月10日 09:55:17 阅读数:3150 using System; using System.Collect ...
- windows版mysql8.0安装详解
2018年07月04日 13:37:40 Zn昕 阅读数 6433更多 分类专栏: mysql 版权声明:本文为博主原创文章,遵循CC 4.0 by-sa版权协议,转载请附上原文出处链接和本声明. ...
随机推荐
- maven 新建项目时修改默认jre路径
新建maven项目时,JRE System Library默认为J2SE-1.5 如果想修改为1.7,修改maven的settings.xml ,在profiles中添加 <profile> ...
- Building clang on RedHat
http://btorpey.github.io/blog/2015/01/02/building-clang/ clang is a great compiler, with a boatload ...
- MySQL入门笔记 - 视图
参考书籍<MySQL入门很简单> 1.视图定义 视图是从一个或者多个表中导出来的虚拟的表,透过这个窗口可以看到系统专门提供的数据,使用户可以只关心对自己有用的数据,方便用户对数据操作,同时 ...
- java的计时:毫秒、纳秒
System.currentTimeMillis()获取毫秒值,但是其精度依赖操作系统 想实现较为精确的毫秒,可以采用 System.nanoTime()/1000000L System.nanoTi ...
- Visual Studio 2017中使用正则修改部分内容 如何使用ILAsm与ILDasm修改.Net exe(dll)文件 C#学习-图解教程(1):格式化数字字符串 小程序开发之图片转Base64(C#、.Net) jquery遍历table为每一个单元格取值及赋值 。net加密解密相关方法 .net关于坐标之间一些简单操作
Visual Studio 2017中使用正则修改部分内容 最近在项目中想实现一个小工具,需要根据类的属性<summary>的内容加上相应的[Description]特性,需要实现的效 ...
- boost的内存管理
smart_ptr raii ( Resource Acquisition Is Initialization ) 智能指针系列的都统称为smart_ptr.包含c++98标准的auto_ptr 智能 ...
- UITableViewController的子控件不随着滑动
UITableViewController的子控件不随着滑动 我们知道有时候使用UITableViewController简单便捷,省事,但是如果我们使用了addSubview,无论是[self.vi ...
- 大话设计模式C++实现-第14章-观察者模式
一.UML图 关键词:Subject维护一个Observer列表.Subject运行Notify()时就运行列表中的每一个Observer的Update(). 二.概念 观察者模式:定义了一种一对多的 ...
- 2016/3/24 ①数据库与php连接 三种输出fetch_row()、fetch_all()、fetch_assoc() ②增删改时判断(布尔型) ③表与表之间的联动 ④下拉菜单 ⑤登陆 三个页面
①数据库与php连接 图表 header("content-type:text/html;charset=utf-8"); //第一种方式: //1,生成连接,连接到数据库上的 ...
- HQL语句详解
4.3 使用HQL查询 Hibernate提供了异常强大的查询体系,使用Hibernate有多种查询方式.可以选择使用Hibernate的HQL查询,或者使用条件查询,甚至可以使用原生的SQL查询语句 ...