Selenium(九)测试用例数据分离与从文件导入数据
一.测试用例数据与代码分离
1.从之前的脚本来看,我还是把数据写在了脚本中,这样脚本的通用性很差。全局的数据其实可以从数据库、文本文件、Excel中直接读取。
2.代码和用户数据分离:

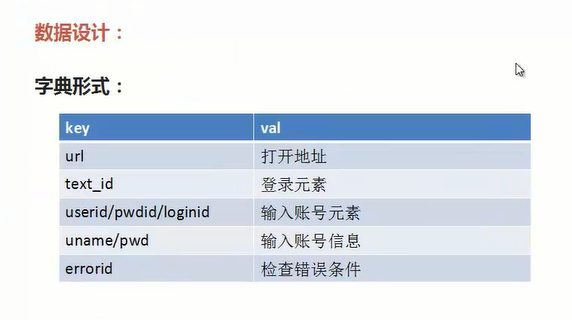
3.数据设计--以字典的形式
from selenium import webdriver
import time
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.support.ui import WebDriverWait def openBrower(): #配置浏览器
webdriver_handle = webdriver.Firefox()
return webdriver_handle def openUrl(handle,url): #打开url
handle.get(url) def get_ele_times(driver,times,func):
return WebDriverWait(driver,times).until(func) #等待方法 def findElement(driver,arg):
'''
arg must be dict
1.login:登录入口
2.user_xpath:用户名
3.pwd_xpath:密码
4.login_xpath:登录按钮 return useEle,pwdEle,loginEle
'''
ele_login = get_ele_times(driver,10,lambda driver:driver.find_element_by_xpath(arg['login']))
ele_login.click()
useEle = driver.find_element_by_xpath(arg['user_xpath'])
pwdEle = driver.find_element_by_xpath(arg['pwd_xpath'])
loginEle = driver.find_element_by_xpath(arg['login_xpath'])
return useEle,pwdEle,loginEle def sendVals(eletuple,arg):
'''
ele tuple
account:uname,pwd
'''
listkey = ['uname','pwd']
i = 0
for key in listkey:
eletuple[i].send_keys('')
eletuple[i].clear()
eletuple[i].send_keys(arg[key])
i+=1
eletuple[2].click()
def checkResult(driver,text):
try:
driver.find_element_by_link_text(test)
print ("ACCOUNT AND PWD ERROR!")
except:
print ("ACCOUNT AND PWD RIGHT!") def login_test(ele_dict):
driver = openBrower()
openUrl(driver,ele_dict['url'])
driver.maximize_window() ele_tuple = findElement(driver,ele_dict) #接收字典的值 sendVals(ele_tuple,ele_dict)
checkResult(driver,ele_dict['errorid']) driver.find_element_by_link_text('退出').click() if __name__ == '__main__':
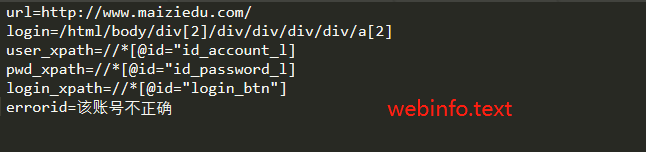
url = 'http://www.maiziedu.com/' #将数据都放入字典中
account = 'XXX'
pwd = 'maizi123456'
ele_dict = {'url':url,'login':'/html/body/div[2]/div/div/div/div/a[2]','user_xpath':'//*[@id="id_account_l"]',\
'pwd_xpath':'//*[@id="id_password_l"]','login_xpath':'//*[@id="login_btn"]',\
'errorid':'该账号不正确','uname':account,'pwd':pwd} login_test(ele_dict)
这样把用户名和密码也加入字典中是不合理的,所以要把用户名和密码抽出来单独用一个list存放:
def login_test(ele_dict,user_list):
driver = openBrower()
openUrl(driver,ele_dict['url'])
driver.maximize_window() ele_tuple = findElement(driver,ele_dict) #接收字典的值
for arg in user_list:
sendVals(ele_tuple,arg)
checkResult(driver,ele_dict['errorid']) if __name__ == '__main__':
url = 'http://www.maiziedu.com/'
account = 'XXX'
pwd = 'maizi123456'
ele_dict = {'url':url,'login':'/html/body/div[2]/div/div/div/div/a[2]','user_xpath':'//*[@id="id_account_l"]',\
'pwd_xpath':'//*[@id="id_password_l"]','login_xpath':'//*[@id="login_btn"]',\
'errorid':'该账号不正确'}
user_list = [{'uname':account,'pwd':pwd}]
login_test(ele_dict,user_list)
二.从文件导入数据

1.webinfo.py
#coding:UTF-8
import codecs def get_webinfo(path):
web_info={} #定义一个空的字典
#config=open(path)
config = codecs.open(path,'r','utf-8') #打开一个路径为path的txt文件 如果打印的话 会出现txt文件里的所有内容
for line in config: #一行一行的遍历txt文件中的内容
result = [ele.strip() for ele in line.split('=')]
'''
列表解析以'='符号为分隔,将遍历的一行的内容放在一个数组里,每一个result的形式都是[ , ]
可用来调试查看是否通过“=”分离开数据 print(result)
'''
web_info.update(dict([result])) return web_info def get_userinfo(path):
user_info = []
config = codecs.open(path,'r','utf-8')
for line in config:
user_dict = {}
result = [ele.strip() for ele in line.split(' ')]
for r in result:
account = [ele.strip() for ele in r.split('=')]
user_dict.update(dict([account]))
user_info.append(user_dict)
return user_info if __name__ == '__main__':
webinfo = get_webinfo(r'C:\Users\胡廷祥\Desktop\webinfo.txt')
for key in info:
print(key,info[key])
userinfo = get_userinfo(r'C:\Users\胡廷祥\Desktop\userinfo.txt')
for l in userinfo:
print(l)
print(userinfo)
2.login.py
from selenium import webdriver
import time
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.support.ui import WebDriverWait
from webinfo import get_webinfo
from webinfo import get_userinfo def openBrower(): #配置浏览器
webdriver_handle = webdriver.Firefox()
return webdriver_handle def openUrl(handle,url): #打开url
handle.get(url) def get_ele_times(driver,times,func):
return WebDriverWait(driver,times).until(func) #等待方法 def findElement(driver,arg):
'''
arg must be dict
1.login:登录入口
2.user_xpath:用户名
3.pwd_xpath:密码
4.login_xpath:登录按钮 return useEle,pwdEle,loginEle
'''
ele_login = get_ele_times(driver,10,lambda driver:driver.find_element_by_xpath(arg['login']))
ele_login.click()
useEle = driver.find_element_by_xpath(arg['user_xpath'])
pwdEle = driver.find_element_by_xpath(arg['pwd_xpath'])
loginEle = driver.find_element_by_xpath(arg['login_xpath'])
return useEle,pwdEle,loginEle def sendVals(eletuple,arg):
'''
ele tuple
account:uname,pwd
'''
listkey = ['uname','pwd']
i = 0
for key in listkey:
eletuple[i].send_keys('')
eletuple[i].clear()
eletuple[i].send_keys(arg[key])
i+=1
eletuple[2].click()
def checkResult(driver,text):
try:
driver.find_element_by_link_text(test)
print ("ACCOUNT AND PWD ERROR!")
except:
print ("ACCOUNT AND PWD RIGHT!") def login_test(ele_dict,user_list):
driver = openBrower()
openUrl(driver,ele_dict['url'])
driver.maximize_window() ele_tuple = findElement(driver,ele_dict) #接收字典的值
for arg in user_list:
sendVals(ele_tuple,arg)
checkResult(driver,ele_dict['errorid']) if __name__ == '__main__':
url = 'http://www.maiziedu.com/'
account = 'XXX'
pwd = 'maizi123456'
'''
ele_dict = {'url':url,'login':'/html/body/div[2]/div/div/div/div/a[2]','user_xpath':'//*[@id="id_account_l"]',\
'pwd_xpath':'//*[@id="id_password_l"]','login_xpath':'//*[@id="login_btn"]',\
'errorid':'该账号不正确'}
user_list = [{'uname':account,'pwd':pwd}]
'''
ele_dict = get_webinfo(r'C:\Users\XXX\Desktop\webinfo.txt')
user_list = get_userinfo(r'C:\Users\XXX\Desktop\userinfo.txt')
#file webinfo/userinfo ele_dict = get_webinfo(path) user_list = get_userinfo(path)
login_test(ele_dict,user_list)
Selenium(九)测试用例数据分离与从文件导入数据的更多相关文章
- 用SQLSERVER里的bcp命令或者bulkinsert命令也可以把dat文件导入数据表
用SQLSERVER里的bcp命令或者bulkinsert命令也可以把dat文件导入数据表 下面的内容的实验环境我是在SQLSERVER2005上面做的 之前在园子里看到两篇文章<C# 读取纯真 ...
- MySQL笔记(三)由txt文件导入数据
改编自学校实验,涉及一些字符集相关的问题. 索引 建库 导入数据 最终脚本 下载数据 点击这里 建库 create.sql DROP DATABASE IF EXISTS orderdb; CREAT ...
- JPA hibernate spring repository pgsql java 工程(二):sql文件导入数据,测试数据
使用jpa保存查询数据都很方便,除了在代码中加入数据外,可以使用sql进行导入.目前我只会一种方法,把数据集中在一个sql文件中. 而且数据在导入中常常具有先后关系,需要用串行的方式导入. 第一步:配 ...
- 从Excel(CSV)文件导入数据到Oracle
步骤: 1.准备数据:在excel中构造出需要的数据2.将excel中的数据另存为文本文件(有制表符分隔的)3.将新保存到文本文件中的数据导入到pl*sql中在pl*sql中选择tools--text ...
- PHP Excel文件导入数据到数据库
1.php部分(本例thinkphp5.1): 下载PHPExcel了扩展http://phpexcel.codeplex.com/ <?phpnamespace app\admin\contr ...
- Linux下通过txt文件导入数据到MySQL数据库
1.修改配置文件 在 /etc/my.conf 中添加 local_infile=1 2.重启MySQL >service mysqld restart 3.登录数据库 登录时添加参数 --lo ...
- [django]l利用xlrd实现xls文件导入数据
代码: #coding:utf-8 import os os.environ.setdefault("DJANGO_SETTINGS_MODULE", "www.sett ...
- mysql通过sql文件导入数据时出现乱码的解决办法
首先在新建数据库时一定要注意生成原数据库相同的编码形式,如果已经生成可以用phpmyadmin等工具再整理一次,防止数据库编码和表的编码不统一造成乱码. 方法一: 通过增加参数 –default-ch ...
- Jmeter—6 CSV Data Set Config 通过文件导入数据
线程组循环次数大于1的时候,请求里每次提交的数据都相同.有的系统限制了不能提交相同数据,我们通过 CSV Data Set Config 加载csv文件数据. 1 创建一个文本文件,输入参数值保存为. ...
随机推荐
- 最新 梦网科技java校招面经 (含整理过的面试题大全)
从6月到10月,经过4个月努力和坚持,自己有幸拿到了网易雷火.京东.去哪儿.梦网科技等10家互联网公司的校招Offer,因为某些自身原因最终选择了梦网科技.6.7月主要是做系统复习.项目复盘.Leet ...
- idea查看一个接口的子接口或实现类的快捷键
ctrl+h 先选中类或接口,再按ctrl+h
- Jenkins+maven+gitlab自动化部署之gitLab搭建(二)
Gitlab我们这里采用docker方式部署,详细请参考:Docker部署Gitlab11.10.4
- 数据结构 -- 二叉树(Binary Search Tree)
一.简介 在计算机科学中,二叉树是每个结点最多有两个子树的树结构.通常子树被称作“左子树”(left subtree)和“右子树”(right subtree).二叉树常被用于实现二叉查找树和二叉堆. ...
- 【C++札记】动态分配内存(malloc,free)
介绍 操作系统中存在一个内存管理器(Memory Manager),简称MM,它负责管理内存. MM提供的服务:应用程序可以向MM申请一块指定大小的内存(借出),用完之后应用程序应该释放(还回). 所 ...
- LC 33. Search in Rotated Sorted Array
问题描述 Suppose an array sorted in ascending order is rotated at some pivot unknown to you beforehand. ...
- scrapy 爬取纵横网实战
前言 闲来无事就要练练代码,不知道最近爬取什么网站好,就拿纵横网爬取我最喜欢的雪中悍刀行练手吧 准备 python3 scrapy 项目创建: cmd命令行切换到工作目录创建scrapy项目 两条命 ...
- Java+Tomcat 环境部署
Java+Tomcat 环境部署 下面在Centos7进行安装Java+Tomcat,网上的很多文章,我在部署中都有些问题,下面是我自己总结的一个安装过程! 安装Java环境 首先,我们先到Java官 ...
- WUTOJ 1284: Gold Medal(Java)
1284: Gold Medal 题目 有N个砝码,重量为:3i-1(1<=i<=N),有一块重量为 W 的金牌.现在将金牌放在天平的左边.你需要将砝码放在左边或右边使得天平平衡,如果 ...
- apache - storm - Setting Up a Development Environment
Installing a Storm release locally If you want to be able to submit topologies to a remote cluster f ...