GraphQL学习之原理篇
前言
在上一篇文章基础篇中,我们介绍了GraphQL的语法以及类型系统,算是对GraphQL有个基本的认识。在这一篇中,我们将会介绍GraphQL的实现原理。说到原理,我们就不得不依托于GraphQL的规范:GraphQL
概述
GraphQL规范主体部分有6大部分,除去我们在上一节讲到的类型系统(Type System)和语言(Language),剩下的便是整个GraphQL的主流程。也就是如下图所示的:

根据规范的章节,也就是GraphQL的实现流程,我们原理篇一一来看看规范到底定义了些什么,以及在实际的使用中,是如何贴近到规范的实现的。
Js语言的实现版本是: graphql-js
流程总览
首先我们肯定会在客户端上书写查询语句,查询语句在发送到服务端之前会转换为标准的请求体。以之前的demo为例子,当我们发起如下的请求的时候:
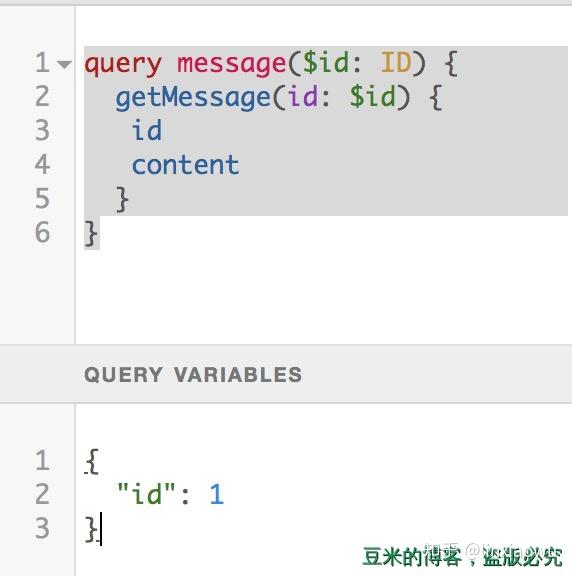
客户端发起的请求体应该具备以下三个字段(POST请求):
{
"query": "...",
"operationName": "...",
"variables": { "myVariable": "someValue", ... }
}截图如下:

这些参数表达了客户端的诉求:调用哪个方法,传递什么样的参数,返回哪些字段。
服务端拿到这段Schema之后,通过事先定义好的服务端Schema接收请求参数,校验参数,然后执行对应的resolver函数,执行完成返回数据。
在express-graphql这个包我们可以看到服务端的整体处理流程,缩略如下:
...
function graphqlHTTP(options: Options): Middleware {
...
// 返回express的中间件形式的函数
return function graphqlMiddleware(request: $Request, response: $Response) {
...
// 处理request的参数,解析出来
return getGraphQLParams(request)
.then(
graphQLParams => {}, // 解析成功
error => {} // 解析失败
)
.then(
optionsData => {
...
// GraphQL只支持GET/POST方法
if (request.method !== 'GET' && request.method !== 'POST') {
response.setHeader('Allow', 'GET, POST');
throw httpError(405, 'GraphQL only supports GET and POST requests.');
}
...
// 校验服务端这边定义的Schema
const schemaValidationErrors = validateSchema(schema);
...
// 根据query生成GraphQL的Source
const source = new Source(query, 'GraphQL request');
// 根据Source生成AST
try {
documentAST = parseFn(source);
} catch (syntaxError) {
// Return 400: Bad Request if any syntax errors errors exist.
response.statusCode = 400;
return { errors: [syntaxError] };
}
// 校验AST
const validationErrors = validateFn(schema, documentAST, [
...specifiedRules,
...validationRules,
]);
...
// 检查GET请求方法是否在Query操作符上
if (request.method === 'GET') {...}
// 执行resolver函数
}
)
.then(result => {
... // 处理GraphQL返回的响应体,做些额外的工作。
})
}
}
更多细节请查看源码。
自省(Introspection)
GraphQL服务器支持根据自己的schema进行自省。这对于我们想要查询一些关心的信息很有用。比如我们可以查询demo的一些关心的类型:
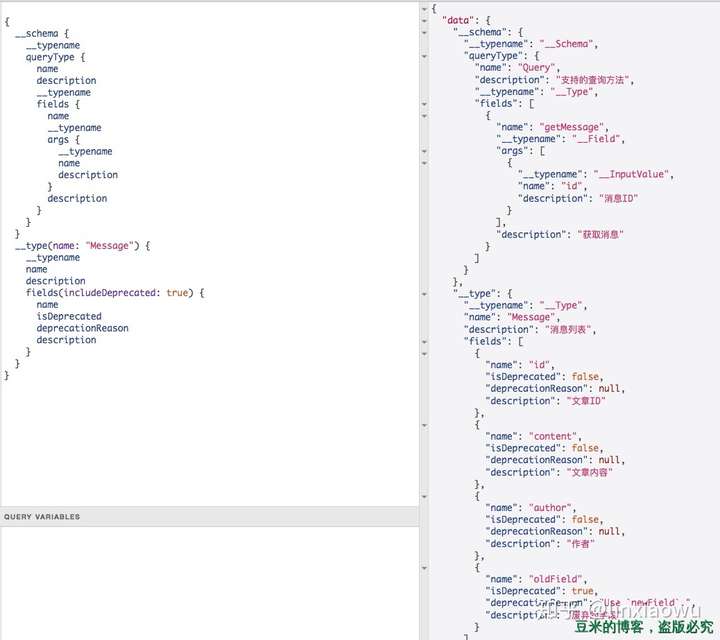
根据规范,有两类自省系统:类型名称自省(typename)和schema自省(schema和__type)。
__typename
GraphQL支持在一个查询中任何一个节点添加对类型名称的自省,在识别Interface/Union类型实际使用的类型的时候比较常用,在上图演示,我们可以看到每个节点都可以添加__typename,返回的类型也有很多:__Type、__Field、__InputValue、__Schema
带有__的都是GraphQL规范内部定义的类型,属于保留名称。开发者自定义的类型不允许出现__字符,否则在语法校验的时候会失败。
举个例子:
将demo中的type Message改为type __Message,然后会报此类错误:
Name \"__Message\" must not begin with \"__\", which is reserved by GraphQL introspection.
schema&type
__schema可以用来查询系统当前支持的所有语法,包括query语法、mutation语法,看它的结构就知道了:
type __Schema {
types: [__Type!]! => 查询系统当前定义的所有类型,包括自定义的和内部定义的所有类型
queryType: __Type! => 查询 type Query {} 里面所有的查询方法
mutationType: __Type => 查询 type Mutation {} 里面所有的mutation方法
subscriptionType: __Type => 查询 type Subscription {} 里面所有subscription方法
directives: [__Directive!]! => 查询系统支持的指令
}
而__type则是用来查询指定的类型属性。关于这些类型的内部定义请参考:Schema Introspection
上图基于的Message类型是这样的:
"""消息列表"""
type Message {
"""文章ID"""
id: ID!
"""文章内容"""
content: String
"""作者"""
author: String
"""废弃的字段"""
oldField: String @deprecated(reason: "Use \`newField\`.")
}Tips: 因为有了自省系统,GraphiQL才有可能在你输入查询信息地时候进行文字提示,因为在页面加载的时候GraphiQL会去请求这些内容,请求的内容可以看这个文件:introspectionQueries.js
校验
在上面的流程总览中提到,客户端发起的请求query字段带有查询的语法,这段语法要先经过校验,我们以下面最简单的一次查询为例:
{
getMessage {
content
author
}
}
解析出来的请求参数数据是:
{ query: '{\n getMessage {\n content\n author\n }\n}',
variables: null,
operationName: null,
raw: false
}
之后先是校验服务端定义的schema:validateSchema(schema),上一节的那个错误就是在这边抛出的。
接着将客户端的query转为Source类型的结构:
{
body: '{\n getMessage {\n content\n author\n }\n}',
name: 'GraphQL request',
locationOffset: { line: 1, column: 1 }
}
接着转为AST:graphql.parse,graphql-js根据特征字符串:
export const TokenKind = Object.freeze({
SOF: '<SOF>',
EOF: '<EOF>',
BANG: '!',
DOLLAR: '$',
AMP: '&',
PAREN_L: '(',
PAREN_R: ')',
SPREAD: '...',
COLON: ':',
EQUALS: '=',
AT: '@',
BRACKET_L: '[',
BRACKET_R: ']',
BRACE_L: '{',
PIPE: '|',
BRACE_R: '}',
NAME: 'Name',
INT: 'Int',
FLOAT: 'Float',
STRING: 'String',
BLOCK_STRING: 'BlockString',
COMMENT: 'Comment',
});
对source逐一解析生成lexer,再执行parseDocument生成解析阶段的产出物document:
{
"kind": "Document",
"definitions": [{
"kind": "OperationDefinition",
"operation": "query",
"variableDefinitions": [],
"directives": [],
"selectionSet": {
"kind": "SelectionSet",
"selections": [{
"kind": "Field",
"name": {
"kind": "Name",
"value": "getMessage",
"loc": {
"start": 4,
"end": 14
}
},
"arguments": [],
"directives": [],
"selectionSet": {
"kind": "SelectionSet",
"selections": [{
"kind": "Field",
"name": {
"kind": "Name",
"value": "content",
"loc": {
"start": 21,
"end": 28
}
},
"arguments": [],
"directives": [],
"loc": {
"start": 21,
"end": 28
}
},
{
"kind": "Field",
"name": {
"kind": "Name",
"value": "author",
"loc": {
"start": 33,
"end": 39
}
},
"arguments": [],
"directives": [],
"loc": {
"start": 33,
"end": 39
}
}
],
"loc": {
"start": 15,
"end": 43
}
},
"loc": {
"start": 4,
"end": 43
}
}],
"loc": {
"start": 0,
"end": 45
}
},
"loc": {
"start": 0,
"end": 45
}
}],
"loc": {
"start": 0,
"end": 45
}
}
其中AST支持的kind可以参考这里的定义: kinds.js
如果同时有多段语法,比如:
query gm($id: ID) {
all: getMessage {
content
author
}
single: getMessage(id: $id) {
content
author
}
}
mutation cr($input: MessageInput) {
createMessage(input: $input) {
id
}
}
那么生成的documentAST就是:
[ { kind: 'OperationDefinition',
operation: 'query',
name: { kind: 'Name', value: 'gm', loc: [Object] },
variableDefinitions: [ [Object] ],
directives: [],
selectionSet: { kind: 'SelectionSet', selections: [Array], loc: [Object] },
loc: { start: 0, end: 128 } },
{ kind: 'OperationDefinition',
operation: 'mutation',
name: { kind: 'Name', value: 'cr', loc: [Object] },
variableDefinitions: [ [Object] ],
directives: [],
selectionSet: { kind: 'SelectionSet', selections: [Array], loc: [Object] },
loc: { start: 129, end: 210 } } ]
这种情况下,必须提供一个operationName来确定操作的是哪个document!该字段也就是我们在最开始说的请求的数据中的operationName,这些校验都发声在源码的buildExecutionContext方法内
接着执行校验的最后一个步骤:校验客户端语法并给出合理的解释, graphql.validate(schema, documentAST, validationRules),比如我在将query语句变更为:
{
getMessage1 {
content
author
}
}
graphql-js就会校验不通过,并且给出对应的提示:
{
"errors": [
{
"message": "Cannot query field \"getMessage1\" on type \"Query\". Did you mean \"getMessage\"?",
"locations": [
{
"line": 2,
"column": 3
}
]
}
]
}
这种结构化的报错信息也是GraphQL的一大特点,定位问题非常方便。只要语法没问题校验阶段就能顺利完成。
执行阶段
graphql.execute是实现GraphQL规范的Execute章节的内容。根据规范,我们将执行阶段分为:
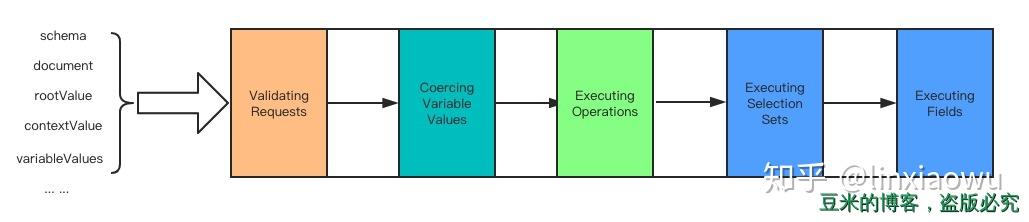
每个阶段解释一下:
- Validating Requests:到这个阶段的校验其实已经很少了,在源码实现上只需要校验入参是否符合规范即可,对应源码的方法是:
assertValidExecutionArguments - Coercing Variable Values:检查客户端请求变量的合法性,需要和schema进行比对,对应源码的方法是:
getVariableValues - Executing Operations:执行客户端请求的方法与之对应的resolver函数。对应源码的方法是:
executeOperation - Executing Selection Sets:搜罗客户端请求需要返回的字段集合,对应源码的方法是:
collectFields - Executing Fields:执行每个字段,需要进行递归,对应源码的方法是:
executeFields
接下去我们大概讲解下每个过程的一些要点
Validating Requests
源码中校验了入参的三个:schema/document/variables
Coercing Variable Values
如果该操作定义了入参,那么这些变量的值需要强制与方法声明的入参类型进行比对。比对不通过,直接报错,比如我们将getMessage改为这样:
query getMessage($id: ID){
getMessage(id: $id) {
content
author
}
}
然后变量是:
{
"id": []
}
那么经过这个函数将会报错返回:"Variable \"$id\" got invalid value []; Expected type ID; ID cannot represent value: []"
Executing Operations => Executing Selection Sets => Executing Fields
在该流程上区分operation是query还是mutation,二者执行的方式前者是并行后者是串行。
整体流程如下所示:
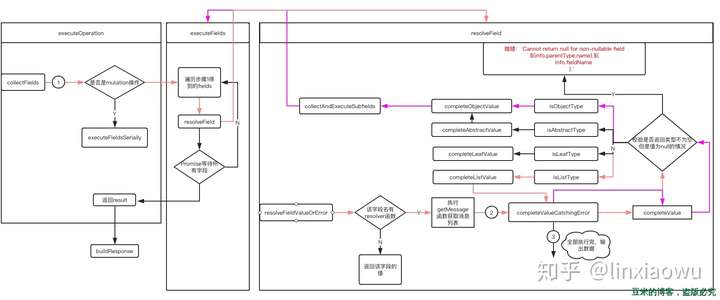
在图中标注的输出的第一次执行的数据如下,仅供参考,流程图以demo中的getMessage为例子所画,其中粉红色是第一次波执行的流程,也就是解析getMessage这个字段所走的流程,以completeValueCatchingError为界限是开始遍历[Message]中的Message,这个流程以紫色线标注,如此往复递归,遍历完客户端要求的所有数据为止
- collectFields{ getMessage: [{ kind: 'Field', alias: undefined, name: [Object], arguments: [], directives: [], selectionSet: [Object], loc: [Object] }] }
- resolveFieldValueOrError 其入参第一次传进去的source是:{ getMessage: [Function: getMessage], createMessage: [Function: createMessage], updateMessage: [Function: updateMessage] }
第一次执行返回的结果:[ { id: 0, content: 'test content', author: 'pp' }, { id: 1, content: 'test content 1', author: 'pp1' } ] - completeValueCatchingError[ { content: 'test content', author: 'pp' }, { content: 'test content 1', author: 'pp1' } ]
整个流程以getMessage这个字段名称为起点,执行resolver函数,得到结果,因为返回类型是[Message],所以会对该返回类型先进行数组解析,再解析数组里面的字段,以此不断重复递归,直到获取完客户端指定的所有字段。图形化的流程我在图中用标号和颜色标注,应该很容易看懂整个流程的。
执行resolver函数的选择
在这里回答demo中提到的问题,一种写法是将schema和resolve分别传入schema和rootValue两个字段内,另外一种写法是使用graphql-tools将typedefs和resolvers转换成带有resolve字段的schema,二者写法都是可行的,原因如下:
首先代码会给系统默认的fieldResolver赋值一个defaultFieldResolver函数,如果fieldResolver没有传值的话,这里明显没有传值。
之后在选择resolver函数执行的时候有这么一段代码来实现了上述两种写法的可行性(resolveField.js):
const resolveFn = fieldDef.resolve || exeContext.fieldResolver;
这样就优先使用schema定义的resolve函数,没有的话就使用了rootValue传递的resolver函数了。因此执行的不一样的话导致resolver函数获取参数的方式略微不同:
第一种入参是:(args, contextValue, info) 第二种入参是:(source, args, contextValue, info) => 也就是此时你想要获取参数的话得从第二个字段开始
Response
Response步骤就很简单了,定义了4个规则:
1、响应体必须是一个对象
2、如果执行operation错误的时候,那么errors必须存在,否则不应该有这个字段
2.1. `error`字段是一个数组对象,对象里面必须包含一个`message`的字段来描述错误的原因以及一些提示
2.2. 另外可能包含的字段有`location`、`path`、`extensions`来提示开发者错误的具体信息。3、如果执行operation没有错误,那么data字段必须有值
4、其他自定义的信息可以定义在extensions这个字段内。
最后
至此,整个GraphQL实现的流程到这里就结束了。更多细节请查看源码和规范,我们将在下一篇文章中聊聊GraphQL的实际项目应用GraphQL学习之实践篇
参考
1、 GraphQL
GraphQL学习之原理篇的更多相关文章
- Elasticsearch学习总结--原理篇
一.概念 1.1 官方文档 以下总结自ElasticSearch的官方文档以及自己的一些实践,有兴趣的可以直接阅读官方文档: https://www.elastic.co/guide/en/elast ...
- Cesium原理篇:5最长的一帧之影像
如果把地球比做一个人,地形就相当于这个人的骨骼,而影像就相当于这个人的外表了.之前的几个系列,我们全面的介绍了Cesium的地形内容,详见: Cesium原理篇:1最长的一帧之渲染调度 Cesium原 ...
- Cesium原理篇:7最长的一帧之Entity(下)
上一篇,我们介绍了当我们添加一个Entity时,通过Graphics封装其对应参数,通过EntityCollection.Add方法,将EntityCollection的Entity传递到DataSo ...
- 【如何快速的开发一个完整的iOS直播app】(原理篇)
原文转自:袁峥Seemygo 感谢分享.自我学习 目录 [如何快速的开发一个完整的iOS直播app](原理篇) [如何快速的开发一个完整的iOS直播app](播放篇) [如何快速的开发一个完整的 ...
- PHP学习笔记 - 进阶篇(11)
PHP学习笔记 - 进阶篇(11) 数据库操作 PHP支持哪些数据库 PHP通过安装相应的扩展来实现数据库操作,现代应用程序的设计离不开数据库的应用,当前主流的数据库有MsSQL,MySQL,Syba ...
- PHP学习笔记 - 进阶篇(6)
PHP学习笔记- 进阶篇(6) 会话控制(session与cookie) 当前的Cookie为: cookie简介 Cookie是存储在客户端浏览器中的数据,我们通过Cookie来跟踪与存储用户数据. ...
- 【转】Android LCD(二):LCD常用接口原理篇
关键词:android LCD TFT TTL(RGB) LVDS EDP MIPI TTL-LVDS TTL-EDP 平台信息:内核:linux2.6/linux3.0系统:android/ ...
- 读Flask源代码学习Python--config原理
读Flask源代码学习Python--config原理 个人学习笔记,水平有限.如果理解错误的地方,请大家指出来,谢谢!第一次写文章,发现好累--!. 起因 莫名其妙在第一份工作中使用了从来没有接 ...
- 让ASP.NET Core支持GraphQL之-GraphQL的实现原理
众所周知RESTful API是目前最流行的软件架构风格之一,它主要用于客户端和服务器交互类的软件.基于这个风格设计的软件可以更简洁,更有层次,更易于实现缓存等机制. RESTful的优越性是毋庸置疑 ...
随机推荐
- Spring Cloud Eureka 注册中心高可用机制
一.Eureka 正常工作流程 Service 服务作为 Eureka Client 客户端需要在启动的时候就要向 Eureka Server 注册中心进行注册,并获取最新的服务列表数据. Eurek ...
- @JsonSerialize @JsonIgnoreProperties @JsonIgnore @JsonFormat
@JsonIgnoreProperties 此注解是类注解,作用是json序列化时将java bean中的一些属性忽略掉,序列化和反序列化都受影响. @JsonIgnore 此注解用于属性或者方法上( ...
- Color Highlight 鼠标放在 #f3f 上面其背景会变成相应的颜色的插件 DocBlockr自动补全注释
不是 Color Highlighter 而是 Color Highlight 少了 er 颜色功能还是很爽的,找了好久 鼠标放在 #f3f 上面其背景会变成相应的颜色的插件 DocBlo ...
- IDEA重启说明
1.点击File–>Invalidate Caches/Restart,进入重启窗口 2.选择自己所需要的重启方式,四个按钮,一共三种重启方式 按钮说明: Invalidate and Rest ...
- MySQL数据库卸载有残留, windows10 sc delete 拒绝访问 失败5
sc delete 拒绝访问,原因是当前用户的权限不足,需要做的是在注册表 HKEY_LOCAL_MACHINE\Software\Microsoft\Windows\CurrentVersion\P ...
- 搭建自己的博客(二十二):通过ajax提交评论信息,并增加公式编辑功能
编辑功能使用到了ckeditor的MathJax组件.ajax提交评论可以不用刷新浏览器. 1.变化的部分
- TensorFlow(十六):TensorFlow GPU准备
一:安装cuda 下载地址 二:安装cuDNN 三:安装GPU版TensorFlow 注意:gpu版的TensorFlow打开tensorboard要使用:tensorboard --logdir C ...
- 数据结构实验之图论四:迷宫探索【dfs 求路径】
分析:起点已知,开个数组来存放路径,注意 vis 数组要初始化!另外,不能忘记了题目还要求回去的路径,只要在 dfs 之后加上就可以了. #include <bits/stdc++.h> ...
- WallpaperEngine 导入 mp4 文件出现 failed opening video
WallpaperEngine 导入 mp4 文件出现 failed opening video 如图 下载这个插件 链接:点击打开链接 密码:dkf8
- oop 编程是什么?
面向对象编程(Object Oriented Programming,OOP,面向对象程序设计)是一种计算机编程架构.OOP 的一条基本原则是计算机程序是由单个能够起到子程序作用的单元或对象组合而成.