Java集合总结(二):Map和Set
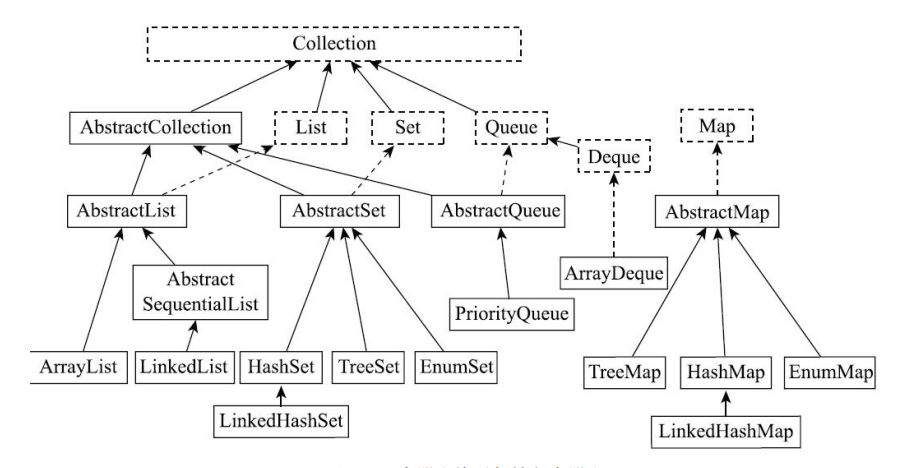
集合类的架构图:
HashMap
- 内部维护一个链表数组做哈希表,默认大小为16,最大值可以为2^30,默认负载因子0.75。
- 可以通过构造方法指定初始大小和负载因子,当键值对个数大于等于临界值threshold(数组当前大小和负载因子的乘积)时对数组进行扩容,扩容策略为当前数组大小乘以2。
- 数组的每一项都是一个链表,链表的每个结点(静态内部类Entry)都是键值对,并缓存了key的hash值。
- key 和value都可以为null,key为null时结点存储在hash表数组下标为0的位置。
put过程:
public V put(K key, V value) {
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
if (key == null)
return putForNullKey(value);
int hash = hash(key);
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}
- 通过key的hashcode计算出一个内部的hash值,然后用这个hash值对哈希表大小取余(算法为h & (length-1),此处可以体现hash表length扩容策略为指数方式的优势)定位到哈希表的位置,然后遍历该位置的链表,当遇到相等的key时,替换原来的value并将原来的value返回
- 如果没找着key相同的记录,就在相应位置添加新的链表结点,并将原来该位置的链表链接到此节点后,此节点作为头结点,当size大于阈值,则扩容到原来数组大小的两倍
HashMap不是线程安全的,多线程环境下可能造成死循环(对hash表扩容后transfer数据时发生)或者丢失数据(hash冲突后添加新节点到链表时发生)。
HashSet
HashSet通过内嵌一个HashMap对象的方式来实现,通过HashMap的key来存储,value都是相同的一个空Object()对象。与HashMap一样,要求需要存储的key实现hashcode和equals方法,且与HashMap具备同样的初始大小和扩容策略。
TreeMap
红黑树:一种大致平衡的二叉查找树,大致平衡是为了在保持较高检索效率的同时还不需要频繁调整,从而保持了统计上的性能。
- TreeMap内部使用了红黑树来实现,维护其根节点,每个key-value都内嵌于其中一个节点(Entry),同时Entry还具有left、right、parent以及color属性用以维持其树形结构。
- 结点之间按key有序,需要key实现comparable接口或者在构造方法中传入一个比较器comparator。
- 迭代时按key排序,保存时会使用key的比较结果对key进行排重,只要比较结果相同就会被认为是同一份,此时保存的key值为第一次put的key,value为第二次put进去的value
- 通过key get时,搜索二叉查找树,找到匹配的返回其value,找不到返回null
- 通过value获取时,遍历所有节点搜索
- TreeMap实现了SortedMap和NavigableMap接口,可以方便的根据键的顺序进行查找,如第一个、最后一个、某一范围的键、邻近键等。
- 根据键保存、查找、删除的效率比较高,为O(h),h为树的高度,在树平衡的情况下,h为log2(N),N为节点数。
- TreeSet
- 内部持有一个TreeMap,类似HashSet,没有重复元素,添加删除判断元素是否存在效率较高,为O(log2N),N为元素个数
- 有序,可以方便的根据顺序进行查找和操作,如第一个,最后一个,某一取值范围,某一值的近邻元素。
LinkedHashMap
- LinkedHashMap是HashMap的子类,内部有一个双向链表维护键值对的顺序,每个键值对既位于哈希表中,也位于这个双向链表中。
- 双向链表的结点LinkedHashMap.Entry继承自HashMap.Entry,添加了before和after两个引用参数,同时重写了HashMap.Entry的recordAccess和recordRemoval方法以维护和hash表中节点的关系。
- LinkedHashMap支持两种顺序,一种是插入顺序,另一种是访问顺序,默认情况下按插入有序,构造方法中accessOrder设为true的时候按访问顺序,可以用来实现LRU缓存(最近最少使用)
LinkedHashSet
LinkedHashMap也有一个对应的Set接口的实现类LinkedHashSet。LinkedHashSet是HashSet的子类,但它内部的Map的实现类是LinkedHashMap,所以它也可以保持插入顺序
EnumMap
内部使用数组实现,构造方法需要传入类型信息。允许值为null,为了区分null和没有值,用一个静态全局唯一的new Integer(0)值来作为没有值
EnumSet
内部使用位向量实现,是一个抽象类,不能直接通过new关键字来新建,必须使用类似于noneOf的其他工厂方法方法创建一个指定枚举类型的set,实际创建的对象是EnumSet的子类RegularEnumSet或JumboEnumSet。
具体子类类型根据传入的枚举类型枚举值的数量来决定:
- 小于等于64返回维护一个long变量(long为64位)作为位向量的子类RegularEnumSet
- 大于64返回一个内部维护long数组作为位向量的子类JumboEnumSet
下面是一些工厂方法:
// 初始集合包括指定枚举类型的所有枚举值
<E extends Enum<E>> EnumSet<E> allOf(Class<E> elementType)
// 初始集合包括枚举值中指定范围的元素
<E extends Enum<E>> EnumSet<E> range(E from, E to)
// 初始集合包括指定集合的补集
<E extends Enum<E>> EnumSet<E> complementOf(EnumSet<E> s)
// 初始集合包括参数中的所有元素
<E extends Enum<E>> EnumSet<E> of(E e)
<E extends Enum<E>> EnumSet<E> of(E e1, E e2)
<E extends Enum<E>> EnumSet<E> of(E e1, E e2, E e3)
<E extends Enum<E>> EnumSet<E> of(E e1, E e2, E e3, E e4)
<E extends Enum<E>> EnumSet<E> of(E e1, E e2, E e3, E e4, E e5)
<E extends Enum<E>> EnumSet<E> of(E first, E... rest)
// 初始集合包括参数容器中的所有元素
<E extends Enum<E>> EnumSet<E> copyOf(EnumSet<E> s)
<E extends Enum<E>> EnumSet<E> copyOf(Collection<E> c)
Java集合总结(二):Map和Set的更多相关文章
- Java 集合系列 15 Map总结
java 集合系列目录: Java 集合系列 01 总体框架 Java 集合系列 02 Collection架构 Java 集合系列 03 ArrayList详细介绍(源码解析)和使用示例 Java ...
- Java集合框架之Map接口浅析
Java集合框架之Map接口浅析 一.Map接口综述: 1.1java.util.Map<k, v>简介 位于java.util包下的Map接口,是Java集合框架的重要成员,它是和Col ...
- Java集合框架之map
Java集合框架之map. Map的主要实现类有HashMap,LinkedHashMap,TreeMap,等等.具体可参阅API文档. 其中HashMap是无序排序. LinkedHashMap是自 ...
- Java 集合系列 08 Map架构
java 集合系列目录: Java 集合系列 01 总体框架 Java 集合系列 02 Collection架构 Java 集合系列 03 ArrayList详细介绍(源码解析)和使用示例 Java ...
- (Set, Map, Collections工具类)JAVA集合框架二
Java集合框架部分细节总结二 Set 实现类:HashSet,TreeSet HashSet 基于HashCode计算元素存放位置,当计算得出哈希码相同时,会调用equals判断是否相同,相同则拒绝 ...
- 【JAVA集合框架之Map】
一.概述.1.Map是一种接口,在JAVA集合框架中是以一种非常重要的集合.2.Map一次添加一对元素,所以又称为“双列集合”(Collection一次添加一个元素,所以又称为“单列集合”)3.Map ...
- 【由浅入深理解java集合】(二)——集合 Set
上一篇文章介绍了Set集合的通用知识.Set集合中包含了三个比较重要的实现类:HashSet.TreeSet和EnumSet.本篇文章将重点介绍这三个类. 一.HashSet类 HashSet简介 H ...
- Java集合框架中Map接口的使用
在我们常用的Java集合框架接口中,除了前面说过的Collection接口以及他的根接口List接口和Set接口的使用,Map接口也是一个经常使用的接口,和Collection接口不同,Map接口并不 ...
- java集合框架07——Map架构与源代码分析
前几节我们对Collection以及Collection中的List部分进行了分析,Collection中还有个Set,因为Set是基于Map实现的,所以这里我们先分析Map,后面章节再继续学习Set ...
- 「 深入浅出 」java集合Collection和Map
本系列文章主要对java集合的框架进行一个深入浅出的介绍,使大家对java集合有个深入的理解. 本篇文章主要具体介绍了Collection接口,Map接口以及Collection接口的三个子接口Set ...
随机推荐
- asp.net core-11.WebHost的配置
1.添加空的web网站 ,在目录下添加settings.json文件,在控制台上输出json的信息 public class Program { public static void Main(str ...
- Spring Boot 多个域名指向同一IP
一.需求:直接通过域名访问首页(同一应用下,多个首页,包括PC端.手机端首页) 方法:采用多个域名绑定同一IP下同一应用,不同域名对应不同产品(PC.手机端)的方法,在后台通过拦截器判断 reques ...
- py datetime
python datetime模块strptime/strptime format常见格式命令- [python]2011-12-23 版权声明:转载时请以超链接形式标明文章原始出处和作者信息及本 ...
- Joy OI【走廊泼水节】题解--最小生成树推论变式
题目链接: http://joyoi.org/problem/tyvj-1391 思路: 首先这需要一个推论: "给定一张无向图,若用\(k(k<n-1)\)条边构成一个生成森林(可以 ...
- opengl 笔记
1. 本函数可以禁用多边形正面或背面上的光照.阴影和颜色计算及操作,消除不必要的渲染计算是因为无论对象如何进行旋转或变换,都不会看到多边形的背面.用GL_CULL_FACE参数调用glEnable和g ...
- puml 用于代码注释
notebook 笔记本 @startuml rectangle sql_decode.py{ object SQLDataset object Name SQLDataset : meta = &q ...
- Go 缓冲信道
缓冲信道 语法结构:cap为容量 ch := make(chan type, cap) 缓冲信道支持len()和cap(). 只能向缓冲信道发送容量以内的数据. 只能接收缓冲信道长度以内的数据. 缓冲 ...
- 使用jMeter对基于SAP ID service进行Authentication的Restful API进行并发测试
这篇文章本来Jerry只在SAP社区上写了英文版的,可以通过点击文末的"阅读原文"获得.后来有两位做Marketing Cloud开发的德国同事,写邮件询问关于文章的更多细节,声称 ...
- Java程序猿跳槽应该学哪些方面的技术
互联网产品.大型企业级项目常会用到的: 并发处理技术 具体到Java上通常是涉及java.util.concurrent.并发锁机制.NIO等方面,当然最近比较火爆的Netty框架也可以作为高并发处理 ...
- 19C imp 导入合并表空间
因为项目需要从9i 导数据到18C,所以发现如下特性 1.18C imp 导入数据,如果表空间在目标库没有,会将表导入到用户默认表空间 2.18C imp 导入数据,如果表空间在目标库有,但缺少权限. ...