Java并发包线程池之ForkJoinPool即ForkJoin框架(二)
前言
前面介绍了ForkJoinPool相关的两个类ForkJoinTask、ForkJoinWorkerThread,现在开始了解ForkJoinPool。ForkJoinPool也是实现了ExecutorService的线程池。但ForkJoinPool不同于其他类型的ExecutorService,主要是因为它使用了窃取工作机制:池中的所有线程都试图查找和执行提交给池和/或由其他活动任务创建的任务(如果不存在工作,则最终阻塞等待工作)。但ForkJoinPool并不是为了代替其他两个线程池,大家所适用的场景各不相同。ForkJoinPool主要是为了执行ForkJoinTask而存在,而ForkJoinTask在上一文已经讲过是一种可以将任务进行递归分解执行从而提高执行并行度的任务,那么ForkJoinPool线程池当然主要就是为了完成这些可递归分解任务的调度执行,加上一些对线程池生命周期的控制,以及提供一些对池的状态检查方法(例如getStealCount),用于帮助开发、调优和监视fork/join应用程序。同样,方法toString以方便的形式返回池状态的指示,以便进行非正式监视。
由于ForkJoinPool的源码太长并且其中涉及到的设计实现非常复杂,目前理解有限,只能做大概的原理阐述以及一些使用示例。
ForkJoinPool原理
在原理开始之前,先了解一下其构造方法,其参数最多的一个构造方法如下:
public ForkJoinPool(int parallelism,
ForkJoinWorkerThreadFactory factory,
UncaughtExceptionHandler handler,
boolean asyncMode) {
//...........
}
构造ForkJoinPool可以指定如下四个参数:
parallelism: 并行度,默认为CPU核心数,最小为1。为1的时候相当于单线程执行。
factory:工作线程工厂,用于创建ForkJoinWorkerThread。
handler:处理工作线程运行任务时的异常情况类,默认为null。
asyncMode:是否为异步模式,默认为 false。这里的同步/异步并不是指F/J框架本身是采用同步模式还是采用异步模式工作,而是指其中的工作线程的工作方式。在F/J框架中,每个工作线程(Worker)都有一个属于自己的任务队列(WorkQueue),这是一个底层采用数组实现的双向队列。同步是指:对于工作线程(Worker)自身队列中的任务,采用后进先出(LIFO)的方式执行;异步是指:对于工作线程(Worker)自身队列中的任务,采用先进先出(FIFO)的方式执行。为true的异步模式只在不join任务结果的消息传递框架中非常有用,因此一般如果任务的结果需要通过join合并,则该参数都设为false。
创建 ForkJoinPool实例除了使用构造方法外,从JDK8开始,还提供了一个静态的commonPool(),该方法可以通过指定系统参数的方式(System.setProperty(?,?))定义“并行度、线程工厂和异常处理类”;并且它使用的是同步模式,也就是说可以支持任务合并(join)。使用该方法返回的ForkJoinPool实例一般来说都能满足大多数的使用场景。
内部数据结构
ForkJoinPool采用了哈希数组 + 双端队列的方式存放任务,但这里的任务分为两类,一类是通过execute、submit 提交的外部任务,另一类是ForkJoinWorkerThread工作线程通过fork/join分解出来的工作任务,ForkJoinPool并没有把这两种任务混在一个任务队列中,对于外部任务,会利用Thread内部的随机probe值映射到哈希数组的偶数槽位中的提交队列中,这种提交队列是一种数组实现的双端队列称之为Submission Queue,专门存放外部提交的任务。对于ForkJoinWorkerThread工作线程,每一个工作线程都分配了一个工作队列,这也是一个双端队列,称之为Work Queue,这种队列都会被映射到哈希数组的奇数槽位,每一个工作线程fork/join分解的任务都会被添加到自己拥有的那个工作队列中。
在ForkJoinPool中的属性 WorkQueue[] workQueues 就是我们所说的哈希数组,其元素就是内部类WorkQueue实现的基于数组的双端队列。该哈希数组的长度为2的幂,并且支持扩容。如下就是该哈希数组的示意结构图:
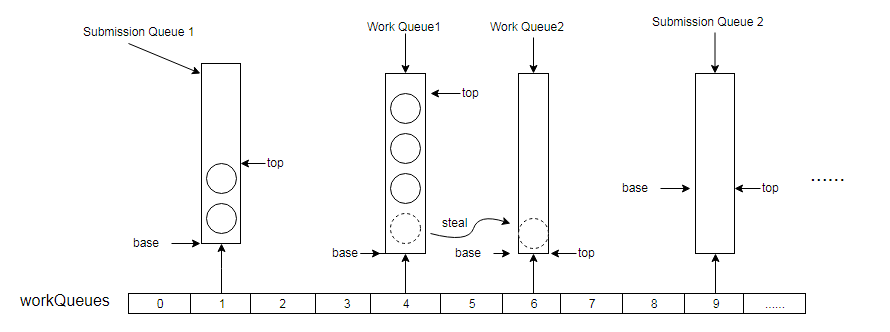
如图,提交队列位于哈希数组workQueue的奇数索引槽位,工作线程的工作队列位于偶数槽位,默认情况下,asyncMode为false,因此工作线程把工作队列当着栈一样使用,将分解的子任务推入工作队列的top端,取任务的时候也从top端取(前面关于双端队列的介绍中,凡是双端队列都会有两个分别指向队列两端的指针,这里就是图上画出的base和top),而当某些工作线程的任务为空的时候,就会从其他队列(不限于workQueue,也会是提交队列)窃取(steal)任务,如图示拥有workQueue2的工作线程从workQueue1中窃取了一个任务,窃取任务的时候采用的是先进先出FIFO的策略(即从base端窃取任务),这样不但可以避免在取任务的时候与拥有其队列的工作线程发生冲突,从而减小竞争,还可以辅助其完成比较大的任务。而当asyncMode为true的话,拥有该工作队列的工作线程将按照先进先出的策略从base端取任务,这一般只用于不需要返回结果的任务,或者事件消息传递框架。
上图展示了提交任务与分解的任务在ForkJoinPool内部的组织形式,并且简单的阐述了工作窃取机制的原理,其实,工作窃取机制的实现过程还包含很多细节,并没有怎么简单,例如还有一种“互助机制”,假设工作线程2窃取了工作线程1的任务之后,通过fork/join又分解产生了子任务,这些子任务会进入工作线程2的工作队列中,这时候如果工作线程1把剩余的任务都完成了,当他发现自己的任务被别人窃取的话,那么它会试着去窃取工作线程2的任务,(你偷了我的,现在我就要偷你的),这就是互助机制。
关于ForkJoinPool的源码太复杂就不分析了,可以参考如下几篇文章:https://www.jianshu.com/apps?utm_medium=desktop&utm_source=navbar-apps 和https://www.cnblogs.com/zhuxudong/p/10122688.html
一些public方法
除了同ThreadPoolExecutor线程池一样重写了AbstractExecutorService的一些方法例如,submit(异步提交任务返回Future)、execute(异步提交任务无返回值)、invokeAll(批量执行该类没有重写)、invokeAny(只要有一个执行结束就返回,该类没有重写)等方法之外,ForkJoinPool增加了一些自己特有的用于监视其状态的方法可供使用者调用,但一般来说这些方法都用不上,除了那些提交任务的方法:
awaitQuiescence,等待线程池空闲
isQuiescent,如果线程池处于空闲状态,返回true。
getActiveThreadCount,获取正在执行任务或窃取任务的线程个数。
getQueuedSubmissionCount(),获取提交提交给线程池但还没开始执行的任务个数。就是所有提交队列中任务之和。
hasQueuedSubmissions(),若getQueuedSubmissionCount不为0,返回true,表示存在任务还在提交队列没被执行。
getQueuedTaskCount(),返回所有工作线程工作队列中的所有任务个数。
getRunningThreadCount(),返回正在运行的没有被阻塞(例如调用Join会被阻塞)的线程个数。
getStealCount(),返回线程从另一个线程的工作队列中窃取的任务总数的估计值。
getParallelism(),返回线程池的并行度,构造方法中有这个参数。
getAsyncMode(),返回工作线程从其任务队列中取走任务的模式,默认为false,表示LIFO后进先出,否则是FIFO,构造方法中有这个参数。
使用示例
对于Fork/Join的使用,也是围绕ForkJoinTask的三个抽象子类的不同作用进行的,我们知道ForkJoinTask的三个子类是RecursiveAction、RecursiveTask和CountedCompleter,分别用于不返回结果,返回结果以及完成触发指定操作的操作。
对于RecursiveAction的使用,最容易让人想到的例子就是,最一个集合或者数组中的所有元素进行自增运行的操作:
public class IncrementTask extends RecursiveAction {
static final int THRESHOLD = 10;
final long[] array;
final int lo, hi;
IncrementTask(long[] array, int lo, int hi) { // 构造方法,指定数组下标范围
this.array = array;
this.lo = lo;
this.hi = hi;
}
// 实现抽象类的接口,这个任务所执行的主要计算。
protected void compute() {
if (hi - lo < THRESHOLD) { // 数组索引区间小于阈值(任务足够小)
for (int i = lo; i < hi; ++i)
array[i]++; // 对每个元素自增1
} else {
int mid = (lo + hi) >>> 1; // 拆分一半
invokeAll(new IncrementTask(array, lo, mid), new IncrementTask(array, mid, hi)); // 一起执行
}
}
public static void main(String[] args) {
long[] array = ... ;//一个很长的数组
new IncrementTask(array, 0, array.length).invoke(); //隐式的使用了ForkJoinPool.commonPool()
}
}
对于RecursiveAction这种不返回结果的并行运算其实还有很多应用场景,比如Java Doc中使用其来对一个数组的元素进行排序,有比如要将一批数据持久化到数据库等。
static class SortTask extends RecursiveAction {
final long[] array; final int lo, hi;
SortTask(long[] array, int lo, int hi) { //构造方法,指定数组下标范围
this.array = array; this.lo = lo; this.hi = hi;
}
SortTask(long[] array) { this(array, 0, array.length); } //构造方法,默认全部数组
//实现抽象类的接口,这个任务所执行的主要计算。
protected void compute() {
if (hi - lo < THRESHOLD) //数组索引区间小于阈值(任务足够小)
sortSequentially(lo, hi); //排序
else {
int mid = (lo + hi) >>> 1; //拆分一半
invokeAll(new SortTask(array, lo, mid), new SortTask(array, mid, hi)); //一起执行
merge(lo, mid, hi); //合并结果
}
}
// implementation details follow:
static final int THRESHOLD = 1000; //数组索引最小区间阈值
void sortSequentially(int lo, int hi) {
Arrays.sort(array, lo, hi);
}
void merge(int lo, int mid, int hi) { //合并结果
long[] buf = Arrays.copyOfRange(array, lo, mid);
for (int i = 0, j = lo, k = mid; i < buf.length; j++)
array[j] = (k == hi || buf[i] < array[k]) ? buf[i++] : array[k++];
}
}
Java Doc提供的排序示例
对于RecursiveTask的使用,也是最常用的,例如求和运算1+2+3+4+…+1000000000。
public class SumTask extends RecursiveTask<Long>{
private static final int THRESHOLD = 100000;
private int start;//开始下标
private int end;//结束下标
public SumTask(int start, int end) {
this.start = start;
this.end = end;
}
private long computeByUnit() {
long sum = 0L;
for (int i = start; i < end; i++) {
sum += i;
}
return sum;
}
@Override
protected Long compute() {
//如果当前任务的计算量在阈值范围内,则直接进行计算
if (end - start < THRESHOLD) {
return computeByUnit();
} else {//如果当前任务的计算量超出阈值范围,则进行计算任务拆分
//计算中间索引
int middle = (start + end) / 2;
//定义子任务-迭代思想
SumTask left = new SumTask(start, middle);
SumTask right = new SumTask(middle, end);
//划分子任务-fork
left.fork();
//right.fork(); 尾部递归消除
//合并计算结果-join
return left.join() + right.invoke();
}
}
public static void main(String[] args) throws Exception{
//这两种方式提交都可以
long result = new SumTask(1, 1000000001).invoke(); //不响应中断,必须等待执行完成
Future<Long> future = ForkJoinPool.commonPool().submit(new SumTask(1, 1000000001));
result = future.get(); //可以被中断
}
}
提交任务到ForkJoinPool可以直接使用ForkJoinTask的invoke,隐式的使用ForkJoinPool.commonPool()池,也可以显示的创建ForkJoinPool实例通过submit提交,通过Future.get的方法获取结果,区别在于后者支持中断,前者必须等待任务完成才会返回。
对于CountedCompleter的使用,由于该类设计成可以构建任务树,所以使用起来灵活多变,CountedCompleter类本身只是提供了一种并发执行任务的设计理念,想要使用它必须要对其有很深的理解才行。这里列举一下Java Doc给出的示例吧:
示例一及其三个改进版本,该示例只是一种简单的递归分解任务,但比起传统的fork/join来说,其树形任务结构依然更加可取,因为它们减少了线程间的通信并提高了负载平衡:
//版本一
class MyOperation { void apply(E e) { ... } } //具体的任务执行逻辑 class ForEach extends CountedCompleter { public static void forEach(E[] array, MyOperation op) {
new ForEach(null, array, op, 0, array.length).invoke(); //隐式调用ForkJoinPool.commonPool()执行该任务
} final E[] array;
final MyOperation op;
final int lo, hi; ForEach(CountedCompleter p, E[] array, MyOperation op, int lo, int hi) {
super(p);
this.array = array;
this.op = op;
this.lo = lo;
this.hi = hi;
} public void compute() { // version 1
if (hi - lo >= 2) { //分解任务
int mid = (lo + hi) >>> 1;
setPendingCount(2); // 必须在fork之前设置挂起计数器
new ForEach(this, array, op, mid, hi).fork(); // fork右子节点
new ForEach(this, array, op, lo, mid).fork(); // fork左子节点
}
else if (hi > lo) //直接执行足够小的任务
op.apply(array[lo]);
tryComplete(); //尝试完成该任务,要么递减挂起任务数,已经到0的话,就将父节点的挂起数减1,以此类推
}
} //版本2,尾部递归消除
class ForEach<E> ...
public void compute() { // version 2
if (hi - lo >= 2) {
int mid = (lo + hi) >>> 1;
setPendingCount(1); // 挂起计数器为1
new ForEach(this, array, op, mid, hi).fork(); // fork右子节点
new ForEach(this, array, op, lo, mid).compute(); // 直接执行左子节点,尾部递归消除
}
else {
if (hi > lo)
op.apply(array[lo]);
tryComplete();
}
}
} //版本3
public void compute() { // version 3
int l = lo, h = hi;
while (h - l >= 2) { //迭代循环fork每一个任务,而不用创建左子节点
int mid = (l + h) >>> 1;
addToPendingCount(1);//每一次设置挂起任务数为1
new ForEach(this, array, op, mid, h).fork(); // right child
h = mid;
}
if (h > l)
op.apply(array[l]);
propagateCompletion(); //传播完成
}
}
示例二,搜索数组:
class Searcher extends CountedCompleter {
final E[] array;
final AtomicReference result; //记录搜索结果
final int lo, hi;
Searcher(CountedCompleter p, E[] array, AtomicReference result, int lo, int hi) {
super(p);
this.array = array; this.result = result; this.lo = lo; this.hi = hi;
}
public E getRawResult() { return result.get(); }//返回结果
public void compute() { // 与ForEach 版本3类似
int l = lo, h = hi;
while (result.get() == null && h >= l) { //迭代循环创建一个任务
if (h - l >= 2) { //分解任务
int mid = (l + h) >>> 1;
addToPendingCount(1); //设置挂起任务数为1
new Searcher(this, array, result, mid, h).fork();
h = mid;
}
else { //足够小,只有一个元素了
E x = array[l];
//找到我们想要的数据了,设置到result中
if (matches(x) && result.compareAndSet(null, x))
quietlyCompleteRoot(); // 根任务现在可以获取结果了
break;
}
}
tryComplete(); // normally complete whether or not found
}
boolean matches(E e) { ... } // 如果找到了返回true
public static E search(E[] array) {
return new Searcher(null, array, new AtomicReference(), 0, array.length).invoke();
}
}
示例三,map-reduce:
class MyMapper { E apply(E v) { ... } }
class MyReducer { E apply(E x, E y) { ... } }
class MapReducer extends CountedCompleter {
final E[] array; final MyMapper mapper;
final MyReducer reducer; final int lo, hi;
MapReducer sibling;
E result;
MapReducer(CountedCompleter p, E[] array, MyMapper mapper, MyReducer reducer, int lo, int hi) {
super(p);
this.array = array; this.mapper = mapper;
this.reducer = reducer; this.lo = lo; this.hi = hi;
}
public void compute() {
if (hi - lo >= 2) { //分解任务
int mid = (lo + hi) >>> 1;
MapReducer left = new MapReducer(this, array, mapper, reducer, lo, mid);
MapReducer right = new MapReducer(this, array, mapper, reducer, mid, hi);
left.sibling = right;
right.sibling = left;
setPendingCount(1); // 只有右任务的挂起的
right.fork(); //fork又任务
left.compute(); // 直接执行左子节点
}
else { //任务足够小
if (hi > lo)
result = mapper.apply(array[lo]); //直接执行
tryComplete();
}
}
public void onCompletion(CountedCompleter caller) {
if (caller != this) {
MapReducer child = (MapReducer)caller;
MapReducer sib = child.sibling; //兄弟任务
if (sib == null || sib.result == null)
result = child.result; //没有兄弟任务那就是最小那个任务
else
//合并兄弟任务的结果
result = reducer.apply(child.result, sib.result);
}
}
public E getRawResult() { return result; } //返回结果
public static E mapReduce(E[] array, MyMapper mapper, MyReducer reducer) {
return new MapReducer(null, array, mapper, reducer,
0, array.length).invoke();
}
}
示例四,完全遍历:
class MapReducer extends CountedCompleter { // version 2
final E[] array;
final MyMapper mapper;
final MyReducer reducer; final int lo, hi;
MapReducer forks, next; // record subtask forks in list
E result;
MapReducer(CountedCompleter p, E[] array, MyMapper mapper,
MyReducer reducer, int lo, int hi, MapReducer next) {
super(p);
this.array = array; this.mapper = mapper;
this.reducer = reducer; this.lo = lo; this.hi = hi;
this.next = next;
}
public void compute() {
int l = lo, h = hi;
while (h - l >= 2) { //循环创建任务
int mid = (l + h) >>> 1;
addToPendingCount(1);
(forks = new MapReducer(this, array, mapper, reducer, mid, h, forks)).fork();
h = mid;
}
if (h > l) //任务足够小,直接执行
result = mapper.apply(array[l]);
// 通过减少和推进子任务链接来完成流程
//利用firstComplete,nextComplete两个方法遍历
for (CountedCompleter c = firstComplete(); c != null; c = c.nextComplete()) {
for (MapReducer t = (MapReducer)c, s = t.forks; s != null; s = t.forks = s.next)
t.result = reducer.apply(t.result, s.result);
}
}
public E getRawResult() { return result; }
public static E mapReduce(E[] array, MyMapper mapper, MyReducer reducer) {
return new MapReducer(null, array, mapper, reducer,
0, array.length, null).invoke();
}
}}
示例五,触发器:
class HeaderBuilder extends CountedCompleter<...> { ... }
class BodyBuilder extends CountedCompleter<...> { ... }
class PacketSender extends CountedCompleter<...> {
PacketSender(...) { super(null, 1); ... } // trigger on second completion
public void compute() { } // never called
public void onCompletion(CountedCompleter caller) { sendPacket(); }
}
// sample use:
PacketSender p = new PacketSender();
new HeaderBuilder(p, ...).fork();
new BodyBuilder(p, ...).fork();
说实话,这几个示例除了前面三个,其他的我基本上也没完全理解,先记录着吧,关于RecursiveAction、RecursiveTask的更多示例,可以查看Java Doc的类注释。其实一般来说,利用那两个简单的RecursiveAction、RecursiveTask已经足够解决我们的问题了,在没有理解CountedCompleter之前,最好不要使用它。
总结
其实要想详细的理解ForkJoinPool,也就是Fork/Join框架的实现过程是一个非常耗时耗精力的事情,我这里只是记录了我自己对ForkJoinPool粗浅的理解,所谓总结也就谈不上有多深入了,但我们学习这些框架结构的时候,最主要的其实也还是学习其设计思想与理念,并不一定非要每一句代码都分析到,对于ForkJoinPool线程池和ForkJoinTask、ForkJoinWorkerThread三者实现的Fork/Join框架,目前按我的理解它就是为了利于现有计算机多核心的架构,将一些可以进行分解的任务进行递归分解之后并行的执行,有些地方也将这种思想称之为分治法,并在执行完成之后利于递归的原理将任务结果汇聚起来,从而达到快速解决复杂任务的高效编程设计。对于ForkJoinPool其内部采用了很多为了加快并行度而实现的设计思想,例如工作窃取机制,互助机制,垃圾回收机制等等都是我们值得学习借鉴的地方。
Java并发包线程池之ForkJoinPool即ForkJoin框架(二)的更多相关文章
- Java并发包线程池之ForkJoinPool即ForkJoin框架(一)
前言 这是Java并发包提供的最后一个线程池实现,也是最复杂的一个线程池.针对这一部分的代码太复杂,由于目前理解有限,只做简单介绍.通常大家说的Fork/Join框架其实就是指由ForkJoinPoo ...
- java并发包&线程池原理分析&锁的深度化
java并发包&线程池原理分析&锁的深度化 并发包 同步容器类 Vector与ArrayList区别 1.ArrayList是最常用的List实现类,内部是通过数组实现的, ...
- Java并发包——线程池
Java并发包——线程池 摘要:本文主要学习了Java并发包中的线程池. 部分内容来自以下博客: https://www.cnblogs.com/dolphin0520/p/3932921.html ...
- Java并发包线程池之Executors、ExecutorCompletionService工具类
前言 前面介绍了Java并发包提供的三种线程池,它们用处各不相同,接下来介绍一些工具类,对这三种线程池的使用. Executors Executors是JDK1.5就开始存在是一个线程池工具类,它定义 ...
- Java并发包线程池之ScheduledThreadPoolExecutor
前言 它是一种可以安排在给定的延迟之后执行一次或周期性执行任务的ThreadPoolExecutor.因为它继承了ThreadPoolExecutor, 当然也具有处理普通Runnable.Calla ...
- Java并发包--线程池原理
转载请注明出处:http://www.cnblogs.com/skywang12345/p/3509954.html 线程池示例 在分析线程池之前,先看一个简单的线程池示例. 1 import jav ...
- Java并发包--线程池框架
转载请注明出处:http://www.cnblogs.com/skywang12345/p/3509903.html 线程池架构图 线程池的架构图如下: 1. Executor 它是"执行者 ...
- Java并发包线程池之ThreadPoolExecutor
参数详解 ExecutorService的最通用的线程池实现,ThreadPoolExecutor是一个支持通过配置一些参数达到满足不同使用场景的线程池实现,通常通过Executors的工厂方法进行配 ...
- 第9章 Java中的线程池 第10章 Exector框架
与新建线程池相比线程池的优点 线程池的分类 ThreadPoolExector参数.执行过程.存储方式 阻塞队列 拒绝策略 10.1 Exector框架简介 10.1.1 Executor框架的两级调 ...
随机推荐
- Vue框架之组件与过滤器的使用
一.组件的使用 局部组件的使用 打油诗: 1.声子 2.挂子 3.用 var App = { tempalte:` <div class='app'></div>` }; ...
- Django之form表单详解
构建一个表单 假设你想在你的网站上创建一个简单的表单,以获得用户的名字.你需要类似这样的模板: <form action="/your-name/" method=" ...
- HTML中使用图像
插入图像 在页面中插入图像的标记只有一个,就是img标记. 语法为:<img src="图片地址" alt="下载失败时的替换文本" title='提示文 ...
- windows cmd命令学习
tasklist|findstr "py"
- JDBC课程1-实现Driver接口连接mysql数据库、通用的数据库连接方法(使用文件jdbc.properties)
package day_18; import jdk.internal.util.xml.impl.Input; import org.junit.Test; import java.io.Input ...
- IntelliJ IDEA如何默认使用阿里云的Maven仓库
点击IntelliJ IDEA的config中的setting选项 在<mirrors>节点中加上一个子节点,然后保存即可: <mirror> <id>alimav ...
- Wide & Deep Learning for Recommender Systems
Wide & Deep Learning for Recommender Systems
- Java基础面试题1
http://blog.csdn.net/jackfrued/article/details/44921941 1.面向对象的特征有哪些方面? 答:面向对象的特征主要有以下几个方面: - 抽象:抽象 ...
- vs2017 c# 控制台 输出中文显示问号 ; vs2017 c# 控制台 输出中文显示乱码
问题: 解决: 在main方法最前面加一句就OK了! Console.OutputEncoding = Encoding.GetEncoding("gbk"); 或者 Consol ...
- xld特征
halcon中什么是xld? xld(eXtended Line Descriptions) 扩展的线性描述,它不是基于像素的,人们称它是亚像素,只不过比像素更精确罢了,可以精确到像素内部的一种描述. ...