Zookeeper安装和运行
安装环境:
CentOS 7 内存1GB
JDK版本:1.8.0_112
为JDK配置如下环境变量:
编辑/etc/profile.d/jdk.sh
JAVA_HOME=/usr/local/jdk1.8.0_112
export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH
之后运行下面的命令:
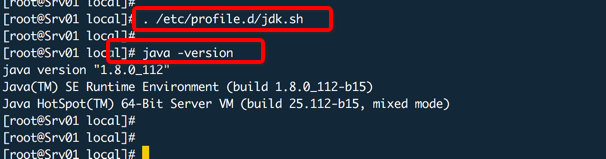
注意:在生产环境中为了避免内存频繁的换进换出,建议将JAVA堆大小设置的更大一点,这取决于你的物理内存大小。
关于集群可用:如果能忍受N台ZK宕机,那么你的集群就需要有2N+1台ZK服务器。3台组成的集群则允许1台失败,5台组成的集群则允许2台失败。集群中ZK数量要保持奇数,当然偶数也可以,只是3台组成的ZK和4台组成的允许失败的台数是一样的。
单机安装
下载稳定版zookeeper,我这里使用的是3.4.11,我把它解压在了/usr/local下面,其实任何路径都可以
配置ZK的环境变量,编辑/etc/profile.d/zk.sh文件
ZOOKEEPER_HOME=/usr/local/zookeeper-3.4.11
export PATH=$ZOOKEEPER_HOME/bin:$ZOOKEEPER_HOME/conf:$PATH
执行下面的命令

准备配置文件
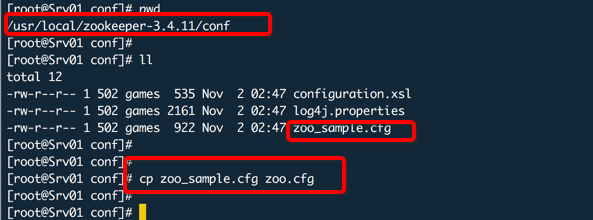
在程序目录中的conf目录中创建zoo.cfg配置文件,zoo_sample.cfg是模板文件,直接复制一下修改名称,然后再修改里面的内容。
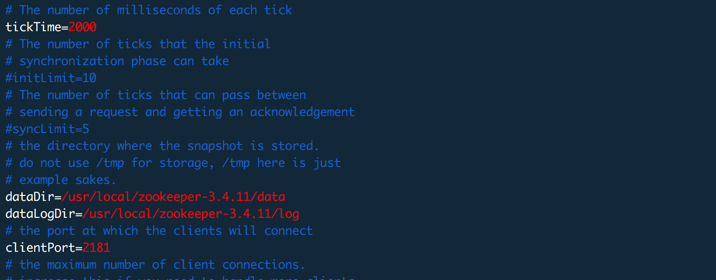
这个配置文件可以设置很多参数,默认只有最基本的。其他参数后面再说
| 参数 | 说明 |
| tickTime | 基本事件单元,单位毫秒。用来设置心跳,最小的session过期时间为tickTime的两倍,ZK中的其他时间都是以这个为倍数的。 |
| dataDir |
存储内存中数据库快照的位置,默认是/tmp/zookeeper,这个只是例子,我们修改为ZK家目录下的data,这个data其实也没有,我们需要手动建立。快照文件并不是实时的,运行一段时间才会有。 |
| dataLogDir |
日志路径,也就是事务日志。我们知道对ZK的读和写都是在内存中完成,所以速度非常快,但是如果停止ZK再启动数据还是需要保证的,所以就会有这样一个路径用来保存事务日志,当ZK再次启动时加载到内存重演过程来恢复数据。这个目录会有一个叫做version-2的目录,这个目录确定了当前事务日志的版本号,当下次某个版本的ZK对其进行修改时,版本号发生变化。日志文件大小为64M,如果数据比较多就会有多个这样大小的文件。 建议将事物日志保存到单独的磁盘而且是高速磁盘。因为为了一致性,ZK对于客户端的写入请求在返回之前就要把本次操作写入到事物日志中。logDir |
| logDir | zookeeper服务的日志路径 |
| clientPort | 监听客户端连接的端口 |
修改一下zkEnv.sh脚本,zk启动后会有一个zookeeper.out文件,这个文件随着时间会越来越大,默认会在执行zkServer.sh的位置生成,所以我们要修改为指定路径。

配置好上面的设置就可以启动了。
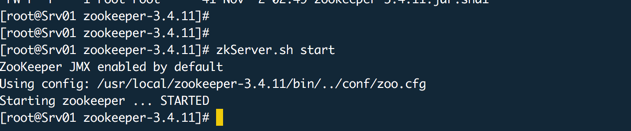
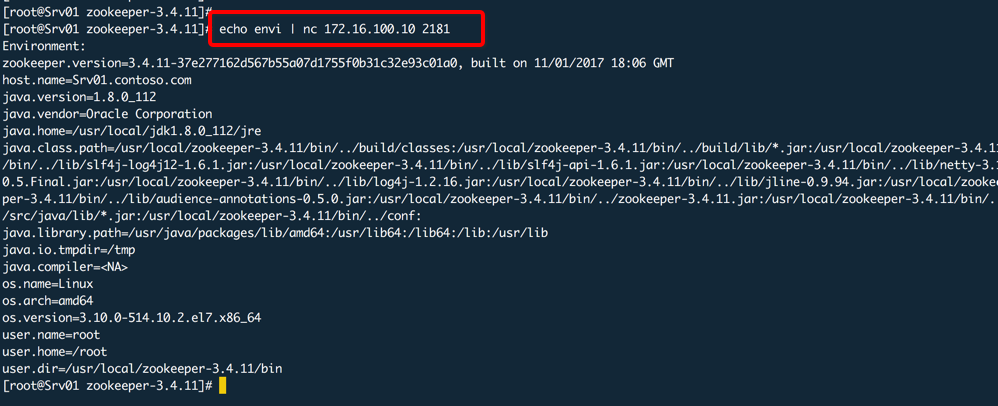
测试连接
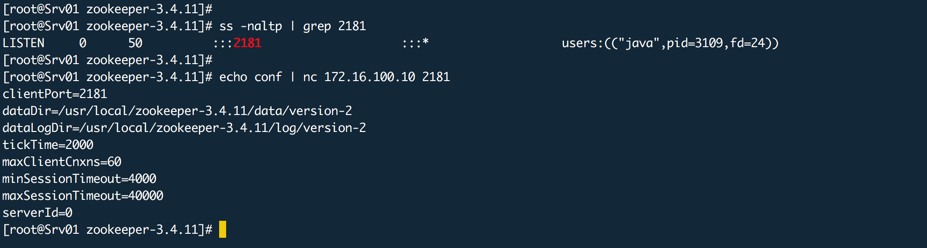 nc是网络命令,全称是netcat,其实使用telnet也一样
nc是网络命令,全称是netcat,其实使用telnet也一样
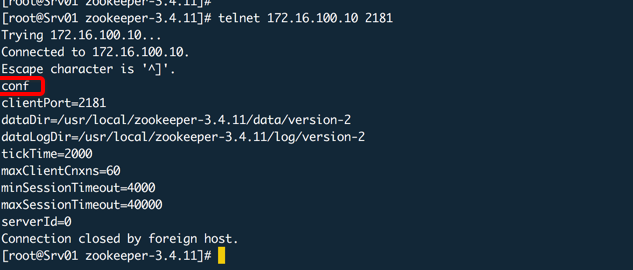
ZK客户端
zkCli.sh -server IP:PORT
也可以不输入IP和端口,默认就会连接127.0.0.1:2181

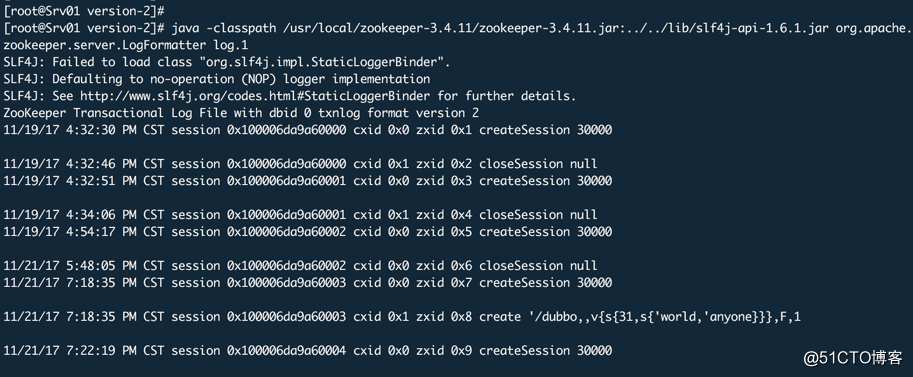
查看事务日志:
java -classpath /usr/local/zookeeper-3.4.11/zookeeper-3.4.11.jar:../../lib/slf4j-api-1.6.1.jar org.apache.zookeeper.server.LogFormatter log.1
集群安装
集群配置和单机安装一样,只是配置文件内容会多一部分内容,内容如下:
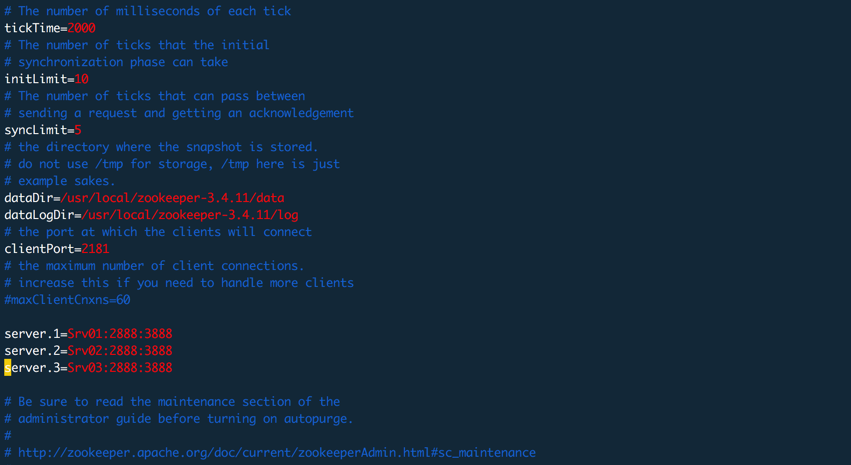
"server.id=host:port:port" 表示不同ZK服务器的配置。id表示不同服务器,在服务器配置文件的dataDir所设置的目录里需要手动创建一个叫做myid的文件,这个文件只有一行内容,标识自己的身份也就是自己的ID值,该值范围可以是1-255之间。
echo 1 > /usr/local/zookeeper3.4.11/data/myid
host:主机名
第一个port:集群中从服务器(follower)连接到主服务器(leader)的端口,也就是作为leader时使用的,其他从服务器都连接到主服务器的这个端口
第二个port:进行leader选举时使用的端口
集群启动和单机启动一样,使用同样的命令,需要注意的是集群不可用那么你将无法连接到ZK服务器,也就是说3台你只启动1台是无法Telnet到ZK的,至少你要启动2台才行。
zkServer.sh start
# 启动集群有可能需要运行下面命令清理防火墙规则,有可能某种安全机制影响集群启动,主要是选举过程
iptables -F
集群启动日志说明
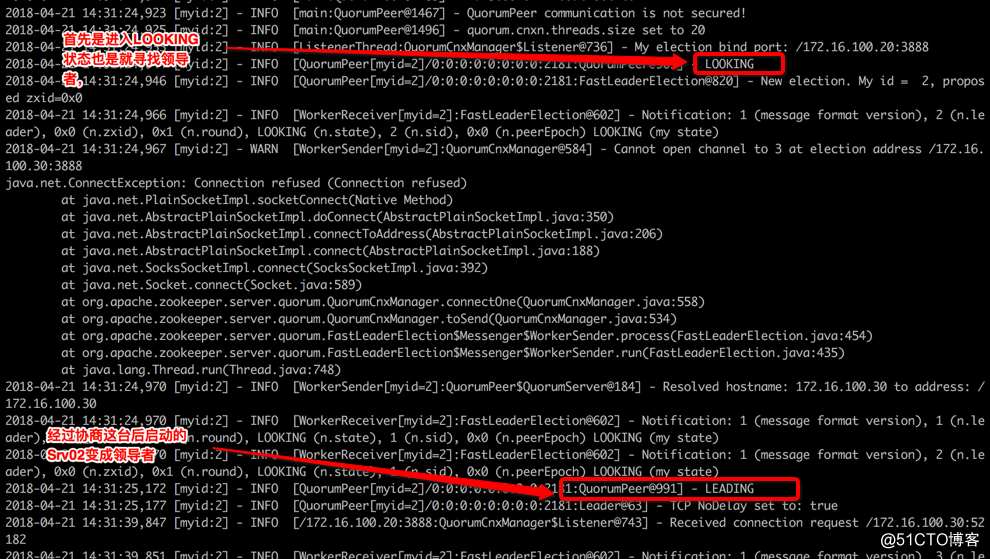
Srv01的日志
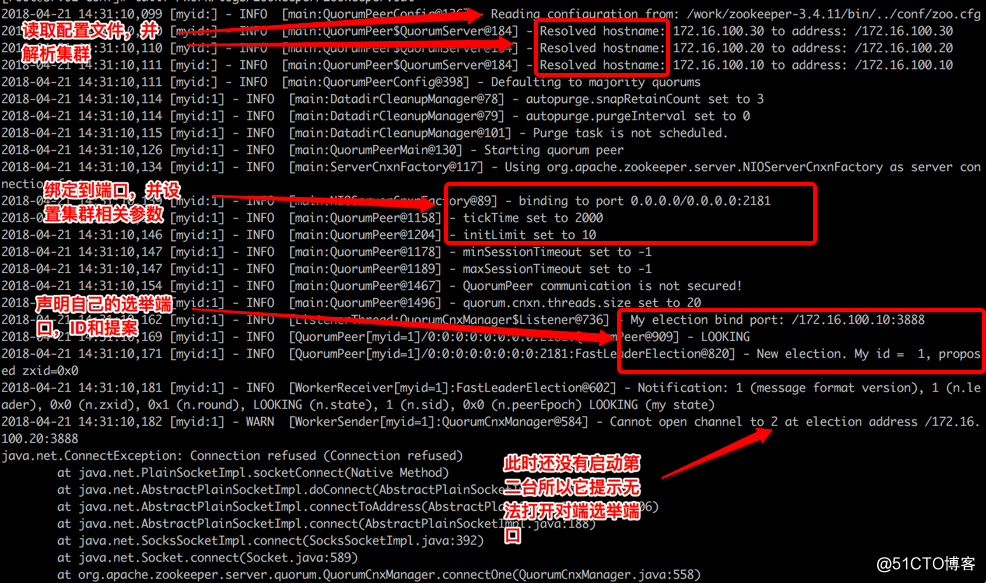
如果对端没有准备好它会一直反复这样的提示
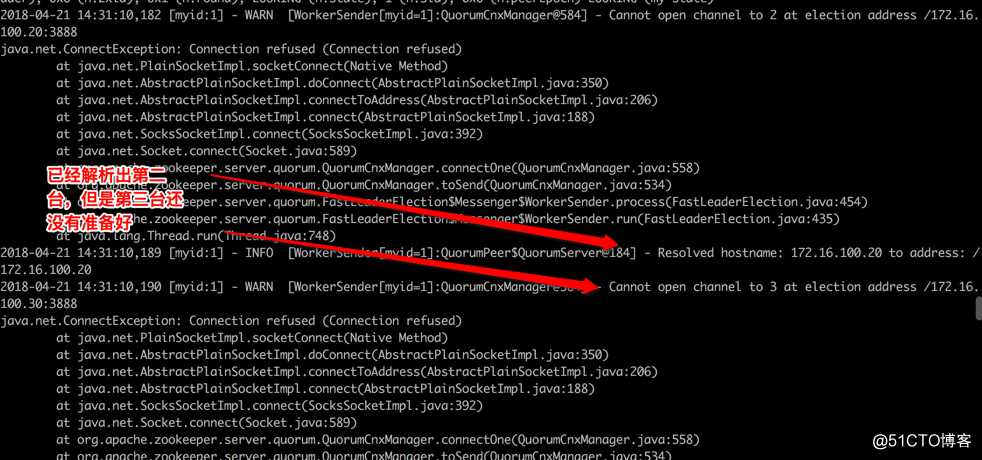
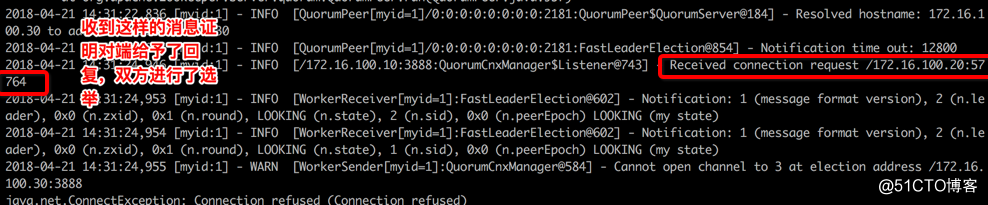
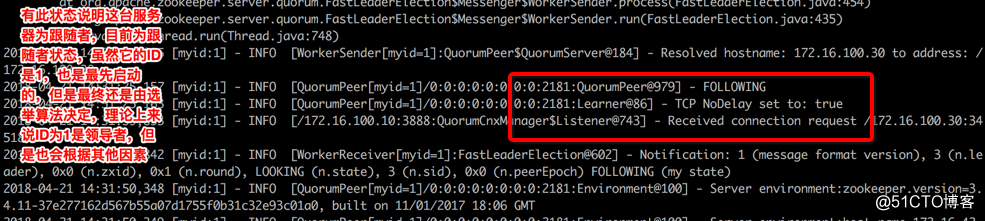
Srv02的日志
Srv03的日志
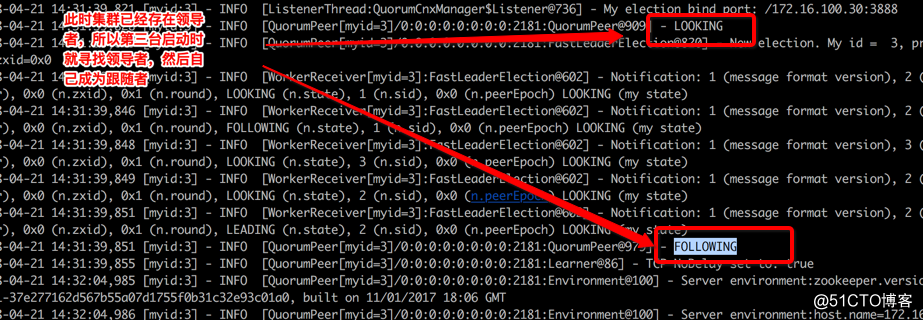
服务器状态
| 状态 | 说明 |
| LOOKING | 寻找Leader,当服务器出现这个状态时,它会认为当前集群没有Leader,因此需要进入选举 |
| FOLLOWING | 跟随者状态,表示当前是Follower角色 |
| LEADING | 领导者状态,表示当前为Leader角色 |
| OBSERVING | 观察者状态,表示当前服务器是Observer角色 |
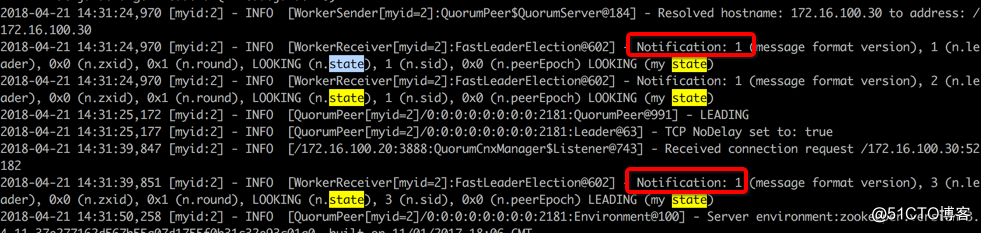
如下为选举信息,其中 (my state) 为当前服务器的状态,最后一次表示它的最终状态,通过看这个前后变化可以知道该服务器在状态变化。
配置Zookeeper
| 基本配置:运行ZK最少需要配置的内容 | |
| clientPort | 监听客户端连接的端口 |
| dataDir | 数据库快照存储位置 |
| tickTime | 客户单到服务器之间的心跳频率,也叫做基本时间单元,单位毫秒,客户端连接ZK之后彼此要发送心跳信息,这个发送频率就是这个时间。配置中所有用到时间地方都会以这个为基础,也就是它的倍数,或者可以理解为能够容忍多少个心跳时间。 |
| 高级配置 | |
| dataLogDir | 事务日志保存路径,生产环境中建议把日志路径和快照路径分别保存在独立磁盘上,避免出现磁盘IO繁忙从而导致性能下降,必要时也可以关闭日志功能 |
| maxClientCnxns | 限制连接到ZK上的客户端数量,并且限制并发连接数量,它通过IP来区分不同客户端。值为0表示不做任何限制。注意这里的限制是针对单台客户端到服务器的,并不是控制所有客户端连接的。默认60. |
| minSessionTimeout | 最小会话超时时间,默认为tickTime的2倍。不建议把这个值设置的比tickTime小。客户端连接到ZK时如果在这个最小时间内没有和ZK联系则标记为超时,也就是说会断开。 |
| maxSessionTimeout | 最大会话超时时间,默认为20倍的最小会话超时时间。不建议把这个值设置的比tickTime小。客户端连接到ZK时如果在这个最大时间内没有和ZK联系则标记为超时。所以上面的参数和这个参数组成了一个时间范围,也就是客户端连接ZK时如果在这个时间范围内没有成功连接则会标记为超时。如果客户端设置的时间范围不在这个服务器设置的范围内,则会被强制应用服务器设置的范围。 |
| autopurge.snapRetainCount | 自动清理日志,该参数设置保留多少个快照文件和对应的事务日志文件,默认为3,如果你设置的小于3则会被自动的调整为3. |
| autopurge.purgeInterval | 自动清理日志,该参数设置自动清理频率,上面的参数配套使用。客户端在和ZK服务器交互中服务器会产生很多日志,而且ZK会将内存中的数据作为快照保存起来,而且这些数据不会自动删除,那么磁盘空间就会被占用,可以设置这2个参数来自动清理,不过如果ZK服务器比较繁忙而且赶上删除日志任务就会影响性能,所以一般不设置这个自动清理,而是在ZK访问量少的时候通过Linux的定时任务来处理。0表示不开启自动清理功能。 |
| globalOutstandingLimit | ZK的最大请求堆积数,客户端请求比较多,为了防止客户端资源过度消耗,服务器必须限制同时处理的请求数量。 |
| preAllocSize | 用于配置ZK事务日志预先分配的空间,默认是64M |
| snapCount | 用于配置相邻两次快照之间的事物日志次数,默认是10万。也就是10万条事务之后做一次快照同时结转事务日志。 |
| clientPortAddres | 这个参数针对多网卡的ZK服务器,允许为每个IP地址指定不同的监听端口。 |
| fsync.warningthresholdms | 用于设置ZK服务器事物日志同步操作时消耗时间的报警阈值,如果实际消耗时长超过这个时间日志就会记录。 |
| electionAlg | 用于配置Leader选举算法,目前只有一种选举算法,所以不用配置。 |
| cnxTimeout | 用于Leader选举时各个服务器之间进行的TCP连接创建超时时间,默认为5. |
| forceSync | 这个参数用于配置ZK服务器是否在事物提交时是否强制写入磁盘(LINUX的延迟写入),默认是YES。 |
| jute.maxbuffer | 用于配置单个数据节点上最大数量,默认是1MB。通常不需要改动该参数,但是因为Zookeeper不适合存放太多数据所以有时候需要把值改小。 |
| skipACL | 是否跳过ACL检查,默认是no,也就是会对所有客户端连接进行acl检查。 |
| 集群配置 | |
| initLimit | 表示允许从服务器(相对于leader来说的客户端)连接到leader并完成数据同步的时间,它是以tickTime的倍数来表示的,也就是从服务器与主服务器完成初始化连接和数据同步是能够容忍多少个心跳时间,如果超过这个时间不能完成初始化连接的建立则表示连接失败。默认是10.如果你的数据量过大而且从服务器数量也多那么这个值可以设置大一点。 |
| syncLimit | 表示主服务器(leader)和从服务器(follower)之间发送心跳请求和应答的频率,如果在这个时间内从服务器不能与主服务器通信,则表示该从服务器失败。默认为5.如果集群环境网络不佳可以调整大一点。 |
| LeaderServes | 用于配置Leader服务器是否接受客户端的连接,是否允许Leader向客户端直接提供服务,默认是可以的。 |
| server.x= | 用于配置集群服务器列表 |
Zookeeper服务状态和配置等查询命令
| 命令 | 说明 |
| conf | 显示当前加载的配置文件信息 |
| cons | 列出当前连接到服务器的客户端会话信息,包括接收和发送的包数量、会话ID等 |
| dump | 列出集群中所有会话信息,以及未经处理的会话和每个会话创建临时节点 |
| envi | 列出当前环境信息,比如使用的JAVA版本、OS信息、主机名等 |
| reqs | 列出未经处理的请求 |
| ruok | 测试服务器是否正常,正常则放回“imok”,不正常则什么也不现实 |
| stat | 显示和性能以及客户端列表,包括Zookeeper版本、运行模式、最新ZXID,连接数,节点数量 |
| srvr | 和stat命令一样,只是不会列出客户端连接信息,而是仅列出服务器信息 |
| mntr | 用于输出比stat更加详细的服务器统计信息,请求延迟、内存数据库大小、集群同步状态等。 |
| wchs | 列出服务器watch的详细信息 |
| wchc | 通过session列出服务器的watch的详细信息,它的输出是一个与watch相关的会话列表 |
| wchp | 通过路径列出服务器watch的详细信息,它的输出是一个与session相关的路径 |

Zookeeper安装和运行的更多相关文章
- ZooKeeper安装与运行
ZooKeeper安装与运行 首先从官网下载ZooKeeper压缩包,然后解压下载得到的ZooKeeper压缩包,发现有“bin,conf,lib”等目录.“bin目录”中存放有运行脚本:“conf目 ...
- Zookeeper安装及运行
zookeeper的安装分为三种模式:单机模式.集群模式和伪集群模式. 单机模式 首先,从Apache官网下载一个Zookeeper稳定版本,本次教程采用的是zookeeper-3.4.9版本. ht ...
- Linux下zookeeper安装及运行
zookeeper下载地址:http://archive.apache.org/dist/zookeeper/ 安装 第一步:安装 jdk(此步省略,我给大家提供的镜像已经安装好JDK) 第二步:把 ...
- Redis安装,mongodb安装,hbase安装,cassandra安装,mysql安装,zookeeper安装,kafka安装,storm安装大数据软件安装部署百科全书
伟大的程序员版权所有,转载请注明:http://www.lenggirl.com/bigdata/server-sofeware-install.html 一.安装mongodb 官网下载包mongo ...
- ZooKeeper学习第二期--ZooKeeper安装配置
一.Zookeeper的搭建方式 Zookeeper安装方式有三种,单机模式和集群模式以及伪集群模式. ■ 单机模式:Zookeeper只运行在一台服务器上,适合测试环境:■ 伪集群模式:就是在一台物 ...
- zookeeper安装以及遇到的一些坑
最近项目中用到了storm,然后storm中用到了zookeeper,然后今天抽空整理一下zookeeper的安装使用,原来后期再慢慢学习. 本篇文档,操作部分是摘自其他博客,里边的问题分析是自己在实 ...
- 【Zookeeper系列】ZooKeeper安装配置(转)
原文链接:https://www.cnblogs.com/sunddenly/p/4018459.html 一.Zookeeper的搭建方式 Zookeeper安装方式有三种,单机模式和集群模式以及伪 ...
- zookeeper安装和使用(Windows环境)
zookeeper安装和使用(Windows环境) 2017年11月27日 10:36:07 董昊炘的博客 阅读数:14785 标签: zookeeperwindows zookeeper 一.简 ...
- 【转载】ZooKeeper学习第二期--ZooKeeper安装配置
原文地址(https://www.cnblogs.com/sunddenly/p/4018459.html) 一.Zookeeper的搭建方式 Zookeeper安装方式有三种,单机模式和集群模式以及 ...
随机推荐
- Sql语法树示例 select username, ismale from userinfo where age > 20 and level > 5 and 1 = 1
select username, ismale from userinfo where age > 20 and level > 5 and 1 = 1 --END-2019年9月5日17 ...
- LC 712. Minimum ASCII Delete Sum for Two Strings
Given two strings s1, s2, find the lowest ASCII sum of deleted characters to make two strings equal. ...
- MVC模式入门案例
import android.app.Activity; import android.os.Bundle; import android.view.View; import android.widg ...
- python 生成随机红包
假设红包金额为money,数量是num,并且红包金额money>=num*0.01 原理如下,从1~money*100的数的集合中,随机抽取num-1个数,然后对这些数进行排序,在排序后的集合前 ...
- CentOS6.8安装Oracle11g
===== 这中间还有很多细节问题该文档中并没有说明和指出: 1.如/tmp目录必须单独分出来,不然oracle在以后的使用中会逐渐变慢 2.官网说的512M内存即可,这里纠正下,如果只是测试安装那还 ...
- Implementing a Dynamic Vector (Array) in C(使用c实现动态数组Vector)
An array (vector) is a common-place data type, used to hold and describe a collection of elements. T ...
- <li>元素的排序
要点: getElementsByTagName("li")返回的是HTMLCollection对象,这个对象不同于Array对象,不能使用sort()方法进行排序~ 下面方法的要 ...
- Python:Base2(List和Tuple类型, 条件判断和循环,Dict和Set类型)
1.Python创建list: Python内置的一种数据类型是列表:list.list是一种有序的集合,可以随时添加和删除其中的元素. 比如,列出班里所有同学的名字,就可以用一个list表示: &g ...
- go语言20小时从入门到精通(六、工程管理)
在实际的开发工作中,直接调用编译器进行编译和链接的场景是少而又少,因为在工程中不会简单到只有一个源代码文件,且源文件之间会有相互的依赖关系.如果这样一个文件一个文件逐步编译,那不亚于一场灾难. Go语 ...
- Spring MVC 源码 分析
spring web 源码 @HandlesTypes(WebApplicationInitializer.class) public class SpringServletContainerInit ...