大型分布式爬虫准备 scrapy + request

而我避免这些问题的方式,控制台清除所有定时
var id = setInterval(function() {}, 0);
while (id--) clearInterval(id);
$(articleSelector).css('height', 'initial')
$(articleSelector).removeClass('lock')
$('#locker').css('display', 'none')
python 运行 js 脚本
pip install PyExecJS
eleme.js
function getParam(){
return 'hello world!'
}
xxx.py
import execjs
import os
os.environ["EXECJS_RUNTIME"] = "PhantomJS"
node = execjs.get()
file = 'eleme.js'
ctx = node.compile(open(file).read())
js_encode = 'getParam()'
params = ctx.eval(js_encode)
print(params)
python 包管理
virtualenv virtualwrapper pipenv pyenv --》 conda
步骤
1. pipenv shell
2. pip install scrapy
3. scrapy shell # 可以做 简单调试
3. scrapy startproject videospider # 生成 基本骨架
4. scrapy genspider jobbole www.jobbole.com
5. 取巧 构造一个 main.py 用来在 IDE 里调试
爬虫中 url 去重
set 去重 是 非常占用内存的
md5 信息摘要 算法 之后会省很多, 但是仍然不如 bitmap 方式
bitmap 会 很容易 造成 hash 冲突
bloom filter 这一种 可以通过 hash 函数 减少 hash 冲突
简而言之 言而简之 urls --> set(urls) --> set(md5(url) s) --> bitmap( xxx ) --> bloom filter( multi_hash_func ( xxx ))
下面这个教程要看评论再说。。。坑哭了
https://blog.csdn.net/chenvast/article/details/79103288
爬取 cnblog 文章 练手
# 使用 pipenv 管理环境
mkdir spiders
cd spiders
pipenv install
pip install scrapy -i http://pypi.douban.com/simple --trusted-host pypi.douban.com
# 利用 模板生成 项目基本样子 类似于 springboot
scrapy startproject ArticleSpider
# 爬取 二级域名下的 文章
cd xxx\ArticleSpider\ArticleSpider\spiders\
scrapy genspider cnblog news.cnblogs.com
# 修改 settings.py 中 的 爬虫配置 ROBOTSTXT_OBEY 为 False
ROBOTSTXT_OBEY = False
# 打开 编辑自动生成的 spider/cnblog.py
# -*- coding: utf-8 -*-
import scrapy
import re
from ArticleSpider.items import ArticleItem
from ArticleSpider.utils.utils import get_md5
from scrapy.http import Request
from urllib import parse
class CnblogSpider(scrapy.Spider):
name = 'cnblog'
allowed_domains = ['news.cnblogs.com']
start_urls = ['http://news.cnblogs.com/']
def parse(self, response):
news_selector_list = response.xpath('//div[@id="news_list"]/div[@class="news_block"]')
for news_selector in news_selector_list:
content = news_selector.xpath('div[@class="content"]')
anchor = content.xpath('h2/a')
article_url = anchor.xpath('@href').extract()[0]
article_title = anchor.xpath("text()").extract()[0]
article_front_image_url = content.xpath('div[@class="entry_summary"]/a/@href').extract()[0]
footer = content.xpath('div[@class="entry_footer"]')
article_author = footer.xpath('a/text()').extract()[0]
matched = re.match('评论\((\d+)\)', footer.xpath('span[@class="comment"]/a/text()').extract()[0])
article_comments = matched.group(1) if matched else 0
article_view = footer.xpath('span[@class="view"]').extract()[0]
article_tag = footer.xpath('span[@class="tag"]').extract()[0]
article_item = ArticleItem()
article_item['article_url'] = article_url
article_item['article_title'] = article_title
article_item['article_front_image_url'] = article_front_image_url
article_item['article_author'] = article_author
article_item['article_comments'] = article_comments
article_item['article_view'] = article_view
article_item['article_tag'] = article_tag
article_item['article_id'] = get_md5(article_url)
yield Request(url=parse.urljoin(response.url ,article_url),meta={"item":article_item}, callback=self.parse_detail)
pass
def parse_detail(self, response):
pass
# 有些时候 我们可以使用 Itemloader 来让我们的代码变得更友好
item_loadder = ItemLoader(item=ArticleItem(), response=response)
item_loadder.add_xpath(field_name="article_url", xpath="//div[@id='news_list']/div[@class='news_block']/div[@class='content']/h2/a/@href")
.
.
.
next_urls_selector = response.xpath('//*[@id="sideleft"]/div[5]/a[11]')
总结 对付反爬
访问 500 一般是 UA 没设置
cookie 携带
token
salt
sign
ctrl + shift + f 很好用 在查找 js 调用时候
cookies 池
ip 代理 池
pip3 install faker
https://cmder.net/
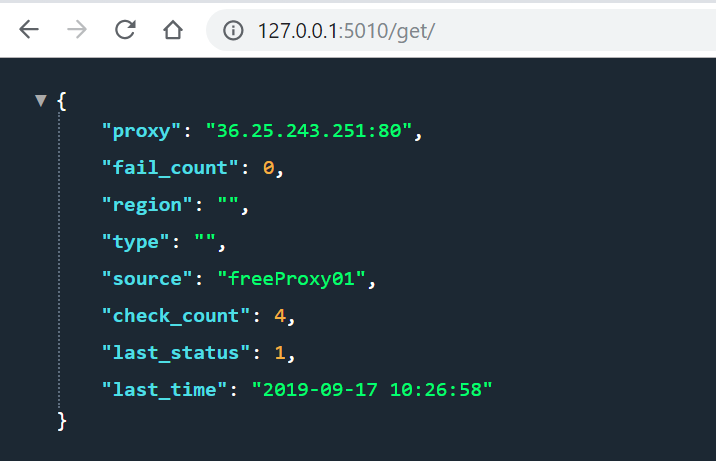
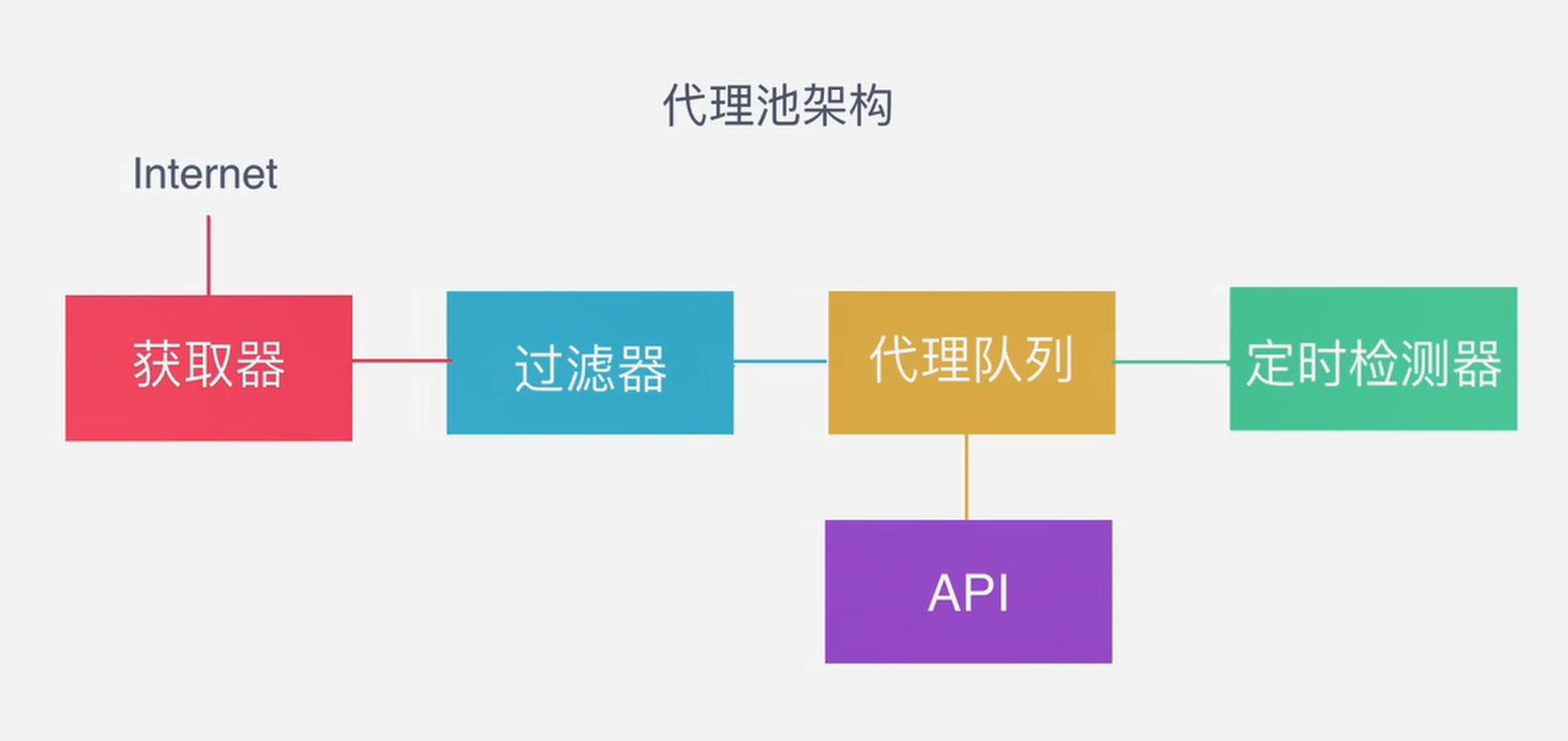
搭建自己的 ip 代理池
mongo db 安装使用
# 创建 ipproxy 数据库 如果没有就创建
use ipproxy;
### 插入数据
db.ipproxy.insert({"ip_port":"192.168.0.18:5678"})
# 删除 数据库
db.dropDatabase()
# 删除集合
db.collection.drop()
# 查询集合
db.ipproxy.find().pretty()
db.createCollection("mycol", { capped : true, autoIndexId : true, size :
6142800, max : 10000 } )
db.ipproxy.drop()
大型分布式爬虫准备 scrapy + request的更多相关文章
- scrapy 分布式爬虫- RedisSpider
爬去当当书籍信息 多台机器同时爬取,共用一个redis记录 scrapy_redis 带爬取的request对象储存在redis中,每台机器读取request对象并删除记录,经行爬取.实现分布式爬虫 ...
- scrapy分布式爬虫scrapy_redis二篇
=============================================================== Scrapy-Redis分布式爬虫框架 ================ ...
- scrapy分布式爬虫scrapy_redis一篇
分布式爬虫原理 首先我们来看一下scrapy的单机架构: 可以看到,scrapy单机模式,通过一个scrapy引擎通过一个调度器,将Requests队列中的request请求发给下载器,进行页 ...
- 第三百七十节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索结果分页
第三百七十节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索结果分页 逻辑处理函数 计算搜索耗时 在开始搜索前:start_time ...
- 第三百六十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索功能
第三百六十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索功能 Django实现搜索功能 1.在Django配置搜索结果页的路由映 ...
- 第三百六十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索的自动补全功能
第三百六十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—用Django实现搜索的自动补全功能 elasticsearch(搜索引擎)提供了自动补全接口 官方说明:https://www.e ...
- 第三百五十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—将bloomfilter(布隆过滤器)集成到scrapy-redis中
第三百五十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—将bloomfilter(布隆过滤器)集成到scrapy-redis中,判断URL是否重复 布隆过滤器(Bloom Filter)详 ...
- 第三百五十七节,Python分布式爬虫打造搜索引擎Scrapy精讲—利用开源的scrapy-redis编写分布式爬虫代码
第三百五十七节,Python分布式爬虫打造搜索引擎Scrapy精讲—利用开源的scrapy-redis编写分布式爬虫代码 scrapy-redis是一个可以scrapy结合redis搭建分布式爬虫的开 ...
- 第三百五十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy信号详解
第三百五十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy信号详解 信号一般使用信号分发器dispatcher.connect(),来设置信号,和信号触发函数,当捕获到信号时执行 ...
随机推荐
- DP&图论 DAY 3 上午
DP&图论 DAY 3 上午 状态压缩dp >状态压缩dp ◦状态压缩是设计dp状态的一种方式.◦当普通的dp状态维数很多(或者说维数与输入数据有关),但每一维总量很少是,可以将多维 ...
- MySQL 插件之 连接控制插件(Connection-Control)
目录 插件介绍 插件安装 插件配置 插件介绍 MySQL 5.7.17 以后提供了Connection-Control插件用来控制客户端在登录操作连续失败一定次数后的响应的延迟.该插件可有效的防止客户 ...
- [idea]创建一个控制台程序
新建项目时,选择JBoss即可.
- GB 和 GiB 的区别
GB 和 GiB 的区别 Gibibyte (GiB) is one of the standard units used in the field of data processing and da ...
- 有效使用Django的QuerySets
对象关系映射 (ORM) 使得与SQL数据库交互更为简单,不过也被认为效率不高,比原始的SQL要慢. 要有效的使用ORM,意味着需要多少要明白它是如何查询数据库的.本文我将重点介绍如何有效使用 Dja ...
- SAS数据挖掘实战篇【四】
SAS数据挖掘实战篇[四] 今天主要是介绍一下SAS的聚类案例,希望大家都动手做一遍,很多问题只有在亲自动手的过程中才会有发现有收获有心得. 1 聚类分析介绍 1.1 基本概念 聚类就是一种寻找数据之 ...
- 关于Yii的ocracle链接问题
1. http://www.yiiframework.com/extension/oci8pdo/ 2.下载extension包,根据配置可解决.
- 外国前端收费模板wrapbootstrap
https://wrapbootstrap.com/ 新闻模板 http://wrapbootstrap.com/preview/WB037B6R2
- Android开发 调试环境
我们这里有3种调试方法,Unity Remote,Android Studio和第三方模拟器 准备工作 (1)Android Studio:安装Google USB Driver (2)手机安装Uni ...
- 系统 --- Linux系统环境搭建
Linux命令介绍 软硬链接 作用:建立连接文件,linux下的连接文件类似于windows下的快捷方式 分类: 软链接:软链接不占用磁盘空间,源文件删除则软链接失效 硬链接:硬链接只能链接不同文件, ...