浅析Scrapy框架运行的基本流程
本篇博客将从Twisted的下载任务基本流程开始介绍,然后再一步步过渡到Scrapy框架的基本运行流程,其中还会需要我们自定义一个Low版的Scrapy框架。但内容不会涉及太多具体细节,而且需要注意的是示例代码的运行过程不会Scrapy一模一样,但不影响你对整体的把握。希望可以帮助那些刚入门爬虫或者刚学习Scrapy的同学理清思路,做到对Scrapy的运行流程有个大概把握,这样以后在继续深入Scrapy框架或者扩展其应用时更加得心应手。(PS:大佬可忽略:))
一、Twisted的下载任务基本过程
首先需要我们导入三个基本的模块
from twisted.internet import reactor
from twisted.web.client import getPage
from twisted.internet import defer
reactor的作用是开启事件循环,可以简单理解为select或者epoll,循环监听socket对象,一旦连接成功或者响应完成,就移除掉对应的socket,不再监听。(终止条件,所有的socket都已移除)getPage的作用是自动帮我们创建socket对象,模拟浏览器给服务器发送请求,放到reactor里面,一旦下载到需要的数据,socket将发生变化,就可以被reactor监听到。(如果下载完成,自动从事件循环中移除)defer里面的defer.Deferred()的作用是创建一个特殊的socket对象,它不会发送请求,如果放在事件循环里面,将永远不会被移除掉,需要我们自己手动移除,作用就是使事件循环一直监听,不会停止。(不会发请求,手动移除)
1、利用getPage创建socket
def response(content):
print(content) def task():
url = "http://www.baidu.com"
d = getPage(url) # 创建socket对象,获取返回的对象d,它其实也是一个Deferred对象
d.addCallback(response) # 当页面下载完成,自动执行函数response,来处理返回数据
上面代码的内部执行过程就是自动创建socket对象,并且发送请求,如果请求成功拿到返回的值,自动调用函数response来处理返回的内容。
但以上内容你可以理解只是创建了socket,并且给了运行结束后应该执行的函数。但还没有加到事件循环。
2.将socket添加到事件循环中
def response(content):
print(content) @defer.inlineCallbacks # 添加事件循环
def task():
url = "http://www.baidu.com"
d = getPage(url)
d.addCallback(response)
yield d
3、开始事件循环
def response(content):
print(content) @defer.inlineCallbacks
def task():
url = "http://www.baidu.com"
d = getPage(url.encode('utf-8'))
d.addCallback(response)
yield d task() # 执行函数
reactor.run() # 开启事件循环。不先执行函数的话,在内部循环中该函数是不会执行的。
但是上面的代码运行后,无法自动终止,需要有一个东西来监听着,当我们发的所有url回来时终止事件循环
4、开始事件循环(自动结束)
def response(content):
print(content) @defer.inlineCallbacks
def task():
url = "http://www.baidu.com"
d = getPage(url.encode('utf-8'))
d.addCallback(response)
yield d d = task()
dd = defer.DeferredList([d,])
dd.addBoth(lambda _:reactor.stop()) # 监听d是否完成或者失败,如果是,调用回调函数,终止事件循环 reactor.run()
上面的代码此时已经实现了基本的功能,但我们还需要再加最后一个功能,就是并发。让函数task可以一次性发送多个请求,并且在所有请求都回来后再终止事件循环。这时就要用到defer.Deferred
5、并发操作
_closewait = None
def response(content):
print(content)
@defer.inlineCallbacks
def task():
"""
每个爬虫的开始:stats_request
:return:
"""
url = "http://www.baidu.com"
d1 = getPage(url.encode('utf-8'))
d1.addCallback(response)
url = "http://www.cnblogs.com"
d2 = getPage(url.encode('utf-8'))
d2.addCallback(response)
url = "http://www.bing.com"
d3 = getPage(url.encode('utf-8'))
d3.addCallback(response)
global _closewait
_close = defer.Deferred()
yield _closewait
spider1 = task()
dd = defer.DeferredList([spider1,])
dd.addBoth(lambda _:reactor.stop())
reactor.run()
调用defer.Deferred,使事件循环一直运行,直到发出去的每个请求都返回。但是上面的代码,在请求都回来之后,事件循环还是不会停止,需要我们手动关闭defer.Deferred。
6、手动关闭defer.Deferred
_closewait = None
count = 0
def response(content): print(content)
global count
count += 1
if count == 3: # 当等于3时,说明发出去的url的响应都拿到了
_closewait.callback(None) @defer.inlineCallbacks
def task():
"""
每个爬虫的开始:stats_request
:return:
"""
url = "http://www.baidu.com"
d1 = getPage(url.encode('utf-8'))
d1.addCallback(response) url = "http://www.cnblogs.com"
d2 = getPage(url.encode('utf-8'))
d2.addCallback(response) url = "http://www.bing.com"
d3 = getPage(url.encode('utf-8'))
d3.addCallback(response) global _closewait
_close = defer.Deferred()
yield _closewait spider = task()
dd = defer.DeferredList([spider, ])
dd.addBoth(lambda _:reactor.stop()) reactor.run()
总结上面的流程:
(1)利用getPage创建socket
(2)将socket添加到事件循环中
(3)开始事件循环 (内部发送请求,并接受响应;当所有的socekt请求完成后,终止事件循环)
二、low版Scrapy框架
在理解了上面的内容之后,那么接下来的部分将会变得轻松,基本的思想和上面差不多。
1、首先我们创建一个爬虫ChoutiSpider,如下代码所示。
有些人可能不知道start_requests是什么,其实这个跟我们用Scrapy创建的一样,这个函数在我们继承的scrapy.Spider里面,作用就是取start_url列表里面的url,并把url和规定好的回调函数parse传给Request类处理。需要注意的是这里的Request我们只是简单的接收来自start_requests传来的值,不做真正的处理,例如发送url请求什么的
from twisted.internet import defer
from twisted.web.client import getPage
from twisted.internet import reactor class Request(object): def __init__(self,url,callback):
self.url = url
self.callback = callback class ChoutiSpider(object):
name = 'chouti' def start_requests(self):
start_url = ['http://www.baidu.com','http://www.bing.com',]
for url in start_url:
yield Request(url,self.parse) def parse(self,response):
print(response) #response是下载的页面 yield Request('http://www.cnblogs.com',callback=self.parse)
2、创建引擎Engine,用来接收需要执行的spider对象
from twisted.internet import defer
from twisted.web.client import getPage
from twisted.internet import reactor class Request(object): def __init__(self,url,callback):
self.url = url
self.callback = callback class ChoutiSpider(object):
name = 'chouti' def start_requests(self):
start_url = ['http://www.baidu.com','http://www.bing.com',]
for url in start_url:
yield Request(url,self.parse) def parse(self,response):
print(response) #response是下载的页面 yield Request('http://www.cnblogs.com',callback=self.parse) import queue
Q = queue.Queue() # 调度器 class Engine(object): def __init__(self):
self._closewait = None @defer.inlineCallbacks
def crawl(self,spider): start_requests = iter(spider.start_requests()) # 把生成器Request对象转换为迭代器
while True:
try:
request = next(start_requests) # 把Request对象放到调度器里面
Q.put(request)
except StopIteration as e:
break self._closewait = defer.Deferred()
yield self._closewait
3、更加具体的实现过程
让引擎实现把Request对象加到调度器Q(队列)里面,然后再从调度器取值进行发送、接收和数据处理。
from twisted.internet import defer
from twisted.web.client import getPage
from twisted.internet import reactor class Request(object): def __init__(self,url,callback):
self.url = url
self.callback = callback class ChoutiSpider(object):
name = 'chouti' def start_requests(self):
start_url = ['http://www.baidu.com','http://www.bing.com',]
for url in start_url:
yield Request(url,self.parse) def parse(self,response):
print(response) #response是下载的页面 yield Request('http://www.cnblogs.com',callback=self.parse) import queue
Q = queue.Queue() class Engine(object): def __init__(self):
self._closewait = None
self.max = 5 # 最大并发数
self.crawlling = [] # 正在爬取的爬虫个数 def get_response_callback(self,content,request):
# content就是返回的response, request就是一开始返回的迭代对象
self.crawlling.remove(request)
result = request.callback(content) # 执行parse方法
import types
if isinstance(result,types.GeneratorType): # 判断返回值是否是yield,如
for req in result: # 果是则加入到队列中
Q.put(req) def _next_request(self):
"""
去调度器中取request对象,并发送请求
最大并发数限制
:return:
"""
# 什么时候终止
if Q.qsize() == 0 and len(self.crawlling) == 0:
self._closewait.callback(None) # 结束defer.Deferred
return if len(self.crawlling) >= self.max:
return
while len(self.crawlling) < self.max:
try:
req = Q.get(block=False) # 设置为非堵塞
self.crawlling.append(req)
d = getPage(req.url.encode('utf-8')) # 发送请求
# 页面下载完成,执行get_response_callback,并且将一开始的迭代对象req作为参数传过去
d.addCallback(self.get_response_callback,req)
# 未达到最大并发数,可以再去调度器中获取Request
d.addCallback(lambda _:reactor.callLater(0, self._next_request)) # callLater表示多久后调用 except Exception as e:
print(e)
return @defer.inlineCallbacks
def crawl(self,spider):
# 将初始Request对象添加到调度器
start_requests = iter(spider.start_requests())
while True:
try:
request = next(start_requests)
Q.put(request)
except StopIteration as e:
break # 去调度器中取request,并发送请求
# self._next_request()
reactor.callLater(0, self._next_request) self._close = defer.Deferred()
yield self._closewait spider = ChoutiSpider()
_active = set()
engine = Engine() d = engine.crawl(spider)
_active.add(d)
dd = defer.DeferredList(_active)
dd.addBoth(lambda _:reactor.stop()) reactor.run()
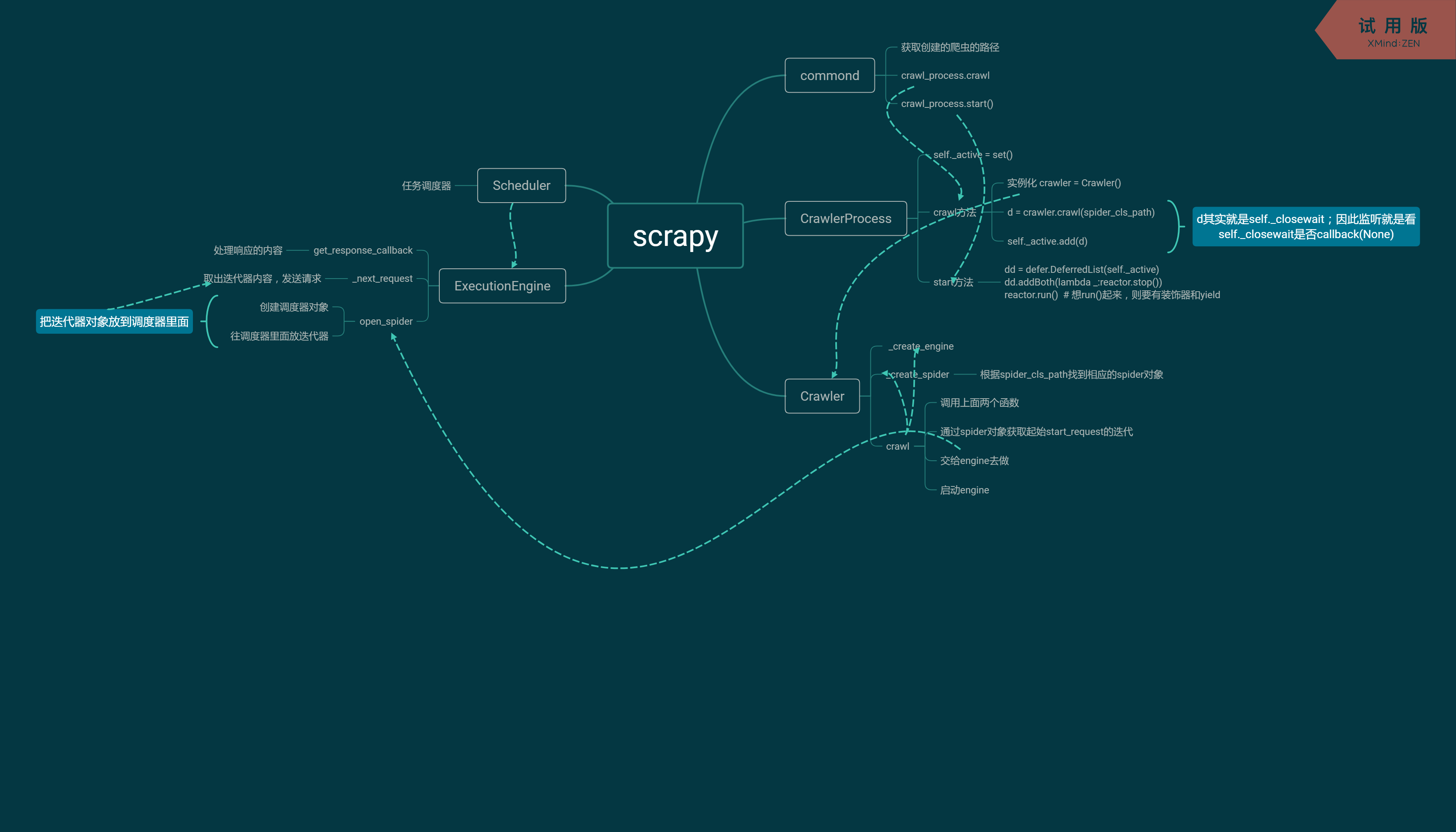
上面其实就是Scrapy框架的基本实现过程,不过要想更进一步的了解,就需要模仿Scrapy的源码,把各个函数的功能独立封装起来,如下。
三、封装
from twisted.internet import reactor
from twisted.web.client import getPage
from twisted.internet import defer
from queue import Queue class Request(object):
"""
用于封装用户请求相关信息
"""
def __init__(self,url,callback):
self.url = url
self.callback = callback class HttpResponse(object): # 对返回的content和request做进一步封装,集合到response里面。然后通过回调函数parse调用response.xxx可以调用不同的功能。具体过程略 def __init__(self,content,request):
self.content = content
self.request = request class Scheduler(object):
"""
任务调度器
"""
def __init__(self):
self.q = Queue() def open(self):
pass def next_request(self): # 取调度器里面的值并发送
try:
req = self.q.get(block=False)
except Exception as e:
req = None
return req def enqueue_request(self,req):
self.q.put(req) def size(self):
return self.q.qsize() class ExecutionEngine(object):
"""
引擎:所有调度
"""
def __init__(self):
self._closewait = None
self.scheduler = None
self.max = 5
self.crawlling = [] def get_response_callback(self,content,request):
self.crawlling.remove(request)
response = HttpResponse(content,request)
result = request.callback(response) # 执行request里面的回调函数(parse)
import types
if isinstance(result,types.GeneratorType):
for req in result:
self.scheduler.enqueue_request(req) def _next_request(self):
if self.scheduler.size() == 0 and len(self.crawlling) == 0:
self._closewait.callback(None)
return while len(self.crawlling) < self.max:
req = self.scheduler.next_request()
if not req:
return
self.crawlling.append(req)
d = getPage(req.url.encode('utf-8'))
d.addCallback(self.get_response_callback,req)
d.addCallback(lambda _:reactor.callLater(0,self._next_request)) @defer.inlineCallbacks
def open_spider(self,start_requests):
self.scheduler = Scheduler() # 创建调度器对象 while True:
try:
req = next(start_requests)
except StopIteration as e:
break
self.scheduler.enqueue_request(req) # 放进调度器里面
yield self.scheduler.open() # 使用那个装饰器后一定要有yield,因此传个 None 相当于yield None
reactor.callLater(0,self._next_request) @defer.inlineCallbacks
def start(self):
self._closewait = defer.Deferred()
yield self._closewait class Crawler(object):
"""
用户封装调度器以及引擎的...
"""
def _create_engine(self): # 创建引擎对象
return ExecutionEngine() def _create_spider(self,spider_cls_path):
""" :param spider_cls_path: spider.chouti.ChoutiSpider
:return:
"""
module_path,cls_name = spider_cls_path.rsplit('.',maxsplit=1)
import importlib
m = importlib.import_module(module_path)
cls = getattr(m,cls_name)
return cls() @defer.inlineCallbacks
def crawl(self,spider_cls_path):
engine = self._create_engine() # 需要把任务交给引擎去做
spider = self._create_spider(spider_cls_path) # 通过路径获取spider,创建对象
start_requests = iter(spider.start_requests())
yield engine.open_spider(start_requests) # 把迭代器往调度器里面放
yield engine.start() # 相当于self._closewait方法 class CrawlerProcess(object):
"""
开启事件循环
"""
def __init__(self):
self._active = set() def crawl(self,spider_cls_path): # 每个爬虫过来只负责创建一个crawler对象
"""
:param spider_cls_path:
:return:
"""
crawler = Crawler()
d = crawler.crawl(spider_cls_path)
self._active.add(d) def start(self): # 开启事件循环
dd = defer.DeferredList(self._active)
dd.addBoth(lambda _:reactor.stop()) reactor.run() # 想run()起来,则要有装饰器和yield class Commond(object): def run(self):
crawl_process = CrawlerProcess()
spider_cls_path_list = ['spider.chouti.ChoutiSpider','spider.cnblogs.CnblogsSpider',]
for spider_cls_path in spider_cls_path_list:
crawl_process.crawl(spider_cls_path) # 创建多个defer对象,也就是把d添加到_active里面
crawl_process.start() # 统一调用一次,相当于reactor.run() if __name__ == '__main__':
cmd = Commond()
cmd.run()
其实上面的代码就是从下往上依次执行,每个类之间各个完成不同的功能。
配合下面的思维导图,希望可以帮助理解。
浅析Scrapy框架运行的基本流程的更多相关文章
- scrapy框架学习
一.初窥Scrapy Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中. 其最初是为了 页面抓取 (更确切来说, 网 ...
- 玩转Windows服务系列——服务运行、停止流程浅析
通过研究Windows服务注册卸载的原理,感觉它并没有什么特别复杂的东西,Windows服务正在一步步退去它那神秘的面纱,至于是不是美女,大家可要睁大眼睛看清楚了. 接下来研究一下Windows服务的 ...
- 玩转Windows服务系列——服务运行、停止流程浅析
原文:玩转Windows服务系列——服务运行.停止流程浅析 通过研究Windows服务注册卸载的原理,感觉它并没有什么特别复杂的东西,Windows服务正在一步步退去它那神秘的面纱,至于是不是美女,大 ...
- Scrapy框架的执行流程解析
这里主要介绍七个大类Command->CrawlerProcess->Crawler->ExecutionEngine->sceduler另外还有两个类:Request和Htt ...
- OpenCart框架运行流程介绍
框架运行流程介绍 这样的一个get请求http://hostname/index.php?route=common/home 发生了什么? 1. 开始执行入口文件index.php. 2. requi ...
- Scrapy 框架流程详解
框架流程图 Scrapy 使用了 Twisted 异步非阻塞网络库来处理网络通讯,整体架构大致如下(绿线是数据流向): 简单叙述一下每层图的含义吧: Spiders(爬虫):它负责处理所有Respon ...
- Python爬虫:scrapy 的运行流程和各模块的作用
scrapy的运行流程 爬虫 -> 起始URL封装Request -> 爬虫中间件 -> 引擎 -> 调度器(Scheduler): 缓存请求, 请求去重 调度器 -> ...
- python的scrapy框架的使用 和xpath的使用 && scrapy中request和response的函数参数 && parse()函数运行机制
这篇博客主要是讲一下scrapy框架的使用,对于糗事百科爬取数据并未去专门处理 最后爬取的数据保存为json格式 一.先说一下pyharm怎么去看一些函数在源码中的代码实现 按着ctrl然后点击函数就 ...
- Python爬虫从入门到放弃(十二)之 Scrapy框架的架构和原理
这一篇文章主要是为了对scrapy框架的工作流程以及各个组件功能的介绍 Scrapy目前已经可以很好的在python3上运行Scrapy使用了Twisted作为框架,Twisted有些特殊的地方是它是 ...
随机推荐
- redis的key设置每天凌晨过期的思路
设置key凌晨过期的思路 设置key的值的时候,计算下当前时间到第二天凌晨的时间差,设置key的过期时间. 利用定时任务,每天凌晨将需要过期的key删除. 应用场景 按天为维度,限制用户对资源的访问次 ...
- C++中的const的简单用法
一.符号常量的声明 常量声明的语句的形式: const + 数据类型说明符 + 常量名 = 常量值 数据类型说明符 + const + 常量名 = 常量值 注意: 符号常量 ...
- WUSTOJ 1341: Lake and Island(Java)
题目链接:1341: Lake and Island Description 北园孩子的专属福利来啦~学校从北区宿舍到湖心岛修建了一条通道让北园的同学们可以上去一(kuang)同(xiu)玩(en)耍 ...
- 『Python基础』第8节:格式化输出
现在有一个需求, 询问用户的姓名, 年龄, 工作, 爱好, 然后打印成以下格式 ************ info of Conan ************ name: Conan age: 23 ...
- 【SCALA】3、模拟电路
Simulation package demo17 abstract class Simulation { type Action = () => Unit case class WorkIte ...
- AX 2009中现有量画面修改
前端时间开发一个东西,需要在现有量画面增加一个字段 但是发现这个display方法写在任何数据源下面都不行,数据取的不对. 因为InventSum这个表只有所有维度都出来时才会有对应关联的invent ...
- DataSource配置
一.JDBC Jar依赖: <dependency> <groupId>org.springframework.boot</groupId> <artifac ...
- c#使用GDI进行简单的绘图
https://www.2cto.com/database/201805/749421.html https://zhidao.baidu.com/question/107832895.html pr ...
- entity-framework-core – 实体框架核心RC2表名称复数
参考地址:https://docs.microsoft.com/zh-cn/ef/core/modeling/relational/tables http://www.voidcn.com/artic ...
- iview的table组件中加入超链接组件,可编辑组件,选择组件,日期组件
这篇文章主要介绍了iview的table组件中使用选择框,日期,可编辑表格,超链接等组件. 1.select选择组件 // tableColumn数组响应对象需要传入一个固定的option数组,如果该 ...