【SQL server】SQL server基础(二)
一、一些重要的SQL命令
- SELECT - 从数据库中提取数据
- UPDATE - 更新数据库中的数据
- DELETE - 从数据库中删除数据
- INSERT INTO - 向数据库中插入新数据
- CREATE DATABASE - 创建新数据库
- ALTER DATABASE - 修改数据库
- CREATE TABLE - 创建新表
- ALTER TABLE - 变更(改变)数据库表
- DROP TABLE - 删除表
- CREATE INDEX - 创建索引(搜索键)
- DROP INDEX - 删除索引
二、SQL基础
+----+--------------+---------------------------+
| id | name | age | country |
+----+--------------+---------------------------+
| 1 | KAY | 22 | CN |
| 2 | SKYE | 15 | CN |
| 3 | KATE | 34 | USA |
| 4 | LORY | 34 | USA |
| 5 | JACK | 66 | EN |
+----+--------------+---------------------------+
1、INSERT INTO实例
1)无需指定插入数据列名:
INSERT INTO table_name
VALUES (value1,value2,value3,...);
INSERT INTO DBO.TEST
VALUES('','casiy',20,'EN') --当没有列名时,values数要与colums数一致(即每个都要赋值)
2)需要指定插入数据列名:插入指定列数据
INSERT INTO table_name (column1,column2,column3,...)
VALUES (value1,value2,value3,...);
INSERT INTO DBO.TEST(ID,NAME,AGE)
VALUES('','LUCK',20)
结果
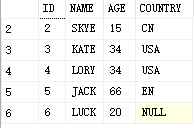
2.UPDATE
UPDATE table_name
SET column1=value1,column2=value2,...
WHERE some_column=some_value;
update [dbo].[Test]
set NAME = 'BEN', AGE = 25
where ID = ''
*注:当没有where时表中所有数据的name都为ben,age都为25
3.DELETE
DELETE FROM table_name
WHERE some_column=some_value;
DELETE FROM [dbo].[Test]
WHERE ID=''
*注当要删除表中内容时可以用 DELETE FROM table_name;或DELETE * FROM table_name;
三、高级
1.SQL SELECT TOP
1)SQL:
SELECT TOP number|percent column_name(s)
FROM table_name;
SELECT TOP 30 PERCENT * FROM [dbo].[Test] --选取前30%的数据
SELECT TOP 3 * FROM [dbo].[Test] --选取前3的数据
2)mySQL
SELECT column_name(s)
FROM table_name
LIMIT number;
SELECT *
FROM [dbo].[Test]
LIMIT 3 --选取前3的数据
2.通配符
% 替代一个或多个字符
_ 仅替代一个字符
[charlist] 字符列中的任何单一字符
[^charlist]或者[!charlist] 不在字符列中的任何单一字符
其中搭配以上通配符可以让LIKE命令实现多种技巧:
1)LIKE'Mc%' 将搜索以字母 Mc 开头的所有字符串(如 McBadden)。
2)LIKE'%inger' 将搜索以字母 inger 结尾的所有字符串(如 Ringer、Stringer)。
3)LIKE'%en%' 将搜索在任何位置包含字母 en 的所有字符串(如 Bennet、Green、McBadden)。
4)LIKE'_heryl' 将搜索以字母 heryl 结尾的所有六个字母的名称(如 Cheryl、Sheryl)。
5)LIKE'[CK]ars[eo]n' 将搜索下列字符串:Carsen、Karsen、Carson 和 Karson(如 Carson)。
6)LIKE'[M-Z]inger' 将搜索以字符串 inger 结尾、以从 M 到 Z 的任何单个字母开头的所有名称(如 Ringer)。
7)LIKE'M[^c]%' 将搜索以字母 M 开头,并且第二个字母不是 c 的所有名称(如MacFeather)。
3.BETWWEN
SELECT column_name(s)
FROM table_name
WHERE column_name BETWEEN value1 AND value2;
*带有文本值得BETWEEN操作实例
SELECT *
FROM [dbo].[Test]
WHERE NAME BETWEEN 'A' AND 'L'; --选取name以A和L之间的字母开始的人员数据
4.sql别名
1)列的别名
SELECT column_name AS alias_name
FROM table_name;
SELECT ID as I,NAME as n,CONCAT(AGE,COUNTRY)as info --CONCAT()as 将age,country和为一列名为ifo
FROM [dbo].[Test]
2)表的命名
SELECT column_name(s)
FROM table_name AS alias_name;
*在下面的情况下,使用别名很有用:
- 在查询中涉及超过一个表
- 在查询中使用了函数
- 列名称很长或者可读性差
- 需要把两个列或者多个列结合在一起
for exple:
SELECT w.name, w.url, a.count, a.date
FROM Websites AS w, access_log AS a
WHERE a.site_id=w.id and w.name="菜鸟教程";
5.SQL连接(JOIN)
+----+--------------+---------------------------+
|s_id | chinese | english |
+----+--------------+---------------------------+
| 1 | 95 | 78 |
| 2 | 80 | 66 |
| 3 | 66 | 59 |
| 5 | 49 | 91 |
| 6 | 90 | 92 |
| 5 | 68 | NULL |
+----+--------------+---------------------------+
1)INNER JOIN(JOIN)
SQL JOIN 子句用于把来自两个或多个表的行结合起来,基于这些表之间的共同字段。最常见的 JOIN 类型:SQL INNER JOIN(简单的 JOIN)。
SQL INNER JOIN 从多个表中返回满足 JOIN 条件的所有行。
SELECT column_name(s)
FROM table1
INNER JOIN table2
ON table1.column_name=table2.column_name;
*TEST 表中的 "id" 列指向 "marks" 表中的字段 "s_id"。上面这两个表是通过 "site_id" 列联系起来的。
然后,如果我们运行下面的 SQL 语句(包含 INNER JOIN):
SELECT t.ID,t.NAME,m.english,m.chinese
FROM [dbo].[Test] as t
INNER JOIN [dbo].[marks] as m
ON t.ID=m.s_id
*INNER JOIN 关键字在表中存在至少一个匹配时返回行。如果 "TEST" 表中的行在 "marks" 中没有匹配,则不会列出这些行。

2)LEFT JOIN
*LEFT JOIN 关键字从左表(table1)返回所有的行,即使右表(table2)中没有匹配。如果右表中没有匹配,则结果为 NULL
SELECT column_name(s)
FROM table1
LEFT JOIN table2
ON table1.column_name=table2.column_name;
SELECT t.ID,t.NAME,m.english,m.chinese
FROM [dbo].[Test] as t
LEFT JOIN [dbo].[marks] as m
ON t.ID=m.s_id
结果:
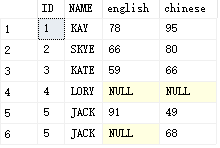
3)RIGHT JOIN
*RIGHT JOIN 关键字从右表(table2)返回所有的行,即使左表(table1)中没有匹配。如果左表中没有匹配,则结果为 NULL。
ELECT column_name(s)
FROM table1
RIGHT JOIN table2
ON table1.column_name=table2.column_name;
SELECT t.ID,t.NAME,m.english,m.chinese
FROM [dbo].[Test] as t
RIGHT JOIN [dbo].[marks] as m
ON t.ID=m.s_id
结果:

4)FULL OUTER JOIN
*FULL OUTER JOIN 关键字只要左表(table1)和右表(table2)其中一个表中存在匹配,则返回行.,FULL OUTER JOIN 关键字结合了 LEFT JOIN 和 RIGHT JOIN 的结果。
SELECT column_name(s)
FROM table1
FULL OUTER JOIN table2
ON table1.column_name=table2.column_name;
6.UNION
+----+--------------+---------------------------+
| id | name | age | country |
+----+--------------+---------------------------+
| 1 | xiaohong | 22 | CN |
| 2 | xiaoming | 15 | CN |
| 3 | xiaobai | 34 | CN |
| 4 | xiaohei | 34 | CN |
| 5 | xiaoliu | 66 | CN |
+----+--------------+---------------------------+
*UNION 操作符用于合并两个或多个 SELECT 语句的结果集。
*请注意,UNION 内部的每个 SELECT 语句必须拥有相同数量的列。列也必须拥有相似的数据类型。同时,每个 SELECT 语句中的列的顺序必须相同。
SELECT column_name(s) FROM table1
UNION
SELECT column_name(s) FROM table2;
*默认地,UNION 操作符选取不同的值。如果允许重复的值,请使用 UNION ALL。
SELECT t.NAME,t.COUNTRY
FROM [dbo].[Test] as t
WHERE t.ID>2
UNION ALL
SELECT m.NAME,m.COUNTRY
FROM [dbo].[Test2] AS m
WHERE m.ID>2
结果:
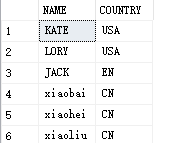
7.SELECT INTO
1)SELECT INTO
SELECT INTO 语句从一个表复制数据,然后把数据插入到另一个新表中。
SELECT column_name(s)
INTO newtable [IN externaldb]
FROM table1;
SELECT t.ID,t.NAME,m.english,m.chinese INTO Test3
FROM [dbo].[Test] as t
LEFT JOIN [dbo].[marks] as m
ON t.ID=m.s_id
2)INSERT INTO ...SELECT
INSERT INTO SELECT 语句从一个表复制数据,然后把数据插入到一个已存在的表中。
INSERT INTO table2(column_name(s))
SELECT column_name(s)
FROM table1;
INSERT INTO [dbo].[Test2](ID,NAME) --被插入的表
SELECT t.ID,t.NAME from [dbo].[Test] as t
WHERE ID<3
结果:

*两者区别:前者产生一个新表,后者是在旧表中插入
8.CREATE DATABASE
CREATE DATABASE dbname;
9.CREATE TABLE
CREATE TABLE table_name
(
column_name1 data_type(size),
column_name2 data_type(size),
column_name3 data_type(size),
....
);
column_name 参数规定表中列的名称。data_type 参数规定列的数据类型(例如 varchar、integer、decimal、date 等等)。size 参数规定表中列的最大长度。
10.create index
可以在表中创建索引,以便更加快速高效地查询数据。用户无法看到索引,它们只能被用来加速搜索/查询。
1)允许使用重复的值
CREATE INDEX index_name
ON table_name(cloumn_name1,cloumn_name2)
2)在表上创建一个唯一的索引。不允许使用重复的值:唯一的索引意味着两个行不能拥有相同的索引值
CREATE UNIQUE INDEX index_name
ON table_name(cloumn_name1,cloumn_name2)
11.SQL 撤销索引、撤销表以及撤销数据库
1)撤销索引
sql:
DROP INDEX table_name.index_name
mysql:
ALTER TABLE tabel_name
DROP INDEX index_name
2)撤销表
DROP TABELE table_name
3)撤销数据库
DROP DATEBASE database_name
4)TRUNCATE TABLE 仅需要删除表内的数据,但并不删除表本身
TRUNCATE TABLE table_name
12.ALTER
ALTER TABLE table_name
ADD COLUMN colunm_name
DROP COLUMN colunm_name
ALTER COLUMN colunm_name datatype
13.AUTO-INCREMNET
1)sql:
Auto-increment 会在新记录插入表中时生成一个唯一的数字。
CREATE TABLE Persons
(
ID int IDENTITY(1,1) PRIMARY KEY,
LastName varchar(255) NOT NULL,
FirstName varchar(255),
Address varchar(255),
City varchar(255),
PRIMARY KEY(ID)
)
MS SQL Server 使用 IDENTITY 关键字来执行 auto-increment 任务。在上面的实例中,IDENTITY 的开始值是 1,每条新记录递增 1。
提示:要规定 "ID" 列以 10 起始且递增 5,请把 identity 改为 IDENTITY(10,5)。
要在 "Persons" 表中插入新记录,我们不必为 "ID" 列规定值(会自动添加一个唯一的值
2)mysql:
CREATE TABLE Persons
(
ID int NOT NULL AUTO_INCREMENT,
LastName varchar(255) NOT NULL,
FirstName varchar(255),
Address varchar(255),
City varchar(255),
PRIMARY KEY (ID)
)
MySQL 使用 AUTO_INCREMENT 关键字来执行 auto-increment 任务。默认地,AUTO_INCREMENT 的开始值是 1,每条新记录递增 1。
要让 AUTO_INCREMENT 序列以其他的值起始,请使用下面的 SQL 语法:ALTER TABLE Persons AUTO_INCREMENT=100
14.视图
视图包含行和列,就像一个真实的表。视图中的字段就是来自一个或多个数据库中的真实的表中的字段。
可以向视图添加 SQL 函数、WHERE 以及 JOIN 语句,也可以呈现数据,就像这些数据来自于某个单一的表一样
1)创建视图
CREATE VIEW view_name AS
SELECT column_name(s)
FROM table_name
WHERE condition
2)修改视图
ALTER VIEW view_name AS
SELECT column_name(s)
FROM table_name
WHERE condition
3)撤销视图
DROP VIEW view_name AS
四、SQL约束
SQL CREATE TABLE + CONSTRAINT 语法
CREATE TABLE table_name
(
column_name1 data_type(size) constraint_name,
column_name2 data_type(size) constraint_name,
column_name3 data_type(size) constraint_name,
....
);
在 SQL 中,我们有如下约束:
- NOT NULL - 指示某列不能存储 NULL 值。
- UNIQUE - 保证某列的每行必须有唯一的值。
- PRIMARY KEY - NOT NULL 和 UNIQUE 的结合。确保某列(或两个列多个列的结合)有唯一标识,有助于更容易更快速地找到表中的一个特定的记录。
- FOREIGN KEY - 保证一个表中的数据匹配另一个表中的值的参照完整性。
- CHECK - 保证列中的值符合指定的条件。
- DEFAULT - 规定没有给列赋值时的默认值。
1.NOT NULL
CREATE TABLE table_name
(
column_name1 data_type(size) NOT NULL,
column_name2 data_type(size) constraint_name,
column_name3 data_type(size) constraint_name,
....
);
2.UNIQUE
1)CREATE TABLE 时的 SQL UNIQUE 约束
CREATE TABLE table_name
(
column_name1 data_type(size) constraint_name ,
column_name2 data_type(size) constraint_name,
....
UNIQUE(column_name)
);
定义多列的unique约束 UNIQUE(column_name1,column_name2),定义约束并重命名CONSTRAINT new_name UNIQUE(column_name)
2)ALTER TABLE 时的 SQL UNIQUE 约束
ALTER TABLE table_name
ADD UNIQUE (column_name)
添加多列的unique约束 UNIQUE(column_name1,column_name2),定义约束并重命名CONSTRAINT new_name UNIQUE(column_name)
3)撤销 UNIQUE 约束
ALTER TABLE table_name
DROP CONSTRAINT constraintname
*mysql:ALTER TABLE table_name
DROP INDEX constraintname
3.PRIMARY KEY:
唯一且不重复,每个都应有个主键,语法法和UNIQUE一样
撤销 PRIMARY KEY 约束
ALTER TABLE table_name
DROP CONSTRAINT constraintname
*mysql:ALTER TABLE table_name
DROP PRIMARY KEY
4.FOREIGN KEY
指向另一个表的主键
1)CREATE TABLE 时的FOREIGN KEY 约束
CREATE TABLE table_name2
(
column_name1 data_type(size) constraint_name ,
column_name2 data_type(size) constraint_name,
....
FOREIGN KEY(column_name1) REFERENCES table1(column_name1))
);
5.CHECK:CHECK
约束用于限制列中的值的范围。
语法同上
exp1:
ALTER Table [dbo].[Persons] ADD CHECK(P_Id>3 AND City=‘CN’) --输入P_ID时必须大于3且CITY=cn
6.DEFAULT:
插入默认自
1)CREATE TABLE 时的 SQL DEFAULT 约束
CREATE TABLE table_name2
(
column_name1 data_type(size) DEFAULT value ,
column_name2 data_type(size) constraint_name,
....
);
2)ALTER TABLE 时的 SQL DEFAULT 约束
mysql:
ALTER TABLE table_name
ALTER column_name SET value
sql:
ALTER TABLE table_name
ADD DEFUALT value FOR column_name
3)撤销 DEFAULT 约束
ALTER TABLE table_name
DROP CONSTRAINT constraintname
五、函数
1.日期函数
1)sql

DATE - 格式:YYYY-MM-DD
DATETIME - 格式:YYYY-MM-DD HH:MM:SS
SMALLDATETIME - 格式:YYYY-MM-DD HH:MM:SS
TIMESTAMP - 格式:唯一的数字
2)mysql
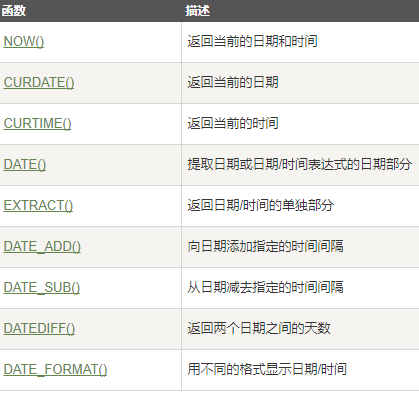
DATE - 格式:YYYY-MM-DD
DATETIME - 格式:YYYY-MM-DD HH:MM:SS
TIMESTAMP - 格式:YYYY-MM-DD HH:MM:SS
YEAR - 格式:YYYY 或 YY
2.ISNULL()
SQL: ISNULL(A,0) 如果A为NULL,则返回0
MYSQL:IFNULL()或COALESCE
3.SQL Aggregate 函数
SQL Aggregate 函数计算从列中取得的值,返回一个单一的值。
有用的 Aggregate 函数:
- AVG() - 返回平均值
SELECT AVG(column_name) AS average From table_name
- COUNT() - 返回行数
SELECT COUNT(column_name) AS count From table_name
- MAX() - 返回最大值
SELECT MAX(column_name) AS max From table_name
- MIN() - 返回最小值
SELECT MIN(column_name) AS min From table_name
- SUM() - 返回总和
SELECT SUM(column_name) AS sum From table_name
4.GROUP BY 分组
SELECT column_name, aggregate_function(column_name)
FROM table_name
WHERE column_name operator value
GROUP BY column_name;
select中有多项时,除聚合函数外都应添加到group by
5.HAVING SQL
增加 HAVING 子句原因是,WHERE 关键字无法与聚合函数一起使用
SELECT column_name, aggregate_function(column_name)
FROM table_name
WHERE column_name operator value
GROUP BY column_name
HAVING aggregate_function(column_name) operator value;
6.SQL Scalar 函数
SQL Scalar 函数基于输入值,返回一个单一的值
- UPPER() - 将某个字段转换为大写
SELECT UPPER(column_name) FROM table_name;
- LOWER() - 将某个字段转换为小写
SELECT LOWER(column_name) FROM table_name;
- MID() - 从某个文本字段提取字符,MySql 中使用
SELECT MID(column_name,start[,length]) FROM table_name;

SubString(字段,1,end) - 从某个文本字段提取字符
- LEN() - 返回某个文本字段的长度
SELECT LEN(column_name) FROM table_name;
MYSQL: LENGTH()
- ROUND() - 对某个数值字段进行指定小数位数的四舍五入
SELECT ROUND(column_name,decimals) FROM table_name;

当decimals为空时,无小数
- NOW() - 返回当前的系统日期和时间
SELECT NOW() FROM table_name;
- FORMAT() - 格式化某个字段的显示方式
SELECT FORMAT(column_name,format) FROM table_name;
SELECT name, url, DATE_FORMAT(Now(),'%Y-%m-%d') AS date
FROM Websites;
【SQL server】SQL server基础(二)的更多相关文章
- C#构造方法(函数) C#方法重载 C#字段和属性 MUI实现上拉加载和下拉刷新 SVN常用功能介绍(二) SVN常用功能介绍(一) ASP.NET常用内置对象之——Server sql server——子查询 C#接口 字符串的本质 AJAX原生JavaScript写法
C#构造方法(函数) 一.概括 1.通常创建一个对象的方法如图: 通过 Student tom = new Student(); 创建tom对象,这种创建实例的形式被称为构造方法. 简述:用来初 ...
- Sql Server来龙去脉系列之二 框架和配置
本节主要讲维持数据的元数据,以及数据库框架结构.内存管理.系统配置等.这些技术点在我们使用数据库时很少接触到,但如果要深入学习Sql Server这一章节也是不得不看.本人能力有限不能把所有核心的知识 ...
- .NET编程和SQL Server ——Sql Server 与CLR集成 (学习笔记整理-1)
原文:.NET编程和SQL Server ——Sql Server 与CLR集成 (学习笔记整理-1) 一.SQL Server 为什么要与CLR集成 1. SQL Server 提供的存储过程.函数 ...
- 服务器文档下载zip格式 SQL Server SQL分页查询 C#过滤html标签 EF 延时加载与死锁 在JS方法中返回多个值的三种方法(转载) IEnumerable,ICollection,IList接口问题 不吹不擂,你想要的Python面试都在这里了【315+道题】 基于mvc三层架构和ajax技术实现最简单的文件上传 事件管理
服务器文档下载zip格式 刚好这次项目中遇到了这个东西,就来弄一下,挺简单的,但是前台调用的时候弄错了,浪费了大半天的时间,本人也是菜鸟一枚.开始吧.(MVC的) @using Rattan.Co ...
- 13Microsoft SQL Server SQL 高级事务,锁,游标,分区
Microsoft SQL Server SQL高级事务,锁,游标,分区 通过采用事务和锁机制,解决了数据库系统的并发性问题. 9.1数据库事务 (1)BEGIN TRANSACTION语句定义事务的 ...
- SQL Server SQL性能优化之--通过拆分SQL提高执行效率,以及性能高低背后的原因
复杂SQL拆分优化 拆分SQL是性能优化一种非常有效的方法之一, 具体就是将复杂的SQL按照一定的逻辑逐步分解成简单的SQL,借助临时表,最后执行一个等价的逻辑,已达到高效执行的目的 一直想写一遍通过 ...
- SQL Server SQL分页查询
SQL Server SQL分页查询的几种方式 目录 0. 序言 1. TOP…NOT IN… 2. ROW_NUMBER() 3. OFFSET…FETCH 4. 执行 ...
- Qt调用Server SQL中的存储过程
Server SQL中的存储过程如下: CREATE procedure PINSERTPC @pcnum int, @pcname varchar(50), @pctype int, @ipaddr ...
- 对SQL Server SQL语句进行优化的10个原则
1.使用索引来更快地遍历表. 缺省情况下建立的索引是非群集索引,但有时它并不是最佳的.在非群集索引下,数据在物理上随机存放在数据页上.合理的索引设计要建立在对各种查询的分析和预测上.一般来说:①.有大 ...
- MySQL连接数据库报时区错误:java.sql.SQLException: The server time zone value
连接MySQL数据库时报以下时区错误信息: java.sql.SQLException: The server time zone value '�й���ʱ��' is unrecognized ...
随机推荐
- selenium chromedriver与chrome版本对应表
chromedriver版本 支持的Chrome版本 v2.41 v67-69 v2.40 v66-68 v2.39 ...
- fetch jsonp请求接口
function loadTbbRec() { var fetchJsonp = require('fetch-jsonp'); fetchJsonp(ext.info.tbbRecUrl, { he ...
- react Link标签 火狐失效怎么解决
这个问题其实找了好多资料都没有具体的解决方法: 今天突然想到可能是层级嵌套出问题了,刚好有个bug也是关于这个的,已经亲测解决了 代码如下:火狐和谷歌都能正常的跳转 <Link to=" ...
- 使用sort,uniq去重并统计出现次数
测试文档test 1 2 3 4 1 2 1 1 sort把相同的放在一起 [root@salt-test ~]# sort test 1 1 1 1 2 2 3 4 uniq -c统计出现的次数 [ ...
- selenium3 web自动化测试框架 四:Unittest介绍及项目实战中的运用
unittest介绍及运用,可以参考之前写的文章,除了未结合web自动化演示,基础知识都有了 https://www.cnblogs.com/wuzhiming/p/8858305.html unit ...
- kali安装chrome
文章搬到自己的网站上,如下: http://101.132.137.140:202/archives/2019-11-25
- Andrew Ng机器学习课程17(2)
Andrew Ng机器学习课程17(2) 声明:引用请注明出处http://blog.csdn.net/lg1259156776/ 说明:主要介绍了利用value iteration和policy i ...
- NAT-地址转换技术的配置
(一)NAT的概念及工作原理 简单来讲,nat就是将私有网址转化为共有网址的技术.NAT通常部署在一个组织的网络出口位置,成为NAT网关.举个栗子,一段报文想离开私网,必须经过NAT网关将数据传输给公 ...
- windows服务器入门 php的安装
下载PHP安装包(下载地址: http://windows.php.net/download/ ),本文档以5.3版本为例,选择如下图对应的安装包: 下载完成后进行安装PHP,需要选择Web服务时,选 ...
- python 使用 RabbitMQ
一.RabbitMQ消息队列介绍 RabbitMQ是在两个独立得python程序,或其他语言交互时使用. RabbitMQ:erlang语言 开发的. Python中连接RabbitMQ的模块:pik ...