《浏览器工作原理与实践》<08>调用栈:为什么JavaScript代码会出现栈溢出?
在上篇文章中,我们讲到了,当一段代码被执行时,JavaScript 引擎先会对其进行编译,并创建执行上下文。但是并没有明确说明到底什么样的代码才算符合规范。
那么接下来我们就来明确下,哪些情况下代码才算是“一段”代码,才会在执行之前就进行编译并创建执行上下文。一般说来,有这么三种情况:
1. 当 JavaScript 执行全局代码的时候,会编译全局代码并创建全局执行上下文,而且在整个页面的生存周期内,全局执行上下文只有一份。
2. 当调用一个函数的时候,函数体内的代码会被编译,并创建函数执行上下文,一般情况下,函数执行结束之后,创建的函数执行上下文会被销毁。
3. 当使用 eval 函数的时候,eval 的代码也会被编译,并创建执行上下文。
好了,又进一步理解了执行上下文,那本节我们就在这基础之上继续深入,一起聊聊调用栈。学习调用栈至少有以下三点好处:
1. 可以帮助你了解 JavaScript 引擎背后的工作原理;
2. 让你有调试 JavaScript 代码的能力;
3. 帮助你搞定面试,因为面试过程中,调用栈也是出境率非常高的题目。
比如你在写 JavaScript 代码的时候,有时候可能会遇到栈溢出的错误,如下图所示:
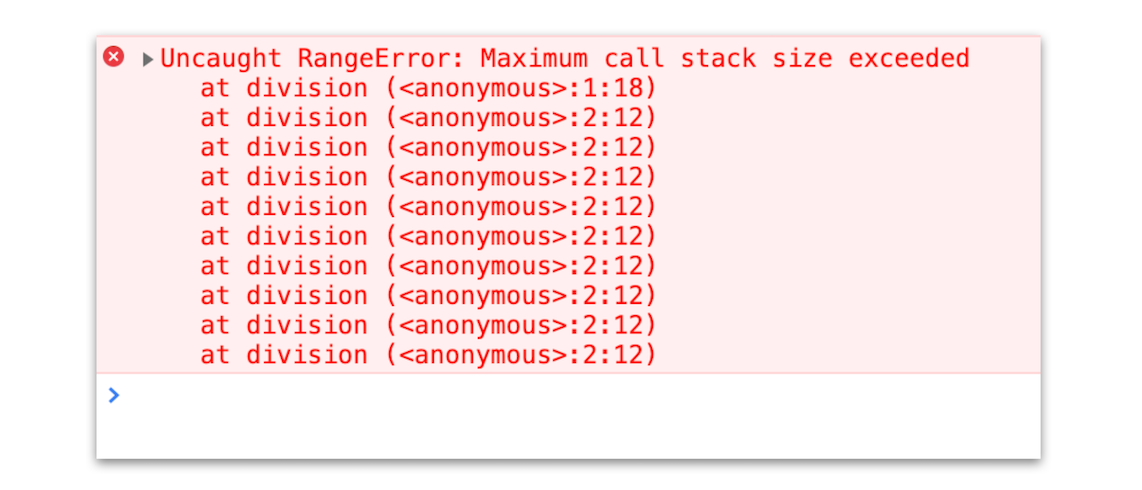
那为什么会出现这种错误呢?这就涉及到了调用栈的内容。你应该知道 JavaScript 中有很多函数,经常会出现在一个函数中调用另外一个函数的情况,调用栈就是用来管理函数调用关系的一种数据结构。因此要讲清楚调用栈,你还要先弄明白函数调用和栈结构。
什么是函数调用
函数调用就是运行一个函数,具体使用方式是使用函数名称跟着一对小括号。下面我们看个简单的示例代码:
var a = 2
function add(){
var b = 10
return a+b
}
add()
这段代码很简单,先是创建了一个 add 函数,接着在代码的最下面又调用了该函数。
那么下面我们就利用这段简单的代码来解释下函数调用的过程。
在执行到函数 add() 之前,JavaScript 引擎会为上面这段代码创建全局执行上下文,包含了声明的函数和变量,你可以参考下图:
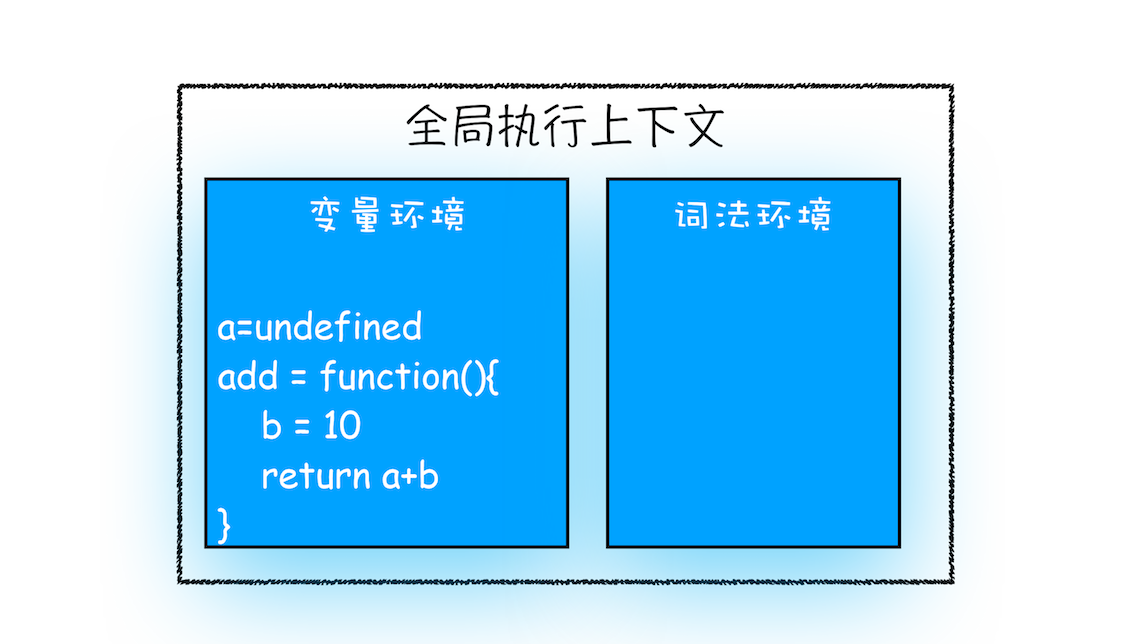
从图中可以看出,代码中全局变量和函数都保存在全局上下文的变量环境中。
执行上下文准备好之后,便开始执行全局代码,当执行到 add 这儿时,JavaScript 判断这是一个函数调用,那么将执行以下操作:
1. 首先,从全局执行上下文中,取出 add 函数代码。
2. 其次,对 add 函数的这段代码进行编译,并创建该函数的执行上下文和可执行代码。
3. 最后,执行代码,输出结果。
当执行到 add 函数的时候,我们就有了两个执行上下文了——全局执行上下文和 add 函数的执行上下文。
也就是说在执行 JavaScript 时,可能会存在多个执行上下文,那么 JavaScript 引擎是如何管理这些执行上下文的呢?
答案是通过一种叫栈的数据结构来管理的。那什么是栈呢?它又是如何管理这些执行上下文呢?
什么是栈
关于栈,你可以结合这么一个贴切的例子来理解,一条单车道的单行线,一端被堵住了,而另一端入口处没有任何提示信息,堵住之后就只能后进去的车子先出来,这时这个堵住的单行线就可以被看作是一个栈容器,车子开进单行线的操作叫做入栈,车子倒出去的操作叫做出栈。
所以,栈就是类似于一端被堵住的单行线,车子类似于栈中的元素,栈中的元素满足后进先出的特点。你可以参看下图:

什么是 JavaScript 的调用栈
JavaScript 引擎正是利用栈的这种结构来管理执行上下文的。在执行上下文创建好后,JavaScript 引擎会将执行上下文压入栈中,通常把这种用来管理执行上下文的栈称为执行上下文栈,又称调用栈。
为便于你更好地理解调用栈,下面我们再来看段稍微复杂点的示例代码:
var a = 2
function add(b,c){
return b+c
}
function addAll(b,c){
var d = 10
result = add(b,c)
return a+result+d
}
addAll(3,6)
在上面这段代码中,你可以看到它是在 addAll 函数中调用了 add 函数,那在整个代码的执行过程中,调用栈是怎么变化的呢?
下面我们就一步步地分析在代码的执行过程中,调用栈的状态变化情况。
第一步,创建全局上下文,并将其压入栈底。如下图所示:
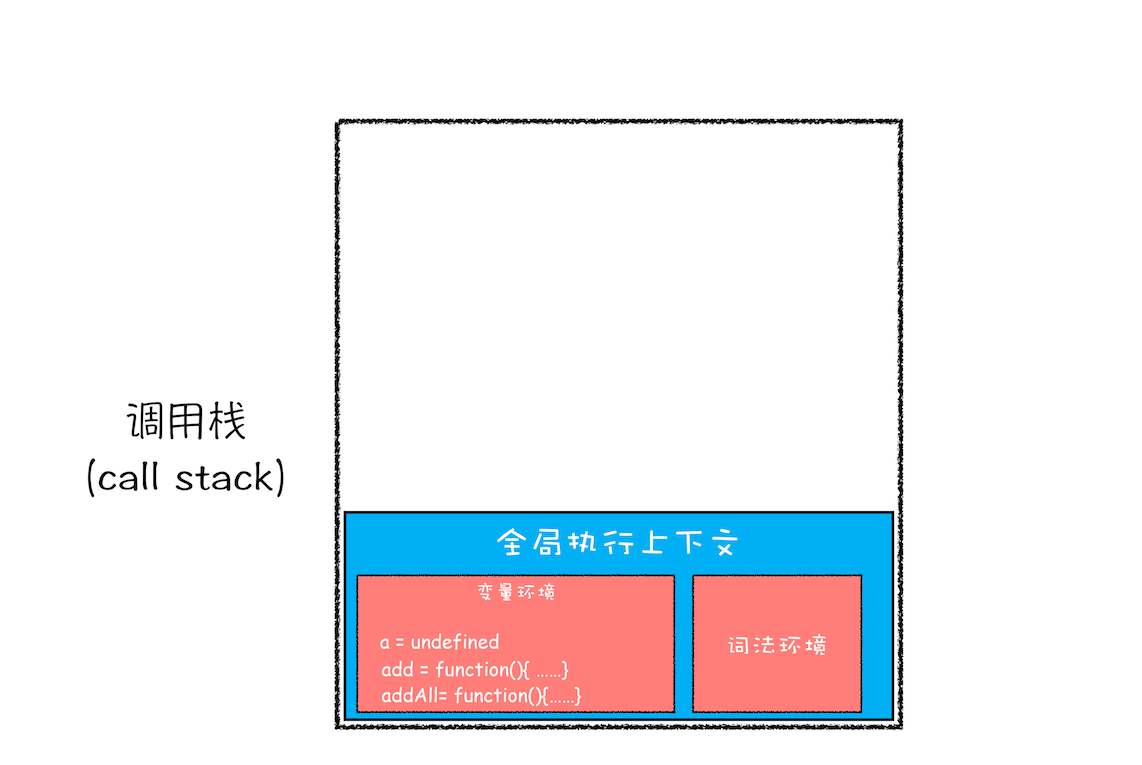
从图中你也可以看出,变量 a、函数 add 和 addAll 都保存到了全局上下文的变量环境对象中。
全局执行上下文压入到调用栈后,JavaScript 引擎便开始执行全局代码了。首先会执行 a=2 的赋值操作,执行该语句会将全局上下文变量环境中 a 的值设置为 2。设置后的全局上下文的状态如下图所示:
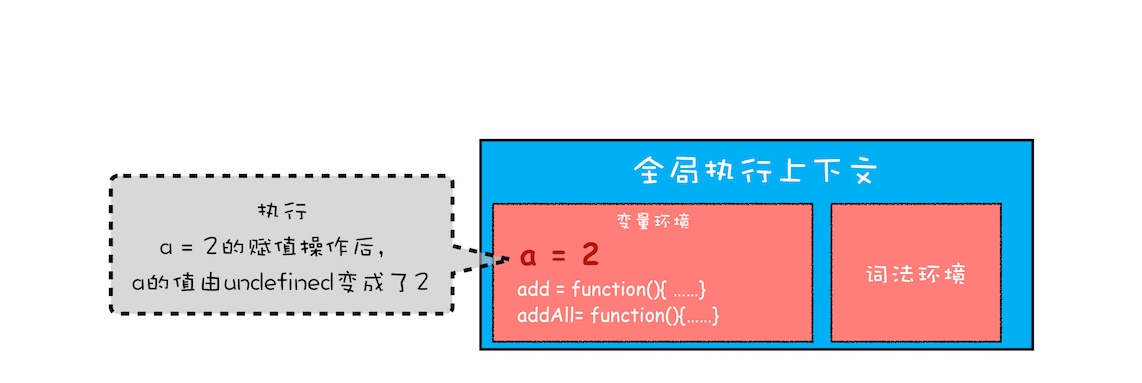
接下来,第二步是调用 addAll 函数。当调用该函数时,JavaScript 引擎会编译该函数,并为其创建一个执行上下文,最后还将该函数的执行上下文压入栈中,如下图所示:
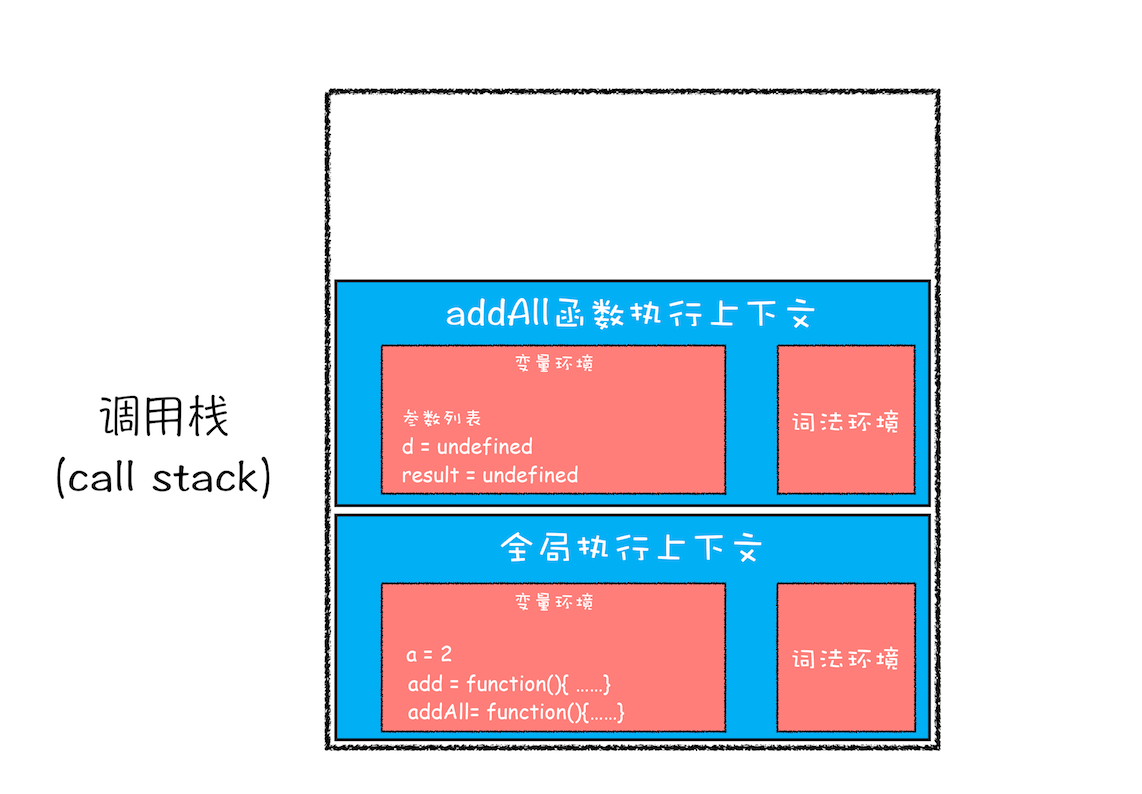
addAll 函数的执行上下文创建好之后,便进入了函数代码的执行阶段了,这里先执行的是 d=10 的赋值操作,执行语句会将 addAll 函数执行上下文中的 d 由 undefined 变成了 10。
然后接着往下执行,第三步,当执行到 add 函数调用语句时,同样会为其创建执行上下文,并将其压入调用栈,如下图所示:
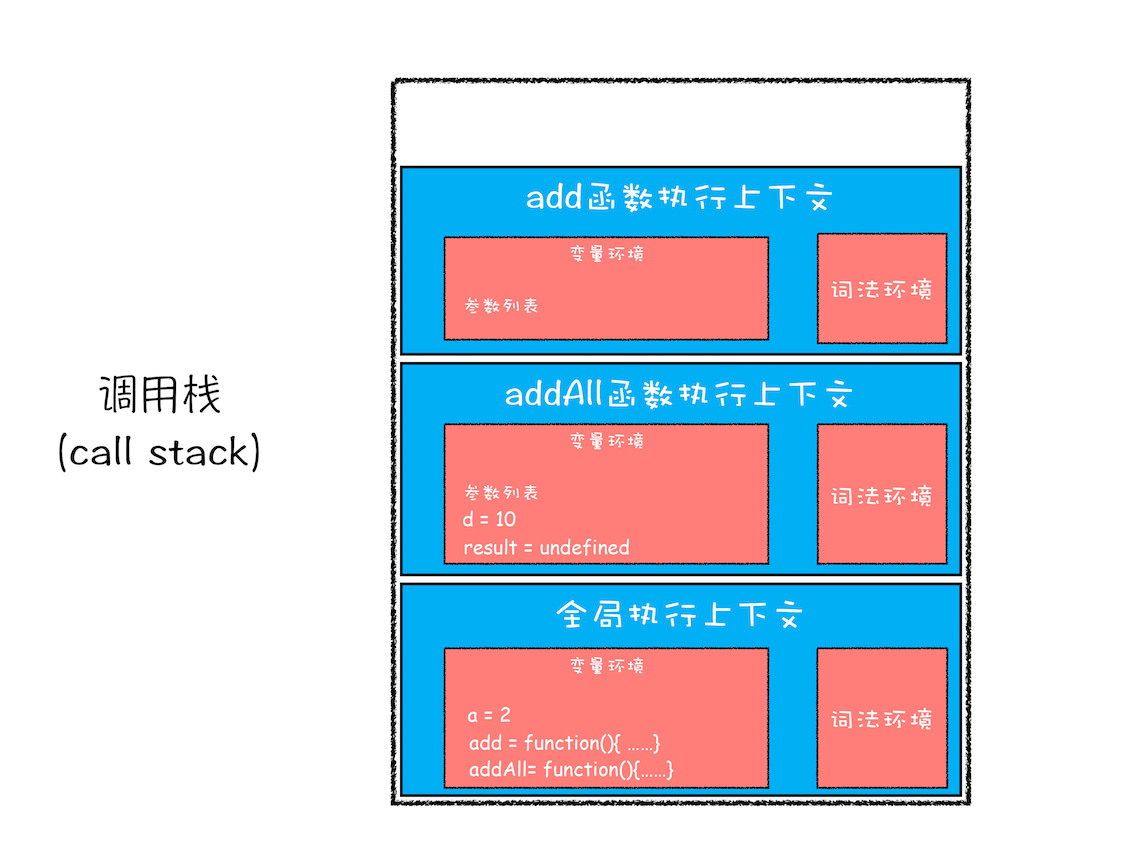
当 add 函数返回时,该函数的执行上下文就会从栈顶弹出,并将 result 的值设置为 add 函数的返回值,也就是 9。如下图所示:

紧接着 addAll 执行最后一个相加操作后并返回,addAll 的执行上下文也会从栈顶部弹出,此时调用栈中就只剩下全局上下文了。最终如下图所示:
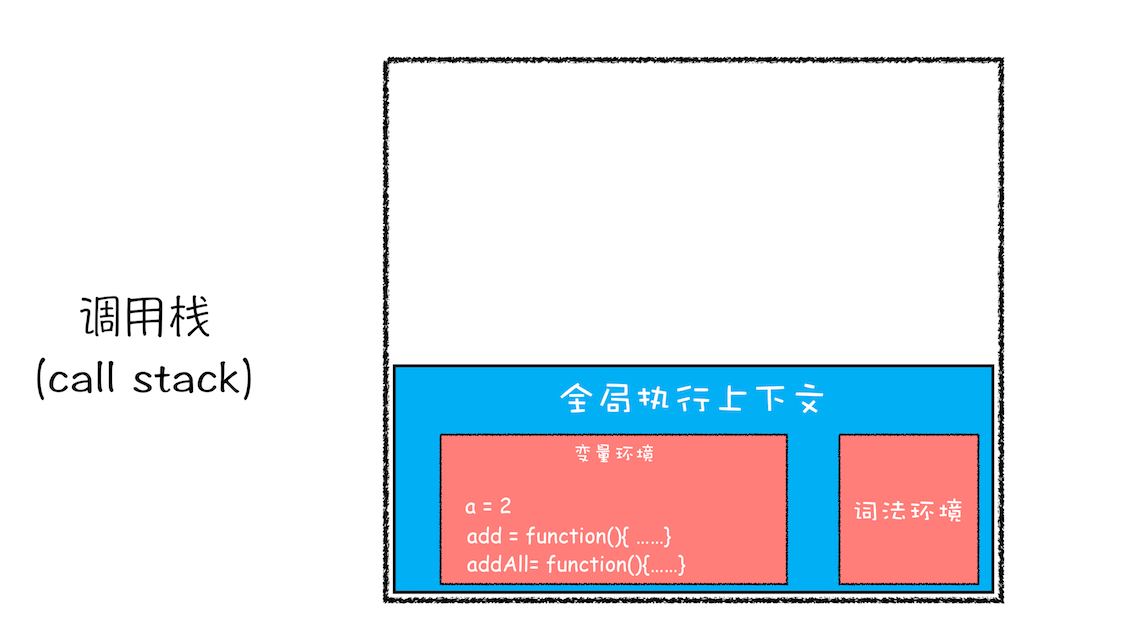
至此,整个 JavaScript 流程执行结束了。
好了,现在你应该知道了调用栈是 JavaScript 引擎追踪函数执行的一个机制,当一次有多个函数被调用时,通过调用栈就能够追踪到哪个函数正在被执行以及各函数之间的调用关系。
在开发中,如何利用好调用栈
鉴于调用栈的重要性和实用性,那么接下来我们就一起来看看在实际工作中,应该如何查看和利用好调用栈。
1. 如何利用浏览器查看调用栈的信息
当你执行一段复杂的代码时,你可能很难从代码文件中分析其调用关系,这时候你可以在你想要查看的函数中加入断点,然后当执行到该函数时,就可以查看该函数的调用栈了。
这么说可能有点抽象,这里我们拿上面的那段代码做个演示,你可以打开“开发者工具”,点击“Source”标签,选择 JavaScript 代码的页面,然后在第 3 行加上断点,并刷新页面。你可以看到执行到 add 函数时,执行流程就暂停了,这时可以通过右边“call stack”来查看当前的调用栈的情况,如下图:
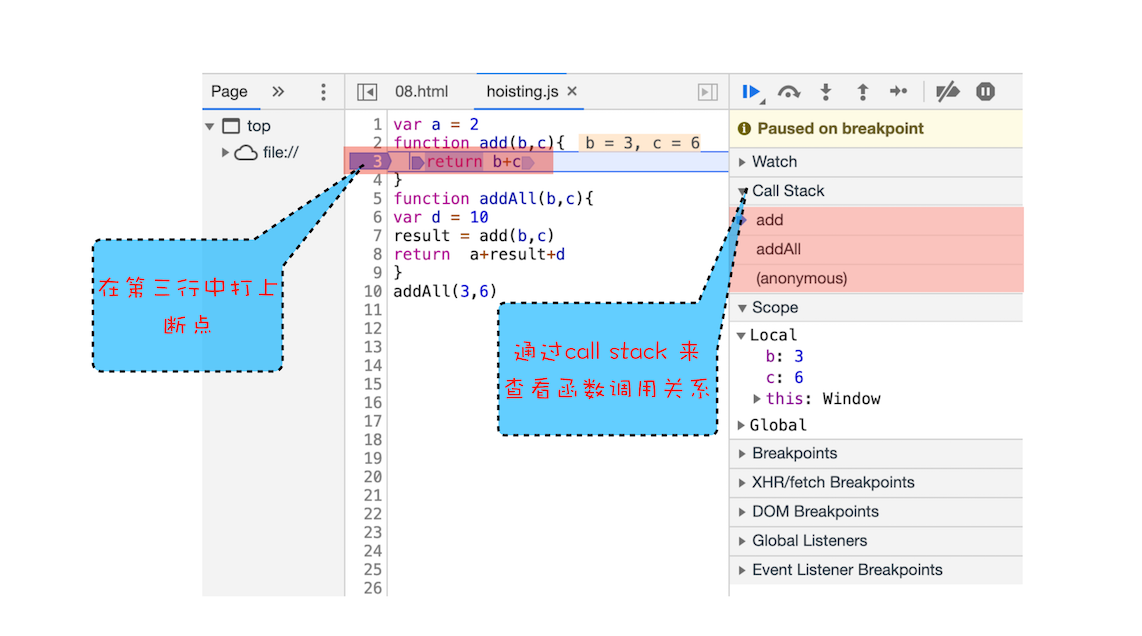
从图中可以看出,右边的“call stack”下面显示出来了函数的调用关系:栈的最底部是 anonymous,也就是全局的函数入口;中间是 addAll 函数;顶部是 add 函数。这就清晰地反映了函数的调用关系,所以在分析复杂结构代码,或者检查 Bug 时,调用栈都是非常有用的。
除了通过断点来查看调用栈,你还可以使用 console.trace() 来输出当前的函数调用关系,比如在示例代码中的 add 函数里面加上了 console.trace(),你就可以看到控制台输出的结果,如下图:

2. 栈溢出(Stack Overflow)
现在你知道了调用栈是一种用来管理执行上下文的数据结构,符合后进先出的规则。不过还有一点你要注意,调用栈是有大小的,当入栈的执行上下文超过一定数目,JavaScript 引擎就会报错,我们把这种错误叫做栈溢出。
特别是在你写递归代码的时候,就很容易出现栈溢出的情况。比如下面这段代码:
function division(a,b){
return division(a,b)
}
console.log(division(1,2))
当执行时,就会抛出栈溢出错误,如下图:

从上图你可以看到,抛出的错误信息为:超过了最大栈调用大小(Maximum call stack size exceeded)。
那为什么会出现这个问题呢?这是因为当 JavaScript 引擎开始执行这段代码时,它首先调用函数 division,并创建执行上下文,压入栈中;然而,这个函数是递归的,并且没有任何终止条件,所以它会一直创建新的函数执行上下文,并反复将其压入栈中,但栈是有容量限制的,超过最大数量后就会出现栈溢出的错误。
理解了栈溢出原因后,你就可以使用一些方法来避免或者解决栈溢出的问题,比如把递归调用的形式改造成其他形式,或者使用加入定时器的方法来把当前任务拆分为其他很多小任务。
总结
好了,今天的内容就讲到这里,下面来总结下今天的内容。
每调用一个函数,JavaScript 引擎会为其创建执行上下文,并把该执行上下文压入调用栈,然后 JavaScript 引擎开始执行函数代码;
如果在一个函数 A 中调用了另外一个函数 B,那么 JavaScript 引擎会为 B 函数创建执行上下文,并将 B 函数的执行上下文压入栈顶;
当前函数执行完毕后,JavaScript 引擎会将该函数的执行上下文弹出栈;
当分配的调用栈空间被占满时,会引发“堆栈溢出”问题;
栈是一种非常重要的数据结构,不光应用在 JavaScript 语言中,其他的编程语言,如 C/C++、Java、Python 等语言,在执行过程中也都使用了栈来管理函数之间的调用关系。所以栈是非常基础且重要的知识点,你必须得掌握。
注: 本文出自极客时间(浏览器工作原理与实践),请大家多多支持李兵老师。如有侵权,请及时告知。
《浏览器工作原理与实践》<08>调用栈:为什么JavaScript代码会出现栈溢出?的更多相关文章
- 《浏览器工作原理与实践》 <12>栈空间和堆空间:数据是如何存储的?
对于前端开发者来说,JavaScript 的内存机制是一个不被经常提及的概念 ,因此很容易被忽视.特别是一些非计算机专业的同学,对内存机制可能没有非常清晰的认识,甚至有些同学根本就不知道 JavaSc ...
- 《浏览器工作原理与实践》<09>块级作用域:var缺陷以及为什么要引入let和const?
在前面我们已经讲解了 JavaScript 中变量提升的相关内容,正是由于 JavaScript 存在变量提升这种特性,从而导致了很多与直觉不符的代码,这也是 JavaScript 的一个重要设计缺陷 ...
- 《浏览器工作原理与实践》<11>this:从JavaScript执行上下文的视角讲清楚this
在上篇文章中,我们讲了词法作用域.作用域链以及闭包,接下来我们分析一下这段代码: var bar = { myName:"time.geekbang.com", printName ...
- 《浏览器工作原理与实践》<10>作用域链和闭包 :代码中出现相同的变量,JavaScript引擎是如何选择的?
在上一篇文章中我们讲到了什么是作用域,以及 ES6 是如何通过变量环境和词法环境来同时支持变量提升和块级作用域,在最后我们也提到了如何通过词法环境和变量环境来查找变量,这其中就涉及到作用域链的概念. ...
- 《浏览器工作原理与实践》<07>变量提升:JavaScript代码是按顺序执行的吗?
讲解完宏观视角下的浏览器后,从这篇文章开始,我们就进入下一个新的模块了,这里我会对 JavaScript 执行原理做深入介绍. 今天在该模块的第一篇文章,我们主要讲解执行上下文相关的内容.那为什么先讲 ...
- 《浏览器工作原理与实践》<03>HTTP请求流程:为什么很多站点第二次打开速度会很快?
一个 TCP 连接过程包括了建立连接.传输数据和断开连接三个阶段. 而 HTTP 协议,正是建立在 TCP 连接基础之上的.HTTP 是一种允许浏览器向服务器获取资源的协议,是 Web 的基础,通常由 ...
- 《浏览器工作原理与实践》<06>渲染流程(下):HTML、CSS和JavaScript,是如何变成页面的?
在上篇文章中,我们介绍了渲染流水线中的 DOM 生成.样式计算和布局三个阶段,那今天我们接着讲解渲染流水线后面的阶段. 这里还是先简单回顾下上节前三个阶段的主要内容:在 HTML 页面内容被提交给渲染 ...
- 《浏览器工作原理与实践》<05>渲染流程(上):HTML、CSS和JavaScript,是如何变成页面的?
在上一篇文章中我们介绍了导航相关的流程,那导航被提交后又会怎么样呢?就进入了渲染阶段.这个阶段很重要,了解其相关流程能让你“看透”页面是如何工作的,有了这些知识,你可以解决一系列相关的问题,比如能熟练 ...
- 《浏览器工作原理与实践》<04>从输入URL到页面展示,这中间发生了什么?
“在浏览器里,从输入 URL 到页面展示,这中间发生了什么? ”这是一道经典的面试题,能比较全面地考察应聘者知识的掌握程度,其中涉及到了网络.操作系统.Web 等一系列的知识. 在面试应聘者时也必问这 ...
随机推荐
- c# 结构体struct注意事项
c# 结构struct注意事项 1,不能定义无参构造函数,因为隐式的默认无参构造函数不能被重写 2,当为某个结构编写带有参数的构造函数时,必须显式初始化所有成员,否则编译不过. 3,不允许在结构的实例 ...
- MariaDB集群配置(主从和多主)
1.mariadb主从 主从多用于网站架构,因为主从的同步机制是异步的,数据的同步有一定延迟,也就是说有可能会造成数据的丢失,但是性能比较好,因此网站大多数用的是主从架构的数据库,读写分离必须基于主从 ...
- go基础系列 第二章 go指针
一. 指针 先来看一段代码 var pa *int pa = &a *pa = fmt.Println(a) 这里定义了一个int类型的变量a, 有定义了一个指针类型的变量pa, 让pa指向了 ...
- java 微信开发的工具类WeChatUtils
import com.alibaba.fastjson.JSONObject;import com.bhudy.entity.BhudyPlugin;import com.bhudy.service. ...
- Java基础---Java 开发工具IntelliJ IDEA 安装
1.1 开发工具概述IDEA是一个专门针对Java的集成开发工具(IDE),由Java语言编写.所以,需要有JRE运行环境并配置好环境变量.它可以极大地提升我们的开发效率.可以自动编译,检查错误.在公 ...
- 向前引用 ? float VS long ? 这些知识你懂吗?
thinking in java 读书笔记(感悟): 作者:淮左白衣 : 写于 2018年4月2日18:14:15 目录 基本数据类型 float 和 long 谁更大 System.out.prin ...
- c++语法笔记(下)
多态性与虚函数 多态性(函数重载,运算符重载就是多态性现象)多态性 :向不同对象发送同一个消息,不同对象在接收时会产生不同的行为.(每个对象用自己的方式去响应共同的消息)多态性又可以分为静态多态性和动 ...
- C语言细节
一些常见细节 int *p[]和 int (*p)[] 的区别 int *p[4]; //定义一个指针数组,该数组中每个元素是一个指针,每个指针指向哪里就需要程序中后续再定义了. int (*p)[4 ...
- Hibernate一对多自关联、多对多关联
今天分享hibernate框架的两个关联关系 多对多关系注意事项 一定要定义一个主控方 多对多删除 主控方直接删除 被控方先通过主控方解除多对多关系,再删除被控方 禁用级联删除 关联关系编辑,不 ...
- Junit 学习笔记
目录 Junit 学习笔记 1. 编写测试用例时需要注意 2. 出现结果分析 3. Junit 运行流程 4. Junit 常用注解 5. Junit 测试套件的使用 6. Junit 参数化设置 J ...