可插拔式后台管理系统(Django)
1.实现效果
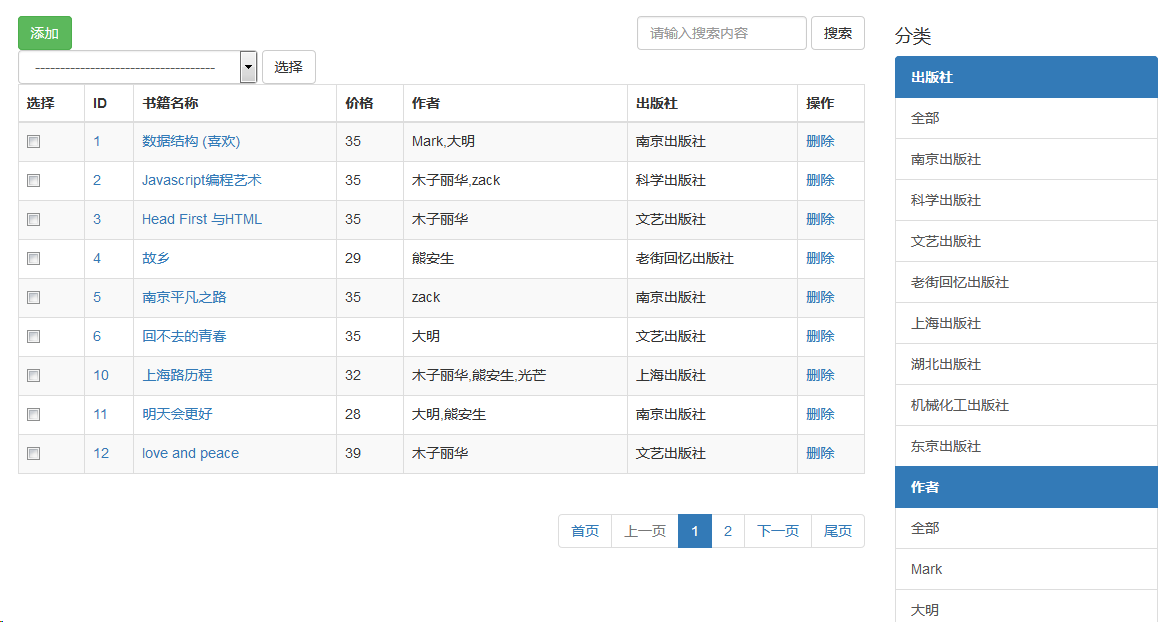
研究了下django admin的功能,自己实现了一个简单的可插拔式后台管理系统,方便自定义特殊的功能,而且作为一个独立单独的django app,可以整体拷贝到其他项目中作为后台数据管理系统,对数据进行增删改查和自定义操作。下图是拷贝到一个图书管理系统中的后台效果:
2.实现思路
2.1 url的设计和分发
Django自带的admin,对于不同app的不同model表,都会动态的生成类似下面的四条url,分别对应着后台数据的增删改查页面。而为了实现动态路由需要配置两处,一是在项目全局urls.py文件中urlpatterns = [ url(r'^admin/', admin.site.urls),], 二是在每个app的admin.py文件中对model表进行了注册admin.site.register(model),这两处都涉及到了一个admin.site对象,因此我们需要实现自己的site对象即可。
查看:http://127.0.0.1:8008/admin/app01/book/
添加:http://127.0.0.1:8008/admin/app01/book/add/
更新:http://127.0.0.1:8008/admin/app01/book/1/change/
删除:http://127.0.0.1:8008/admin/app01/book/1/delete/
另外,对于django的url多级路由格式需要了解下:url(r" ",([ url(), url()], None, None)), 为 一个三元元祖([],None,None),而元祖中的列表[]又可以嵌套多个相同格式的url([],None,None),如下面的代码实现了三条路由:
url(r'^myAdmin2/', ([ url(r'^book1/',views.index1),
url(r'^book2/',([ url(r'^change/',views.index2), url(r'^add/',views.index3)],None,None ))],
None,None),)
对应的url如下:
http://127.0.0.1:8008/myAdmin2/book1/
http://127.0.0.1:8008/myAdmin2/book2/change/
http://127.0.0.1:8008/myAdmin2/book2/add/
根据上述的思路和多级url路由,可以定义同样的路由设置,一是设置urls.py中全局路由,二是在app的admin.py文件中注册model,三是实现自己的myAdmin.site对象。对应的代码依次如下:
urls.py
from django.conf.urls import urlfrom myAdmin.service.site import site # 引入自定义的site.py 文件中生成的site单例对象
urlpatterns = [
url(r'^myAdmin/', site.urls),
]
app01/admin.py
from myAdmin.service.site import site
from app01 import models
site.register(models.Book)
site.register(models.Author)
site.register(models.Publish)
myAdmin/service/site.py
class ModelAdmin(object):
def __init__(self, model):
self.model = model
self.model_name = self.model._meta.model_name
self.app_label = self.model._meta.app_label @property
def urls(self):
return self.get_urls(), None, None def get_urls(self):
patterns = [url(r'^$', self.list_view, name='%s_%s_list'%(self.model_name,self.app_label)),
url(r'^add/$', self.add_view,name='%s_%s_add'%(self.model_name,self.app_label)),
url(r'^(.+)/change/$', self.change_view,name='%s_%s_change'%(self.model_name,self.app_label)),
url(r'^(.+)/delete/$', self.delete_view,name='%s_%s_delete'%(self.model_name,self.app_label)),
]
return patterns class AdminSite(object):
def __init__(self):
self._registry = {} def register(self, model, admin_class=None): #对应model表注册时的site.register()
if not admin_class:
admin_class = ModelAdmin
admin_obj = admin_class(model)
self._registry[model] = admin_obj @property
def urls(self): #对应全局路由中的site.urls
return self.get_urls(), None, None def get_urls(self):
patterns = []
for model, admin_obj in self._registry.items():
urls = url(r'^{0}/{1}/'.format(model._meta.app_label, model._meta.model_name), admin_obj.urls)
patterns.append(urls)
return patterns site = AdminSite()
在site.py代码中有三处值得注意,
1. site = AdminSite(), 这里是采用了python模块的天然单例模式,由于每个app中都会采用site对象,因此在整个项目中只能有一个site对象。
2. AdminSite中的get_urls(self)函数
urls = url(r'^{0}/{1}/'.format(model._meta.app_label, model._meta.model_name), admin_obj.urls) 实现了第一级动态路由,即/app01/model/
3. ModelAdmin中的get_urls(self)函数
patterns = [url(r'^$', self.list_view, name='%s_%s_list'%(self.model_name,self.app_label)),
url(r'^add/$', self.add_view,name='%s_%s_add'%(self.model_name,self.app_label)),
url(r'^(.+)/change/$', self.change_view,name='%s_%s_change'%(self.model_name,self.app_label)),
url(r'^(.+)/delete/$', self.delete_view,name='%s_%s_delete'%(self.model_name,self.app_label)), ]
实现了第二级动态路由,即 app01/model, app01/model/add/, app01/model/id/change/, app01/model/id/delete 增删改查四条路径。
2.2 实现增删改查处理函数
在上面url设计中,在ModelAdmin类中定义了相应的处理函数,如下面self.list_view,self.add_view,self.change_view,self.delete_view,需要对其依次实现。
patterns = [url(r'^$', self.list_view, name='%s_%s_list'%(self.model_name,self.app_label)),
url(r'^add/$', self.add_view,name='%s_%s_add'%(self.model_name,self.app_label)),
url(r'^(.+)/change/$', self.change_view,name='%s_%s_change'%(self.model_name,self.app_label)),
url(r'^(.+)/delete/$', self.delete_view,name='%s_%s_delete'%(self.model_name,self.app_label)), ]
实现后的site.py代码如下:由于需要用到ModelForm类,定义了两个辅助方法get_modelform_class()和 change_modelform()
def get_modelform_class(self):
class Model_form(ModelForm):
class Meta:
model = self.model
fields = '__all__'
return Model_form #返回类对象 def change_modelform(self,modelform):
for item in modelform:
if isinstance(item.field, ModelChoiceField): # ModelChoiceField表示field字段对应的为外键或多对对关系
pop_item_name = item.name
item.is_pop=True #为实例动态绑定属性
item_model_name = item.field.queryset.model._meta.model_name
item_app_label = item.field.queryset.model._meta.app_label
item.pop_url = '/myAdmin/{0}/{1}/add/?pop_item_name={2}'.format(item_app_label, item_model_name,pop_item_name)
return modelform
#添加数据
def add_view(self, request):
modelform_class = self.get_modelform_class()
form = modelform_class()
form = self.change_modelform(form)
if request.method == 'POST':
form = modelform_class(request.POST)
field_obj = form.save()
# url = request.path[:-]
# print url
pop_item_name = request.GET.get('pop_item_name')
if pop_item_name:
result = {'pk':field_obj.pk,'text':str(field_obj),'pop_item_name':pop_item_name}
return render(request, 'process_pop.html', {'result':result})
return redirect(self.get_list_url())
return render(request, 'add_view.html', locals()) # 改变数据
def change_view(self, request, number):
modelform_class = self.get_modelform_class()
model_obj = self.model.objects.filter(id=number).first()
form = modelform_class(instance=model_obj)
form = self.change_modelform(form)
if request.method == 'POST':
form = modelform_class(request.POST, instance=model_obj)
form.save()
return redirect(self.get_list_url())
return render(request, 'change_view.html', locals()) # 删除数据
def delete_view(self, request, number):
model_obj = self.model.objects.get(id=number)
list_url = self.get_list_url()
edit_url = self.get_change_url(model_obj)
if request.method=='POST':
model_obj.delete()
return redirect(list_url)
return render(request, 'delete_view.html', locals())
site.py
list_view 较为复杂,上面没列出,下面单独列出代码。因为list_view界面中还支持搜索,分类和批量处理三个功能,list_view必须对这三种请求进行捕获和处理。从下面代码中可以看到:定义了两个辅助方法,get_search_condition()和get_filter_condition()来处理搜索和分类过滤(详细见自定义字段的实现)。搜索框和分类过滤器请求通过GET请求提交,get_search_condition()处理搜索框提交的GET请求,将搜索条件封装成一个Q对象返回,get_filter_condition()处理过滤器提交的GET请求,返回Q对象。actions的请求(批量处理)通过POST请求提交,将批处理函数和选定项提交到request.POST,然后list_view进行处理。实现代码如下:
#处理搜索框提交的请求
def get_search_condition(self,request):
search_connector = Q()
if request.method=='GET':
search_content = request.GET.get('search_content','')
search_connector.connector = 'or'
if search_content and self.search_field:
for field in self.search_field:
# field_obj = self.model._meta.get_field(field)
# if isinstance(field_obj,ManyToManyField) or isinstance(field_obj,ForeignKey):
# search_connector.children.append((field + '__name__contains', search_content)) #对于多对多关系,如何实现动态?
# else:
search_connector.children.append((field + '__contains', search_content))
return search_connector #处理过滤标签的<a>标签提交的请求
def get_filter_condition(self,request):
filter_connector = Q()
if request.method == 'GET':
for filter_field, value in request.GET.items():
if filter_field in self.list_filter: # 设置分页后url会出现page参数,不应做为过滤条件
filter_connector.children.append((filter_field, value))
return filter_connector #查看:显示数据
def list_view(self, request):
model = self.model
if request.method == 'POST':
choice_item = request.POST.get('choice_item')
selected_item = request.POST.getlist('selected_item')
action_func = getattr(self,choice_item)
queryset = model.objects.filter(id__in =selected_item)
action_func(queryset)
search_condition = self.get_search_condition(request)
filter_condition = self.get_filter_condition(request)
model_list = model.objects.all().filter(search_condition).filter(filter_condition)
showlist= Showlist(self,model_list,model,request) #单独抽象出一个类,用来配置前端数据的显示
return render(request, 'list_view.html', locals())
2.3 自定义字段的实现
在ModelAdmin中可以定义相应的字段,对数据管理显示界面进行设置,从而在model进行注册时能根据需求对这些字段进行更改和扩展,展示出不同的显示效果。下面定义了显示字段,过滤器,搜索和批处理等:
class ModelAdmin(object):
list_display = ('__str__',) #自定义显示的字段
list_display_links = () #自定义超链接字段,点击进入编辑页面
list_filter = () #自定义过滤器字段,根据该字段分类
search_field = () #自定义搜索字段,搜索的内容和这些字段进行匹配
actions = () #自定义批处理函数
list_display 的扩展
下面代码为list_display的实现,首先在list_display中加入默认的选择框,编辑和删除超链接,然后对用户配置的list_play进行扩展,得到完整的list_play,再进行渲染,代码如下:
# 定义默认要显式的内容, 编辑,删除操作和选择框,并扩展list_display
def edit(self,model_obj=None,isHeader=False): #model_obj: 一个model表对象,isHeader是否是表格的表头字段
if isHeader:
return '操作'
return mark_safe(
'<a href="%s/change/">编辑</a>' % model_obj.pk) # 注意href="%s/change/ 和 href="/%s/change/的区别,前者为当前目录,后者为根目录 def checkbox(self,model_obj=None, isHeader=False):
if isHeader:
return '选择'
return mark_safe('<input type="checkbox" value="%s" name="selected_item"/>'%model_obj.pk) def delete(self,model_obj=None, isHeader=False):
if isHeader:
return '操作'
return mark_safe(
'<a href="%s/delete/">删除</a>' % model_obj.pk) def get_list_display(self):
new_list_display = []
new_list_display.append(ModelAdmin.checkbox) #加入选择框
new_list_display.extend(self.list_display) #加入用户配置的list_display
if not self.list_display_links:
new_list_display.append(ModelAdmin.edit) #如果用户未配置超链接字段,加入编辑操作
new_list_display.append(ModelAdmin.delete) #加入删除操作
return new_list_display
上面代码拿到了一个完整的list_display=(checkbox, '', '', exit, delete),而对于list_display的处理和前端显示见下面Showlist 类。
actions 的扩展
和list_diaplay一样,下面代码中,在actions加入默认的批量删除函数,并扩展用户配置的actions批处理函数,拿到了一个完整的actions=(batch_delete, ), 其处理和前端显示见后面Showlist 类
#定义默认的批量删除函数,并扩展用户actions
def batch_delete(self,queryset):
queryset.delete()
batch_delete.short_description = '批量删除' def get_actions(self):
new_actions = []
new_actions.append(ModelAdmin.batch_delete) # 加入批量删除操作
new_actions.extend(self.actions) # 扩展用户配置actions
return new_actions
在实现list_view()函数时,用到了一个单独的类Showlist, 其中定义了 list_diaplay, list_play_links, list_filter, search_field 和 actions的处理和前端显示逻辑,代码如下:
class Showlist(object):
'''
需要四个参数来初始化实例:
model_config: ModelAdmin 的实例对象,决定了其相关配置项
model_list: 发送给前端的表格中要展示的数据对象(Queryset)
model:数据表对象
request:视图函数中的request参数
''' def __init__(self,model_config,model_list,model,request):
self.model_config = model_config
self.model_list = model_list
self.model = model
self.request = request # 设置分页
current_page = int(request.GET.get('page',1))
params = self.request.GET
base_url = self.request.path
all_count = self.model_list.count()
#print 'all_count',all_count
self.page = page.Pagination(current_page, all_count, base_url, params, per_page_num=4, pager_count=3,)
self.page_data = self.model_list[self.page.start:self.page.end] # 前端actions的显示数据
def get_action_desc(self):
# actions
list_actions = []
if self.model_config.get_actions():
for action in self.model_config.get_actions():
list_actions.append({
"name": action.__name__, #批处理函数的名字
"desc": action.short_description
})
return list_actions
# 前端过滤器的显示数据
def get_filter_dict(self):
filter_dict = {}
for field in self.model_config.list_filter:
params = copy.deepcopy(self.request.GET)
selection = self.request.GET.get(field, 0)
field_obj = self.model._meta.get_field(field)
if isinstance(field_obj, ForeignKey) or isinstance(field_obj, ManyToManyField): #对于多对多或外键字段的处理
data_list = field_obj.rel.to.objects.all() #field_obj.rel.to 能拿到多对多或外键字段对应的另一张model表对象
else:
data_list = self.model.objects.all().values('pk', field)
temp = []
if params.get(field): #url参数的过滤条件中,如果有该字段的过滤条件,则点击全部时应该删除该字段的过滤条件,从而显示全部数据;
del params[field]
temp.append("<a href='?%s' class='list-group-item is_selected'>全部</a>" % params.urlencode())
else: #不含有该字段的过滤条件,点击时不处理
temp.append("<a href='#' class='list-group-item'>全部</a>")
for item in data_list:
if isinstance(field_obj, ForeignKey) or isinstance(field_obj, ManyToManyField): #多对多或外键字段,拿到的为对象
id = item.pk
text = str(item)
params[field] = id #多对多或外键字段,以id做为过滤条件
else: #普通字段拿到的为字典
id = item['pk']
text = item[field]
params[field] = text #普通字段以字段名称做为过滤条件
tag_url = params.urlencode()
if selection == str(id) or selection == text: #判断此时url过滤字段中选中的条件,为其添加特殊style样式
temp.append("<a href='?%s' class='list-group-item is_selected'>%s</a>" % (tag_url, text))
else:
temp.append("<a href='?%s' class='list-group-item'>%s</a>" % (tag_url, text))
filter_dict[field_obj] = temp
return filter_dict
#前端表格表头的显示数据
def get_head_list(self):
head_list = []
for field in self.model_config.get_list_display():
if isinstance(field, str): #判断函数和字符窜
if field == '__str__': #用户未配置时默认的list_play=('__str__',)
value = self.model._meta.model_name
else:
field_obj = self.model._meta.get_field(field) # 拿到字符窜对应的field对象
value = field_obj.verbose_name # 通过拿到verbose_name 来显示中文
else:
value = field(self.model_config, isHeader=True) # 获取标题,传入isHeader, 注意此处传入的self.model_config
if value:
head_list.append(value)
return head_list
#前端表格内容的显示数据
def get_data_list(self):
data_list = []
for model_obj in self.page_data: #分页截取的某一页的数据列表
row_list = []
for field in self.model_config.get_list_display():
if isinstance(field, str): #判断是字符窜或函数
try :
field_obj = self.model_config.model._meta.get_field(field) #判断设置的显式列是否为多对多关系,处理相应的多个数据
if isinstance(field_obj, ManyToManyField):
temp_list = getattr(model_obj, field).all()
#print temp_list
ret = []
for temp in temp_list:
#print temp
ret.append(str(temp)) #转换为字符窜后进行拼接
value = ','.join(ret)
#print value
else:
value = getattr(model_obj, field) # 通过反射拿到字符窜对应的值
if field in self.model_config.list_display_links: # 判断该字段是否设置为超链接,放在此处表明了多对多关系设置在超链接列中无效
value = mark_safe('<a href="%s/change/">%s</a>' % (model_obj.pk, value))
except Exception as e:
#print e
value = getattr(model_obj, field)
else:
value = field(self.model_config, model_obj) # 获取内容,传入model_obj,不用传入isHeader
if value:
row_list.append(value)
data_list.append(row_list)
# print data_list
return data_list
2.4 增加自定义的url 路径
可以为某个model表单独增加一个url接口,来处理特殊的业务;首先需要在site.py 文件中定义接口,然后在app的admin.py注册文件中进行定义处理逻辑。在下面的代码中model表通过覆盖父类的extra_urls()函数来增加了一条url和相应的处理逻辑。
site.py定义的接口如下:
def get_urls(self):
patterns = [url(r'^$', self.list_view, name='%s_%s_list'%(self.model_name,self.app_label)),
url(r'^add/$', self.add_view,name='%s_%s_add'%(self.model_name,self.app_label)),
url(r'^(.+)/change/$', self.change_view,name='%s_%s_change'%(self.model_name,self.app_label)),
url(r'^(.+)/delete/$', self.delete_view,name='%s_%s_delete'%(self.model_name,self.app_label)),
]
patterns.extend(self.extra_url())
return patterns
#定义url接口,modelConfigure通过继承覆盖来配置额外的url
def extra_url(self):
return []
admin.py 定义处理逻辑如下:
class BookConfig(ModelAdmin):
# 通过下面三个函数,为book添加一条单独的url处理逻辑,实现点击id值,为title添加喜欢或不喜欢
def list_id(self,model_obj=None, isHeader=False):
if isHeader:
return 'ID'
return mark_safe('<a href="like_book/%s">%s</a>'%(model_obj.pk, model_obj.pk))
def like_book(self,request,obj_id):
model_obj = models.Book.objects.get(id = obj_id)
if '(喜欢)' not in model_obj.title:
new_title = '%s (喜欢)'%model_obj.title
else:
new_title = model_obj.title.replace('(喜欢)','')
models.Book.objects.filter(id=obj_id).update(title = new_title)
return redirect(self.get_list_url())
def extra_url(self):
temp = [url(r'like_book/(\d+)',self.like_book)]
return temp
list_display = (list_id, 'title','price','author','publish')
site.register(models.Book,BookConfig)
3 总结
通过上述部分,实现了一个完成的后台管理系统,有两个小特色,一是插拔式,方便在其他项目中进行复用;二是代码中保留了扩展字段和自定义url接口,能够根据不同的业务需求扩展特殊的功能。项目源代码及基本使用见下面github。
项目源代码: https://github.com/silence-cho/Myadmin
可插拔式后台管理系统(Django)的更多相关文章
- Django学习(四) Django提供的后台管理系统以及如何定义URL路由
一旦你建立了模型Models,那么Django就可以为你创建一个专业的,可以提供给生成用的后台管理站点.这个站点可以提供给有权限的人进行已有模型Models数据的增删改查. 将新建的模型Models是 ...
- Django后台管理系统讲解及使用
大家在创建Django项目后,在根路由urls.py文件中,会看到一行代码 from django.contrib import admin urlpatterns = [ url(r'^admin/ ...
- 4、Django实战第4天:xadmin快速搭建后台管理系统
Django默认为我们提供了后台管理系统admin, urls.py中配置的第一条就是访问后台管理系统admin的 urlpatterns = [ url(r'^admin/', admin.site ...
- django后台管理系统(admin)的简单使用
目录 django后台管理系统的使用 检查配置文件 检查根urls.py文件 启动项目,浏览器输入ip端口/admin 如: 127.0.0.1/8000/admin 回车 注册后台管理系统超级管理 ...
- 【tips】xadmin - django第三方后台管理系统
Django 为大家提供了一个完善的后台管理系统—admin,但是这个后台管理系统总体来说不太适合国人的习惯,所以有大神就使用 bootstrap 和 jQuery,为我们开发了一个第三 方的 Dja ...
- Django后台管理系统的使用
目录 django后台管理系统的使用 检查配置文件 检查根urls.py文件 启动项目,浏览器输入ip端口/admin 如: 127.0.0.1/8000/admin 回车 注册后台管理系统超级管理 ...
- Django的后台管理系统Admin(5)
Django的后台管理系统就是为了方便管理员管理网站,所以django自带了一个后台管理系统,接下来记录一下如何使用这个后台的管理系统. 首先我们要进入后台管理系统,就要有一个管理员的账号,先来创建有 ...
- pycharm(pythoon3)_django2.0_xadmin创建测试用例后台管理系统
1.测试用例的app名字:Testcase 2.Testcase文件夹下各个文件的代码: 2.1. __init__.py: default_app_config = "TestCase.a ...
- xadmin快速搭建后台管理系统
一.xadmin的特点: 1.基于Bootstrap3:Xadmin使用Bootstrap3.0框架精心打造.基于Bootstrap3,Xadmin天生就支持在多种屏幕上无缝浏览,并完全支持Boots ...
随机推荐
- JS原生实现照片抽奖
HTML表格标记实现九宫格,放入九张图片.利用CSS的滤镜属性控制图片的透明度.Javascript实现抽奖和中奖. 可以做为教师上课,随机抽取回答问题的同学,使学生感受到随机的公平性,简单有趣! 点 ...
- 温度传感器 DS18B20
1. 实物图 2. 64位(激)光刻只读存储器 开始8位(28H)是产品类型标号,接着的48位是该DS18B20自身的序列号,最后8位是前面56位的循环冗余校验码 光刻ROM的作用是使每一个DS18B ...
- 使用FindCmdLineSwitch处理命令行参数
一.四个形式(变体) .function FindCmdLineSwitch(const Switch: string; const Chars: TSysCharSet; IgnoreCase: B ...
- MySQL的sql_mode参数之NO_AUTO_VALUE_ON_ZERO对主键ID为0的记录影响
最近遇到一个不合理使用数据库进行项目开发最终导致项目进度受阻的一个问题,某天几位开发人员找到我并告知数据库中某张表数据无法写入,又告知某行记录被删除了,因为被删除的记录对开发框架影响很大,他们已尝试重 ...
- 【2017-06-02】Linq高级查询,实现分页组合查询。
1.以XXX开头 2.以XXX结尾 3.模糊查询 4.求个数 5.求最大值 6.求最小值 7.求平均值 8.求和 9.升序 10.降序 11.分页 Skip()跳过多少条 Take()取多少条 12. ...
- C# 一个数组集合,任意组合,不遗漏,不重复
using System; using System.Collections.Generic; using System.Diagnostics; using System.Linq; using S ...
- jemeter生成测试报告
Jmeter生成测试报告 相对于Loadrunner,Jmeter其实也是可以有测试报告产出的,虽然一般都不用(没有Loadrunner的报告那么强大是一方面),还是顺手写一下吧,其实方法在用命令 ...
- 关于C++编译时内链接和外链接
最近在阅读<大规模C++ 程序设计> 在第1部分,作者讨论了内链接和外链接问题(因为大规模的C++程序有繁多的类和单元.因此编译速度是个大问题) 这里记录一下关于内链接和外链接的理解. ...
- 如何在SpringBoot的 过滤器之中注入Bean对象
我建立一个全局拦截器,此拦截器主要用于拦截APP用户登录和请求API时候,必须加密,我把它命名为SecurityFilter,它继承了Filter,web应用启动的顺序是:listener->f ...
- (二)线程Thread中的方法详解
1.start() start()方法的作用讲得直白点就是通知"线程规划器",此线程可以运行了,正在等待CPU调用线程对象得run()方法,产生一个异步执行的效果.通过start( ...