Elasticsearch(ELK)集群搭建
一、前言
Elasticsearch是一个开源的高扩展的分布式全文检索引擎,它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理PB级别的数据。Elasticsearch也使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单。
二、准备
2.1、机器环境准备
我们准备3台机器,并都装好JDK且设置好hostname。
| 机器IP | hostname |
| 192.168.182.132 | node-1 |
| 192.168.182.133 | node-2 |
| 192.168.182.134 | node-3 |
2.2、创建elsearch用户(Linux 下不要使用 root 用户运行 Elasticsearch, 否则会报异常 can not run elasticsearch as root)
# 创建用户组
groupadd elsearch # 创建用户,-p : 登录密码
useradd elsearch -g elsearch -p elsearch
三、搭建
3.1、下载并安装
官网下载:https://www.elastic.co/cn/downloads/elasticsearch
# 下载
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.4.2-linux-x86_64.tar.gz
# 解压
tar zxvf elasticsearch-7.4.2-linux-x86_64.tar.gz && cd elasticsearch-7.4.2/ # 切换用户组:所有者,跟上面创建的用户相对应
chown -R elsearch:elsearch .
3.2、修改配置文件以支持集群
.注意修改network.host为各节点IP地址
.注意修改discovery.zen.ping.unicast.hosts列表
备份:
cp -a config/elasticsearch.yml config/elasticsearch.yml.bak
配置:
cat <<EOF >>/etc/elasticsearch/elasticsearch.yml
## 集群名称
cluster.name: my-cs-cluster ## 节点名称(每个节点名称不能相同)
node.name: 'node-1' ## 允许 JVM 锁住内存,禁止操作系统交换出去
# bootstrap.memory_lock: true ## 是否有资格成为主节点
## 通过 node.master 可以配置该节点是否有资格成为主节点,如果配置为 true,则主机有资格成为主节点
## 注意这里是有资格成为主节点,不是一定会成为主节点
node.master: true ## 是否是数据节点
## 当 node.master 和 node.data 均为 false,则该主机会作为负载均衡节点
node.data: true ## 设置访问的地址和端口
network.host: 192.168.182.132
http.port: 9200 ## 集群地址设置
## 配置之后集群的主机之间可以自动发现
discovery.zen.ping.unicast.hosts: ["192.168.182.132", "192.168.182.133", "192.168.182.134"] # 参数设置一系列符合主节点条件的节点的主机名或 IP 地址来引导启动集群。手动指定可以成为 mater 的所有节点的 name 或者 ip,这些配置将会在第一次选举中进行计算
# cluster.initial_master_nodes: ["node-1"] # 配置集群的主机地址,配置之后集群的主机之间可以自动发现(可选项)
# discovery.seed_hosts: ["192.168.182.132:9300","192.168.182.133:9300","192.168.182.134:9300"] # 配置初始化集群的master节点,node.name的值
# cluster.initial_master_nodes: ["node-1"] ## 配置大多数节点(通常为主节点的节点总数/ 2 + 1)来防止“裂脑”:
discovery.zen.minimum_master_nodes: ## 在完全集群重启后阻止初始恢复,直到启动N个节点
gateway.recover_after_nodes: # 外网访问设置
http.cors.enabled: true
# 注意:*最好加上引号,要不然6.x版本肯能启动不了
http.cors.allow-origin: '*' EOF
vim /etc/elasticsearch/elasticsearch.yml
四、启动出现的问题及解决方案
4.1、JDK版本过低
报错信息:
OpenJDK -Bit Server VM warning: Option UseConcMarkSweepGC was deprecated in version 9.0 and will likely be removed in a future release.
[--04T00::,][WARN ][o.e.b.ElasticsearchUncaughtExceptionHandler] [node-] uncaught exception in thread [main]
org.elasticsearch.bootstrap.StartupException: java.lang.RuntimeException: can not run elasticsearch as root
at org.elasticsearch.bootstrap.Elasticsearch.init(Elasticsearch.java:) ~[elasticsearch-7.4..jar:7.4.]
at org.elasticsearch.bootstrap.Elasticsearch.execute(Elasticsearch.java:) ~[elasticsearch-7.4..jar:7.4.]
at org.elasticsearch.cli.EnvironmentAwareCommand.execute(EnvironmentAwareCommand.java:) ~[elasticsearch-7.4..jar:7.4.]
at org.elasticsearch.cli.Command.mainWithoutErrorHandling(Command.java:) ~[elasticsearch-cli-7.4..jar:7.4.]
at org.elasticsearch.cli.Command.main(Command.java:) ~[elasticsearch-cli-7.4..jar:7.4.]
at org.elasticsearch.bootstrap.Elasticsearch.main(Elasticsearch.java:) ~[elasticsearch-7.4..jar:7.4.]
at org.elasticsearch.bootstrap.Elasticsearch.main(Elasticsearch.java:) ~[elasticsearch-7.4..jar:7.4.]
Caused by: java.lang.RuntimeException: can not run elasticsearch as root
at org.elasticsearch.bootstrap.Bootstrap.initializeNatives(Bootstrap.java:) ~[elasticsearch-7.4..jar:7.4.]
at org.elasticsearch.bootstrap.Bootstrap.setup(Bootstrap.java:) ~[elasticsearch-7.4..jar:7.4.]
at org.elasticsearch.bootstrap.Bootstrap.init(Bootstrap.java:) ~[elasticsearch-7.4..jar:7.4.]
at org.elasticsearch.bootstrap.Elasticsearch.init(Elasticsearch.java:) ~[elasticsearch-7.4..jar:7.4.]
... more
解决:下载安装OpenJDK11
wget https://download.java.net/java/GA/jdk11/13/GPL/openjdk-11.0.1_linux-x64_bin.tar.gz
tar -xzvf jdk-11.0.4_linux-x64_bin.tar.gz /opt/
修改ES启动脚本加上jdk11的配置:
为了方便大家参考,这里贴上完整的配置文件
#!/bin/bash # CONTROLLING STARTUP:
#
# This script relies on a few environment variables to determine startup
# behavior, those variables are:
#
# ES_PATH_CONF -- Path to config directory
# ES_JAVA_OPTS -- External Java Opts on top of the defaults set
#
# Optionally, exact memory values can be set using the `ES_JAVA_OPTS`. Note that
# the Xms and Xmx lines in the JVM options file must be commented out. Example
# values are "512m", and "10g".
#
# ES_JAVA_OPTS="-Xms8g -Xmx8g" ./bin/elasticsearch # 配置自己的jdk11
export JAVA_HOME=/home/elsearch/jdk-11.0.1
export PATH=$JAVA_HOME/bin:$PATH source "`dirname "$"`"/elasticsearch-env if [ -z "$ES_TMPDIR" ]; then
ES_TMPDIR=`"$JAVA" -cp "$ES_CLASSPATH" org.elasticsearch.tools.launchers.TempDirectory`
fi ES_JVM_OPTIONS="$ES_PATH_CONF"/jvm.options
JVM_OPTIONS=`"$JAVA" -cp "$ES_CLASSPATH" org.elasticsearch.tools.launchers.JvmOptionsParser "$ES_JVM_OPTIONS"`
ES_JAVA_OPTS="${JVM_OPTIONS//\$\{ES_TMPDIR\}/$ES_TMPDIR}" # 添加jdk判断
if [ -x "$JAVA_HOME/bin/java" ]; then
JAVA="/home/elsearch/jdk-11.0.1/bin/java"
else
JAVA=`which java`
fi # manual parsing to find out, if process should be detached
if ! echo $* | grep -E '(^-d |-d$| -d |--daemonize$|--daemonize )' > /dev/null; then
exec \
"$JAVA" \
$ES_JAVA_OPTS \
-Des.path.home="$ES_HOME" \
-Des.path.conf="$ES_PATH_CONF" \
-Des.distribution.flavor="$ES_DISTRIBUTION_FLAVOR" \
-Des.distribution.type="$ES_DISTRIBUTION_TYPE" \
-Des.bundled_jdk="$ES_BUNDLED_JDK" \
-cp "$ES_CLASSPATH" \
org.elasticsearch.bootstrap.Elasticsearch \
"$@"
else
exec \
"$JAVA" \
$ES_JAVA_OPTS \
-Des.path.home="$ES_HOME" \
-Des.path.conf="$ES_PATH_CONF" \
-Des.distribution.flavor="$ES_DISTRIBUTION_FLAVOR" \
-Des.distribution.type="$ES_DISTRIBUTION_TYPE" \
-Des.bundled_jdk="$ES_BUNDLED_JDK" \
-cp "$ES_CLASSPATH" \
org.elasticsearch.bootstrap.Elasticsearch \
"$@" \
<&- &
retval=$?
pid=$!
[ $retval -eq ] || exit $retval
if [ ! -z "$ES_STARTUP_SLEEP_TIME" ]; then
sleep $ES_STARTUP_SLEEP_TIME
fi
if ! ps -p $pid > /dev/null ; then
exit
fi
exit
fi exit $?
3.2、配置过低
[]: max file descriptors [] for elasticsearch process is too low, increase to at least []
[]: max virtual memory areas vm.max_map_count [] is too low, increase to at least []
解决:
- 文件描述符配置
- 临时生效
- 使用
root用户 - 运行
ulimit -n 65536
- 使用
- 永久生效
- 使用
root用户 - 进入
/etc/security/limits.conf - 添加
* hard nofile 65536
* hard nofile 65536
- 使用
- 临时生效
- 虚拟内存配置
- 临时生效
- 使用
root用户 - 运行
sysctl -w vm.max_map_count=262144
- 使用
- 永久生效
- 使用
root用户 - 进入
/etc/sysctl.conf - 添加或更新一行
vm.max_map_count=262144
- 使用
- 临时生效
- 自动发现配置
- 单节点
- 进入 elasticsearch 安装目录,打开 config/elasticsearch.yml
- 添加或更新一行
discovery.type: single-node
3.3、JVM内存大小指定太大,但本机内存不够用
[root@file elasticsearch-7.1.]# ./bin/elasticsearch
Java HotSpot(TM) -Bit Server VM warning: INFO: os::commit_memory(0x00000000c5330000, , ) failed; error='Cannot allocate memory' (errno
#
# There is insufficient memory for the Java Runtime Environment to continue.
# Native memory allocation (mmap) failed to map bytes for committing reserved memory.
# An error report file with more information is saved as:
# logs/hs_err_pid27766.log
解决:
# 修改jvm.options文件配置即可,从1g改成了100m # Xms represents the initial size of total heap space
# Xmx represents the maximum size of total heap space -Xms100m
-Xmx100m
五、安装elasticsearch-head
5.1、下载安装
# 下载
wget https://github.com/mobz/elasticsearch-head.git # 解压
unzip elasticsearch-head-master.zip && cd elasticsearch-head-master
# 安装npminstallgrunt --save
修改服务器监听地址
修改elasticsearch-head下Gruntfile.js文件,默认监听在127.0.0.1下9200端口

或者修改 elasticsearch-head-master/Gruntfile.js,在connect属性中,增加hostname: ‘0.0.0.0’
修改连接地址
cd _site
vim app.js
this.base_uri = this.config.base_uri || this.prefs.get("app-base_uri") || "http://localhost:9200";
启动
#执行
grunt server
输出
>> Local Npm module "grunt-contrib-jasmine" not found. Is it installed? Running "connect:server" (connect) task
Waiting forever...
Started connect web server on http://localhost:9100
浏览器访问
http://192.168.182.132:9100
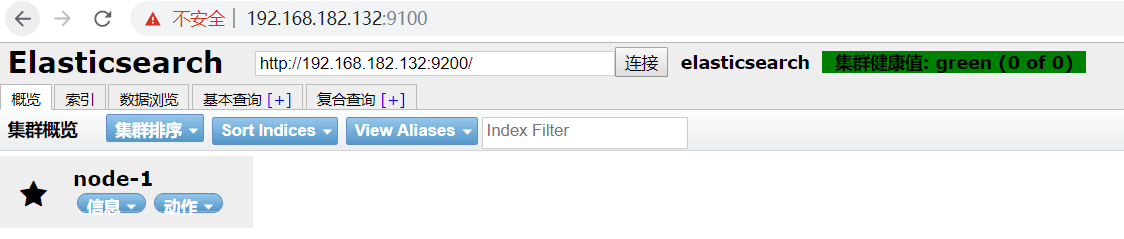
elasticsearch-head 设置后台启动和关闭
启动
进入elasticsearch-head-master目录
# vim elasticsearch-head_start.sh #!/bin/bash
echo "START elasticsearch-head "
nohup grunt server &exit
关闭
#!/bin/bash
echo "STOP elasticsearch-head "
ps -ef |grep head|awk '{print $2}'|xargs kill -
六、安装Kibana
6.1、下载
官网下载:https://www.elastic.co/cn/downloads/kibana
6.2、安装
wget https://artifacts.elastic.co/downloads/kibana/kibana-7.4.2-linux-x86_64.tar.gz tar -zxvf kibana-7.4.-linux-x86_64.tar.gz && cd kibana-7.4.-linux-x86_64
6.3、修改配置
# vi config/kibana.yml
# 允许外部访问
server.host: "0.0.0.0" # 修改默认关联的ES地址
elasticsearch.hosts: ["http://192.168.182.132:9200"]
6.4、启动
# 默认不支持root启动,可以后面加参数允许root启动
./kibana --allow-root
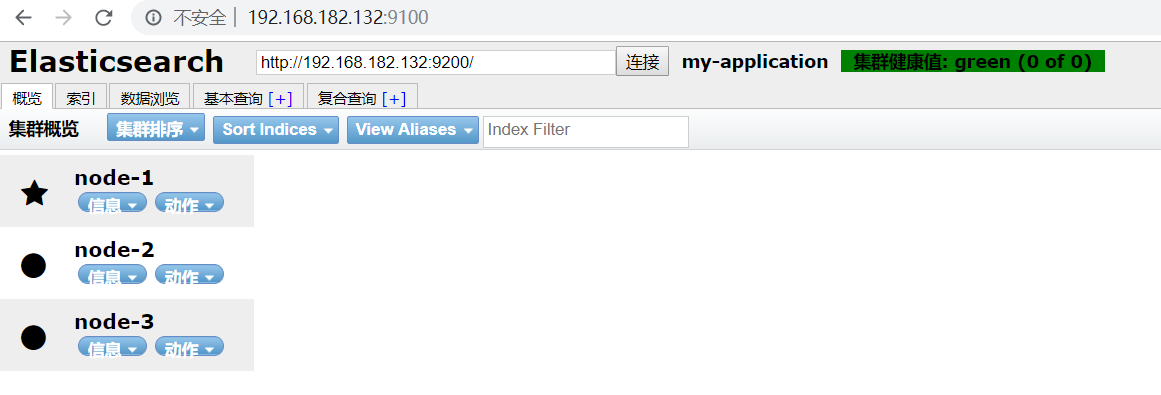
六、在另外两台机子上安装ES
6.1、拷贝
scp -r /home/elsearch/elasticsearch-7.4. root@192.168.182.133:/home/elsearch/ scp -r /home/elsearch/elasticsearch-7.4. root@192.168.182.134:/home/elsearch/
6.2、修改配置
# 修改节点名称
node.name: "node-2" # node- # 修改节点属性
node.master: false # 修改能访问的ip地址
network.host: "192.168.182.133" # network.host: "192.168.182.134"
6.3、修改配置,跟上面的master机子一样的设置
6.4、如果有如下报错
[node-] failed to send join request to master [{node-}{WbcP0pC_T32jWpYvu5is1A}{2_LCVHx1QEaBZYZ7XQEkMg}{10.10.11.200}{10.10.11.200:}], reason [RemoteTransportException[[node-][10.10.11.200:][internal:discovery/zen/join]]; nested: IllegalArgumentException[can't add node {node-2}{WbcP0pC_T32jWpYvu5is1A}{p-HCgFLvSFaTynjKSeqXyA}{10.10.11.200}{10.10.11.200:9301}, found existing node {node-1}{WbcP0pC_T32jWpYvu5is1A}{2_LCVHx1QEaBZYZ7XQEkMg}{10.10.11.200}{10.10.11.200:9300} with the same id but is a different node instance]; ]
解决:
# 停止ES 清空/data cd data/
rm -rf *
通过以上安装配置,ES集群就搭建起来了
最后附上配置完整说明:
cluster.name: elasticsearch
# 配置的集群名称,默认是elasticsearch,es服务会通过广播方式自动连接在同一网段下的es服务,通过多播方式进行通信,同一网段下可以有多个集群,通过集群名称这个属性来区分不同的集群。 node.name: "Franz Kafka"
# 当前配置所在机器的节点名,你不设置就默认随机指定一个name列表中名字,该name列表在es的jar包中config文件夹里name.txt文件中,其中有很多作者添加的有趣名字。 node.master: true
# 指定该节点是否有资格被选举成为node(注意这里只是设置成有资格, 不代表该node一定就是master),默认是true,es是默认集群中的第一台机器为master,如果这台机挂了就会重新选举master。 node.data: true
# 指定该节点是否存储索引数据,默认为true。 index.number_of_shards:
# 设置默认索引分片个数,默认为5片。 index.number_of_replicas:
# 设置默认索引副本个数,默认为1个副本。如果采用默认设置,而你集群只配置了一台机器,那么集群的健康度为yellow,也就是所有的数据都是可用的,但是某些复制没有被分配
# (健康度可用 curl 'localhost:9200/_cat/health?v' 查看, 分为绿色、黄色或红色。绿色代表一切正常,集群功能齐全,黄色意味着所有的数据都是可用的,但是某些复制没有被分配,红色则代表因为某些原因,某些数据不可用)。 path.conf: /path/to/conf
# 设置配置文件的存储路径,默认是es根目录下的config文件夹。 path.data: /path/to/data
# 设置索引数据的存储路径,默认是es根目录下的data文件夹,可以设置多个存储路径,用逗号隔开,例:
# path.data: /path/to/data1,/path/to/data2 path.work: /path/to/work
# 设置临时文件的存储路径,默认是es根目录下的work文件夹。 path.logs: /path/to/logs
# 设置日志文件的存储路径,默认是es根目录下的logs文件夹 path.plugins: /path/to/plugins
# 设置插件的存放路径,默认是es根目录下的plugins文件夹, 插件在es里面普遍使用,用来增强原系统核心功能。 bootstrap.mlockall: true
# 设置为true来锁住内存不进行swapping。因为当jvm开始swapping时es的效率 会降低,所以要保证它不swap,可以把ES_MIN_MEM和ES_MAX_MEM两个环境变量设置成同一个值,并且保证机器有足够的内存分配给es。 同时也要允许elasticsearch的进程可以锁住内# # 存,linux下启动es之前可以通过`ulimit -l unlimited`命令设置。 network.bind_host: 192.168.0.1
# 设置绑定的ip地址,可以是ipv4或ipv6的,默认为0.0.0.0,绑定这台机器的任何一个ip。 network.publish_host: 192.168.0.1
# 设置其它节点和该节点交互的ip地址,如果不设置它会自动判断,值必须是个真实的ip地址。 network.host: 192.168.0.1
# 这个参数是用来同时设置bind_host和publish_host上面两个参数。 transport.tcp.port:
# 设置节点之间交互的tcp端口,默认是9300。 transport.tcp.compress: true
# 设置是否压缩tcp传输时的数据,默认为false,不压缩。 http.port:
# 设置对外服务的http端口,默认为9200。 http.max_content_length: 100mb
# 设置内容的最大容量,默认100mb http.enabled: false
# 是否使用http协议对外提供服务,默认为true,开启。 gateway.type: local
# gateway的类型,默认为local即为本地文件系统,可以设置为本地文件系统,分布式文件系统,hadoop的HDFS,和amazon的s3服务器等。 gateway.recover_after_nodes:
# 设置集群中N个节点启动时进行数据恢复,默认为1。 gateway.recover_after_time: 5m
# 设置初始化数据恢复进程的超时时间,默认是5分钟。 gateway.expected_nodes:
# 设置这个集群中节点的数量,默认为2,一旦这N个节点启动,就会立即进行数据恢复。 cluster.routing.allocation.node_initial_primaries_recoveries:
# 初始化数据恢复时,并发恢复线程的个数,默认为4。 cluster.routing.allocation.node_concurrent_recoveries:
# 添加删除节点或负载均衡时并发恢复线程的个数,默认为4。 indices.recovery.max_size_per_sec:
# 设置数据恢复时限制的带宽,如入100mb,默认为0,即无限制。 indices.recovery.concurrent_streams:
# 设置这个参数来限制从其它分片恢复数据时最大同时打开并发流的个数,默认为5。 discovery.zen.minimum_master_nodes:
# 设置这个参数来保证集群中的节点可以知道其它N个有master资格的节点。默认为1,对于大的集群来说,可以设置大一点的值(2-4) discovery.zen.ping.timeout: 3s
# 设置集群中自动发现其它节点时ping连接超时时间,默认为3秒,对于比较差的网络环境可以高点的值来防止自动发现时出错。 discovery.zen.ping.multicast.enabled: false
# 设置是否打开多播发现节点,默认是true。 discovery.zen.ping.unicast.hosts: ["host1", "host2:port", "host3[portX-portY]"]
# 设置集群中master节点的初始列表,可以通过这些节点来自动发现新加入集群的节点。
elasticsearch7版本引入的新集群协调子系统了解一哈,新增两个如下配置项
discovery.seed_hosts
cluster.initial_master_nodes
官方文档栗子:
discovery.seed_hosts:
- 192.168.1.10:
- 192.168.1.11
- seeds.mydomain.com
cluster.initial_master_nodes:
- master-node-a
- master-node-b
- master-node-c
七、与数据导入
7.1、下载
wget https://artifacts.elastic.co/downloads/logstash/logstash-7.4.2.tar.gz
7.2、解压
tar -zxf logstash-7.4..tar.gz && cd logstash-7.4.
7.3、到 grouplens 下载 MovieLens 测试数据集
wget http://files.grouplens.org/datasets/movielens/ml-latest-small.zip
7.4、解压测试数据集
unzip ml-latest-small.zip && cd ml-latest-small
7.5、创建并编辑 logstash.conf 文件,添加如下内容(Ruby 语法)
input {
file {
path => "/home/elsearch/ml-latest-small/movies.csv"
start_position => "beginning"
sincedb_path => "/dev/null"
}
}
filter {
csv {
separator => ","
columns => ["id","content","genre"]
}
mutate {
split => { "genre" => "|" }
remove_field => ["path", "host","@timestamp","message"]
}
mutate {
split => ["content", "("]
add_field => { "title" => "%{[content][0]}"}
add_field => { "year" => "%{[content][2]}"}
}
mutate {
convert => {
"year" => "integer"
}
strip => ["title"]
remove_field => ["path", "host","@timestamp","message","content"]
}
}
output {
elasticsearch {
hosts => "http://192.168.182.132:9200"
index => "movies"
document_id => "%{id}"
}
stdout {}
}
7.6、导入数据,注意导入后不会自动退出,用 Ctrl-C 手动退出
./bin/logstash -f ../ml-latest-small/logstash.conf
7.7、Management 查看数据(Index 相当于关系型数据库的 Table)
Elasticsearch(ELK)集群搭建的更多相关文章
- ELK集群搭建
基于5台虚拟机,搭建ELK集群. 方案: 1. ELK是日志分析平台,而不是一款软件,是一整套解决方案,是三个软件产品的首字母缩写,ELK分别代表: Elasticsearch:负责日志检索和储存 L ...
- elasticsearch 分布式集群搭建
elasticsearch环境搭建及单节点搭建可参考我的上一篇:http://www.cnblogs.com/xuwenjin/p/8745624.html 本文以Elaticsearch 6.2.2 ...
- 【7.1.1】ELK集群搭建 之 ES集群
写在前边 昨天晚上就已经完成这篇博客了,就是在测试这块是否正常跑起来,晚上没搞完,上班前把电脑关机带着,结果没保存!基本上昨天写的东西都丢了,好在博客园的图片url还在. 为了让大家都轻松些,我轻松写 ...
- Elasticsearch冷热集群搭建
ES版本:6.2.4 集群环境:7台机器,每台部署一个master节点.其中3台部署2个hot节点,另外4台部署2个warm节点.共21个节点. 1. 挂盘 按实际情况分盘,一个机子上的2个data节 ...
- ElasticSearch入门 —— 集群搭建
一.环境介绍与安装准备 1.环境说明 2台虚拟机,OS为ubuntu13.04,ip分别为xxx.xxx.xxx.140和xxx.xxx.xxx.145. 2.安装准备 ElasticSearch(简 ...
- 使用 docker 进行 ElasticSearch + Kibana 集群搭建
在Docker容器中运行Elasticsearch Kibana和Cerebro 机器信息 10.160.13.139 10.160.9.162 10.160.11.171 1. 安装docker和d ...
- 搭建Elk集群搭建 ES-filebeat-logstrash-kibana
一 .基础环境 软件 版本 作用 Linux/Win Server2012 CentOs/Win Server2012 服务器环境 JDK 1.8.0_151 运行环境依赖 Elasticsearch ...
- 通过docker搭建ELK集群
单机ELK,另外两台服务器分别有一个elasticsearch节点,这样形成一个3节点的ES集群. 可以先尝试单独搭建es集群或单机ELK https://www.cnblogs.com/lz0925 ...
- 搭建ELK日志分析平台(上)—— ELK介绍及搭建 Elasticsearch 分布式集群
笔记内容:搭建ELK日志分析平台(上)-- ELK介绍及搭建 Elasticsearch 分布式集群笔记日期:2018-03-02 27.1 ELK介绍 27.2 ELK安装准备工作 27.3 安装e ...
随机推荐
- 利用k8s实现HPA
如何利用kubernetes实现应用的水平扩展(HPA) 云计算具有水平弹性的特性,这个是云计算区别于传统IT技术架构的主要特性.对于Kubernetes中的POD集群来说,HPA就是实现这种水平伸缩 ...
- mybatis3.1-[topic-18-20]-_映射文件_参数处理_单个参数&多个参数&命名参数 _POJO&Map&TO 三种方式及举例
笔记要点出错分析与总结 /**MyBatis_映射文件_参数处理_单个参数&多个参数&命名参数 * _POJO&Map&TO 三种方式及举例 _ * 单个参数 : #{ ...
- Redis vs kafka
kafka的订阅可以重复消费,但redis的不行,只能收到订阅之后发布的数据 redis无法实现消息堆积和回溯 1 Redis是个数据库,可以改.查,而KFAKA 不能改查2 redis是内存数据库, ...
- mysql双主模式方案
MySQL双主(主主)架构方案 在企业中,数据库高可用一直是企业的重中之重,中小企业很多都是使用mysql主从方案,一主多从,读写分离等,但是单主存在单点故障,从库切换成主库需要作改动.因此,如果 ...
- 2019-2020-1 20199312《Linux内核原理与分析》第四周作业
计算机和操作系统的法宝 计算机三个法宝 存储程序计算机.函数调用堆栈机制.中断 操作系统:中断中断上下文的切换--保护和恢复现场 进程上下文的切换. Linux源代码目录分析 arch目录:代码量庞大 ...
- 46、[源码]-Spring容器创建-注册BeanPostProcessors
46.[源码]-Spring容器创建-注册BeanPostProcessors 6.registerBeanPostProcessors(beanFactory);注册BeanPostProcesso ...
- MessageDigest的功能及用法
MessageDigest 类为应用程序提供信息摘要算法的功能,如 MD5 或 SHA 算法.信息摘要是安全的单向哈希函数,它接收任意大小的数据,并输出固定长度的哈希值. MessageDigest ...
- Codeforces Round #438 by Sberbank and Barcelona Bootcamp (Div. 1 + Div. 2 combined) A,B,C【真的菜·】
8说了 #include<bits/stdc++.h> using namespace std; #define int long long signed main(){ string s ...
- sql server 事务和锁的作用
事务 事务就是作为一个逻辑工作单元的SQL语句,如果任何一个语句操作失败那么整个操作就被失败,以后操作就会回滚到操作前状态,或者是上个节点.为了确保要么执行,要么不执行,就可以使用事务.而锁是实现事务 ...
- codeforces#1249F. Maximum Weight Subset(树上dp)
题目链接: http://codeforces.com/contest/1249/problem/F 题意: 一棵树的每个节点有个权值,选择一个节点集,使得任意点对的距离大于$k$ 求最大节点集权值, ...