DB 分库分表的基本思想和切分策略
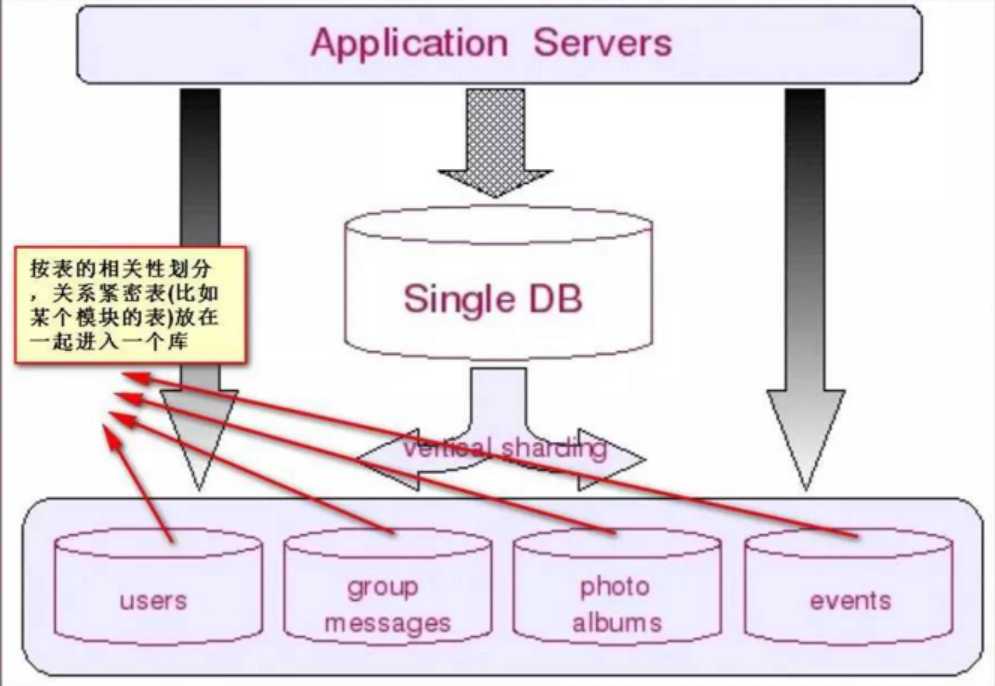

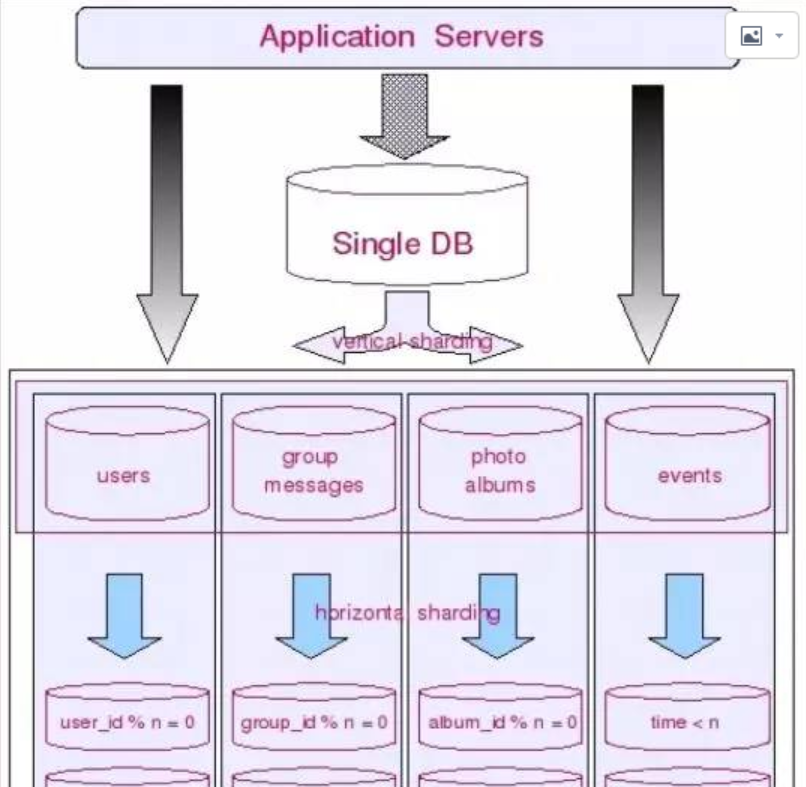

- 若划归到一起的表格关系紧密,且数据量并不大,增速也非常缓慢,则适宜放在一个shard里,不需要再进行水平切分;
- 若划归到一起的表格数据量巨大且增速迅猛,则势必要在垂直切分的基础上再进行水平切分,水平切分就意味着原单一shard会被细分成多个更小的shard,每一个shard存在一个主表(即会以该表ID进行散列的表)和多个相之相关的关联表。
DB 分库分表的基本思想和切分策略的更多相关文章
- DB 分库分表(5):一种支持自由规划无须数据迁移和修改路由代码的 Sharding 扩容方案
作为一种数据存储层面上的水平伸缩解决方案,数据库Sharding技术由来已久,很多海量数据系统在其发展演进的历程中都曾经历过分库分表的Sharding改造阶段.简单地说,Sharding就是将原来单一 ...
- DB 分库分表(1):拆分实施策略和示例演示
DB 分库分表(1):拆分实施策略和示例演示 第一部分:实施策略 1.准备阶段 对数据库进行分库分表(Sharding化)前,需要开发人员充分了解系统业务逻辑和数据库schema.一个好的建议是绘制一 ...
- DB 分库分表(2):全局主键生成策略
DB 分库分表(2):全局主键生成策略 本文将主要介绍一些常见的全局主键生成策略,然后重点介绍flickr使用的一种非常优秀的全局主键生成方案.关于分库分表(sharding)的拆分策略和实施细则,请 ...
- 转数据库分库分表(sharding)系列(一) 拆分实施策略和示例演示
本文原文连接: http://blog.csdn.net/bluishglc/article/details/7696085 ,转载请注明出处!本文着重介绍sharding切分策略,如果你对数据库sh ...
- 数据库分库分表(sharding)系列(一)拆分实施策略和示例演示
本文原文连接: http://blog.csdn.net/bluishglc/article/details/7696085 ,转载请注明出处!本文着重介绍sharding切分策略,如果你对数据库sh ...
- 据库分库分表(sharding)系列(一) 拆分实施策略和示例演示
本文原文连接: http://blog.csdn.net/bluishglc/article/details/7696085 ,转载请注明出处!本文着重介绍sharding切分策略,如果你对数据库sh ...
- DB 分库分表(3):关于使用框架还是自主开发以及 sharding 实现层面的考量
当团队对系统业务和数据库进行了细致的梳理,确定了切分方案后,接下来的问题就是如何去实现切分方案了,目前在sharding方面有不少的开源框架和产品可供参考,同时很多团队也会选择自主开发实现,而不管是选 ...
- DB 分库分表(4):多数据源的事务处理
系统经sharding改造之后,原来单一的数据库会演变成多个数据库,如何确保多数据源同时操作的原子性和一致性是不得不考虑的一个问题.总体上看,目前对于一个分布式系统的事务处理有三种方式:分布式事务.基 ...
- Mysql系列四:数据库分库分表基础理论
一.数据处理分类 1. 海量数据处理,按照使用场景主要分为两种类型: 联机事务处理(OLTP) 面向交易的处理系统,其基本特征是原始数据可以立即传送到计算机中心进行处理,并在很短的时间内给出处理结果. ...
随机推荐
- wabacus JaveEE开发框架
http://www.wabacus.org/ css学习网站:http://www.divcss5.com/rumen/r422.shtml
- JavaMaven【五、Maven集成Eclipse使用】
创建Maven项目 右键->new->other(Ctrl+n)->Maven Project->quickStart(catalog) 执行指令 右键->Run As- ...
- 开源you-get项目爬虫,以及基于python+selenium的自动测试利器
写在前面 爬虫和自动测试,对于python来说是最合适不过也是最擅长的. 开源的项目也很多,例如you-get项目https://github.com/soimort/you-get.盗链和爬虫神器. ...
- shell脚本中使用nohup执行命令不生效
1 例如 !#/bin/bash nohup echo "hello world" 2 解决办法 加上 source /etc/profile 就好了 !#/bin/bash so ...
- STM32 ARM调试问题总结
文章转载自:http://xfjane.spaces.eepw.com.cn/articles/article/item/77908 基于ADS的ARM调试有关问题总结 1. 在添加文件的过程中你可 ...
- 在values中添加colors.xml
如何在values中添加colors.xml文件?按钮上的文字,背景色的动态变化的xml放在res/drawable里,现在我就说静态的xml文件吧. res/values/colors.xml< ...
- linux 命令技巧(转)--history
本文介绍一些关于bash的能够提高效率的技巧,主要是关于历史命令操作和一些快捷键,让你在命令行下工作效率翻倍. 1.history-----最基本的查看历史命令 2.!n-----编号为n的历史命令 ...
- 数据防泄密(DLP)
数据防泄密(DLP)近几年已经成为国内非常热门的关键词. 目前市场上DLP产品主要可以分为三大类,各类产品都来源于不同的技术体系,防护效果也各有优缺点. 第一类,以监控审计为主,对进出的数据进行过滤, ...
- PAT1005 继续(3n+1)猜想
卡拉兹(Callatz)猜想已经在1001中给出了描述.在这个题目里,情况稍微有些复杂. 当我们验证卡拉兹猜想的时候,为了避免重复计算,可以记录下递推过程中遇到的每一个数.例如对 n=3 进行验证的时 ...
- python中的函数def和函数的参数
'''函数: 1.减少代码重用性 2.易维护 3.可扩展性强 4.类型function 定义函数: def 函数变量名(): 函数的调用: 1.函数名加括号 2.函数如果没被调用,不会去执行函数内部的 ...