用Python爬取小说《一念永恒》
我们首先选定从笔趣看网站爬取这本小说。
然后开始分析网页构造,这些与以前的分析过程大同小异,就不再多叙述了,只需要找到几个关键的标签和user-agent基本上就可以了。
那么下面,我们直接来看代码。
from urllib import request
from bs4 import BeautifulSoup
import re
import sys if __name__ == "__main__":
#创建txt文件
file = open('一念永恒.txt', 'w', encoding='utf-8')
#一念永恒小说目录地址
target_url = 'http://www.biqukan.com/1_1094/'
head = {}
head['User-Agent'] = 'Mozilla/5.0 (Linux; Android 4.1.1; Nexus 7 Build/JRO03D) AppleWebKit/535.19 (KHTML, like Gecko) Chrome/18.0.1025.166 Safari/535.19'
target_req = request.Request(url = target_url, headers = head)
target_response = request.urlopen(target_req)
target_html = target_response.read().decode('gbk','ignore')
listmain_soup = BeautifulSoup(target_html)
#找出div标签中class为listmain的所有子标签
chapters = listmain_soup.find_all('div',class_ = 'listmain')
download_soup = BeautifulSoup(str(chapters))
#计算章节个数
numbers = (len(download_soup.dl.contents) - 1) / 2 - 8
index = 1
begin_flag = False
for child in download_soup.dl.children:
if child != '\n':
#找到《一念永恒》正文卷
if child.string == u"《一念永恒》正文卷":
begin_flag = True
#爬取链接并下载链接内容
if begin_flag == True and child.a != None:
download_url = "http://www.biqukan.com" + child.a.get('href')
download_req = request.Request(url = download_url, headers = head)
download_response = request.urlopen(download_req)
download_html = download_response.read().decode('gbk','ignore')
download_name = child.string
soup_texts = BeautifulSoup(download_html)
texts = soup_texts.find_all(id = 'content', class_ = 'showtxt')
soup_text = BeautifulSoup(str(texts))
write_flag = True
file.write(download_name + '\n\n')
#将爬取内容写入文件
for each in soup_text.div.text.replace('\xa0',''): if each == 'h':
write_flag = False
if write_flag == True and each != ' ':
file.write(each)
if write_flag == True and each == '\r':
file.write('\n')
print('正在写入第{0}小节'.format(index))
index+=1
file.write('\n\n')
#打印爬取进度
sys.stdout.write("已下载:%.3f%%" % float(index/numbers) + '\r')
sys.stdout.flush()
index += 1
file.close()
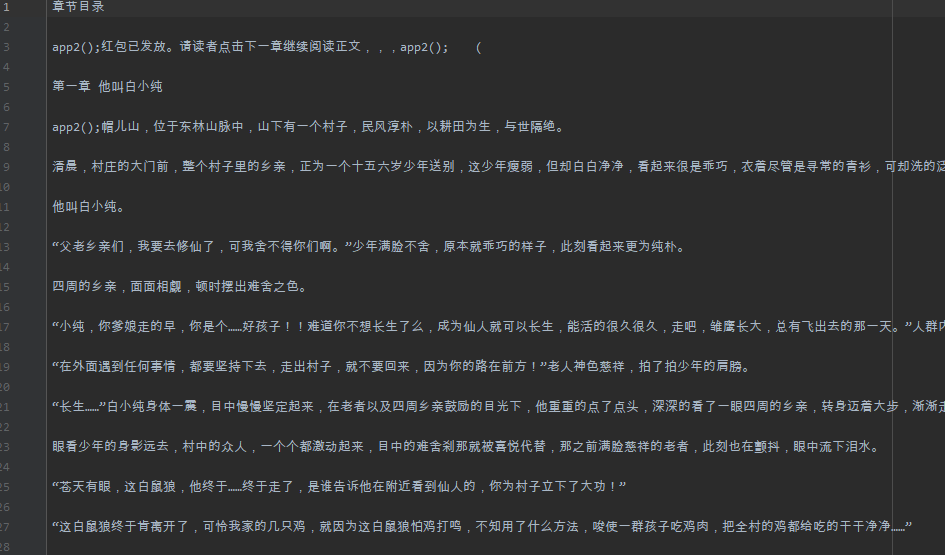
这个代码可能还存在着一些小问题,但是并不影响我们爬取小说,下面来看看我们的运行结果。

用Python爬取小说《一念永恒》的更多相关文章
- python爬取小说详解(一)
整理思路: 首先观察我们要爬取的页面信息.如下: 自此我们获得信息有如下: ♦1.小说名称链接小说内容的一个url,url的形式是:http://www.365haoshu.com/Book/Cha ...
- 详细记录了python爬取小说《元尊》的整个过程,看了你必会~
学了好几天的渗透测试基础理论,周末了让自己放松一下,最近听说天蚕土豆有一本新小说,叫做<元尊>,学生时代的我可是十分喜欢读天蚕土豆的小说,<斗破苍穹>相信很多小伙伴都看过吧.今 ...
- 用python爬取小说章节内容
在学爬虫之前, 最好有一些html基础, 才能更好的分析网页. 主要是五步: 1. 获取链接 2. 正则匹配 3. 获取内容 4. 处理内容 5. 写入文件 代码如下: #导入相关model fro ...
- python爬取小说
运行结果: 代码: import requests from bs4 import BeautifulSoup from selenium import webdriver import os cla ...
- python之爬取小说
继上一篇爬取小说一念之间的第一章,这里将进一步展示如何爬取整篇小说 # -*- coding: utf- -*- import urllib.request import bs4 import re ...
- python入门学习之Python爬取最新笔趣阁小说
Python爬取新笔趣阁小说,并保存到TXT文件中 我写的这篇文章,是利用Python爬取小说编写的程序,这是我学习Python爬虫当中自己独立写的第一个程序,中途也遇到了一些困难,但是最后 ...
- Python3爬取小说并保存到文件
问题 python课上,老师给同学们布置了一个问题,因为这节课上学的是正则表达式,所以要求利用python爬取小说网的任意小说并保存到文件. 我选的网站的URL是'https://www.biquka ...
- Python实战项目网络爬虫 之 爬取小说吧小说正文
本次实战项目适合,有一定Python语法知识的小白学员.本人也是根据一些网上的资料,自己摸索编写的内容.有不明白的童鞋,欢迎提问. 目的:爬取百度小说吧中的原创小说<猎奇师>部分小说内容 ...
- python爬虫——爬取小说 | 探索白子画和花千骨的爱恨情仇(转载)
转载出处:药少敏 ,感谢原作者清晰的讲解思路! 下述代码是我通过自己互联网搜索和拜读完此篇文章之后写出的具有同样效果的爬虫代码: from bs4 import BeautifulSoup imp ...
随机推荐
- 【转载】 我的Machine Learning学习之路
原文地址: https://www.cnblogs.com/steven-yang/p/5857964.html ------------------------------------------- ...
- github上fork分支后再合入原master分支的改动
几个月前看到一个电商项目,文档比较全,fork下来学习下.后来因为其他事情耽搁了,现在想重新看看,发现改动比较大,master分支跟我fork下来的分支不一样了.咋办?简单,把最新的master分支下 ...
- ByteBuffer使用实例
ByteBuffer作为JDK的字节流处理对象,这里举个小例子说明下用法,直接上代码: package com.wlf.netty.nettyserver; import org.junit.Asse ...
- linux无网络情况下安装rpm包
首先理清楚两个东西:rpm和yum.rpm全称redhat package manager,用来管理软件包:yum全称yellow dog updater,modified,它是rpm的前端程序,因为 ...
- 编译安装hls协议切片工具 m3u8-segmenter
操作系统:Ubuntu16.04.4 amd64 安装http://m3u8-segmenter.inodes.org/方式安装m3u8-segmenter报错,于是有了这篇文章 apt instal ...
- 改进初学者的PID-手自动切换
最近看到了Brett Beauregard发表的有关PID的系列文章,感觉对于理解PID算法很有帮助,于是将系列文章翻译过来!在自我提高的过程中,也希望对同道中人有所帮助.作者Brett Beaure ...
- git 操作说明
第一步:代码提交到本地仓库 第二步:更新远程服务器代码到本地,如果有冲突需要优先解决,解决冲突后执行第一步操作 第三步:推送本地代码到远程服务器,可以使用source Tree 或者工具自带的配置gi ...
- WPF ComboBox(转)
WPF ComboBox 创建一个ComboBox控件,并设置ComboBox控件的名称,高度,宽度.及设置ComboBox的垂直和水平对齐. <ComboBox Name="Comb ...
- 阿里nacos k8s部署
阿里nacos k8s部署 [root@master1 nacos]# cat nacos-quick-start.yaml --- apiVersion: v1 kind: Service meta ...
- visual studio 2017搭建linux c++开发环境
https://blog.csdn.net/cekonghyj/article/details/77917433 https://blog.csdn.net/norsd/article/details ...