spark教程(三)-RDD认知与创建
RDD 介绍
spark 最重要的一个概念叫 RDD,Resilient Distributed Dataset,弹性分布式数据集,它是 spark 的最基本的数据(也是计算)抽象。
代码中是一个抽象类,它代表一个 不可变、可分区、里面的元素可并行计算的数据集合。
RDD 的属性
拥有一组分区:数据集的基本组成单位
拥有一个计算每个分区的函数
拥有一个分区器,partitioner,即 RDD 的分片函数
RDD 间存在依赖关系 【下面 RDD 特点中有解释】
拥有一个列表,存储每个 partitioner 的优先位置
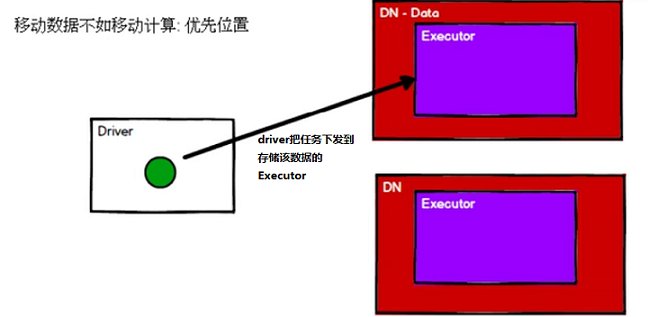
优先位置
这里有个概念叫移动数据不如移动计算,之前在 hadoop 中接触过这个概念,不多解释;
RDD 也是分区存储的,那么 RDD 的数据到底存储在哪个节点,必须有个记录;
当有请求过来时,为了提高运行效率,我们需要把任务下发到存储所需数据的节点,这样避免了网络传输
RDD 的特点
只读:无法进行更改,也就是不可变,如果需要改动,只能创建一个新的 RDD,也就是从一个 RDD 转换成另一个 RDD
依赖关系:一个 RDD 由另一个 RDD 转换得到,也就是 一个 RDD 依赖另一个 RDD,而且可以多层依赖,为了便于理解和描述,我们有时把依赖关系也叫血缘关系;
当 血缘关系 很长时,可以通过持久化 RDD 来切断血缘关系;
惰性执行:RDD 的执行是按照血缘关系延时计算的,也就是 惰性计算
依赖关系
依赖关系有两种
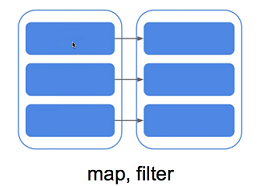
窄依赖:一对一;RDDs 之间分区 一 一对应,也就是一个分区完全由另一个分区转换得到,而不是由另外几个分区转换得到
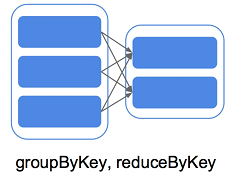
宽依赖:多对一;与窄依赖相反,一个分区由另外几个分区转换得到
缓存
缓存是把 RDD 暂时存起来,用于如下场景:
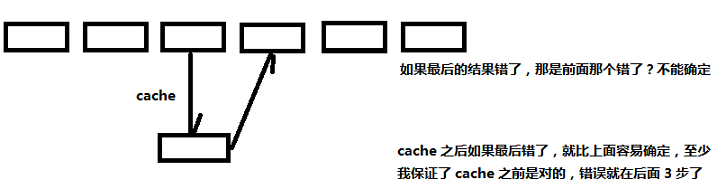
1. 优化效率:一个程序中多次用到一个 RDD,可以先把这个 RDD 缓存起来,避免重复计算

2. 避免出错:
distFile = sc.textFile('README.md')
m = distFile.map(lambda x: len(x)) # map 是 转换 操作,并不立即执行
m.cache() # 把 map 的输出缓存到内存中,其实 cache 就是 执行 操作
#或者
m.persist()
RDD 的创建
创建 RDD 有 3 种方式
1. 基于内存:从内存中的数据创建 RDD,并行化已存在的序列
2. 基于外部存储介质:读取外部数据源,比如 hdfs 【外部存储介质中的数据,注意 spark 本身没有存储功能】
3. 由一个 RDD 转换得到:这种方式不多解释
并行化数据集合
并行化集合是通过在一个 迭代器或者集合 上 调用 SparkContext 的 parallelize 方法生成的 【内存中的数据】
可能还有个 makeRDD,我这里实验不成功,makeRDD 封装了 parallelize,功能是一样的
data = range(10000)
distData = sc.parallelize(data)
distData.reduce(lambda a, b: a+b)
为了创建一个能并行操作的分布式数据集,所有元素都将被拷贝;
然后我们可以调用 reduce 进行叠加,累计求和
并行化集合时一个重要的参数是将数据集切分的数量。一个切片对应一个 spark 任务,我们可指定切片数量
distData2 = sc.parallelize(data, 100) # 切 100 分
外部数据集
由于 spark 本身没有存储功能,一般是从 本地文件、hadoop 等获取外部数据集
本地文件
textFile(name, minPartitions=None, use_unicode=True)[source]
Read a text file from HDFS, a local file system (available on all nodes), or any Hadoop-supported file system URI, and return it as an RDD of Strings. If use_unicode is False, the strings will be kept as str (encoding as utf-8), which is faster and smaller than unicode. (Added in Spark 1.2)
minPartitions 指定最小分区数,也就是说,实际分区数可能比这个数大,在 hdfs 中,文件本身就是 以 block 存储的,此时这个 分区数 不能小于 block 数
示例代码
distFile = sc.textFile('README.md')
distFile = sc.textFile('xx.csv')
distFile = sc.textFile('logs') # 支持文件夹
# textFile("/my/directory/*.txt") # 支持通配符
# textFile("/my/directory/*.gz") # 支持压缩文件
type(sc.textFile('README.md')) # <class 'pyspark.rdd.RDD'>
distFile.map(lambda x: int(x[-1])).reduce(lambda a, b: a + b)
distFile.map(lambda x: len(x)).reduce(lambda a, b: a + b) # map 的输入是每一行,map 的作用是求每一行的 len
# reduce 的输入是两个数字,reduce 的作用是求这两个数的和,
# 也就是把 所有行的 len 逐次求当前元素(当前累计 len 的和)与下一元素的和
读取文件后自动生成 RDD;
各种读取方式都支持 多种 文件格式,如 文件夹,通配符、压缩文件
批量读取本地文件
distFile = sc.wholeTextFiles('files') # 读取 files 文件夹下所有文件内容,返回 (filename, filecontent) 键值对
输入必须是 路径
读取 hdfs 文件
rdd = sc.textFile('hdfs://hadoop10:9000/spark/dwd.csv')
RDD 的读取与存储
读取和存储其实都是一种 action 操作,这里只做简单介绍
rdd.collect() # 读取
rdd.saveAsPickleFile('path')
rdd.saveAsTextFile('path')
存储路径事先不能存在;Pickle 序列化,编码存储;
RDD 算子
算子:认知心理学中的概念,它认为解决问题其实是将问题的初始状态,通过一系列的操作,对问题状态进行转换,然后达到解决状态,这个一系列操作称为算子。
只是一种高大上的叫法,其实就是 RDD 操作
RDD 支持两种类型的操作:transformations 和 actions
transformations:转换,就是从一种 RDD 转换成 另一种 符合 要求 的 RDD,类似于 map
actions:行动,执行计算,类似于 reduce,返回结果
值得注意的是,transformations 是惰性计算,也就是说 transformations 并不立即执行,只有 actions 时,才会执行 transformations
这使得 spark 高效,以 map-reduce 为例,如果我们 map 并不是目的,reduce 才是目的,那么 map 之后 就计算的话,输出存在哪里呢?
如果存在文件,一浪费时间,二浪费地方,如果我们 reduce 时才执行 map,直接把 map 的庞大输出存入内存即可,甚至 流式 传给 reduce,非常高效。
RDD 分区
我们通过实操来验证 RDD 是如何分区的
parallelize 分区
操作一:local 模式,不指定分区
data = range(5)
distData = sc.parallelize(data)
distData.saveAsPickleFile('output') # 存储路径事先不能存在
输出 4 个分区
_SUCCESS
part-00000 # 存放了 0
part-00001 # 存放了 1
part-00002 # 存放了 2
part-00003 # 存放了 3,4
4 从何而来呢?
[root@hadoop10 ~]# cat /proc/cpuinfo |grep "cores"|uniq
cpu cores : 4
即 CPU 核数,
也就是说,parallelize 默认分区数为 CPU 核数
操作二:local 模式,指定分区
data = range(5)
distData = sc.parallelize(data, 3)
distData.saveAsTextFile('output')
输出 3 个分区
_SUCCESS
part-00000 # 存放了 0
part-00001 # 存放了 12
part-00002 # 存放了 34
也就是说,指定了分区数,就分为多少个区,注意,请指定 大于等于 2 的数,不要瞎搞
操作三:local 模式,指定分区,且分区数大于数据量
data = range(5)
distData = sc.parallelize(data, 6)
distData.saveAsTextFile('output')
输出 6 个分区
_SUCCESS
part-00000 # 存放了 空
part-00001 # 存放了 0
part-00002 # 存放了 1
part-00000 # 存放了 2
part-00001 # 存放了 3
part-00002 # 存放了 4
也就是说,即使数据量不够多个分区瓜分,也会按指定个数生成分区,没分到数据的分区为空
通过源码知悉,parallelize 的分区数优先级 为 自定义 --> max(cpu 核数,2),也就是最小为 2
textFile 分区
这个相对来说比较麻烦,我们做个简单介绍。
首先看下 textFile 源码
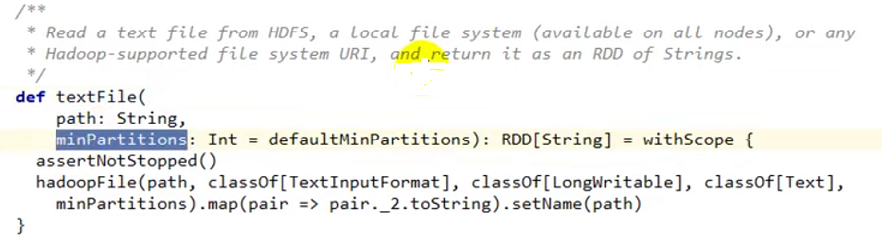
可以看到,minPartitions 就是我们自定义的分区数;然后 调用了 hadoopFile 方法并把 minPartitions 传给了 hadoopFile;
minPartitions 的默认值是 调用 defaultMinPartitions 方法,源码如下
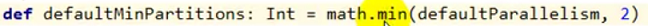
它取 defaultParallelism 和 2 的最小值;defaultParallelism 方法 源码如下

spark.default.parallelism 是在 SPARK_HOME/conf/spark-default.conf 中设置的一个参数,默认是没有这个配置的;
所以:
1. 如果没有在 textFile 中指定 minPartitions,而且也没有配置 spark.default.parallelism,那么 minPartitions 最大是 2
2. 如果没有在 textFile 中指定 minPartitions,但是配置了 spark.default.parallelism,那么 minPartitions 最大也是 2 【如果没有自定义分区数 minPartitions,那么 minPartitions = min(max(CPU 核数, 2), 2);假设我们认为核数大于 2 ,故 minPartitions = 2】
3. 如果没有在 textFile 中指定 minPartitions,minPartitions 最大是 2
4. 如果在 textFile 中指定了 minPartitions,minPartitions 就是指定数目
接下来,我们把 minPartitions 传给 hadoopFile,hadoopFile 会计算文件(如果有多个文件,计算全部文件大小)大小 totalSize,然后把文件 split 成 minPartitions 分,每个切片大小为 goalSize = totalSize / minPartitions,取整
每个 hadoop block 也是一个 文件,在 hadoop中 block 大小是有 最大值的,比如 64M,也就是说我们不能把文件切分成 大于 block 大小的块,也就是说 切片 取 min(goalSize, blockSize) 作为 真正的 切片大小,
但是 切片太小的话又没有意义了,所以 splitSize = max(minSize,min(goalSize, blockSize)), 而 minSize = max(SPLIT_MINSIZE,1),也就是说 minSize 最小为 1, 于是 splitSize 最小为 1,
分数区计算:totalSize / splitSize,如果整除,就是本身,如果不整除,取整,然后 + 1
那我们来测试下
dataFile = sc.textFile('data.txt')
dataFile.saveAsTextFile('output')
7 字节文件,不指定分区数,结果分为 3 个区;splitSize = 7 / 2 = 3.5 = 3, 分区数 = 7 / 3 = 2 + 1 = 3
8 字节文件,不指定分区数,结果分为 2 个区;splitSize = 8 / 2 = 4,分区数 = 8 / 4 = 2
8 字节文件,指定 4 个分区,splitSize = 8 / 4 = 2,分区数 = 8 / 2 = 4;经测试,正解
参考资料:
https://blog.csdn.net/zjwcsdn123/article/details/80489537 spark中textfile方法对文件的分片
https://www.jianshu.com/p/e33671341f0d spark通过textFile读取hdfs数据分区数量规则
spark教程(三)-RDD认知与创建的更多相关文章
- spark教程(四)-SparkContext 和 RDD 算子
SparkContext SparkContext 是在 spark 库中定义的一个类,作为 spark 库的入口点: 它表示连接到 spark,在进行 spark 操作之前必须先创建一个 Spark ...
- 【项目管理和构建】十分钟教程,eclipse配置maven + 创建maven项目(三)
[项目管理和构建]十分钟教程,eclipse配置maven + 创建maven项目(三) 上篇博文中我们介绍了maven下载.安装和配置(二),这篇博文我们配置一下eclipse,将它和maven结合 ...
- RDD编程 上(Spark自学三)
弹性分布式数据集(简称RDD)是Spark对数据的核心抽象.RDD其实就是分布式的元素集合.在Spark中,对数据的操作不外乎创建RDD.转化已有RDD以及调用RDD操作进行求值.而在这一切背后,Sp ...
- Spark 核心概念 RDD 详解
RDD全称叫做弹性分布式数据集(Resilient Distributed Datasets),它是一种分布式的内存抽象,表示一个只读的记录分区的集合,它只能通过其他RDD转换而创建,为此,RDD支持 ...
- Spark分布式计算和RDD模型研究
1背景介绍 现今分布式计算框架像MapReduce和Dryad都提供了高层次的原语,使用户不用操心任务分发和错误容忍,非常容易地编写出并行计算程序.然而这些框架都缺乏对分布式内存的抽象和支持,使其在某 ...
- Spark学习之RDD编程总结
Spark 对数据的核心抽象——弹性分布式数据集(Resilient Distributed Dataset,简称 RDD).RDD 其实就是分布式的元素集合.在 Spark 中,对数据的所有操作不外 ...
- Spark的核心RDD(Resilient Distributed Datasets弹性分布式数据集)
Spark的核心RDD (Resilient Distributed Datasets弹性分布式数据集) 原文链接:http://www.cnblogs.com/yjd_hycf_space/p/7 ...
- Spark 核心概念RDD
文章正文 RDD全称叫做弹性分布式数据集(Resilient Distributed Datasets),它是一种分布式的内存抽象,表示一个只读的记录分区的集合,它只能通过其他RDD转换而创建,为此, ...
- Spark深入之RDD
目录 Part III. Low-Level APIs Resilient Distributed Datasets (RDDs) 1.介绍 2.RDD代码 3.KV RDD 4.RDD Join A ...
随机推荐
- Mysql主从同步 异常Slave_SQL_Running: No
在刚搭建好的mysql主从节点上对从节点进行操作,导致同步异常:报错如下: 从节点执行: mysql> show slave status\G;************************* ...
- easyui编辑editor
$.extend($.fn.datagrid.defaults.editors, { textarea: { init: function(container, options){ var input ...
- 代码优化-多态代替IF条件判断
场景描述 在开发的场景中,常常会遇到打折的业务需求,每个用户对应的等级,他们的打折情况也是不一样的.例如普通会员打9折,青铜会员打8.5折,黄金会员打8折等等.在一般开发中最简单的就是判断用户的等级, ...
- SRS之信号的管理:SrsSignalManager
1. 综述 SRS 中使用了 State Threads 协程库,该库对信号的处理是将信号事件转换为 I/O 事件.主要做法是:对关注的信号设置同样地信号处理函数 sig_catcher(),该函数捕 ...
- laravel查询构造器DB还是ORM,这两者有什么区别,各该用在什么场景中
解答一: 我们所有操作都是走的orm,因为操作简单 直观明了 好维护,性能是低一些 但还没有多致命,真有并发需要优化了 用DB也不一定能解决问题.还是要了解orm每个方法的意思,不然你可能一不小心就会 ...
- A Beginner's Guide To Understanding Convolutional Neural Networks Part One (CNN)笔记
原文链接:https://adeshpande3.github.io/adeshpande3.github.io/A-Beginner's-Guide-To-Understanding-Convolu ...
- [Python]python-jenkins获取正在构建中的job
需求: 我现在需要完成1个接口,这个接口会启动jenkins构建jobA, jobA构建结束, 返回job的构建结果 思路: 首先使用get_job_info获取最后1次构建的构建序号,然后再通过ge ...
- 用泛型方法Java从实体中提取属性值,以及在泛型方法中的使用
public <T> T getFieldValue(Object target, String fieldName, Class<T> typeName) { try { O ...
- ROC曲线详解
转自https://blog.csdn.net/qq_26591517/article/details/80092679 1 ROC曲线的概念 受试者工作特征曲线 (receiver operatin ...
- JavaScript DOM 编程艺术(第二版) 初读学习笔记
这本书留给我的印象就是结构.表现和行为层的分离,以及书后面部分一直在强调的最佳实践原则:平稳退化,逐步增强,向后兼容以及性能考虑. 要注意这不是一本JavaScript入门书籍~ 2.1 准备工作 用 ...