spark 实现多文件输出
需求
不同的key输出到不同的文件
txt文件
multiple.txt
中国;22
美国;4342
中国;123
日本;44
日本;6
美国;55
美国;43765
日本;786
日本;55
scala代码
import org.apache.hadoop.mapred.lib.MultipleTextOutputFormat
import org.apache.spark.{SparkConf, SparkContext} object Mutiple {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("phone-count").setMaster("local[*]")
val sc = new SparkContext(conf)
val input = "C://multiple.txt"
val fileRDD = sc.textFile(input)
val kvRDD = fileRDD.map(line => (line.split(";")(0), line.split(";")(1)))
kvRDD.saveAsHadoopFile("C://out", classOf[String], classOf[String], classOf[RDDMultipleTextOutputFormat])
}
} class RDDMultipleTextOutputFormat extends MultipleTextOutputFormat[Any, Any]{
override def generateFileNameForKeyValue(key: Any, value: Any, name: String): String = {
//定义输出的文件名
key.asInstanceOf[String].split("\t")(0) + ".txt"
}
}
结果
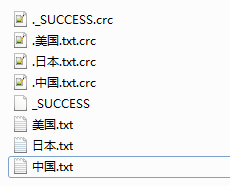
spark 实现多文件输出的更多相关文章
- mapreduce多文件输出的两方法
mapreduce多文件输出的两方法 package duogemap; import java.io.IOException; import org.apache.hadoop.conf ...
- 使用log4j配置不同文件输出不同内容
敲代码中很不注意写日志,虽然明白很重要.今天碰到记录日志,需要根据内容分别输出到不同的文件. 参考几篇文章: 感觉最详细:http://blog.csdn.net/azheng270/article/ ...
- spark 加载文件
spark 加载文件 textFile的参数是一个path,这个path可以是: 1. 一个文件路径,这时候只装载指定的文件 2. 一个目录路径,这时候只装载指定目录下面的所有文件(不包括子目录下面的 ...
- 详解log4j2(下) - Async/MongoDB/Flume Appender 按日志级别区分文件输出
1. 按日志级别区分文件输出 有些人习惯按日志信息级别输出到不同名称的文件中,如info.log,error.log,warn.log等,在log4j2中可通过配置Filters来实现. 假定需求是把 ...
- 使用logback.xml配置来实现日志文件输出
转自:http://sungang-1120.iteye.com/blog/2104296 Logback是由log4j创始人设计的又一个开源日志组件.logback当前分成三个模块:logback- ...
- Python同时向控制台和文件输出日志logging的方法 Python logging模块详解
Python同时向控制台和文件输出日志logging的方法http://www.jb51.net/article/66756.htm 1 #-*- coding:utf-8 -*- 2 import ...
- hadoop多文件输出
现实环境中,经常遇到一个问题就是想使用多个Reduce,可是迫于setup和cleanup在每个Reduce中会调用一次,仅仅能设置一个Reduce,无法是实现负载均衡. 问题,假设要在reduce中 ...
- Hadoop 实现多文件输出
比如word.txt内容如下: aaa bbb aba abc bba bbd bbbc cc ccd cce 要求按单词的首字母区分单词并分文件输出 代码如下: LineRecordWriter p ...
- freemarker嵌入文件输出结果
freemarker嵌入文件输出结果 1.嵌入的文件代码 inc.ftl: <#assign username="李思思"> 2.父文件代码 inner.ftl: &l ...
随机推荐
- 基于grafana+prometheus构建Flink监控
先上一个架构图 Flink App : 通过report 将数据发出去 Pushgateway : Prometheus 生态中一个重要工具 Prometheus : 一套开源的系统监控报警框架 ...
- bootstrap-table中使用bootstrap-switch开关按钮
先上图 准备工作: 添加css和js文件 #bootstrap开关按钮#} <link href="https://cdn.bootcss.com/bootstrap-switch/3 ...
- Suspended Animation——《The Economist》阅读积累(考研英语二·2010 Reading Text 1)
[知识小百科] Damien Hirst(达米恩●赫斯特):生于1965年,是新一代英国艺术家的主要代表人物之一.他主导了90年代英国艺术发展并享有很高的国际声誉.赫斯特在1986年9月就读于伦敦大学 ...
- LeetCode 141. 环形链表(Linked List Cycle) 19
141. 环形链表 141. Linked List Cycle 题目描述 给定一个链表,判断链表中是否有环. 为了表示给定链表中的环,我们使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 ...
- java23种设计模式之十:责任链模式
最近在学习netty中发现其中用到了责任链模式,然后结合自己在写代码中遇到了大量写if...else的情况,决定学习一下责任链模式. 一.什么样的场景下会选择用责任链模式 我们在进行业务逻辑判断时,需 ...
- fpga基础
1.FPGA 的分类: 根据 FPGA 基本结构,可将其分为基于乘积项(Product-Term)技术的 FPGA 和基于查找表(Look-Up-Table)技术的 FPGA 两种. (1)基于乘积项 ...
- MySQL索引工作原理
为什么需要索引(Why is it needed)?当数据保存在磁盘类存储介质上时,它是作为数据块存放.这些数据块是被当作一个整体来访问的,这样可以保证操作的原子性.硬盘数据块存储结构类似于链表,都包 ...
- vue的就地复用--- v-for与:key
v-for遵循的是vue的就地复用原则.文本与数据是绑定的,所以当文本被重新渲染的时候,列表也会被重新渲染. 就地复用只适用于不依赖子组件状态或临时DOM状态的列表渲染输出.[比如表单输入值的列表渲染 ...
- python pip命令安装相当于yum仓库
进入pip目录: 创建pip.conf: 打开pip.conf [global] index-url=https://mirrors.aliyun.com/pypi/simple/ trusted-h ...
- 详解Ubuntu16.04安装Python3.7及其pip3并切换为默认版本(转)
原文:https://www.jb51.net/article/156927.htm