Java并发包concurrent——ConcurrentHashMap
转:
Java并发包concurrent——ConcurrentHashMap
目录
1. ConcurrentHashMap的实现——JDK7版本
2. ConcurrentHashMap的实现——JDK8版本
ConcurrentHashMap从JDK1.5开始随java.util.concurrent包一起引入JDK中,主要为了解决HashMap线程不安全和Hashtable效率不高的问题。众所周知,HashMap在多线程编程中是线程不安全的,而Hashtable由于使用了synchronized修饰方法而导致执行效率不高;因此,在concurrent包中,实现了ConcurrentHashMap以使在多线程编程中可以使用一个高性能的线程安全HashMap方案。
而JDK1.7之前的ConcurrentHashMap使用分段锁机制实现,JDK1.8则使用数组+链表+红黑树数据结构和CAS原子操作实现ConcurrentHashMap;本文将分别介绍这两种方式的实现方案及其区别。
1. ConcurrentHashMap的实现——JDK7版本
1.1 分段锁机制
Hashtable之所以效率低下主要是因为其实现使用了synchronized关键字对put等操作进行加锁,而synchronized关键字加锁是对整个对象进行加锁,也就是说在进行put等修改Hash表的操作时,锁住了整个Hash表,从而使得其表现的效率低下;因此,在JDK1.5~1.7版本,Java使用了分段锁机制实现ConcurrentHashMap.
简而言之,ConcurrentHashMap在对象中保存了一个Segment数组,即将整个Hash表划分为多个分段;而每个Segment元素,即每个分段则类似于一个Hashtable;这样,在执行put操作时首先根据hash算法定位到元素属于哪个Segment,然后对该Segment加锁即可。因此,ConcurrentHashMap在多线程并发编程中可是实现多线程put操作。接下来,本文将详细分析JDK1.7版本中ConcurrentHashMap的实现原理。
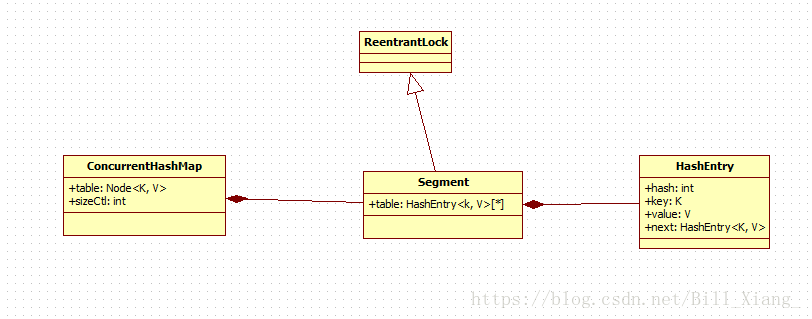
1.2 ConcurrentHashMap的数据结构

ConcurrentHashMap类结构如上图所示。由图可知,在ConcurrentHashMap中,定义了一个Segment<K, V>[]数组来将Hash表实现分段存储,从而实现分段加锁;而么一个Segment元素则与HashMap结构类似,其包含了一个HashEntry数组,用来存储Key/Value对。Segment继承了ReetrantLock,表示Segment是一个可重入锁,因此ConcurrentHashMap通过可重入锁对每个分段进行加锁。
1.3 ConcurrentHashMap的初始化
JDK1.7的ConcurrentHashMap的初始化主要分为两个部分:一是初始化ConcurrentHashMap,即初始化segments数组、segmentShift段偏移量和segmentMask段掩码等;然后则是初始化每个segment分段。接下来,我们将分别介绍这两部分初始化。
ConcurrentHashMap包含多个构造函数,而所有的构造函数最终都调用了如下的构造函数:
- public ConcurrentHashMap(int initialCapacity,
- float loadFactor, int concurrencyLevel) {
- if (!(loadFactor > 0) || initialCapacity < 0 || concurrencyLevel <= 0)
- throw new IllegalArgumentException();
- if (concurrencyLevel > MAX_SEGMENTS)
- concurrencyLevel = MAX_SEGMENTS;
- // Find power-of-two sizes best matching arguments
- int sshift = 0;
- int ssize = 1;
- while (ssize < concurrencyLevel) {
- ++sshift;
- ssize <<= 1;
- }
- this.segmentShift = 32 - sshift;
- this.segmentMask = ssize - 1;
- if (initialCapacity > MAXIMUM_CAPACITY)
- initialCapacity = MAXIMUM_CAPACITY;
- int c = initialCapacity / ssize;
- if (c * ssize < initialCapacity)
- ++c;
- int cap = MIN_SEGMENT_TABLE_CAPACITY;
- while (cap < c)
- cap <<= 1;
- // create segments and segments[0]
- Segment<K,V> s0 =
- new Segment<K,V>(loadFactor, (int)(cap * loadFactor),
- (HashEntry<K,V>[])new HashEntry[cap]);
- Segment<K,V>[] ss = (Segment<K,V>[])new Segment[ssize];
- UNSAFE.putOrderedObject(ss, SBASE, s0); // ordered write of segments[0]
- this.segments = ss;
- }
由代码可知,该构造函数需要传入三个参数:initialCapacity、loadFactor、concurrencyLevel,其中,concurrencyLevel主要用来初始化segments、segmentShift和segmentMask等;而initialCapacity和loadFactor则主要用来初始化每个Segment分段。
1.3.1 初始化ConcurrentHashMap
根据ConcurrentHashMap的构造方法可知,在初始化时创建了两个中间变量ssize和sshift,它们都是通过concurrencyLevel计算得到的。其中ssize表示了segments数组的长度,为了能通过按位与的散列算法来定位segments数组的索引,必须保证segments数组的长度是2的N次方,所以在初始化时通过循环计算出一个大于或等于concurrencyLevel的最小的2的N次方值来作为数组的长度;而sshift表示了计算ssize时进行移位操作的次数。
segmentShift用于定位参与散列运算的位数,其等于32减去sshift,使用32是因为ConcurrentHashMap的hash()方法返回的最大数是32位的;segmentMask是散列运算的掩码,等于ssize减去1,所以掩码的二进制各位都为1.
因为ssize的最大长度为65536,所以segmentShift最大值为16,segmentMask最大值为65535. 由于segmentShift和segmentMask与散列运算相关,因此之后还会对此进行分析。
1.3.2 初始化Segment分段
ConcurrentHashMap通过initialCapacity和loadFactor来初始化每个Segment. 在初始化Segment时,也定义了一个中间变量cap,其等于initialCapacity除以ssize的倍数c,如果c大于1,则取大于等于c的2的N次方,cap表示Segment中HashEntry数组的长度;loadFactor表示了Segment的加载因子,通过cap*loadFactor获得每个Segment的阈值threshold.
默认情况下,initialCapacity等于16,loadFactor等于0.75,concurrencyLevel等于16.
1.4 定位Segment
由于采用了Segment分段锁机制实现一个高效的同步,那么首先则需要通过hash散列算法计算key的hash值,从而定位其所在的Segment. 因此,首先需要了解ConcurrentHashMap中hash()函数的实现。
- private int hash(Object k) {
- int h = hashSeed;
- if ((0 != h) && (k instanceof String)) {
- return sun.misc.Hashing.stringHash32((String) k);
- }
- h ^= k.hashCode();
- // Spread bits to regularize both segment and index locations,
- // using variant of single-word Wang/Jenkins hash.
- h += (h << 15) ^ 0xffffcd7d;
- h ^= (h >>> 10);
- h += (h << 3);
- h ^= (h >>> 6);
- h += (h << 2) + (h << 14);
- return h ^ (h >>> 16);
- }
通过hash()函数可知,首先通过计算一个随机的hashSeed减少String类型的key值的hash冲突;然后利用Wang/Jenkins hash算法对key的hash值进行再hash计算。通过这两种方式都是为了减少散列冲突,从而提高效率。因为如果散列的质量太差,元素分布不均,那么使用Segment分段加锁也就没有意义了。
- private Segment<K,V> segmentForHash(int h) {
- long u = (((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASE;
- return (Segment<K,V>) UNSAFE.getObjectVolatile(segments, u);
- }
接下来,ConcurrentHashMap通过上述定位函数则可以定位到key所在的Segment分段。
1.5 ConcurrentHashMap的操作
在介绍ConcurrentHashMap的操作之前,首先需要介绍一下Unsafe类,因为在JDK1.7新版本中是通过Unsafe类的方法实现锁操作的。Unsafe类是一个保护类,一般应用程序很少用到,但其在一些框架中经常用到,如JDK、Netty、Spring等框架。Unsafe类提供了一些硬件级别的原子操作,其在JDK1.7和JDK1.8中的ConcurrentHashMap都有用到,但其用法却不同,在此只介绍在JDK1.7中用到的几个方法:
- arrayBaseOffset(Class class):获取数组第一个元素的偏移地址。
- arrayIndexScale(Class class):获取数组中元素的增量地址。
- getObjectVolatile(Object obj, long offset):获取obj对象中offset偏移地址对应的Object型field属性值,支持Volatile读内存语义。
1.5.1 get
JDK1.7的ConcurrentHashMap的get操作是不加锁的,因为在每个Segment中定义的HashEntry数组和在每个HashEntry中定义的value和next HashEntry节点都是volatile类型的,volatile类型的变量可以保证其在多线程之间的可见性,因此可以被多个线程同时读,从而不用加锁。而其get操作步骤也比较简单,定位Segment –> 定位HashEntry –> 通过getObjectVolatile()方法获取指定偏移量上的HashEntry –> 通过循环遍历链表获取对应值。
定位Segment:(((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASE
定位HashEntry:(((tab.length - 1) & h)) << TSHIFT) + TBASE
1.5.2 put
ConcurrentHashMap的put方法就要比get方法复杂的多,其实现源码如下:
- public V put(K key, V value) {
- Segment<K,V> s;
- if (value == null)
- throw new NullPointerException();
- int hash = hash(key);
- int j = (hash >>> segmentShift) & segmentMask;
- if ((s = (Segment<K,V>)UNSAFE.getObject // nonvolatile; recheck
- (segments, (j << SSHIFT) + SBASE)) == null) // in ensureSegment
- s = ensureSegment(j);
- return s.put(key, hash, value, false);
- }
同样的,put方法首先也会通过hash算法定位到对应的Segment,此时,如果获取到的Segment为空,则调用ensureSegment()方法;否则,直接调用查询到的Segment的put方法插入值,注意此处并没有用getObjectVolatile()方法读,而是在ensureSegment()中再用volatile读操作,这样可以在查询segments不为空的时候避免使用volatile读,提高效率。在ensureSegment()方法中,首先使用getObjectVolatile()读取对应Segment,如果还是为空,则以segments[0]为原型创建一个Segment对象,并将这个对象设置为对应的Segment值并返回。
在Segment的put方法中,首先需要调用tryLock()方法获取锁,然后通过hash算法定位到对应的HashEntry,然后遍历整个链表,如果查到key值,则直接插入元素即可;而如果没有查询到对应的key,则需要调用rehash()方法对Segment中保存的table进行扩容,扩容为原来的2倍,并在扩容之后插入对应的元素。插入一个key/value对后,需要将统计Segment中元素个数的count属性加1。最后,插入成功之后,需要使用unLock()释放锁。
1.5.3 size
ConcurrentHashMap的size操作的实现方法也非常巧妙,一开始并不对Segment加锁,而是直接尝试将所有的Segment元素中的count相加,这样执行两次,然后将两次的结果对比,如果两次结果相等则直接返回;而如果两次结果不同,则再将所有Segment加锁,然后再执行统计得到对应的size值。
2. ConcurrentHashMap的实现——JDK8版本
在JDK1.7之前,ConcurrentHashMap是通过分段锁机制来实现的,所以其最大并发度受Segment的个数限制。因此,在JDK1.8中,ConcurrentHashMap的实现原理摒弃了这种设计,而是选择了与HashMap类似的数组+链表+红黑树的方式实现,而加锁则采用CAS和synchronized实现。
2.1 CAS原理
一般地,锁分为悲观锁和乐观锁:悲观锁认为对于同一个数据的并发操作,一定是为发生修改的;而乐观锁则任务对于同一个数据的并发操作是不会发生修改的,在更新数据时会采用尝试更新不断重试的方式更新数据。
在Java中,悲观锁的实现方式就是各种锁;而乐观锁则是通过CAS实现的。
CAS(Compare And Swap,比较交换):CAS有三个操作数,内存值V、预期值A、要修改的新值B,当且仅当A和V相等时才会将V修改为B,否则什么都不做。Java中CAS操作通过JNI本地方法实现,在JVM中程序会根据当前处理器的类型来决定是否为cmpxchg指令添加lock前缀。如果程序是在多处理器上运行,就为cmpxchg指令加上lock前缀(Lock Cmpxchg);反之,如果程序是在单处理器上运行,就省略lock前缀。
Intel的手册对lock前缀的说明如下:
- 确保对内存的读-改-写操作原子执行。之前采用锁定总线的方式,但开销很大;后来改用缓存锁定来保证指令执行的原子性。
- 禁止该指令与之前和之后的读和写指令重排序。
- 把写缓冲区中的所有数据刷新到内存中。
CAS同时具有volatile读和volatile写的内存语义。
不过CAS操作也存在一些缺点:1. 存在ABA问题,其解决思路是使用版本号;2. 循环时间长,开销大;3. 只能保证一个共享变量的原子操作。
为了能更好的利用CAS原理解决并发问题,JDK1.5之后在java.util.concurrent.atomic包下采用CAS实现了一系列的原子操作类,这在之后的文章中会详细分析介绍。
2.2 ConcurrentHashMap的数据结构
JDK1.8的ConcurrentHashMap数据结构比JDK1.7之前的要简单的多,其使用的是HashMap一样的数据结构:数组+链表+红黑树。ConcurrentHashMap中包含一个table数组,其类型是一个Node数组;而Node是一个继承自Map.Entry<K, V>的链表,而当这个链表结构中的数据大于8,则将数据结构升级为TreeBin类型的红黑树结构。另外,JDK1.8中的ConcurrentHashMap中还包含一个重要属性sizeCtl,其是一个控制标识符,不同的值代表不同的意思:其为0时,表示hash表还未初始化,而为正数时这个数值表示初始化或下一次扩容的大小,相当于一个阈值;即如果hash表的实际大小>=sizeCtl,则进行扩容,默认情况下其是当前ConcurrentHashMap容量的0.75倍;而如果sizeCtl为-1,表示正在进行初始化操作;而为-N时,则表示有N-1个线程正在进行扩容。
2.3 ConcurrentHashMap的初始化
JDK1.8的ConcurrentHashMap的初始化过程也比较简单,所有的构造方法最终都会调用如下这个构造方法。
- public ConcurrentHashMap(int initialCapacity,
- float loadFactor, int concurrencyLevel) {
- if (!(loadFactor > 0.0f) || initialCapacity < 0 || concurrencyLevel <= 0)
- throw new IllegalArgumentException();
- if (initialCapacity < concurrencyLevel) // Use at least as many bins
- initialCapacity = concurrencyLevel; // as estimated threads
- long size = (long)(1.0 + (long)initialCapacity / loadFactor);
- int cap = (size >= (long)MAXIMUM_CAPACITY) ?
- MAXIMUM_CAPACITY : tableSizeFor((int)size);
- this.sizeCtl = cap;
- }
该初始化过程通过指定的初始容量initialCapacity,加载因子loadFactor和预估并发度concurrencyLevel三个参数计算table数组的初始大小sizeCtl的值。
可以看到,在构造ConcurrentHashMap时,并不会对hash表(Node<K, V>[] table)进行初始化,hash表的初始化是在插入第一个元素时进行的。在put操作时,如果检测到table为空或其长度为0时,则会调用initTable()方法对table进行初始化操作。
- private final Node<K,V>[] initTable() {
- Node<K,V>[] tab; int sc;
- while ((tab = table) == null || tab.length == 0) {
- if ((sc = sizeCtl) < 0)
- Thread.yield(); // lost initialization race; just spin
- else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
- try {
- if ((tab = table) == null || tab.length == 0) {
- int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
- @SuppressWarnings("unchecked")
- Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
- table = tab = nt;
- sc = n - (n >>> 2);
- }
- } finally {
- sizeCtl = sc;
- }
- break;
- }
- }
- return tab;
- }
可以看到,该方法使用一个循环实现table的初始化;在循环中,首先会判断sizeCtl的值,如果其小于0,则说明其正在进行初始化或扩容操作,则不执行任何操作,调用yield()方法使当前线程返回等待状态;而如果sizeCtl大于等于0,则使用CAS操作比较sizeCtl的值是否是-1,如果是-1则进行初始化。初始化时,如果sizeCtl的值为0,则创建默认容量的table;否则创建大小为sizeCtl的table;然后重置sizeCtl的值为0.75n,即当前table容量的0.75倍,并返回创建的table,此时初始化hash表完成。
2.4 Node链表和红黑树结构转换
上文中说到,一个table元素会根据其包含的Node节点数在链表和红黑树两种结构之间切换,因此我们本节先介绍Node节点的结构转换的实现。
首先,在table中添加一个元素时,如果添加元素的链表节点个数超过8,则会触发链表向红黑树结构转换。具体的实现方法如下:
- private final void treeifyBin(Node<K,V>[] tab, int index) {
- Node<K,V> b; int n, sc;
- if (tab != null) {
- if ((n = tab.length) < MIN_TREEIFY_CAPACITY)
- tryPresize(n << 1);
- else if ((b = tabAt(tab, index)) != null && b.hash >= 0) {
- synchronized (b) {
- if (tabAt(tab, index) == b) {
- TreeNode<K,V> hd = null, tl = null;
- for (Node<K,V> e = b; e != null; e = e.next) {
- TreeNode<K,V> p =
- new TreeNode<K,V>(e.hash, e.key, e.val,
- null, null);
- if ((p.prev = tl) == null)
- hd = p;
- else
- tl.next = p;
- tl = p;
- }
- setTabAt(tab, index, new TreeBin<K,V>(hd));
- }
- }
- }
- }
- }
该方法首先会检查hash表的大小是否大于等于MIN_TREEIFY_CAPACITY,默认值为64,如果小于该值,则表示不需要转化为红黑树结构,直接将hash表扩容即可。
如果当前table的长度大于64,则使用CAS获取指定的Node节点,然后对该节点通过synchronized加锁,由于只对一个Node节点加锁,因此该操作并不影响其他Node节点的操作,因此极大的提高了ConcurrentHashMap的并发效率。加锁之后,便是将这个Node节点所在的链表转换为TreeBin结构的红黑树。
然后,在table中删除元素时,如果元素所在的红黑树节点个数小于6,则会触发红黑树向链表结构转换。具体实现如下:
- static <K,V> Node<K,V> untreeify(Node<K,V> b) {
- Node<K,V> hd = null, tl = null;
- for (Node<K,V> q = b; q != null; q = q.next) {
- Node<K,V> p = new Node<K,V>(q.hash, q.key, q.val, null);
- if (tl == null)
- hd = p;
- else
- tl.next = p;
- tl = p;
- }
- return hd;
- }
该方法实现简单,在此不再进行细致分析。
2.5 ConcurrentHashMap的操作
2.5.1 get
通过get获取hash表中的值时,首先需要获取key值的hash值。而在JDK1.8的ConcurrentHashMap中通过speed()方法获取。
- static final int spread(int h) {
- return (h ^ (h >>> 16)) & HASH_BITS;
- }
speed()方法将key的hash值进行再hash,让hash值的高位也参与hash运算,从而减少哈希冲突。然后再查询对应的value值。
- public V get(Object key) {
- Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;
- int h = spread(key.hashCode());
- if ((tab = table) != null && (n = tab.length) > 0 &&
- (e = tabAt(tab, (n - 1) & h)) != null) {
- if ((eh = e.hash) == h) {
- if ((ek = e.key) == key || (ek != null && key.equals(ek)))
- return e.val;
- }
- else if (eh < 0)
- return (p = e.find(h, key)) != null ? p.val : null;
- while ((e = e.next) != null) {
- if (e.hash == h &&
- ((ek = e.key) == key || (ek != null && key.equals(ek))))
- return e.val;
- }
- }
- return null;
- }
查询时,首先通过tabAt()方法找到key对应的Node链表或红黑树,然后遍历该结构便可以获取key对应的value值。其中,tabAt()方法主要通过Unsafe类的getObjectVolatile()方法获取value值,通过volatile读获取value值,可以保证value值的可见性,从而保证其是当前最新的值。
2.5.2 put
JDK1.8的ConcurrentHashMap的put操作实现方式主要定义在putVal(K key, V value, boolean onlyIfAbsent)中。
- final V putVal(K key, V value, boolean onlyIfAbsent) {
- if (key == null || value == null) throw new NullPointerException();
- int hash = spread(key.hashCode());
- int binCount = 0;
- for (Node<K,V>[] tab = table;;) {
- Node<K,V> f; int n, i, fh;
- if (tab == null || (n = tab.length) == 0)
- tab = initTable();
- else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
- if (casTabAt(tab, i, null,
- new Node<K,V>(hash, key, value, null)))
- break; // no lock when adding to empty bin
- }
- else if ((fh = f.hash) == MOVED)
- tab = helpTransfer(tab, f);
- else {
- V oldVal = null;
- synchronized (f) {
- if (tabAt(tab, i) == f) {
- if (fh >= 0) {
- binCount = 1;
- for (Node<K,V> e = f;; ++binCount) {
- K ek;
- if (e.hash == hash &&
- ((ek = e.key) == key ||
- (ek != null && key.equals(ek)))) {
- oldVal = e.val;
- if (!onlyIfAbsent)
- e.val = value;
- break;
- }
- Node<K,V> pred = e;
- if ((e = e.next) == null) {
- pred.next = new Node<K,V>(hash, key,
- value, null);
- break;
- }
- }
- }
- else if (f instanceof TreeBin) {
- Node<K,V> p;
- binCount = 2;
- if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
- value)) != null) {
- oldVal = p.val;
- if (!onlyIfAbsent)
- p.val = value;
- }
- }
- }
- }
- if (binCount != 0) {
- if (binCount >= TREEIFY_THRESHOLD)
- treeifyBin(tab, i);
- if (oldVal != null)
- return oldVal;
- break;
- }
- }
- }
- addCount(1L, binCount);
- return null;
- }
put操作大致可分为以下几个步骤:
- 计算key的hash值,即调用speed()方法计算hash值;
- 获取hash值对应的Node节点位置,此时通过一个循环实现。有以下几种情况:
- 如果table表为空,则首先进行初始化操作,初始化之后再次进入循环获取Node节点的位置;
- 如果table不为空,但没有找到key对应的Node节点,则直接调用casTabAt()方法插入一个新节点,此时不用加锁;
- 如果table不为空,且key对应的Node节点也不为空,但Node头结点的hash值为MOVED(-1),则表示需要扩容,此时调用helpTransfer()方法进行扩容;
- 其他情况下,则直接向Node中插入一个新Node节点,此时需要对这个Node链表或红黑树通过synchronized加锁。
- 插入元素后,判断对应的Node结构是否需要改变结构,如果需要则调用treeifyBin()方法将Node链表升级为红黑树结构;
- 最后,调用addCount()方法记录table中元素的数量。
2.5.3 size
JDK1.8的ConcurrentHashMap中保存元素的个数的记录方法也有不同,首先在添加和删除元素时,会通过CAS操作更新ConcurrentHashMap的baseCount属性值来统计元素个数。但是CAS操作可能会失败,因此,ConcurrentHashMap又定义了一个CounterCell数组来记录CAS操作失败时的元素个数。因此,ConcurrentHashMap中元素的个数则通过如下方式获得:
元素总数 = baseCount + sum(CounterCell)
- final long sumCount() {
- CounterCell[] as = counterCells; CounterCell a;
- long sum = baseCount;
- if (as != null) {
- for (int i = 0; i < as.length; ++i) {
- if ((a = as[i]) != null)
- sum += a.value;
- }
- }
- return sum;
- }
而JDK1.8中提供了两种方法获取ConcurrentHashMap中的元素个数。
- public int size() {
- long n = sumCount();
- return ((n < 0L) ? 0 :
- (n > (long)Integer.MAX_VALUE) ? Integer.MAX_VALUE :
- (int)n);
- }
- public long mappingCount() {
- long n = sumCount();
- return (n < 0L) ? 0L : n; // ignore transient negative values
- }
如代码所示,size只能获取int范围内的ConcurrentHashMap元素个数;而如果hash表中的数据过多,超过了int类型的最大值,则推荐使用mappingCount()方法获取其元素个数。
以上主要分析了ConcurrentHashMap在JDK1.7和JDK1.8中的两种不同实现方案,当然ConcurrentHashMap的功能强大,还有很多方法本文都未能详细解析,但其分析方法与本文以上的内容类似,因此不再赘述,感兴趣的同学可以自行分析比较。通过学习JDK源码,对以后的Java程序设计也有一定的帮助。本系列文章将深入剖析Java concurrent包中的并发编程设计,并从中提炼出一些使用场景,从而为今后的Java程序设计提供一些小小的灵感。
Java并发包concurrent——ConcurrentHashMap的更多相关文章
- Java并发包concurrent类简析
1.ConcurrentHashMap ConcurrentHashMap是线程安全的HashMap的实现. 1)添加 put(Object key , Object value) Concurren ...
- HashMap、Hashtable、ConcurrentHashMap、ConcurrentSkipListMap对比及java并发包(java.util.concurrent)
一.基础普及 接口(interface) 类(class) 继承类 实现的接口 Array √ Collection √ Set √ Collection List √ Collection Map ...
- Java集合及concurrent并发包总结(转)
Java集合及concurrent并发包总结(转) 1.集合包 集合包最常用的有Collection和Map两个接口的实现类,Colleciton用于存放多个单对象,Map用于存放Key-Valu ...
- at java.util.concurrent.ConcurrentHashMap.hash(ConcurrentHashMap.java:333)
at java.util.concurrent.ConcurrentHashMap.hash(ConcurrentHashMap.java:333) 原因: null request
- java并发包研究之-ConcurrentHashMap
概述 HashMap是非线程安全的,HashTable是线程安全的. 那个时候没怎么写Java代码,所以根本就没有听说过ConcurrentHashMap,只知道面试的时候就记住这句话就行了…至于为什 ...
- dubbox部署到jdk1.7环境,启动:java.lang.NoSuchMethodError: java.util.concurrent.ConcurrentHashMap.keySet()
本地用jdk1.8编译的服务提供端war包,部署到环境报错了: INFO: Initializing Spring root WebApplicationContext [16/08/17 05:14 ...
- Java并发包--ConcurrentHashMap原理解析
ConcurrentHashMap实现原理及源码分析 ConcurrentHashMap是Java并发包中提供的一个线程安全且高效的HashMap实现(若对HashMap的实现原理还不甚了解,可参 ...
- Java并发包源码学习系列:JDK1.8的ConcurrentHashMap源码解析
目录 为什么要使用ConcurrentHashMap? ConcurrentHashMap的结构特点 Java8之前 Java8之后 基本常量 重要成员变量 构造方法 tableSizeFor put ...
- Java并发包源码分析
并发是一种能并行运行多个程序或并行运行一个程序中多个部分的能力.如果程序中一个耗时的任务能以异步或并行的方式运行,那么整个程序的吞吐量和可交互性将大大改善.现代的PC都有多个CPU或一个CPU中有多个 ...
随机推荐
- 微信小程序开发(七)获取手机网络类型
// succ.wxml <view>手机网络状态:{{netWorkType}}</view> // succ.js var app = getApp() Page({ da ...
- CentOS 7 系统初始化
0.安装系统基础依赖工具包 yum install net-tools gcc-c++ wget lrzsz vim ntpdate cronolog make psmisc 1.修改主机名 cent ...
- 在SqlServer和Oralce中创建索引
给表名A的字段A增加索引 SqlServer: if exists (select 1 from sysobjects where name='表名A' and type='u')and exists ...
- 【实用linux命令记录】
1.显示完整的进程命令 cat /proc/29049/cmdline 如上面显示不完整可用当前的 cat /proc/进程号/cmdline显示 vtysh下显示完整的配置
- Python&Selenium 数据驱动【unittest+ddt+mysql】
一.摘要 本博文将介绍Python和Selenium做自动化测试的时候,基于unittest框架,借助ddt模块使用mysql数据库为数据源作为测试输入 二.SQL脚本 # encoding crea ...
- 通过自动回复机器人学Mybatis---加强版
第2章 接口式编程 介绍 Mybatis 的接口式编程,并说明为什么要采用这种形式,以及 Mybatis 是如何实现的
- Java中wait()与notify()理解
通常,多线程之间需要协调工作.例如,浏览器的一个显示图片的线程displayThread想要执行显示图片的任务,必须等待下载线程 downloadThread将该图片下载完毕.如果图片还没有下载完,d ...
- kudu_CM安装准备工作
Cloudera Manager简介: hadoop: https://yq.aliyun.com/articles/60759 ----------------------------------- ...
- Acwing-287-积蓄程度(树上DP, 换根)
链接: https://www.acwing.com/problem/content/289/ 题意: 有一个树形的水系,由 N-1 条河道和 N 个交叉点组成. 我们可以把交叉点看作树中的节点,编号 ...
- react-native-page-listview使用方法(自定义FlatList/ListView下拉刷新,上拉加载更多,方便的实现分页)
react-native-page-listview 对ListView/FlatList的封装,可以很方便的分页加载网络数据,还支持自定义下拉刷新View和上拉加载更多的View.兼容高版本Flat ...