mssql表分区
1:表分区
什么是表分区
一般情况下,我们建立数据库表时,表数据都存放在一个文件里。
但是如果是分区表的话,表数据就会按照你指定的规则分放到不同的文件里,把一个大的数据文件拆分为多个小文件,还可以把这些小文件放在不同的磁盘下由多个cpu进行处理。这样文件的大小随着拆分而减小,还得到硬件系统的加强,自然对我们操作数据是大大有利的。
所以大数据量的数据表,对分区的需要还是必要的,因为它可以提高select效率,还可以对历史数据经行区分存档等。但是数据量少的数据就不要凑这个热闹啦,因为表分区会对数据库产生不必要的开销,除啦性能还会增加实现对象的管理费用和复杂性。
创建文件组
T-sql语法:
alter database <数据库名> add filegroup <文件组名>
alter database testdb add filegroup testdbGroup1
alter database testdb add filegroup testdbGroup2
alter database testdb add filegroup testdbGroup3
alter database testdb add filegroup testdbGroup4
alter database testdb add filegroup testdbGroup5
alter database testdb add filegroup testdbGroup6
alter database testdb add filegroup testdbGroup7
alter database testdb add filegroup testdbGroup8
alter database testdb add filegroup testdbGroup9
alter database testdb add filegroup testdbGroup10

创建数据文件到文件组里面
T-sql语法:
alter database <数据库名称> add file <数据标识> to filegroup <文件组名称> --<数据标识> (name:文件名,fliename:物理路径文件名,size:文件初始大小kb/mb/gb/tb,filegrowth:文件自动增量kb/mb/gb/tb/%,maxsize:文件可以增加到的最大大小kb/mb/gb/tb/unlimited)
alter database testdb add file
(name=N'testdb1',filename=N'C:\Program Files\Microsoft SQL Server\MSSQL13.MSSQLSERVER\MSSQL\DATA\testdbGroup\testdb1.ndf',size=5Mb,filegrowth=5mb)
to filegroup testdbGroup1
alter database testdb add file
(name=N'testdb2',filename=N'C:\Program Files\Microsoft SQL Server\MSSQL13.MSSQLSERVER\MSSQL\DATA\testdbGroup\testdb2.ndf',size=5Mb,filegrowth=5mb)
to filegroup testdbGroup2
alter database testdb add file
(name=N'testdb3',filename=N'C:\Program Files\Microsoft SQL Server\MSSQL13.MSSQLSERVER\MSSQL\DATA\testdbGroup\testdb3.ndf',size=5Mb,filegrowth=5mb)
to filegroup testdbGroup3
alter database testdb add file
(name=N'testdb4',filename=N'C:\Program Files\Microsoft SQL Server\MSSQL13.MSSQLSERVER\MSSQL\DATA\testdbGroup\testdb4.ndf',size=5Mb,filegrowth=5mb)
to filegroup testdbGroup4
alter database testdb add file
(name=N'testdb5',filename=N'C:\Program Files\Microsoft SQL Server\MSSQL13.MSSQLSERVER\MSSQL\DATA\testdbGroup\testdb5.ndf',size=5Mb,filegrowth=5mb)
to filegroup testdbGroup5
alter database testdb add file
(name=N'testdb6',filename=N'C:\Program Files\Microsoft SQL Server\MSSQL13.MSSQLSERVER\MSSQL\DATA\testdbGroup\testdb6.ndf',size=5Mb,filegrowth=5mb)
to filegroup testdbGroup6
alter database testdb add file
(name=N'testdb7',filename=N'C:\Program Files\Microsoft SQL Server\MSSQL13.MSSQLSERVER\MSSQL\DATA\testdbGroup\testdb7.ndf',size=5Mb,filegrowth=5mb)
to filegroup testdbGroup7
alter database testdb add file
(name=N'testdb8',filename=N'C:\Program Files\Microsoft SQL Server\MSSQL13.MSSQLSERVER\MSSQL\DATA\testdbGroup\testdb8.ndf',size=5Mb,filegrowth=5mb)
to filegroup testdbGroup8
alter database testdb add file
(name=N'testdb9',filename=N'C:\Program Files\Microsoft SQL Server\MSSQL13.MSSQLSERVER\MSSQL\DATA\testdbGroup\testdb9.ndf',size=5Mb,filegrowth=5mb)
to filegroup testdbGroup9
alter database testdb add file
(name=N'testdb10',filename=N'C:\Program Files\Microsoft SQL Server\MSSQL13.MSSQLSERVER\MSSQL\DATA\testdbGroup\testdb10.ndf',size=5Mb,filegrowth=5mb)
to filegroup testdbGroup10
插入测试数据
declare @i int
set @i=0
while @i<100000000
begin
insert Student([name]) values(CONVERT(varchar(8000),@i)+'名称')
set @i=@i +1
end

分区函数,分区方案,分区表,分区索引
1.分区函数
指定分依据区列(依据列唯一),分区数据范围规则,分区数量,然后将数据映射到一组分区上。
创建语法:
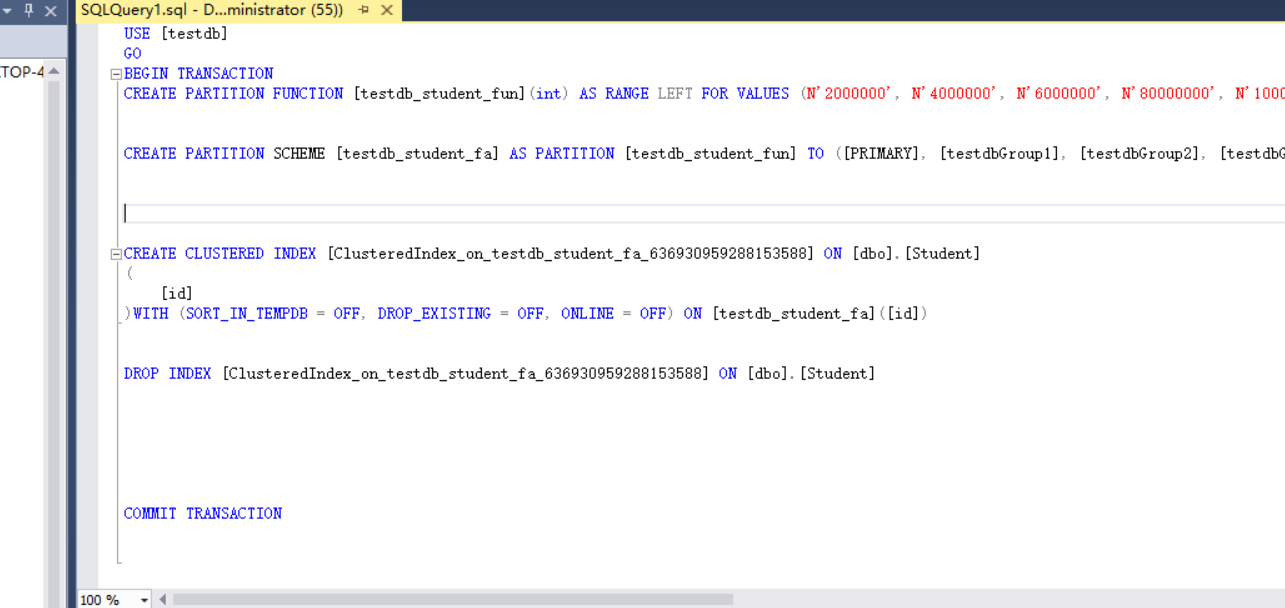
create partition function 分区函数名(<分区列类型>) as range [left/right]
for values (每个分区的边界值,....)
--创建分区函数
CREATE PARTITION FUNCTION [bgPartitionFun](int) AS RANGE LEFT FOR VALUES (N'1000000', N'2000000', N'3000000', N'4000000', N'5000000', N'6000000', N'7000000', N'8000000', N'9000000', N'10000000')
然而,分区函数只定义了分区的方法,此方法具体用在哪个表的那一列上,则需要在创建表或索引是指定。
删除语法:
--删除分区语法
drop partition function <分区函数名>
--删除分区函数 bgPartitionFun
drop partition function bgPartitionFun
需要注意的是,只有没有应用到分区方案中的分区函数才能被删除。
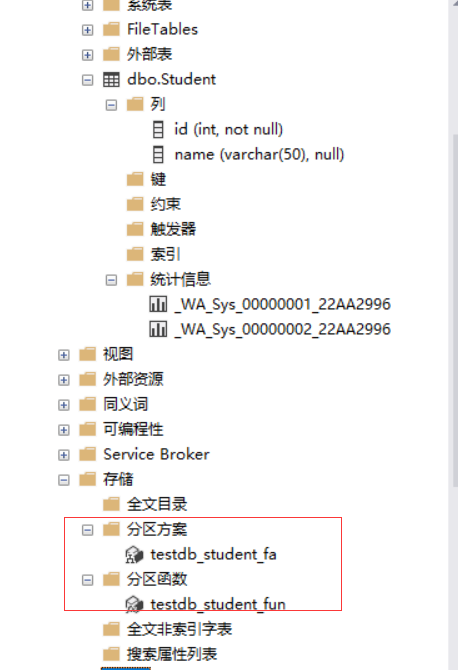
2.分区方案
指定分区对应的文件组。
创建语法:
--创建分区方案语法
create partition scheme <分区方案名称> as partition <分区函数名称> [all]to (文件组名称,....)
--创建分区方案,所有分区在一个组里面
CREATE PARTITION SCHEME [bgPartitionSchema] AS PARTITION [bgPartitionFun] TO ([ByIdGroup1], [ByIdGroup1], [ByIdGroup1], [ByIdGroup1], [ByIdGroup1], [ByIdGroup1], [ByIdGroup1], [ByIdGroup1], [ByIdGroup1], [ByIdGroup1], [ByIdGroup1])
分区函数必须关联分区方案才能有效,然而分区方案指定的文件组数量必须与分区数量一致,哪怕多个分区存放在一个文件组中。
删除语法:
--删除分区方案语法
drop partition scheme<分区方案名称>
--删除分区方案 bgPartitionSchema
drop partition scheme bgPartitionSchema1
只有没有分区表,或索引使用该分区方案是,才能对其删除。
3.分区表
创建语法:
--创建分区表语法
create table <表名> (
<列定义>
)on<分区方案名>(分区列名)

--创建分区表
create table BigOrder (
OrderId int identity,
orderNum varchar(30) not null,
OrderStatus int not null default 0,
OrderPayStatus int not null default 0,
UserId varchar(40) not null,
CreateDate datetime null default getdate(),
Mark nvarchar(300) null
)on bgPartitionSchema(OrderId)
如果在表中创建主键或唯一索引,则分区依据列必须为该列。
4.分区索引
创建语法:
--创建分区索引语法
create <索引分类> index <索引名称>
on <表名>(列名)
on <分区方案名>(分区依据列名)
--创建分区索引
CREATE CLUSTERED INDEX [ClusteredIndex_on_bgPartitionSchema_635342971076448165] ON [dbo].[BigOrder]
(
[OrderId]
)WITH (SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF) ON [bgPartitionSchema]([OrderId])
使用分区索引查询,可以避免多个cpu操作多个磁盘时产生的冲突。
分区表明细信息
这里的语法,我就不写啦,自己看语句分析吧。简单的很。。
1.查看分区依据列的指定值所在的分区
--查询分区依据列为10000014的数据在哪个分区上
select $partition.bgPartitionFun(2000000) --返回值是2,表示此值存在第2个分区
2.查看分区表中,每个非空分区存在的行数
--查看分区表中,每个非空分区存在的行数
select $partition.bgPartitionFun(orderid) as partitionNum,count(*) as recordCount
from bigorder
group by $partition.bgPartitionFun(orderid)
3.查看指定分区中的数据记录
---查看指定分区中的数据记录
select * from bigorder where $partition.bgPartitionFun(orderid)=2
结果:数据从1000001开始到200W结束
分区的拆分与合并以及数据移动
1.拆分分区
在分区函数中新增一个边界值,即可将一个分区变为2个。
--分区拆分
alter partition function bgPartitionFun()
split range(N'1500000') --将第二个分区拆为2个分区
注意:如果分区函数已经指定了分区方案,则分区数需要和分区方案中指定的文件组个数保持对应一致。
2.合并分区
与拆分分区相反,去除一个边界值即可。
--合并分区
alter partition function bgPartitionFun()
merge range(N'1500000') --将第二第三分区合并
3.分区中的数据移动
你或许会遇到这样的需求,将普通表数据复制到分区表中,或者将分区表中的数据复制到普通表中。
那么移动数据这两个表,则必须满足下面的要求。
- 字段数量相同,对应位置的字段相同
- 相同位置的字段要有相同的属性,相同的类型。
- 两个表在一个文件组中
1.创建表时指定文件组
--创建表
create table <表名> (
<列定义>
)on <文件组名>
2.从分区表中复制数据到普通表
--将bigorder分区表中的第一分区数据复制到普通表中
alter table bigorder switch partition 1 to <普通表名>
3.从普通标中复制数据到分区表中
这里要注意的是要先将分区表中的索引删除,即便普通表中存在跟分区表中相同的索引。
--将普通表中的数据复制到bigorder分区表中的第一分区
alter table <普通表名> switch to bigorder partition 1
分区视图
分区视图是先建立带有字段约束的相同表,而约束不同,例如,第一个表的id约束为0--100W,第二表为101万到200万.....依次类推。
创建完一系列的表之后,用union all 连接起来创建一个视图,这个视图就形成啦分区视同。
很简单的,这里我主要是说分区表,就不说分区视图啦。。
查看数据库分区信息
SELECT OBJECT_NAME(p.object_id) AS ObjectName,
i.name AS IndexName,
p.index_id AS IndexID,
ds.name AS PartitionScheme,
p.partition_number AS PartitionNumber,
fg.name AS FileGroupName,
prv_left.value AS LowerBoundaryValue,
prv_right.value AS UpperBoundaryValue,
CASE pf.boundary_value_on_right
WHEN 1 THEN 'RIGHT'
ELSE 'LEFT' END AS Range,
p.rows AS Rows
FROM sys.partitions AS p
JOIN sys.indexes AS i
ON i.object_id = p.object_id
AND i.index_id = p.index_id
JOIN sys.data_spaces AS ds
ON ds.data_space_id = i.data_space_id
JOIN sys.partition_schemes AS ps
ON ps.data_space_id = ds.data_space_id
JOIN sys.partition_functions AS pf
ON pf.function_id = ps.function_id
JOIN sys.destination_data_spaces AS dds2
ON dds2.partition_scheme_id = ps.data_space_id
AND dds2.destination_id = p.partition_number
JOIN sys.filegroups AS fg
ON fg.data_space_id = dds2.data_space_id
LEFT JOIN sys.partition_range_values AS prv_left
ON ps.function_id = prv_left.function_id
AND prv_left.boundary_id = p.partition_number - 1
LEFT JOIN sys.partition_range_values AS prv_right
ON ps.function_id = prv_right.function_id
AND prv_right.boundary_id = p.partition_number
WHERE
OBJECTPROPERTY(p.object_id, 'ISMSShipped') = 0
UNION ALL
SELECT
OBJECT_NAME(p.object_id) AS ObjectName,
i.name AS IndexName,
p.index_id AS IndexID,
NULL AS PartitionScheme,
p.partition_number AS PartitionNumber,
fg.name AS FileGroupName,
NULL AS LowerBoundaryValue,
NULL AS UpperBoundaryValue,
NULL AS Boundary,
p.rows AS Rows
FROM sys.partitions AS p
JOIN sys.indexes AS i
ON i.object_id = p.object_id
AND i.index_id = p.index_id
JOIN sys.data_spaces AS ds
ON ds.data_space_id = i.data_space_id
JOIN sys.filegroups AS fg
ON fg.data_space_id = i.data_space_id
WHERE
OBJECTPROPERTY(p.object_id, 'ISMSShipped') = 0
ORDER BY
ObjectName,
IndexID,
PartitionNumber
待测试项:
1:多少数据量在一张表中是分区性能的临界点
mssql表分区的更多相关文章
- SQL Server 2008 表分区的含义
https://www.cnblogs.com/knowledgesea/p/3696912.html 继续看这个文档 http://www.360doc.com/content/16/0104/11 ...
- (3)SQL Server表分区
1.简介 当一个表数据量很大时候,很自然我们就会想到将表拆分成很多小表,在执行查询时候就到各个小表去查,最后汇总数据集返回给调用者加快查询速度.比如电商平台订单表,库存表,由于长年累月读写较多,积累数 ...
- SQL Server表分区
什么是表分区 一般情况下,我们建立数据库表时,表数据都存放在一个文件里. 但是如果是分区表的话,表数据就会按照你指定的规则分放到不同的文件里,把一个大的数据文件拆分为多个小文件,还可以把这些小文件放在 ...
- sql表分区
1.单表达多少条数据后需要分区呢? a.个人认为要似情况而定,有些常操作的表,分区反而带来麻烦,可以采用物理分表以及其它方法处理: b.对于一些日志.历史订单类的查询数据,500w左右即可享受 ...
- Oracle10g 表分区
1.分区的原因 (1)Tables greater than 2GB should always be considered for partitioning. (2)Tables containin ...
- oracle11g interval(numtoyminterval())自动创建表分区
Oracle11g通过间隔分区实现按月创建表分区 在项目数据库设计过程中由于单表的数据量非常庞大,需要对表进行分区处理.由于表中的数据是历史交易,故按月分区,提升查询和管理. 由于之前对于表分区了解不 ...
- oracle表分区以及普表转分区表(转)
概述 Oracle的表分区功能通过改善可管理性.性能和可用性,从而为各式应用程序带来了极大的好处.通常,分区可以使某些查询以及维护操作的性能大大提高.此外,分区还可以极大简化常见的管理任务,分区是构建 ...
- Mysql 表分区
是否支持分区:mysql> show variables like '%partition%';+-----------------------+-------+| Variable_name ...
- SQL Server表分区的NULL值问题
SQL Server表分区的NULL值问题 SQL Server表分区只支持range分区这一种类型,但是本人觉得已经够用了 虽然MySQL支持四种分区类型:RANGE分区.LIST分区.HASH分区 ...
随机推荐
- STM32WB 信息块之OTP
1.OTP Area范围:0x1FFF 7000 - 0x1FFF 73FF 大小1 K 2.OTP描述 1 KB (128 double words) OTP (one-time programma ...
- Ansible简单介绍(一)
一 :ansible简单介绍 此名取自 Ansible 作者最喜爱的<安德的游戏> 小说,而这部小说更被后人改编成电影 -<战争游戏>. 官网地址:https://www.an ...
- 基于partition的递归
partition算法可以应用在快速排序算法中,也可以应用到 Selection algorithm(在无序数组中寻找第K大的值) Partition 实现 快速排序中用到的 partition 算法 ...
- ad 拼板
随着整个电子产业的不断发展,电子行业的很多产品都已经有完善的上下游配套企业.从一个成熟产品的方案设计,外观设计,加工制造,装配测试,包装,批发商渠道等等,这样的一条产业链在特定的环境就这样自然地生成. ...
- numpy的ndarray数组如何reshape成固定大小
在做肺结节检测的时候,遇到dicom文件reshape之后尺寸大小不一.因为大下不一,numpy.reshape又无法重塑成指定大小的.最后还是在一个大牛的代码中找到了解决方法. VL = np.lo ...
- Flutter入门(三)-底部导航+路由
* StatefulWidget 如果想改变页面中的数据就要用到StatefulWidget,之前自定义组件继承的StatelessWidget是不能动态修改页面数据的 //自定义有状态组件 clas ...
- Luogu P3804 【模板】后缀自动机
注意空间开两倍 #include <bits/stdc++.h> using namespace std; typedef long long LL; template<class ...
- redis主从配置及其java的调用(转)
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明.本文链接:https://blog.csdn.net/gsying1474/article/de ...
- yii框架学习(MVC)
路由:两种方式,第一种是默认方式访问,假设配置了虚拟主机,那么localhost/web/index.php?r=admin/index 访问的是controllers目录下的admin控制器里 ...
- Gulp error in WebStorm: Failed to list gulp tasks
I have the same problem with webstorm after install a updated version of node. The solution for me i ...