day4学python 字符编码转换+元组概念
字符编码转换+元组概念
字符编码转换
#coding:gbk //此处必声明 文件编码(看右下角编码格式) #用来得到python默认编码
import sys
print(sys.getdefaultencoding()) #python本身所有数据类型默认Unicode (与文件编码无关)
s="你好" #encode得到的其他编码是byte类型 decode得到的Unicode是str类型
print(s.encode("utf-8").decode("utf-8").encode("gb2312").decode("gb2312"))
@@@@@@@@@@@@@@@@@@@@@@@@
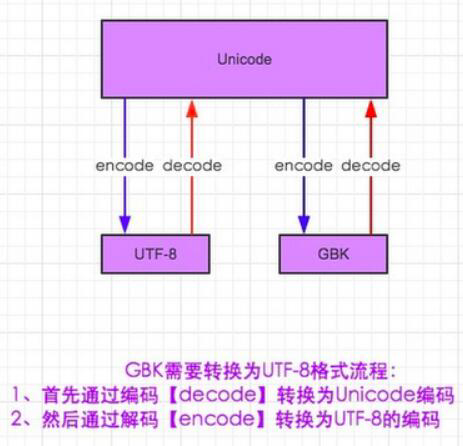
总结:一切编码都可解码为最大的Unicode 反之Unicode可转换为其他编码形式 ASCII==>GB2312 ==>GB18030==>GBK(常用中文编码) 中文编码演变
ASCII 英语占1个字节 8位 没有中文
万国码Unicode 所有字符都占2个字节 16位
=>>>>
升级成 可变长的编码UTF-8 所有英文字符 按照ASCII码占一个字节 中文字符占3个字节 python 3.0默认Unicode格式
========================================================================================
#函数作用
#1.代码重用
#2.保持一致性
#3.可扩展性
#返回数=0个 返回none
def fun1():
print(1) #返回数=1个 返回这个数
def fun2():
print(2)
return 0 #返回数>1个 返回元组组合
def fun3():
print(3)
return 1,[0,1,3,6],{"sa":"bi"} def num(x,y=2):
print(x,y)
num(1,2) #与形参列表一一对应
num(y=1,x=2) #位置参数都标出 与顺序无关
num(2,y=3) #关键参数只能放于位置参数后
num(2) #默认参数非必传 但也可给 并覆盖 def test(x,*args): #参数组 形参以*开头 只能接受位置参数 不能接受关键参数
print(x) #取出首位 接受多个参数其他位变为元组
print(args)
test("",23,1,4353,["",234],{"s":2})
test(*[1,32,43,2]) #**kwargs
def test2(**kwargs): #接受关键字参数变为字典形式
print(kwargs)
test2(name='cf',age=20,sex="man")
test2(**{'name':'al','age':'','sex':'f'})
总结:
def test3(name,age=18,*args,**kwargs): #按形参顺序 *args(反元组)位于一般形参后 **kwargs位于最后
print(name)
print(age)
print(args)
print(kwargs)
test3('cf',12,"s",sex="nan")
输出:
cf
12
('s',) #位置参数变为元组
{'sex': 'nan'} #关键字参数变为字典
day4学python 字符编码转换+元组概念的更多相关文章
- Python—字符编码转换、函数基本操作
字符编码转换 函数 #声明文件编码,格式如下: #-*- coding:utf-8 -*- 注意此处只是声明了文件编码格式,python的默认编码还是unicode 字符编码转换: import sy ...
- Python字符编码转换
编码回顾 在备编码相关的课件时,在知乎上看到一段关于Python编码的回答这哥们的这段话说的太对了,搞Python不把编码彻底搞明白,总有一天它会猝不及防坑你一把.不过感觉这哥们的答案并没把编码问题写 ...
- python 字符编码 转换
#!/bin/env python#-*- encoding=utf8 -*-# 文件头指定utf8编码还是乱码时,使用下面方式指定# fix encoding problem import sys ...
- python字符编码转换说明及深浅copy介绍
编码说明: 常用编码介绍: ascii 数字,字母 特殊字符. 字节:8位表示一个字节. 字符:是你看到的内容的最小组成单位. abc : a 一个字符. 中国:中 一个字符. a : 0000 10 ...
- 深入理解Python字符编码--转
http://blog.51cto.com/9478652/2057896 不论你是有着多年经验的 Python 老司机还是刚入门 Python 不久,你一定遇到过UnicodeEncodeError ...
- 深入理解Python字符编码
不论你是有着多年经验的 Python 老司机还是刚入门 Python 不久,你一定遇到过UnicodeEncodeError.UnicodeDecodeError 错误,每当遇到错误我们就拿着 enc ...
- Python字符编码详解,str,bytes
什么是明文 “明文”是可以是文本,音乐,可以编码成mp3文件.明文可以是图像的,可以编码为gif.png或jpg文件.明文是电影的,可以编码成wmv文件.不一而足. 什么是编码?把明文变成计算机语言 ...
- 转1:Python字符编码详解
Python27字符编码详解 声明 一 字符编码基础 1 抽象字符清单ACR 2 已编码字符集CCS 3 字符编码格式CEF 31 ASCII初创 311 ASCII 312 EASCII 32 MB ...
- 转2:Python字符编码详解
1. 字符编码简介 1.1. ASCII ASCII(American Standard Code for Information Interchange),是一种单字节的编码.计算机世界里一开始只有 ...
随机推荐
- dB2 索引相关
ALTER TABLE "XXXX"."tableA" PCTFREE 20 ; CREATE INDEX "schema"."X ...
- ansible安装配置zabbix客户端
安装软件 ansible host -m apt -a "name=zabbix-agent state=present" ansible host -m shell -a ...
- 32位机,CPU是如何利用段寄存器寻址的
转自:http://blog.sina.com.cn/s/blog_640531380100xa15.html 32位cpu 地址线扩展成了32位,这和数据线的宽度是一致的.因此,在32位机里其实并不 ...
- java实现递归(1)
1.递归算法基本思路: Java递归算法是基于Java语言实现的递归算法.递归算法是一种直接或者间接调用自身函数或者方法的算法.递归算法实质是把问题分解成规模缩小的同类问题的子问题,然后递归调用方法表 ...
- MFC 控件使用汇总
一.动态创建button CButton *button=new CButton; button->Create(_T(,,,),);//最后一个是ID BEGIN_MESSAGE_MAP(CM ...
- 聚类 高维聚类 聚类评估标准 EM模型聚类
高维数据的聚类分析 高维聚类研究方向 高维数据聚类的难点在于: 1.适用于普通集合的聚类算法,在高维数据集合中效率极低 2.由于高维空间的稀疏性以及最近邻特性,高维的空间中基本不存在数据簇. 在高维聚 ...
- Struts2 result type(结果类型)
转自:http://www.cnblogs.com/liaojie970/p/7151103.html 在struts2框架中,当action处理完之后,就应该向用户返回结果信息,该任务被分为两部分: ...
- jetbrains idea/webstorm等(注册,激活,破解码,一起支持正版,最新可用)(2017.3.16更新)【转】
选择 License server (2017.3.16更新) http://idea.imsxm.com/ 详细请参考: http://www.cnblogs.com/ys-wuhan/p/584 ...
- 通过模板判断Value是否为指针
有个参数,需要判断其Value是否为指针,如果是做相应的处理. 代码示例如下,后来发现is_pointer在std空间中. #include <stdio.h> #include<i ...
- Linux的基本指令--
VIM简介: Vi有三种基本工作模式 1.命令模式 2.文本输入模式 3. 末行模式 VIM基本操作: 一 . 进入插入模式: i: 插入光标前一个字符 I: 插入行首 a: 插入光标后一个字符 A ...