tensorflow学习笔记(2)-反向传播
tensorflow学习笔记(2)-反向传播
反向传播是为了训练模型参数,在所有参数上使用梯度下降,让NN模型在的损失函数最小
损失函数:学过机器学习logistic回归都知道损失函数-就是预测值和真实值得差距,比如sigmod或者cross-entropy
均方误差:tf.reduce_mean(tf.square(y-y_))很好理解,假如在欧式空间只有两个点的的话就是两点间距离的平方,多点就是多点误差的平方和除以对比点个数
学习率:决定了参数每次更新的幅度
反向传播训练方法:为了减小loss的值为优化目标
# -*- coding: utf-8 -*-
"""
Created on Sat May 26 18:42:08 2018 @author: Administrator
""" import tensorflow as tf
import numpy as np
BATCH_SIZE=8
seed=23455 #基于seed产生随机数
rng=np.random.RandomState(seed)
#随机返回32行2列的矩阵 作为数据集输入
X=rng.rand(32,2) #从X这个32行2列的矩阵中取出一行 判断如果和小于1 给Y赋值1 如果和不小于1 给Y赋值0
#Y作为训练集的标签
Y=[[int((x0+x1)<1)] for(x0,x1) in X] print(X)
print(Y)
#定义输入,参数和输出
x=tf.placeholder(tf.float32,shape=(None,2))
y_=tf.placeholder(tf.float32,shape=(None,1))
#2是特征值 3是隐藏层 1是输出
w1=tf.Variable(tf.random_normal([2,3],stddev=1,seed=1))
w2=tf.Variable(tf.random_normal([3,1],stddev=1,seed=1)) a=tf.matmul(x,w1)
y=tf.matmul(a,w2) #定义损失函数以及反向传播方法
loss=tf.reduce_mean(tf.square(y-y_))
train_step=tf.train.GradientDescentOptimizer(0.001).minimize(loss) #会话训练
with tf.Session() as sess:
init_op=tf.global_variables_initializer()
sess.run(init_op)
#输出未训练的参数值
print(sess.run(w1))
print(sess.run(w2)) #训练3000次
STEPS=10000
for i in range(STEPS):
start=(i*BATCH_SIZE)%32
end=BATCH_SIZE+start
#每次训练抽取start到end的数据
sess.run(train_step,feed_dict={x:X[start:end],y_:Y[start:end]})
#每500次打印一次参数
if i%500==0:
total_loss=sess.run(loss,feed_dict={x:X,y_:Y})
print("在第%d次训练,损失为%g"%(i,total_loss))
#输出训练后的参数
print("\n")
print(sess.run(w1))
print(sess.run(w2))
这是输出的内容
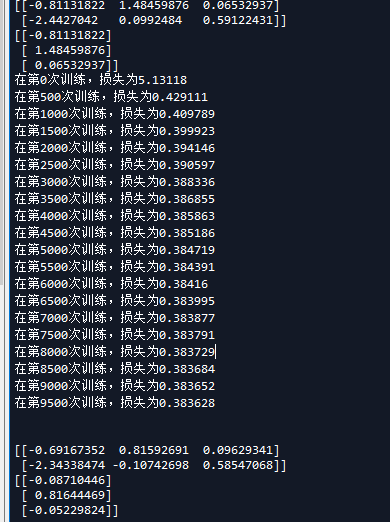
我们现在稍微改下参数比较下,首先是学习速率
当学习速率为0.1时候 当学习速率为0.01

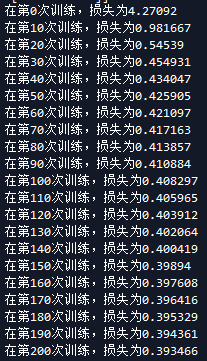
可以看出来学习速率越大梯度下降越块。
再来看看隐藏层
首先是隐藏层为4时候 隐藏层为3时候

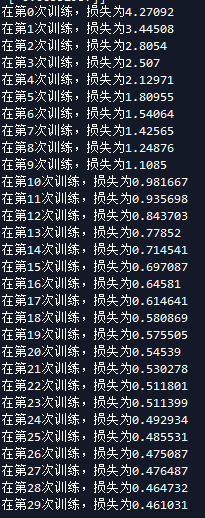
现在还不知道隐藏层怎么定义,知道以后再补上
问了群里老哥:老哥回答

tensorflow学习笔记(2)-反向传播的更多相关文章
- tensorflow学习笔记(1)-基本语法和前向传播
tensorflow学习笔记(1) (1)tf中的图 图中就是一个计算图,一个计算过程. 图中的constant是个常量 计 ...
- tensorflow学习笔记(4)-学习率
tensorflow学习笔记(4)-学习率 首先学习率如下图 所以在实际运用中我们会使用指数衰减的学习率 在tf中有这样一个函数 tf.train.exponential_decay(learning ...
- tensorflow学习笔记(3)前置数学知识
tensorflow学习笔记(3)前置数学知识 首先是神经元的模型 接下来是激励函数 神经网络的复杂度计算 层数:隐藏层+输出层 总参数=总的w+b 下图为2层 如下图 w为3*4+4个 b为4* ...
- TensorFlow学习笔记——深层神经网络的整理
维基百科对深度学习的精确定义为“一类通过多层非线性变换对高复杂性数据建模算法的合集”.因为深层神经网络是实现“多层非线性变换”最常用的一种方法,所以在实际中可以认为深度学习就是深度神经网络的代名词.从 ...
- tensorflow学习笔记——使用TensorFlow操作MNIST数据(2)
tensorflow学习笔记——使用TensorFlow操作MNIST数据(1) 一:神经网络知识点整理 1.1,多层:使用多层权重,例如多层全连接方式 以下定义了三个隐藏层的全连接方式的神经网络样例 ...
- tensorflow学习笔记——自编码器及多层感知器
1,自编码器简介 传统机器学习任务很大程度上依赖于好的特征工程,比如对数值型,日期时间型,种类型等特征的提取.特征工程往往是非常耗时耗力的,在图像,语音和视频中提取到有效的特征就更难了,工程师必须在这 ...
- tensorflow学习笔记——使用TensorFlow操作MNIST数据(1)
续集请点击我:tensorflow学习笔记——使用TensorFlow操作MNIST数据(2) 本节开始学习使用tensorflow教程,当然从最简单的MNIST开始.这怎么说呢,就好比编程入门有He ...
- TensorFlow学习笔记10-卷积网络
卷积网络 卷积神经网络(Convolutional Neural Network,CNN)专门处理具有类似网格结构的数据的神经网络.如: 时间序列数据(在时间轴上有规律地采样形成的一维网格): 图像数 ...
- Tensorflow学习笔记No.4.1
使用CNN卷积神经网络(1) 简单介绍CNN卷积神经网络的概念和原理. 已经了解的小伙伴可以跳转到Tensorflow学习笔记No.4.2学习如和用Tensorflow实现简单的卷积神经网络. 1.C ...
随机推荐
- centOS 7 更改root密码
Linux忘记密码怎么办,不用重装系统,进入emergency mode 更改root密码即可. 首先重启系统,按下 向下 按钮, 定位在第一个,摁 e ,进行编辑 找到 ro , 把ro改为 rw ...
- static函数
C语言中使用静态函数的好处: 静态函数会被自动分配在一个一直使用的存储区,直到退出应用程序实例,避免了调用函数时压栈出栈,速度快很多. 关键字“static”,译成中文就是“静态 ...
- 到底什么时候需要使用 final
final: final修饰属性,则该属性不可再次改变,而且在初始化中必须在属性或者是构造方法中其中且中有一个中初始化他 final修饰方法,则该方法不可被重写 final修饰类,则不可被继承 1:当 ...
- html基础用法(下)
设计表格: <html> <head> <title>表格</title> <meta charset="utf-8" /&g ...
- 在Win7虚拟机下搭建Hadoop2.6.0+Spark1.4.0单机环境
Hadoop的安装和配置可以参考我之前的文章:在Win7虚拟机下搭建Hadoop2.6.0伪分布式环境. 本篇介绍如何在Hadoop2.6.0基础上搭建spark1.4.0单机环境. 1. 软件准备 ...
- PL/SQL 条件控制语句
1.if-then 语句 语法: IF 条件 THEN 语句序列; END IF; 实例: DECLARE i ) :; BEGIN THEN dbms_output.put_line('True') ...
- HTML表格和表单
<table>格式: 注意:1. 合并单元格:COLSPAN(跨列)ROWSPAN(跨行) 2.cellspacing属性定义单元格之间的间距(以像素为单位). cellpadding属性 ...
- CodePush自定义更新弹框及下载进度条
CodePush 热更新之自定义更新弹框及下载进度 先来几张弹框效果图 非强制更新场景 image 强制更新场景 image 更新包下载进度效果 image 核心代码 这里的热更新Modal框,是封装 ...
- php第一节(入门语法、数据类型)
<?php /** * 变量命名用 $ 符 * 变量名称的命名规范 * 1.变量名称以$标示 * 2.变量名称只能以字母和下划线开头 * 3.变量的名称只能包含字母.下划线.数字 * 4.变量名 ...
- 小a和uim之大逃离(dp)
题目背景 小a和uim来到雨林中探险.突然一阵北风吹来,一片乌云从北部天边急涌过来,还伴着一道道闪电,一阵阵雷声.刹那间,狂风大作,乌云布满了天空,紧接着豆大的雨点从天空中打落下来,只见前方出现了一个 ...