机器学习——XGBoost
###基础概念
XGBoost(eXtreme Gradient Boosting)是GradientBoosting算法的一个优化的版本,针对传统GBDT算法做了很多细节改进,包括损失函数、正则化、切分点查找算法优化等。
####xgboost的优化点
相对于传统的GBM,XGBoost增加了正则化步骤。正则化的作用是减少过拟合现象。
xgboost可以使用随机抽取特征,这个方法借鉴了随机森林的建模特点,可以防止过拟合。
速度上有很好的优化,主要体现在以下方面:
1、现了分裂点寻找近似算法,先通过直方图算法获得候选分割点的分布情况,然后根据候选分割点将连续的特征信息映射到不同的buckets中,并统计汇总信息。
2、xgboost考虑了训练数据为稀疏值的情况,可以为缺失值或者指定的值指定分支的默认方向,这能大大提升算法的效率。
3、正常情况下Gradient Boosting算法都是顺序执行,所以速度较慢,xgboost特征列排序后以块的形式存储在内存中,在迭代中可以重复使用,因而xgboost在处理每个特征列时可以做到并行。
总的来说,xgboost相对于GBDT在模型训练速度以及在降低过拟合上不少的提升。
###XGBOOST原理
基于不同y的理解, 我们可以有不同的问题,如回归、分类、排序等。 我们需要找到一种方法来找到最好的参数给定的训练数据。 为了达到这个目的,我们需要定义一个 目标函数 , 用它来测量模型的性能。目标函数包含两部分:损失函数+正则项

其中L为损失函数,Ω是正则项,在预测数据时常用的损失函数比如均方根误差:

另外一个常用的损失函数是logistic损失函数:

其中,我们是通关不断优化,降低损失函数,来提高模型的性能,另外,正则项的主要作用是防止模型的过拟合现象。
对于xgboost而言,它的目标函数可以写成:
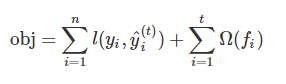
xgboost比传统解决最优化问题常用的梯度迭代方法要跟难,它并不是一次性训练所有树,而是采用一种加法策略,一次添加一个树,因此步骤t的预测值y可以写:

根据上面的推理过程,我们可以把目标函数写成:

如果考虑使用均方误差作为损失函数的,最终可以使用的目标函数可写成

对以上目标函数进行二阶泰勒展开,得到以下公式:

其中,gi和hi被定义为:

最终的目标函数表示形式为:

从中可以看到,xgboost的最优化问题,将取决于目标函数过程中gi和hi取值。
###补充理解
补充理解部分主要是对上面提到的正则化和泰勒展开式做补充解释
####泰勒展开式
泰勒公式是一个用函数在某点的信息描述其附近取值的公式。如果函数足够平滑的话,在已知函数在某一点的各阶导数值的情况之下,泰勒公式可以用这些导数值做系数构建一个多项式来近似函数在这一点的邻域中的值。泰勒公式还给出了这个多项式和实际的函数值之间的偏差。
在机器学习中,使用泰勒展开式的目的是通过泰勒展开式函数的局部近似特性来简化复杂函数的表达。
例如:
函数y=x^3,当自变量有变化时,即 △x,自变量y会变化△y,带入到函数里面就有:

当△x —> 0时,上式的后两项是△x的高阶无穷小舍去的话上式就变成了

也就是说当自变量x足够小的时候,也就是在某点的很小的邻域内,Δy是可以表示成Δx的线性函数的。线性函数计算起来,求导起来会很方便。
对于一般函数,当在某点很小领域内我们也可以写成类似上面的这种自变量和因变量之间线性关系

变化一下形式Δy=f(x)-f(x0), Δx = x-x0在代入上式

这个就是在x0点邻域内舍掉高阶无穷小项以后得到的局部线性近似公式了。为了提高近似的精确度,于是把上面的一次近似多项式修正为二次多项式。再进一步二次修正为三次,一直下去就得到n阶泰勒多项式。
只做一次近似的公式如下:

近似的多项式和原始函数是通过同一点x0。
进行二次近似的公式如下:

近似的多项式和原始函数既过同一点,而且在同一点的导数相同,也就是多项式表达的函数在x0点的切线也相同。
最终n阶泰勒展开公式:

展开越多近似程度越高。
####L1正则化和L2正则化
L1正则化和L2正则化可以看做是损失函数的惩罚项。所谓『惩罚』是指对损失函数中的某些参数做一些限制。对于线性回归模型,使用L1正则化的模型建叫做Lasso回归,使用L2正则化的模型叫做Ridge回归(岭回归)。
通常情况下,L1正则化是在损失函数上加入一项α||w||1,L2正则化则是在损失函数上加入一项α||w||22
一般回归分析中回归w表示特征的系数,从上式可以看到正则化项是对系数做了处理(限制)。L1正则化和L2正则化的说明如下:
- L1正则化是指权值向量w中各个元素的绝对值之和,通常表示为||w||1,L1正则化可以产生稀疏权值矩阵,即产生一个稀疏模型,可以用于特征选择。
- L2正则化是指权值向量w中各个元素的平方和然后再求平方根,通常表示为||w||2,L2正则化可以防止模型过拟合(overfitting);一定程度上,L1也可以防止过拟合。
####L1正则化的作用阐述
L1正则化有助于生成一个稀疏权值矩阵(稀疏矩阵指的是很多元素为0,只有少数元素是非零值的矩阵,即得到的线性回归模型的大部分系数都是0. ),进而可以用于特征选择。
通常机器学习中特征数量很多,例如文本处理时,如果将一个词组(term)作为一个特征,那么特征数量会达到上万个(bigram)。在预测或分类时,那么多特征显然难以选择,但是如果代入这些特征得到的模型是一个稀疏模型,表示只有少数特征对这个模型有贡献,绝大部分特征是没有贡献的,或者贡献微小(因为它们前面的系数是0或者是很小的值,即使去掉对模型也没有什么影响),此时我们就可以只关注系数是非零值的特征。这就是稀疏模型与特征选择的关系。
####L2正则化的作用阐述
L2正则化可以在拟合过程构造一个所有参数都比较小的模型。因为一般认为参数值小的模型比较简单,能适应不同的数据集,也在一定程度上避免了过拟合现象。可以设想一下对于一个线性回归方程,若参数很大,那么只要数据偏移一点点,就会对结果造成很大的影响;但如果参数足够小,数据偏移得多一点也不会对结果造成什么影响,专业一点的说法是抗扰动能力强。
###python中xgboost的使用
xgboost的参数可以分为三类:通用参数,booster参数及目标参数。
1、通用参数
- booster:选择基分类器,可选参数gbtree和gblinear,默认为gbtree
- silent:是否打印模型信息,0表示打印,1表示不打印,默认0
- nthread:线程数选择,默认为最大可用线程数
- num_pbuffer:预测缓冲区的大小,通常设置为训练实例的数量。缓冲区用于保存最后的预测结果提高一步
- num_feature:boosting过程中用到的特征维数,一般xgboost会自动设置
2、booster参数
* eta :学习步长,相当于其他集合模型中的learning_rate,默认为0.3,一般范围0.01-0.2
* gamma:最小损失函数值,默认为0,对于一个节点的划分只有在其loss function 得到结果大于0的情况下才进行
* max_depth:树的最大深度,默认为6 ,用于控制过拟合
* min_child_weight:子节点最小的样本权重,默认为1,用于控制过拟合
* max_delta_step:每棵树权重改变的最大步长,默认为0,一般不设置
* subsample:随机采样的比例,默认为1,用户控制过拟合
* colsample_bytree:随机抽取特征比例,默认1,用户控制过拟合
* colsample_bylevel:每个层级随机抽取特征比例,默认为1
* lambda:l2正则项参数,默认为1
* alpha:l1正则项参数,默认为1
* tree_method:树的构造方法,默认为auto
auto 启发式方法
exact 精确贪婪算法
approx 近似贪婪算法
hist 垂直最优化贪婪算法
* scale_pos_weight:类别处理不平衡处理,默认为0,大于0的取值可以处理类别不平衡的问题。帮助模型更快收敛
* updater 更新树的构建方法,
* refresh_leaf 节点更新,默认为true
* process_type boosting处理方式选择,默认为default
* max_leaves 树的最大节点数增加,默认为0
3、目标参数
* objective:损失函数选择,默认为reg:linear,可选参数如下
“reg:linear” –线性回归。
“reg:logistic” –逻辑回归。
“binary:logistic” –二分类的逻辑回归问题,输出为概率。
“binary:logitraw” –二分类的逻辑回归问题,输出的结果为wTx。
“count:poisson” –计数问题的poisson回归,输出结果为poisson分布。在poisson回归中,max_delta_step的缺省值为0.7。(used to safeguard optimization)
“multi:softmax” –让XGBoost采用softmax目标函数处理多分类问题,同时需要设置参数num_class(类别个数)
“multi:softprob” –和softmax一样,但是输出的是ndata * nclass的向量,可以将该向量reshape成ndata行nclass列的矩阵。每行数据表示样本所属于每个类别的概率。
“rank:pairwise” –通过最小化pairwise损失做排名任务
- eval_metric:最优化损失函数的方法
rmse 均方根误差
mae 平均绝对误差
logloss 负对数似然函数值
error 二分类错误率
merror 多分类错误率
mlogloss 多分类logloss损失函数
auc 曲线下面积排名估计
ndcg 归一化累积增益
###python代码实现
import xgboost as xgb
from sklearn.datasets import load_boston
import pandas as pd
from sklearn.cross_validation import train_test_split
from sklearn.metrics import accuracy_score
boston = load_boston()
#查看波士顿数据集的keys
print(boston.keys())
boston_data=boston.data
target_var=boston.target
feature=boston.feature_names
boston_df=pd.DataFrame(boston_data,columns=boston.feature_names)
boston_df['tar_name']=target_var
#查看目标变量描述统计
print(boston_df['tar_name'].describe())
#把数据集转变为二分类数据
boston_df.loc[boston_df['tar_name']<=21,'tar_name']=0
boston_df.loc[boston_df['tar_name']>21,'tar_name']=1
x_train, x_test, y_train, y_test = train_test_split(boston_df[feature], boston_df['tar_name'], test_size=0.30, random_state=1)
train_data=xgb.DMatrix(x_train,label=y_train)
dtrain=xgb.DMatrix(x_train)
dtest=xgb.DMatrix(x_test)
params={'booster':'gbtree',
'objective': 'binary:logistic',
'eval_metric': 'auc',
'max_depth':6,
'subsample':0.75,
'colsample_bytree':0.75,
'eta': 0.03,}
watchlist = [(train_data,'train')]
bst=xgb.train(params,train_data,num_boost_round=100,evals=watchlist)
# 度量xgboost的准确性
y_train_pred = (bst.predict(dtrain)>=0.5)*1
y_test_pred =(bst.predict(dtest)>=0.5)*1
tree_train = accuracy_score(y_train, y_train_pred)
tree_test = accuracy_score(y_test, y_test_pred)
print('xgboost train/test accuracies %.3f/%.3f' % (tree_train, tree_test))
结果为:xgboost train/test accuracies 0.980/0.868
参考资料:http://xgboost.readthedocs.io/en/latest/model.html
机器学习——XGBoost的更多相关文章
- 机器学习——XGBoost大杀器,XGBoost模型原理,XGBoost参数含义
0.随机森林的思考 随机森林的决策树是分别采样建立的,各个决策树之间是相对独立的.那么,在我们得到了第k-1棵决策树之后,能否通过现有的样本和决策树的信息, 对第m颗树的建立产生有益的影响呢?在随机森 ...
- 机器学习 xgboost 笔记
一.数据预处理.特征工程 类别变量 labelencoder就够了,使用onehotencoder反而会降低性能.其他处理方式还有均值编码(对于存在大量分类的特征,通过监督学习,生成数值变量).转换处 ...
- 机器学习--Xgboost调参
Xgboost参数 'booster':'gbtree', 'objective': 'multi:softmax', 多分类的问题 'num_class':10, 类别数,与 multisoftma ...
- 机器学习xgboost参数解释笔记
首先xgboost有两种接口,xgboost自带API和Scikit-Learn的API,具体用法有细微的差别但不大. 在运行 XGBoost 之前, 我们必须设置三种类型的参数: (常规参数)gen ...
- 图解机器学习 | LightGBM模型详解
作者:韩信子@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/34 本文地址:http://www.showmeai.tech/article-det ...
- 机器学习(四)--- 从gbdt到xgboost
gbdt(又称Gradient Boosted Decision Tree/Grdient Boosted Regression Tree),是一种迭代的决策树算法,该算法由多个决策树组成.它最早见于 ...
- 小巧玲珑:机器学习届快刀XGBoost的介绍和使用
欢迎大家前往腾讯云技术社区,获取更多腾讯海量技术实践干货哦~ 作者:张萌 序言 XGBoost效率很高,在Kaggle等诸多比赛中使用广泛,并且取得了不少好成绩.为了让公司的算法工程师,可以更加方便的 ...
- 【机器学习学习】SKlearn + XGBoost 预测 Titanic 乘客幸存
Titanic 数据集是从 kaggle下载的,下载地址:https://www.kaggle.com/c/titanic/data 数据一共又3个文件,分别是:train.csv,test.csv, ...
- 一文读懂机器学习大杀器XGBoost原理
http://blog.itpub.net/31542119/viewspace-2199549/ XGBoost是boosting算法的其中一种.Boosting算法的思想是将许多弱分类器集成在一起 ...
随机推荐
- Task async await
暇之余,究多Task.async.await. using System; using System.Collections.Generic; using System.Linq; using Sys ...
- Android 学习笔记 文本文件的读写操作
activity_main.xml <LinearLayout xmlns:android="http://schemas.android.com/apk/res/android&qu ...
- go-spew golang最强大的调试助手,没有之一
go内置的fmt.sprintf已经很强大了,但是和spew比起来还是相形见绌,这里来一个例子. import ( "fmt" "github.com/davecgh/g ...
- 20165219 学习基础与C语言基础调查
学习基础与C语言基础调查 你有什么技能比大多数人要好? 因为不知道其他人的具体情况,我只能说,我比较擅长钢琴,素描,国画,这也是小时候掌握的比较好的技能. 针对这个技能的获取有什么成功的经验 小时候学 ...
- Python之路Python内置函数、zip()、max()、min()
Python之路Python内置函数.zip().max().min() 一.python内置函数 abs() 求绝对值 例子 print(abs(-2)) all() 把序列中每一个元素做布尔运算, ...
- 在 Mac OS X 10.9 搭建 Python3 科学计算环境
安装 Homebrew 使用 Homebrew 管理 Python 版本.在 Terminal/iTerm2 输入: $ ruby -e "$(curl -fsSL https://raw. ...
- 6. 重点来啦,pytest的各种装饰圈fixtures
pytest中,fixture的目的是什么 为可靠的和可重复执行的测试提供固定的基线.(可以理解为测试的固定配置,使不同范围的测试都能够获得统一的配置.) fixture提供了区别于传统单元测试(se ...
- [HNOI2006]公路修建问题 BZOJ1196 Kruskal
题目描述 输入输出格式 输入格式: 在实际评测时,将只会有m-1行公路 输出格式: 输入输出样例 输入样例#1: 复制 4 2 5 1 2 6 5 1 3 3 1 2 3 9 4 2 4 6 1 输出 ...
- flex弹性布局,好用
一直不太喜欢自己布局前端页面,都是扒别人的页面 ,最近在练习小程序,页面无处可扒,只有自己布局 发现flex弹性布局真好用,布局起来很简单,实现的效果也很好,赞 以后可以自己写一点前端了,哈哈
- 19年PDYZ冬令营游记
我和卓越的那些事 ——2019年平度一中卓越计划冬令营 题前记: 正月十三那天,刚看完<流浪地球>,便接到了一个电话,老妈告诉我竟然一中组织了一个冬令营,并且起了一个很好的名字“卓越计 ...