win32下开发hadoop
转载自:http://my.oschina.net/muou/blog/408543【木偶:Windows下使用Hadoop2.6.0-eclipse-plugin插件】
对于一些细节地方,我进行了补充。
一.简介
Hadoop2.x之后没有Eclipse插件工具,我们就不能在Eclipse上调试代码,我们要把写好的java代码的MapReduce打包成jar然后在Linux上运行,所以这种不方便我们调试代码,所以我们自己编译一个Eclipse插件,方便我们在我们本地上调试,经过hadoop1.x的发展,编译hadoop2.x版本的eclipse插件比之前简单多了。接下来我们开始编译Hadoop-eclipse-plugin插件,并在Eclipse开发Hadoop。
二.软件安装并配置
1.JDK配置
1) 安装jdk
2) 配置环境变量。JAVA_HOME、CLASSPATH、PATH等设置,这里就不多介绍,网上很多资料
2.Eclipse
1) 下载eclipse-jee-mars-1-win32.zip
2) 解压到本地磁盘,如图所示:
注:
1、eclipse一定要下载jee版,否则后面在eclipse中安装插件后,左边不会显示DFS Locations。或者你暂不不用管这个,等出现这个问题,再重新下个eclipse也行。
2、eclipse的解压路径中不要包含空格,否则后面用ant编译eclipse插件时,会报类似下面的错误:can not found D:\Program\eclipse\plugins。这是因为我把eclipse解压到了D:\Program Files\里,但ant编译插件时,应该是把空格当做了分隔符,于是要求找到D:\Program\eclipse\plugins,但实际上plugins目录应该是D:\Program Files\eclipse\plugins。
3.Ant
1)下载apache-ant-1.9.6-bin.zip
2)解压到一个盘,如图所示:
3)环境变量的配置
新建ANT_HOME=D:\hadoop\apache-ant-1.9.6
在PATH后面加;%ANT_HOME%\bin
4)cmd 测试一下是否配置正确

4.Hadoop
1) 下载hadoop包
hadoop-2.6.0.tar.gz
解压到本地磁盘,如图所示:
下载hadoop2x-eclipse-plugin源代码
1)目前hadoop2的eclipse-plugins源代码由github脱管,下载地址是https://github.com/winghc/hadoop2x-eclipse-plugin,然后在右侧的Download ZIP连接点击下载,如图所示:
2)下载完后,将其解压到本地磁盘,如图所示:
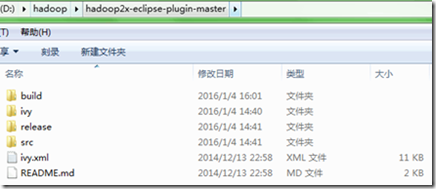
三.编译hadoop-eclipse-plugin插件
1) cmd切换到hadoop2x-eclipse-plugin-master\src\contrib\eclipse-plugin目录,如图所示:

2) 执行ant jar编译生成插件,如下:
ant jar -Dversion=2.6.0 -Declipse.home= D:\hadoop\eclipse -Dhadoop.home= D:\hadoop\hadoop-2.6.0
注:
1、使用ant jar编译生成插件时,可能会卡在ivy-resolve-common,网上的说法很多,比如网络不行等等,我的解决方法是(已验证成功):修改eclipse-plugin\build.xml文件,大概68行的位置(直接ctrl+F,查找compile即可),如下:

作如上修改是因为ivy-resolve-common下载下来的jar包貌似没有什么用,直接去掉这个依赖关系。
2、编译过程中会出现警告,这个没有影响,不用在意。
3) 编译生成的hadoop-eclipse-plugin-2.6.0.jar在新建的build目录下,如下:
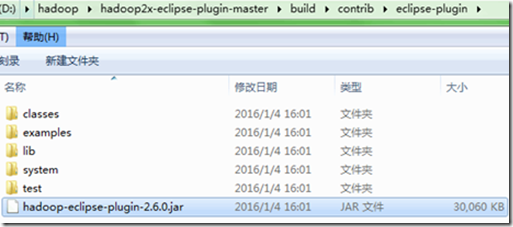
四.Eclipse配置hadoop-eclipse-plugin插件
1) 我已经把可以用的插件包上传了,地址如下:
http://download.csdn.net/detail/tingxuelouwq/9389652
注意,我的环境win7 32位,如果你的是64位,请自行编译,或者上网搜。
把hadoop-eclipse-plugin-2.6.0.jar拷贝到D:\hadoop\eclipse\plugins\目录下,重启Eclipse,然后可以看到DFS Locations,这表示插件安装成功。如图所示:
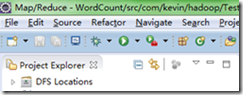
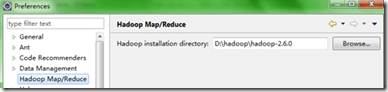
2) 打开Window-->Preferens,可以看到Hadoop Map/Reduc选项,然后指定hadoop-2.6.0的安装路径,如图所示:
3) 配置Map/ReduceLocations
1、点击Window-->Show View -->MapReduce Tools,点击Map/ReduceLocation,如图:

2、点击Map/ReduceLocation选项卡,点击右边小象图标,打开Hadoop Location配置窗口进行配置,如图:
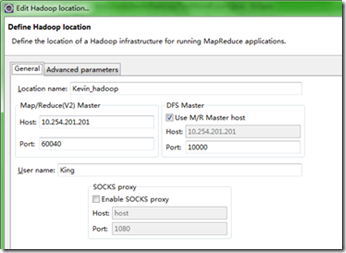
上图中几个参数的说明:
Host:即master(主节点)的ip地址
Map/Reduce中的Port:即mapred-site.xml文件中配置的mapreduce.jobtracker.address的端口号,如下:

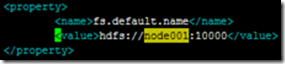
DFS中的Port:即core-site.xml文件中配置的fs.default.name的端口号,如下:
4) 查看是否连接成功。
配置好之后,点击DFS Locations的子菜单,可以看到目前我们hdfs上已有的文件,如下:
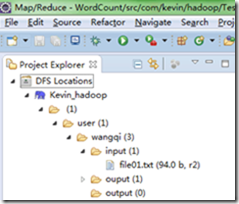
注:可能一开始点击子菜单时,会出现listening,这是因为eclipse正在连接远程的hadoop集群,要等待一下才能看到。
五.新建MapReduce项目并运行
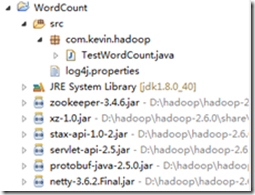
1) 右击New->Map/Reduce Project,项目名称为WordCount
2) 新建TestWordCount.java,然后在Hadoop的share目录下找到wordcount的案例,拷贝到TestWordCount.java中,如下:
注:wordcount案例的路径为:
D:\hadoop\hadoop-2.6.0\share\hadoop\mapreduce\sources\hadoop-mapreduce-examples-2.6.0-sources.jar
将hadoop-mapreduce-examples-2.6.0-sources.jar解压后,在\org\apache\hadoop\examples可以找到WordCount.java文件。
3) 在hdfs创建一个input目录(输出目录可以不用创建,运行MR时会自动创建),并上传一个file01.txt文件(随便写几个单词),整个过程如下:
//新建input文件夹
[wangqi@node001 ~]$ hdfs dfs -mkdir input
[wangqi@node001 ~]$ hdfs dfs -ls -R /
drwxr-xr-x - wangqi supergroup 0 2016-01-05 10:07 /user
drwxr-xr-x - wangqi supergroup 0 2016-01-05 10:08 /user/wangqi
drwxr-xr-x - wangqi supergroup 0 2016-01-05 10:08 /user/wangqi/input
//新建file01.txt文件,并写几个单词
[wangqi@node001 ~]$ touch file01.txt
[wangqi@node001 ~]$ vim file01.txt
hello world. this is my first hadoop program in eclipse.
I love the world, and I love hadoop.
//将file01.txt文件上传到input文件夹下
[wangqi@node001 ~]$ hdfs dfs -put file01.txt input/
[wangqi@node001 ~]$ hdfs dfs -ls -R /
drwxr-xr-x - wangqi supergroup 0 2016-01-05 10:07 /user
drwxr-xr-x - wangqi supergroup 0 2016-01-05 10:08 /user/wangqi
drwxr-xr-x - wangqi supergroup 0 2016-01-05 10:10 /user/wangqi/input
-rw-r--r-- 2 wangqi supergroup 94 2016-01-05 10:10 /user/wangqi/input/file01.txt
注:因为现在eclipse已经连上了hadoop集群,因此你也可以在elicpse中直接创建这些文件及文件夹。
4) 在TestWordCount.java上右键-Run As-Run Configurations,设置输入和输出目录路径,如图所示:
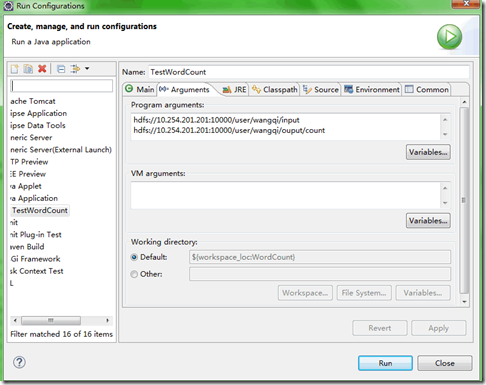
注:不要忘了写端口号,这里的端口号就是core-site.xml中fs.default.name的端口号。
5) 运行maprecude项目前的一些配置。
在运行TestWordCount.java之前,我们需要做一些配置,否则运行时出各种错误。
(1)配置log4j。
配置log4j的好处是可以从日志中看到出了哪些问题。只需要在src目录下写一个log4j.properties即可,如下:
log4j.properties的内容如下:
log4j.rootLogger=debug,stdout,R log4j.appender.stdout=org.apache.log4j.ConsoleAppender log4j.appender.stdout.layout=org.apache.log4j.PatternLayout log4j.appender.stdout.layout.ConversionPattern=%5p - %m%n log4j.appender.R=org.apache.log4j.RollingFileAppender log4j.appender.R.File=mapreduce_test.log log4j.appender.R.MaxFileSize=1MB log4j.appender.R.MaxBackupIndex=1 log4j.appender.R.layout=org.apache.log4j.PatternLayout log4j.appender.R.layout.ConversionPattern=%p %t %c - %m%n log4j.logger.com.codefutures=DEBUG
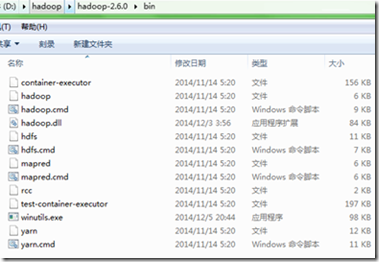
(2)把winutil.exe放到hadoop安装文件的bin目录下,即:
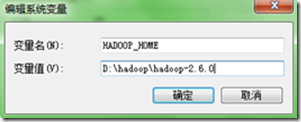
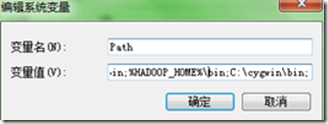
然后配置环境变量HADOOP_HOME和Path,即:
注:winutil.exe可以到网上搜索,注意是win32位的(我的机子是32位的),并且是hadoop 2.6.0的。网上的大多都是hadoop 2.2.0,并且是64位的,注意一下。或者你可以到如下地址下载:
http://download.csdn.net/detail/tingxuelouwq/9390307
缺少winutil.exe文件,在运行时会报如下错误:
Exception in thread "main" java.lang.NullPointerException
at java.lang.ProcessBuilder.start
(3)把hadoop.dll放到C:\Windows\System32目录下,然后重启电脑。(最好将hadoop.dll也拷贝一份到hadoop安装文件的bin目录下)。
注:缺少hadoop.dll文件,在运行时会报如下错误:
Exception in thread "main"java.lang.UnsatisfiedLinkError:
org.apache.hadoop.io.nativeio.NativeIO$Windows.access0
(4)修改hdfs-site.xml文件,添加如下代码:
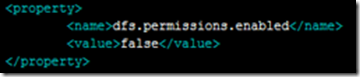
注:这一步是设置对hadoop中目录的访问权限(在正式的服务器上不要这样设置),如果不设置,会报如下错误:
org.apache.hadoop.security.AccessControlException: Permissiondenied: user=wangqi, access=WRITE,inode="/user/wangqi/output":root:supergroup:drwxr-xr-x
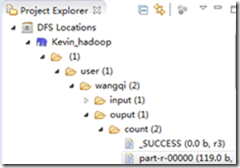
6) 在TestWordCount.java上右键-Run As-Run on Hadoop,执行完成后,在output/count目录下有一个统计文件,如图:
win32下开发hadoop的更多相关文章
- win32下用VC扩展PHP全过程
闲着无聊,打算开发一些PHP组件来玩玩,由于在家没有工作环境,遂打算在win32(我的环境是vista)用VC开发DLL模块,费话不 多说了,进入正题: 一.已经在机器上安装PHP环境的就略过,否则先 ...
- Linux下使用Eclipse开发Hadoop应用程序
在前面一篇文章中介绍了如果在完全分布式的环境下搭建Hadoop0.20.2,现在就再利用这个环境完成开发. 首先用hadoop这个用户登录linux系统(hadoop用户在前面一篇文章中创建的),然后 ...
- Eclipse下的Hadoop应用开发准备
window下开发的准备: A.在windows的某个目录下解压一个hadoop的安装包 B.将安装包下的lib和bin目录用对应windows版本平台编译的本地库替换 C.在window系统中配置H ...
- 【神经网络与深度学习】【CUDA开发】caffe-windows win32下的编译尝试
[神经网络与深度学习][CUDA开发]caffe-windows win32下的编译尝试 标签:[神经网络与深度学习] [CUDA开发] 主要是在开发Qt的应用程序时,需要的是有一个使用的库文件也只是 ...
- 在桌面Linux环境下开发图形界面程序的方案对比
在Linux下开发GUI程序的方法有很多,比如Gnome桌面使用GTK+作为默认的图形界面库,KDE桌面使用Qt作为默认的图形界面库,wxWidgets则是另一个使用广泛的图形库,此外使用Java中的 ...
- 在Linux下开发多语言软件(gettext解决方案)
最近的项目出现了一个bug.项目是基于一个已有的成熟开源软件之上做修改的,新写了加解密库,用于为该成熟开源软件增添加解密功能.功能增加完成后效果都很好,可是就是中文出不来了,也就是说没办法自适应多语言 ...
- [MapReduce_add_1] Windows 下开发 MapReduce 程序部署到集群
0. 说明 Windows 下开发 MapReduce 程序部署到集群 1. 前提 在本地开发的时候保证 resource 中包含以下配置文件,从集群的配置文件中拷贝 在 resource 中新建 ...
- Windows下运行Hadoop
Windows下运行Hadoop,通常有两种方式:一种是用VM方式安装一个Linux操作系统,这样基本可以实现全Linux环境的Hadoop运行:另一种是通过Cygwin模拟Linux环境.后者的好处 ...
- windows下开发PHP扩展dll(无需Cygwin)
windows下开发php扩展网上很多资料都说需要Cygwin,其实完全可以不必安装该东东.没错,是可以在linux下生成骨架后拷到windos下来用,但是,如果没有linux环境呢?什么,装虚拟机? ...
随机推荐
- Linux源码包安装和脚本安装
能够先 vi INSTALL 看看安装过程. 1.源码包安装 2.脚本安装
- python3爬虫-分析Ajax,抓取今日头条街拍美图
# coding=utf-8 from urllib.parse import urlencode import requests from requests.exceptions import Re ...
- T-SQL怎样提高数据库性能
总结: 1.书写问题 2.表连接方式 3.索引的抉择 4.执行计划之参数嗅探 5.子查询与表连接的效率 6.临时表.CTE.表变量的选择 7.常用sp与select的缓存命中 8.锁(善用nolock ...
- 解决svnserve: Can't bind server socket: Address already in use
最近在忙着搭建jenkins系统集成版本控制和git分布式版本控制,其中涉及到了点svn方面的,由于自己也是第一次搭建svn,挺顺利的,中间遇到点小问题: 我使用的是yum安装的svn,安装完成配置结 ...
- JAVA中遍历Map和Set方法,取出map中所有的key
Java遍历Set集合 1.迭代器遍历: Set<String> set = new HashSet<String>(); Iterator<String> it ...
- SQL SERVER 存储/ 存储结构 内部数据结构
资料: http://www.cnblogs.com/woodytu/p/4488930.html
- 流量分析系统---echarts模拟迁移中 ,geocoord从后台获取动态数值
由于在echarts的使用手册中说了 {Object} geoCoord (geoCoord是Object类型) ,所以不能用传统的字符串拼接或数组的方式赋值.在后台的controller中用Map& ...
- 关于Class.getResourceAsStream
Properties properties = new Properties(); properties.load(new InputStreamReader(CharactorTest.cl ...
- 【leetcode刷题笔记】Multiply Strings
Given two numbers represented as strings, return multiplication of the numbers as a string. Note: Th ...
- HTTP协议—HTTP响应头和请求头
HTTP请求头提供了关于请求,响应或者其他的发送实体的信息. HTTP的头信息包括通用头.请求头.响应头和实体头四个部分.每个头域由一个域名,冒号(:)和域值三部分组成. 通用头标:即可用于请求,也可 ...