Selenium(十四):自动化测试模型介绍、模块化驱动测试案例、数据驱动测试案例
1. 自动化测试模型介绍
随着自动化测试技术的发展,演化为了集中模型:线性测试、模块化驱动测试、数据驱动测试和关键字驱动测试。
下面分别介绍这几种自动化测试模型的特点。
1.1 线性测试
通过录制或编写对应用程序的操作步骤产生相应的线性脚本,每个测试脚本相对独立,且不产生其他依赖与调用,这也是早期自动化测试的一种形式:它们其实就是单纯的来模拟用户完整的操作场景。
前面写的所有文章所编写的测试脚本都属于线性测试。
这种模型的优势就是每一个脚本都是完整且独立的。所以,任何一个测试用例脚本拿出来都可以单独执行。当然,缺点也相当明显,测试用例的开发与维护成本很高。
开发成本高,测试用例之间可能会存在重复的操作,不得不为每一个用例去录制或编写这些重复的操作。例如每个用例中重复的用户登录和退出操作等。
维护成本高,正因为测试用例之间存在重复的操作,所以当这些重复的操作发生改变时,就需要逐一的对它们进行修改。例如登录输入框的定位发生了改变,就需要对每一个包含登录的用例进行调整。
1.2 模块化驱动测试
正是由于线性测试的缺陷非常明显,因此早期的自动化编程专家就考虑用新的自动化测试模块来代替线性测试。做法也很简单,借鉴了编程语言中模块化的思想,把重复的操作独立成公共模块,当用例执行过程中需要用到这一门课操作时则被调用,这样就最大限度的消除了重复,从而提高测试用例的可维护性。
提高了开发效率,不用重复编写相同的操作脚本。例如,已经写好一个登录模块,后续测试用例在需要登录的地方调用即可。
简化了维护的复杂性,加入登录按钮的定位发生了变化,那么只需修改登录模块的脚本即可,对于所有调用登录模块的测试脚本来说不需要做任何修改。
1.3 数据驱动测试
虽然模块化驱动测试很好的解决了脚本的重复问题,但是自动化测试脚本在开发的过程中还是发型了诸多不便。例如,现在我要测试不同用户的登录,首先用的是“张三”的用户名登录,下一个测试用例要换成“李四”的用户名登录。在这种情况下,还是需要重复的编写登录脚本,因为虽然登录的步骤相同,但是登录所用的测试数据不同。
于是,数据驱动测试的概念就为解决这类问题而被提出。从它的本意来解释,就是数据的改变从而驱动自动化测试的执行,最终引起测试结果的改变。这听上去的确是个高大上的概念,而在早期的商业自动化工具中,也的确把这一概念作为一个卖点。对于数据驱动所需要的测试数据,也是通过根据工具内置的Datapool管理。
数据驱动说的直白点就是数据的参数化,因为熟人数据的不同从而引起输出结果的不同。
不管我们读取的是定义的数组、字典,或者是外部文件(Excel、csv、txt、xml等),都可以看作是数据驱动,它的目的就是实现数据与脚本的分离。
这样做的好处同样是显而易见的,它进一步增强了脚本的复用性。同样以道路为例,首先是重新设计登录模块,使其可以接受不同的数据,把接收到的数据作为登录操作的一部分。这样就可以很好的适应相同操作、不同的数据的情况。当指定登录用户是“张三”时,那么登录之后的结果就是欢迎“张三”;当指定登录用户是“李四”时,登录结果就显示“欢迎李四”。这就是数据驱动所希望达到的目的。
1.4 关键字驱动测试
理解了数据驱动后,无非是把“数据”换成“关键字”,通过关键字的改变引起测试结果的改变。
目前市面上典型关键字驱动工具以OTP(目前已更名为UFT-Unified Funcionl Testing)、Robot Framework(RIDE)工具为主。这类工具封装了底层的代码,提供给用户独立的图像界面,以“填表格”的形式免除测试人员对写代码的恐惧,从而降低脚本的编写难度,我们只需使用工具所提供的关键字以“过程式”的方式来编写用例即可。(我公司使用的是Robot Framework)
当然,selenium家族中的selenium IDE也可以看作是一种传统的关键字驱动的自动化工具。
2. 模块化驱动测试案例
通过对自动化测试模型的介绍,我们了解了模块化设计的优点。这里我们就以具体的例子来介绍模块的具体应用,当然它的基础是Python语言中函数与类方法的调用。
线性测试代码:
from selenium import webdriver wd = webdriver.Chrome()
wd.implicitly_wait(10)
#进入某网站
wd.get('https://www.xx.com') #登录
wd.find_element_by_id("id1").clear()#防止输入框里面有内容
wd.find_element_by_id("id1").send_keys("username")
wd.find_element_by_id("id2").clear()
wd.find_element_by_id("id2").send_keys("password")
wd.find_element_by_id("id3").click() #进入网站后的操作
#...... #退出
wd.find_element_by_link_text("退出").click()
wd.quit()
从上述流程分析,很多功能都需要登录之后才能进行,对于手工来说,测试人员在执行用例的过程中可以一次登录后验证多个功能再退出,但自动化测试的执行有别于手工测试的执行,需要保持测试用例的独立性和完整性,所以每一条用例在执行时都需要登录和退出操作。这个时候就可以把登录和退出的操作封装为公共函数。当每一条用例需要登录/退出时,只需调用它们即可,从而消除代码重复,提高脚本的可维护性。
下面对登录和退出进行模块封装。
from selenium import webdriver #登录
def login():
wd.find_element_by_id("id1").clear()#防止输入框里面有内容
wd.find_element_by_id("id1").send_keys("username")
wd.find_element_by_id("id2").clear()
wd.find_element_by_id("id2").send_keys("password")
wd.find_element_by_id("id3").click() #退出
def logout():
wd.find_element_by_link_text("退出").click()
wd.quit() wd = webdriver.Chrome()
wd.implicitly_wait(10)
#进入某网站
wd.get('https://www.xx.com')
login()#调用登录模块 #进入网站后的操作
#...... logout()#调用退出模块
现在将登录的操作步骤封装到login()函数中,把退出的操作封装到logout()函数中,对于用例本身只需要调用这两个函数即可,可以把更多的注意力放到用例本身的操作步骤中。
当然,如果只是把操作步骤封装成函数并没简便太多,我们想要将其放到单独的脚本文件中供其他用例调用。
public.py:
class Login():
# 登录
def login(self,driver):
driver.find_element_by_id("id1").clear() # 防止输入框里面有内容
driver.find_element_by_id("id1").send_keys("username")
driver.find_element_by_id("id2").clear()
driver.find_element_by_id("id2").send_keys("password")
driver.find_element_by_id("id3").click()
# 退出
def logout(self,driver):
driver.find_element_by_link_text("退出").click()
driver.quit()
当函数被独立到单独的脚本文件中时做了一点调整,主要是为函数增加了浏览器驱动的形参。因为函数实现的操作需要通过浏览器驱动driver,driver需要通过具体调用的用例给定。
from selenium import webdriver
from helloworld.public import Login wd = webdriver.Chrome()
wd.implicitly_wait(10)
#进入某网站
wd.get('https://www.xx.com') Login.login(wd)#调用登录模块 #进入网站后的操作
#...... Login.logout(wd)#调用退出模块
首先,需要导入当前目录下public.py文件中的Login()类,在需要的位置调用类中的login()和logout()函数。这样对于每个用例的编写与维护就方便了很多。
3. 数据驱动测试案例
前面提到关于数据驱动的形式有很多,我们既可以通过定义变量的方式进行参数化,也可以通过定义数组、字典的方式进行参数化,还可以通过读取文件(txt\csv\xml)的方式进行参数化。
3.1 参数化登录
现在的需求是测试不同用户的登录。对于测试用例来说,不变的是登录的步骤,变化的是每次登录的用户名和密码,这种情况下就需要用到数据驱动方式来编写测试用例。基于前面的例子做如下修改。
public.py:
class Login():
# 登录
def login(self,driver,username,password):
driver.find_element_by_id("id1").clear() # 防止输入框里面有内容
driver.find_element_by_id("id1").send_keys(username)
driver.find_element_by_id("id2").clear()
driver.find_element_by_id("id2").send_keys(password)
driver.find_element_by_id("id3").click()
# 退出
def logout(self,driver):
driver.find_element_by_link_text("退出").click()
driver.quit()
修改login()方法的形参,为其增加username、password的形参,将得到的具体参数作为登录时的数据。
from selenium import webdriver
from helloworld.public import Login class LoginTest(): def __init__(self):
self.wd = webdriver.Chrome()
self.wd.implicitly_wait(10)
self.wd.get('https://www.xx.com') #test1用户登录
def test1_login(self):
username = 'test1'
password = ''
Login().logout(self.wd,username,password)
self.wd.quit() def test2_login(self):
username = 'test2'
password = ''
Login().logout(self.wd, username, password)
self.wd.quit() LoginTest.test1_login()
LoginTest.test2_login()
创建LoginTest类,并在__init__()方法中初始化浏览器驱动、等待超时长和URL等。这样test1_login()与test2_login()两个测试方法只需关注登录的用户名和密码,通过调研Login()类的login()方法并传入具体的参数来测试不同的用户的登录。
3.2 参数化搜索关键字
再来看一个百度搜索的例子。我们每天上网一般要用很多次百度搜索,而我们每次在使用百度搜索时步骤都是一样的,不一样的是每一次搜索的“关键字”不同。下面我们就以数组的方式对搜索的关键字进行参数化。
from selenium import webdriver search_text = ['python','中文','text'] for text in search_text:
wd = webdriver.Chrome()
wd.implicitly_wait(10)
wd.get("http://www.baidu.com")
wd.find_element_by_id('kw').send_keys(text)
wd.find_element_by_id('su').click()
这个例子比较简单,首先创建一个数组search_text用来存放搜索的关键字,通过for循环来遍历数组,最后把遍历的数组元素作为每次百度搜索的关键字。这个例子可以更充分的体现出数据驱动的概念,因为测试数据的不同从而引起测试结果的不同。
3.3 读取txt文件
txt文件是我们经常操作的文件类型,Python提供了以下几种读取txt文件的方式。
read():读取整个文件
readline():读取一行数据
readlines():读取所有行的数据
回到前面的登录案例,现在使用txt文件来存放用户名和密码数据,并通过读取该文件中的数据作为用例的测试数据。
txt:
xiaohuihui1,123
xiaohuihui2,456
xiaohuihui3,789
首先将用户名和密码按行写入txt文件中,这里把用户名和密码用逗号“,”隔开。
代码:
user_file = open('user_info.txt','r')
lines = user_file.readlines()
user_file.close()
for line in lines:
username = line.split(',')[0]
password = line.split(',')[1]
print(username,password)
运行结果:

首先通过open()方法以读(“r”)的形式打开user_info.txt文件,使用readlines()方法按行读取txt文件,将获取到的每一行数据通过split()方法拆分出用户名和密码。split()可以将一个字符串通过某一个字符为分割点拆分成左右两部分,这里以逗号(,)为分割点。split()拆分出来的左右两部分以数组的形式存放,所以[0]可以取到左半部分的字符串,[1]可以取到右半部分的字符串。
在上面的例子中循环遍历出每一行数据的用户名和密码,得到想要的数据后就可以将其用于自动化测试脚本了。
3.4 读取csv文件
那么新的问题来了,假设现在每次要读取的是一组用户数据,这一组数据包括用户名、邮箱、年龄、性别等学习,这时再使用txt文件来存放这些数据,读取起来就没那么方便了。对于这种类型的数据可以通过CSV文件来存放。
创建info.csv文件,首先通过WPS表格或Excel创建表格,文件另存为CSV格式进行保存。注意不要通过直接修改文件的后缀名来创建CSV文件,这样创建的并非真正的CSV类型的文件。
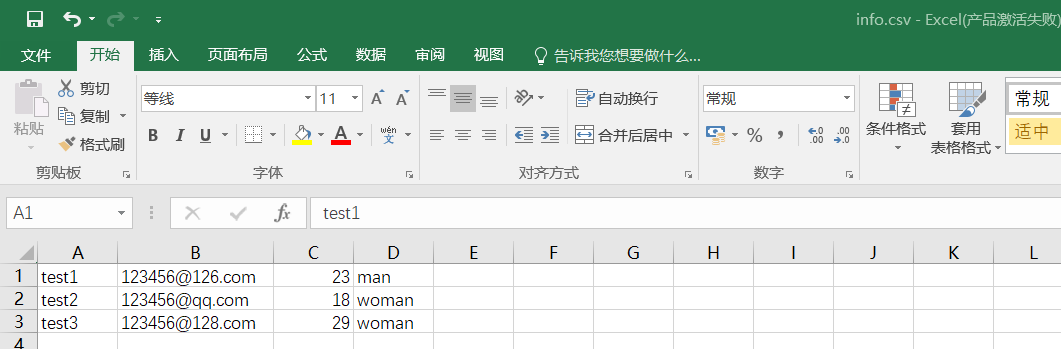
下面编写python代码进行循环读取。
import csv #导入csv包 #读取本地CSV文件
date = csv.reader(open('info.csv','r')) #循环输出每一行信息
for user in date:
print(user)
运行结果:

首先导入cvs模块,通过reader()方法读取CSV文件,然后通过for循环遍历文件中的每一行数据。
从打印结果可以看出,读取的每一行数据均是以数组的形式存储的。如果想取用户的某一列数据,只需要指定数组下标即可。
import csv #导入csv包 #读取本地CSV文件
date = csv.reader(open('info.csv','r')) #循环输出每一行信息
for user in date:
print(user[1])
运行结果:
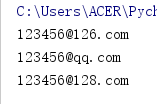
假如现在需要所有用户的邮箱地址,那么只需指定邮箱所在列的下标即可。数组下标是以0开始的,邮箱位于数组的第二列,所以指用户邮箱下标为[1]。
通过这种CVS文件来存放数据可以方便的解决读取多列数据的问题。当然,用Excel文件存放这些数据也是一个不错的选择,只是所调用的模块就需要从csv切换为xlrd,针对Excel文件操作的方法也会有所不同。
3.5 读取xml文件
有时候我们需要读取的数据是不规则的。例如,我们需要一个配置文件来配置当前自动化测试脚本的URL、浏览器、登录的用户名和密码等,这时候就可以考虑选择使用XML文件来存放这些信息。
info.xml:
<?xml version="1.0" encoding="utf-8"?>
<info>
<base>
<platform>Windows</platform>
<browser>Chrome</browser>
<url>http://baidu.com</url>
<login username="admin" password="123456"/>
<login username="guest" password="654321"/>
</base>
<test>
<province>北京</province>
<province>广东</province>
<city>深圳</city>
<city>珠海</city>
<province>浙江</province>
<city>杭州</city>
</test>
</info>
下面以info.xml为例介绍读取XML文件的方法。
3.5.1 获取标签信息
from xml.dom import minidom #打开xml文档
dom = minidom.parse("info.xml") #得到文档元素对象
root = dom.documentElement print(root.nodeName)
print(root.nodeValue)
print(root.nodeType)
print(root.ELEMENT_NODE)
运行结果:

首先导入xml的minidom模块,用来处理XML文件,parse()用于打开一个XML文件,documentElement用于得到XML文件的唯一根元素。
每一个节点都有它的nodeName、nodeValue、nodeType等属性。nodeName为节点名称,nodeValue为节点的值,支队文本节点有效,nodeType为节点的类型。
3.5.2 获得任意标签名
from xml.dom import minidom #打开xml文档
dom = minidom.parse("info.xml") #得到文档元素对象
root = dom.documentElement tagname = root.getElementsByTagName('browser')
print(tagname[0].tagName) tagname = root.getElementsByTagName('login')
print(tagname[1].tagName) tagname = root.getElementsByTagName('province')
print(tagname[2].tagName)
运行结果:

getElementByTagName()可以通过标签名获取标签,它所获取的对象是以数组形式存放。假如“login”和“province”标签在info.xml文件中有多个,则可以通过指定数组的下标的方式获取某个具体标签。
getElementByTagName('province'):获得的是标签名为“province”的一组标签
getElementByTagName('province').tagname[0]:表示一组标签中的第一个
getElementByTagName('province').tagname[2]:表示一组标签中的第三个
3.5.3 获得标签的属性值
from xml.dom import minidom #打开xml文档
dom = minidom.parse("info.xml") #得到文档元素对象
root = dom.documentElement logins = root.getElementsByTagName('login') #获得login标签的username属性值
username = logins[0].getAttribute("username")
print(username) #获得login标签的password属性值
password = logins[0].getAttribute("password")
print(password) #获得第二个login标签的username属性值
username = logins[1].getAttribute("username")
print(username) #获得第二个login标签的password属性值
username = logins[1].getAttribute("password")
print(password)
运行结果:

getAttribute()方法用于获取元素的属性值。它和WebDriver中所提供的get_attribute()方法相似。
3.5.4 获得标签对之间的数据
from xml.dom import minidom #打开xml文档
dom = minidom.parse("info.xml") #得到文档元素对象
root = dom.documentElement provinces = dom.getElementsByTagName('province')
citys = dom.getElementsByTagName('city') #获得第二个province标签对的值
p2 = provinces[1].firstChild.data
print(p2) #获得第一个city标签对的值
c1 = citys[0].firstChild.data
print(c1) #获得第二个city标签对的值
c2 = citys[1].firstChild.data
print(c2)
运行结果:

firstChild属性返回被选节点的第一个子节点。data表示获取该节点的数据,它和WebDriver中提供的text方法类似。
Selenium(十四):自动化测试模型介绍、模块化驱动测试案例、数据驱动测试案例的更多相关文章
- 自动化测试架构设计 &&自动化持续集成测试任务实战[线性测试、模块驱动测试、数据驱动测试、关键字驱动测试]
1 为什么设计自动化测试架构 1.1 企业现状分析 压力大:产品需求不明确,上线时间确定,压力山大. 混乱:未立项,开发时间已过半,前期无控制,后期无保障. 疲于应付:开发人员交付的文件质量差,测试跟 ...
- web自动化测试-自动化测试模型介绍
一.线性测试 什么是线性测试? 通过录制或编写对应用程序的操作步骤产生相应的线性脚本,每个测试脚本相对独立,不产生依赖和调用,单纯的来模拟用户完整的操作场景 缺点 1.开发成本高,测试用例之间存在重复 ...
- Nodejs学习笔记(十四)— Mongoose介绍和入门
目录 简介 mongoose安装 连接字符串 Schema Model 常用数据库操作 插入 更新 删除 条件查询 数量查询 根据_id查询 模糊查询 分页查询 其它操作 写在之后... 简介 Mon ...
- Nodejs学习笔记(十四)—Mongoose介绍和入门
简介 Mongoose是在node.js异步环境下对mongodb进行便捷操作的对象模型工具 那么要使用它,首先你得装上node.js和mongodb,关于mongodb的安装和操作介绍可以参考:ht ...
- java selenium (十四) 处理Iframe 中的元素
有时候我们定位元素的时候,发现怎么都定位不了. 这时候你需要查一查你要定位的元素是否在iframe里面 阅读目录 什么是iframe iframe 就是HTML 中,用于网页嵌套网页的. 一个网页可以 ...
- 二十四、SSH介绍
1.ssh介绍: SSH先对联机数据包通过加密技术进行加密处理,加密后在进行数据传输,确保了传递的数据安全.(运维的一大重视点就是要对安全敏感) 在当前的生产环境运维工作中,绝大多数企业都是SSH协议 ...
- python+selenium十四:xpath和contains模糊匹配
xpath可以以标签定位,也可以@任意属性: 如:以input标签定位:driver.find_element_by_xpath("//input[@id='kw']") 如:@t ...
- 架构实战项目心得(十四):spring-boot结合Swagger2构建RESTful API测试体系
一.添加依赖: <dependency> <groupId>io.springfox</groupId> <artifactId>springfox-s ...
- 爬虫(十四):Scrapy框架(一) 初识Scrapy、第一个案例
1. Scrapy框架 Scrapy功能非常强大,爬取效率高,相关扩展组件多,可配置和可扩展程度非常高,它几乎可以应对所有反爬网站,是目前Python中使用最广泛的爬虫框架. 1.1 Scrapy介绍 ...
随机推荐
- Nginx入门简介和反向代理、负载均衡、动静分离理解
场景 Nginx简介 Nginx ("engine x")是一个高性能的 HTTP 和反向代理服务器 特点是占有内存少,并发能力强,事实上 nginx 的并发能力确实在同类型的网页 ...
- vue组件初始化过程
之前文章有写到vue构造函数的实例化过程,只是对vue实例做了个粗略的描述,并没有说明vue组件实例化的过程.本文主要对vue组件的实例化过程做一些简要的描述. 组件的实例化与vue构造函数的实例化, ...
- jTopo HTML5 Canvas 画图组件
jTopo是什么? jTopo(Javascript Topology library)是一款完全基于HTML5 Canvas的关系.拓扑图形化界面开发工具包. jTopo关注于数据的图形展示,它是面 ...
- IntelliJ IDEA 安装、配置和使用Lombok插件
Lombok 可用来帮助开发人员消除 Java 的重复代码,尤其是对于简单的 Java 对象(POJO),比如说getter/setter/toString等方法的编写.它通过注解实现这一目的.官网: ...
- inux 网络监控分析
一.sar -n:查看网卡流量 -n 参数,他有6个不同的开关:DEV | EDEV | NFS | NFSD | SOCK | ALL .DEV显示网络接口信息,EDEV显示关于网络错误的统计数据, ...
- Pycharm导入Django项目
Pycharm导入Django项目 添加项目:file-->open,找到项目所在的位置打开项目 添加django后台项目路径 file-->settings-->Languages ...
- global、nonlocal关键字
一:global:在函数内部引用/声明全局变量 在自定义函数时,有时候需要引用函数外的一些全局变量,如果不需要修改全局变量的内容,则可以直接引用,像下面这样: c = 999 def func(): ...
- VS2019 开发Django(三)------连接MySQL
导航:VS2019开发Django系列 下班回到家,洗漱完毕,夜已深.关于Django这个系列的博文,我心中的想法就是承接之前的微信小程序的内容,做一个服务端的管理中心,上新菜单,调整价格啊!之类的, ...
- Mysql的安装、配置、优化
Mysql的安装.配置.优化 安装步骤 1.先单击中的安装文件,如果是win7系统,请选择以管理员的方式运行. 2.大概需要30秒的时间,开始进入安装界面.请先把标红的打勾,好进行下一步的动作. 3. ...
- Often Misused:Spring Remote Service 经常被误用:Spring远程服务