hadoop2.9.0之前的版本yarn RM fairScheduler调度性能优化
对一般小公司来说 可能yarn调度能力足够了 但是对于大规模集群1000 or 2000+的话 yarn的调度性能捉襟见肘
恰好网上看到一篇很好的文章https://tech.meituan.com/2019/08/01/hadoop-yarn-scheduling-performance-optimization-practice.html
参考了YARN-5969 发现hadoop2.9.0已经修正了该issue 实测提高了调度性能
FairScheduler 调度方式有两种
心跳调度:Yarn的NodeManager会通过心跳的方式定期向ResourceManager汇报自身状态 伴随着这次rpc请求 会触发Resourcemanager 触发nodeUpdate()方法 为这个节点进行一次资源调度
持续调度:有一个固定守护线程每隔很短的时间调度 实时的资源分配,与NodeManager的心跳出发的调度相互异步并行进行
- 每次dataNode 发来心跳 时候作为一个event走下面方法
FairScheduler 类
@Override
public void handle(SchedulerEvent event) {
switch (event.getType()) {
case NODE_ADDED:
if (!(event instanceof NodeAddedSchedulerEvent)) {
throw new RuntimeException("Unexpected event type: " + event);
}
NodeAddedSchedulerEvent nodeAddedEvent = (NodeAddedSchedulerEvent)event;
addNode(nodeAddedEvent.getContainerReports(),
nodeAddedEvent.getAddedRMNode());
break;
case NODE_REMOVED:
if (!(event instanceof NodeRemovedSchedulerEvent)) {
throw new RuntimeException("Unexpected event type: " + event);
}
NodeRemovedSchedulerEvent nodeRemovedEvent = (NodeRemovedSchedulerEvent)event;
removeNode(nodeRemovedEvent.getRemovedRMNode());
break;
case NODE_UPDATE:
if (!(event instanceof NodeUpdateSchedulerEvent)) {
throw new RuntimeException("Unexpected event type: " + event);
}
NodeUpdateSchedulerEvent nodeUpdatedEvent = (NodeUpdateSchedulerEvent)event;
nodeUpdate(nodeUpdatedEvent.getRMNode());
break;
case APP_ADDED:
if (!(event instanceof AppAddedSchedulerEvent)) {
throw new RuntimeException("Unexpected event type: " + event);
}
AppAddedSchedulerEvent appAddedEvent = (AppAddedSchedulerEvent) event;
每次nodeUpdate 走的都是相同的逻辑
attemptScheduling(node) 持续调度跟心跳调度都走该方法
// If the node is decommissioning, send an update to have the total
// resource equal to the used resource, so no available resource to
// schedule.
if (nm.getState() == NodeState.DECOMMISSIONING) {
this.rmContext
.getDispatcher()
.getEventHandler()
.handle(
new RMNodeResourceUpdateEvent(nm.getNodeID(), ResourceOption
.newInstance(getSchedulerNode(nm.getNodeID())
.getUsedResource(), 0)));
} if (continuousSchedulingEnabled) {
if (!completedContainers.isEmpty()) { //持续调度开启时
attemptScheduling(node);
}
} else {
attemptScheduling(node); //心跳调度
} // Updating node resource utilization
node.setAggregatedContainersUtilization(
nm.getAggregatedContainersUtilization());
node.setNodeUtilization(nm.getNodeUtilization());
持续调度是一个单独的守护线程
间隔getContinuousSchedulingSleepMs()时间运行一次continuousSchedulingAttempt方法
/**
* Thread which attempts scheduling resources continuously,
* asynchronous to the node heartbeats.
*/
private class ContinuousSchedulingThread extends Thread { @Override
public void run() {
while (!Thread.currentThread().isInterrupted()) {
try {
continuousSchedulingAttempt();
Thread.sleep(getContinuousSchedulingSleepMs());
} catch (InterruptedException e) {
LOG.warn("Continuous scheduling thread interrupted. Exiting.", e);
return;
}
}
}
}
之后进行一次node节点 根据资源宽松情况的排序
void continuousSchedulingAttempt() throws InterruptedException {
long start = getClock().getTime();
List<NodeId> nodeIdList = new ArrayList<NodeId>(nodes.keySet());
// Sort the nodes by space available on them, so that we offer
// containers on emptier nodes first, facilitating an even spread. This
// requires holding the scheduler lock, so that the space available on a
// node doesn't change during the sort.
synchronized (this) {
Collections.sort(nodeIdList, nodeAvailableResourceComparator);
}
// iterate all nodes
for (NodeId nodeId : nodeIdList) {
FSSchedulerNode node = getFSSchedulerNode(nodeId);
try {
if (node != null && Resources.fitsIn(minimumAllocation,
node.getAvailableResource())) {
attemptScheduling(node);
}
} catch (Throwable ex) {
LOG.error("Error while attempting scheduling for node " + node +
": " + ex.toString(), ex);
if ((ex instanceof YarnRuntimeException) &&
(ex.getCause() instanceof InterruptedException)) {
// AsyncDispatcher translates InterruptedException to
// YarnRuntimeException with cause InterruptedException.
// Need to throw InterruptedException to stop schedulingThread.
throw (InterruptedException)ex.getCause();
}
}
}
依次对node遍历分配Container
queueMgr.getRootQueue().assignContainer(node) 从root遍历树 对抽象的应用资源遍历
boolean validReservation = false;
FSAppAttempt reservedAppSchedulable = node.getReservedAppSchedulable();
if (reservedAppSchedulable != null) {
validReservation = reservedAppSchedulable.assignReservedContainer(node);
}
if (!validReservation) {
// No reservation, schedule at queue which is farthest below fair share
int assignedContainers = 0;
Resource assignedResource = Resources.clone(Resources.none());
Resource maxResourcesToAssign =
Resources.multiply(node.getAvailableResource(), 0.5f);
while (node.getReservedContainer() == null) {
boolean assignedContainer = false;
Resource assignment = queueMgr.getRootQueue().assignContainer(node);
if (!assignment.equals(Resources.none())) { //判断是否分配到container
assignedContainers++;
assignedContainer = true;
Resources.addTo(assignedResource, assignment);
}
if (!assignedContainer) { break; }
if (!shouldContinueAssigning(assignedContainers,
maxResourcesToAssign, assignedResource)) {
break;
}
}
接下来在assignContainer 方法中对子队列使用特定的比较器排序这里是fairSchduler
@Override
public Resource assignContainer(FSSchedulerNode node) { 对于每一个服务器,对资源树进行一次递归搜索
Resource assigned = Resources.none(); // If this queue is over its limit, reject
if (!assignContainerPreCheck(node)) {
return assigned;
} // Hold the write lock when sorting childQueues
writeLock.lock();
try {
Collections.sort(childQueues, policy.getComparator());
} finally {
writeLock.unlock();
}
对队列下的app排序
/*
* We are releasing the lock between the sort and iteration of the
* "sorted" list. There could be changes to the list here:
* 1. Add a child queue to the end of the list, this doesn't affect
* container assignment.
* 2. Remove a child queue, this is probably good to take care of so we
* don't assign to a queue that is going to be removed shortly.
*/
readLock.lock();
try {
for (FSQueue child : childQueues) {
assigned = child.assignContainer(node);
if (!Resources.equals(assigned, Resources.none())) {
break;
}
}
} finally {
readLock.unlock();
}
return assigned;
assignContainer 可能传入的是app 可能传入的是一个队列 是队列的话 进行递归 直到找到app为止(root(FSParentQueue)节点递归调用assignContainer(),最终将到达最终叶子节点的assignContainer()方法,才真正开始进行分配)

优化一 : 优化队列比较器
我们在这里 关注的就是排序
hadoop2.8.4 排序类 FairSharePolicy中的 根据权重 需求的资源大小 和内存占比 进行排序 多次获取
getResourceUsage() 产生了大量重复计算 这个方法是一个动态获取的过程(耗时)
@Override
public int compare(Schedulable s1, Schedulable s2) {
double minShareRatio1, minShareRatio2;
double useToWeightRatio1, useToWeightRatio2;
Resource minShare1 = Resources.min(RESOURCE_CALCULATOR, null,
s1.getMinShare(), s1.getDemand());
Resource minShare2 = Resources.min(RESOURCE_CALCULATOR, null,
s2.getMinShare(), s2.getDemand());
boolean s1Needy = Resources.lessThan(RESOURCE_CALCULATOR, null,
s1.getResourceUsage(), minShare1);
boolean s2Needy = Resources.lessThan(RESOURCE_CALCULATOR, null,
s2.getResourceUsage(), minShare2);
minShareRatio1 = (double) s1.getResourceUsage().getMemorySize()
/ Resources.max(RESOURCE_CALCULATOR, null, minShare1, ONE).getMemorySize();
minShareRatio2 = (double) s2.getResourceUsage().getMemorySize()
/ Resources.max(RESOURCE_CALCULATOR, null, minShare2, ONE).getMemorySize();
useToWeightRatio1 = s1.getResourceUsage().getMemorySize() /
s1.getWeights().getWeight(ResourceType.MEMORY);
useToWeightRatio2 = s2.getResourceUsage().getMemorySize() /
s2.getWeights().getWeight(ResourceType.MEMORY);
int res = 0;
if (s1Needy && !s2Needy)
res = -1;
else if (s2Needy && !s1Needy)
res = 1;
else if (s1Needy && s2Needy)
res = (int) Math.signum(minShareRatio1 - minShareRatio2);
else
// Neither schedulable is needy
res = (int) Math.signum(useToWeightRatio1 - useToWeightRatio2);
if (res == 0) {
// Apps are tied in fairness ratio. Break the tie by submit time and job
// name to get a deterministic ordering, which is useful for unit tests.
res = (int) Math.signum(s1.getStartTime() - s2.getStartTime());
if (res == 0)
res = s1.getName().compareTo(s2.getName());
}
return res;
}
}
新版优化后如下
@Override
public int compare(Schedulable s1, Schedulable s2) {
int res = compareDemand(s1, s2); // Pre-compute resource usages to avoid duplicate calculation
Resource resourceUsage1 = s1.getResourceUsage();
Resource resourceUsage2 = s2.getResourceUsage(); if (res == 0) {
res = compareMinShareUsage(s1, s2, resourceUsage1, resourceUsage2);
} if (res == 0) {
res = compareFairShareUsage(s1, s2, resourceUsage1, resourceUsage2);
} // Break the tie by submit time
if (res == 0) {
res = (int) Math.signum(s1.getStartTime() - s2.getStartTime());
} // Break the tie by job name
if (res == 0) {
res = s1.getName().compareTo(s2.getName());
} return res;
} private int compareDemand(Schedulable s1, Schedulable s2) {
int res = 0;
Resource demand1 = s1.getDemand();
Resource demand2 = s2.getDemand();
if (demand1.equals(Resources.none()) && Resources.greaterThan(
RESOURCE_CALCULATOR, null, demand2, Resources.none())) {
res = 1;
} else if (demand2.equals(Resources.none()) && Resources.greaterThan(
RESOURCE_CALCULATOR, null, demand1, Resources.none())) {
res = -1;
}
return res;
} private int compareMinShareUsage(Schedulable s1, Schedulable s2,
Resource resourceUsage1, Resource resourceUsage2) {
int res;
Resource minShare1 = Resources.min(RESOURCE_CALCULATOR, null,
s1.getMinShare(), s1.getDemand());
Resource minShare2 = Resources.min(RESOURCE_CALCULATOR, null,
s2.getMinShare(), s2.getDemand());
boolean s1Needy = Resources.lessThan(RESOURCE_CALCULATOR, null,
resourceUsage1, minShare1);
boolean s2Needy = Resources.lessThan(RESOURCE_CALCULATOR, null,
resourceUsage2, minShare2); if (s1Needy && !s2Needy) {
res = -1;
} else if (s2Needy && !s1Needy) {
res = 1;
} else if (s1Needy && s2Needy) {
double minShareRatio1 = (double) resourceUsage1.getMemorySize() /
Resources.max(RESOURCE_CALCULATOR, null, minShare1, ONE)
.getMemorySize();
double minShareRatio2 = (double) resourceUsage2.getMemorySize() /
Resources.max(RESOURCE_CALCULATOR, null, minShare2, ONE)
.getMemorySize();
res = (int) Math.signum(minShareRatio1 - minShareRatio2);
} else {
res = 0;
} return res;
} /**
* To simplify computation, use weights instead of fair shares to calculate
* fair share usage.
*/
private int compareFairShareUsage(Schedulable s1, Schedulable s2,
Resource resourceUsage1, Resource resourceUsage2) {
double weight1 = s1.getWeights().getWeight(ResourceType.MEMORY);
double weight2 = s2.getWeights().getWeight(ResourceType.MEMORY);
double useToWeightRatio1;
double useToWeightRatio2;
if (weight1 > 0.0 && weight2 > 0.0) {
useToWeightRatio1 = resourceUsage1.getMemorySize() / weight1;
useToWeightRatio2 = resourceUsage2.getMemorySize() / weight2;
} else { // Either weight1 or weight2 equals to 0
if (weight1 == weight2) {
// If they have same weight, just compare usage
useToWeightRatio1 = resourceUsage1.getMemorySize();
useToWeightRatio2 = resourceUsage2.getMemorySize();
} else {
// By setting useToWeightRatios to negative weights, we give the
// zero-weight one less priority, so the non-zero weight one will
// be given slots.
useToWeightRatio1 = -weight1;
useToWeightRatio2 = -weight2;
}
} return (int) Math.signum(useToWeightRatio1 - useToWeightRatio2);
} }
用了测试环境集群 比较了修改前后两次队列排序耗时
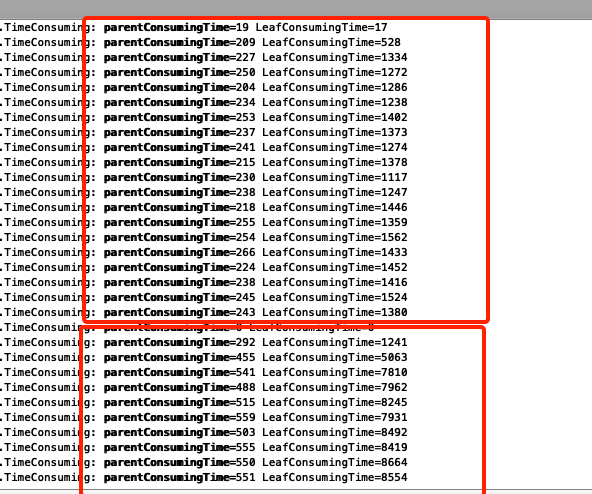
图中使用挫劣的方式比对 请观众凑合看吧^-^
上面红框里为 新版本 下面红框为老版本 虽然没有进行压测 但是在同样的调度任务前提下 是有说服力的 在大集群上每秒调度上千万乃至上亿次该方法时 调度优化变的明显
上线压测时 在1000队列 1500 pending任务600running任务时 调度性能提高了一倍 还是比较明显的提升的
优化二 : 优化yarn调度逻辑
思想:在大规模集群中 资源利用率表现的并不好,为了提高资源利用率,开启持续调度 然而实践发现 资源利用率是上去了但是 集群调度能力很弱 处理跟释放的container并没有提高
排查原因是心跳调度跟持续调度 走相同的synchronized 方法修饰的attemptScheduling 导致竞争锁 分配和释放都变的缓慢 且队列排序分配 在集群pending任务巨多时异常缓慢
优化:1,启用持续调度 禁用心跳调度
2,持续调度按批进行 间接减少队列排序造成的耗时影响
3. 释放不重要的锁 解放性能
说干就干
开启yarn的持续调度 配置如下:
<property>
<name>yarn.scheduler.fair.continuous-scheduling-enabled</name>
<value>true</value>
<discription>是否打开连续调度功能</discription>
</property>
<property>
持续调度 每5ms执行一次上述方法 对node依次迭代执行
void continuousSchedulingAttempt() throws InterruptedException {
long start = getClock().getTime();
List<NodeId> nodeIdList = new ArrayList<NodeId>(nodes.keySet());
// Sort the nodes by space available on them, so that we offer
// containers on emptier nodes first, facilitating an even spread. This
// requires holding the scheduler lock, so that the space available on a
// node doesn't change during the sort.
synchronized (this) {
Collections.sort(nodeIdList, nodeAvailableResourceComparator); //对所有node 根据资源排序
}
// iterate all nodes
for (NodeId nodeId : nodeIdList) { //遍历所有的node
FSSchedulerNode node = getFSSchedulerNode(nodeId);
try {
if (node != null && Resources.fitsIn(minimumAllocation,
node.getAvailableResource())) { //判断该node 上现有的资源是否大于最小配置资源单位
attemptScheduling(node); //执行ttemptScheduling方法
} } catch (Throwable ex) { LOG.error("Error while attempting scheduling for node " + node + ": " + ex.toString(), ex); if ((ex instanceof YarnRuntimeException) && (ex.getCause() instanceof InterruptedException)) { // AsyncDispatcher translates InterruptedException to // YarnRuntimeException with cause InterruptedException. // Need to throw InterruptedException to stop schedulingThread. throw (InterruptedException)ex.getCause(); } } }
下面看下attemptScheduling方法
@VisibleForTesting
synchronized void attemptScheduling(FSSchedulerNode node) {
if (rmContext.isWorkPreservingRecoveryEnabled()
&& !rmContext.isSchedulerReadyForAllocatingContainers()) {
return;
} final NodeId nodeID = node.getNodeID();
if (!nodes.containsKey(nodeID)) { //合法性
// The node might have just been removed while this thread was waiting
// on the synchronized lock before it entered this synchronized method
LOG.info("Skipping scheduling as the node " + nodeID +
" has been removed");
return;
} // Assign new containers...
// 1. Check for reserved applications
// 2. Schedule if there are no reservations boolean validReservation = false;
FSAppAttempt reservedAppSchedulable = node.getReservedAppSchedulable();
if (reservedAppSchedulable != null) {
validReservation = reservedAppSchedulable.assignReservedContainer(node);
}
if (!validReservation) { //合法性判断
// No reservation, schedule at queue which is farthest below fair share
int assignedContainers = 0;
Resource assignedResource = Resources.clone(Resources.none());
Resource maxResourcesToAssign =
Resources.multiply(node.getAvailableResource(), 0.5f); //默认使用该node最大50%的资源
while (node.getReservedContainer() == null) {
boolean assignedContainer = false;
Resource assignment = queueMgr.getRootQueue().assignContainer(node); //主要方法 依次对root树 遍历直到app 对该node上分配container
if (!assignment.equals(Resources.none())) { //分配到资源
assignedContainers++; //分配到的container个数增1
assignedContainer = true;
Resources.addTo(assignedResource, assignment);
}
if (!assignedContainer) { break; } //未匹配到 跳出
if (!shouldContinueAssigning(assignedContainers, //根据相关配置判断 现在分配的container个数 是否超出node上配置最大数 或node上的可用资源是否超出最小的配置资源
maxResourcesToAssign, assignedResource)) {
break;
}
}
}
updateRootQueueMetrics();
}
针对上面源码 修改为如下内容:
interface Schedulable 接口新增 方法
/**
* Assign list container list this node if possible, and return the amount of
* resources assigned.
*/
public List<Resource> assignContainers(List<FSSchedulerNode> nodes);
@VisibleForTesting
protected void attemptSchedulings(ArrayList<FSSchedulerNode> fsSchedulerNodeList) {
if (rmContext.isWorkPreservingRecoveryEnabled()
&& !rmContext.isSchedulerReadyForAllocatingContainers()) {
return;
}
List<FSSchedulerNode> fsSchedulerNodes = new ArrayList(); //定义个新集合 添加通过检查的node 抽象对象
fsSchedulerNodeList.stream().forEach(node -> {
final NodeId nodeID = node.getNodeID();
if (nodes.containsKey(nodeID)) {
// Assign new containers...// 1. Check for reserved applications
// 2. Schedule if there are no reservations
boolean validReservation = false;
FSAppAttempt reservedAppSchedulable = node.getReservedAppSchedulable();
if (reservedAppSchedulable != null) {
validReservation = reservedAppSchedulable.assignReservedContainer(node);
}
if (!validReservation) { //通过合法检查
if (node.getReservedContainer() == null) { //该node上 没有被某个container预留
fsSchedulerNodes.add(node);
}
}
} else {
LOG.info("Skipping scheduling as the node " + nodeID +
" has been removed");
}
});
if (fsSchedulerNodes.isEmpty()) {
LOG.error("Handle fsSchedulerNodes empty and return");
return;
}
LOG.info("符合条件的nodes:" + fsSchedulerNodeList.size());
List<Resource> resources = queueMgr.getRootQueue().assignContainers(fsSchedulerNodes); //传入node的集合 批量操作
fsOpDurations.addDistributiveContainer(resources.size());
LOG.info("本次分配的container count:" + resources.size());
updateRootQueueMetrics();
}
FSParentQueue 类中 添加实现
@Override
public List<Resource> assignContainers(List<FSSchedulerNode> nodes) {
List<Resource> assignedsNeed = new ArrayList<>();
ArrayList<FSSchedulerNode> fsSchedulerNodes = new ArrayList<>();
for (FSSchedulerNode node : nodes) {
if (assignContainerPreCheck(node)) {
fsSchedulerNodes.add(node);
}
}
if (fsSchedulerNodes.isEmpty()) {
LOG.info("Nodes is empty, skip this assign around");
return assignedsNeed;
} // Hold the write lock when sorting childQueues
writeLock.lock();
try {
Collections.sort(childQueues, policy.getComparator()); //排序又见排序 哈哈
} finally {
writeLock.unlock();
} /*
* We are releasing the lock between the sort and iteration of the
* "sorted" list. There could be changes to the list here:
* 1. Add a child queue to the end of the list, this doesn't affect
* container assignment.
* 2. Remove a child queue, this is probably good to take care of so we
* don't assign to a queue that is going to be removed shortly.
*/
readLock.lock();
try {
for (FSQueue child : childQueues) {
List<Resource> assigneds = child.assignContainers(fsSchedulerNodes); //同样传入node集合
if (!assigneds.isEmpty()) {
for (Resource assign : assigneds) {
assignedsNeed.add(assign);
}
break;
}
}
} finally {
readLock.unlock();
} return assignedsNeed;
}
app最终在FSLeafQueue节点上得到处理
@Override
public List<Resource> assignContainers(List<FSSchedulerNode> nodes) {
Resource assigned = Resources.none();
List<Resource> assigneds = new ArrayList<>();
ArrayList<FSSchedulerNode> fsSchedulerNodes = new ArrayList<>();
for (FSSchedulerNode node : nodes) {
if (assignContainerPreCheck(node)) {
fsSchedulerNodes.add(node);
}
}
if (fsSchedulerNodes.isEmpty()) {
LOG.info("Nodes is empty, skip this assign around");
return assigneds;
}
// Apps that have resource demands.
TreeSet<FSAppAttempt> pendingForResourceApps =
new TreeSet<FSAppAttempt>(policy.getComparator());
readLock.lock();
try {
for (FSAppAttempt app : runnableApps) { //所有的app running or pending 队列 进行依次排序
Resource pending = app.getAppAttemptResourceUsage().getPending();
if (!pending.equals(Resources.none())) { //有资源需求的加入排序队列
pendingForResourceApps.add(app);
}
}
} finally {
readLock.unlock();
} int count = 0; //每个node 分配container计数
Set<String> repeatApp = new HashSet<>(); //定义去重集合
for (FSSchedulerNode node : fsSchedulerNodes) { //node 遍历
count = 0;
for (FSAppAttempt sched : pendingForResourceApps) { //app遍历
// One node just allocate for one app once
if (repeatApp.contains(sched.getId())) { //去重
continue;
}
if (SchedulerAppUtils.isPlaceBlacklisted(sched, node, LOG)) { //判断app有没有在node黑名单里
continue;
}
if (node.getReservedContainer() == null
&& Resources.fitsIn(minimumAllocation, node.getAvailableResource())) { //判断node上还有没有资源
assigned = sched.assignContainer(node); //具体分配container方法
if (!assigned.equals(Resources.none())) {//给container 在node上分配到了资源
count++;
repeatApp.add(sched.getId());
assigneds.add(assigned);
if (LOG.isDebugEnabled()) {
LOG.debug("Assigned container in queue:" + getName() + " " +
"container:" + assigned);
}
}
}
if (count >= maxNodeContainerAssign) { //node 分配的数量 超出最大的配置数 跳出 给下一node 分配
break;
}
}
}
return assigneds;
}
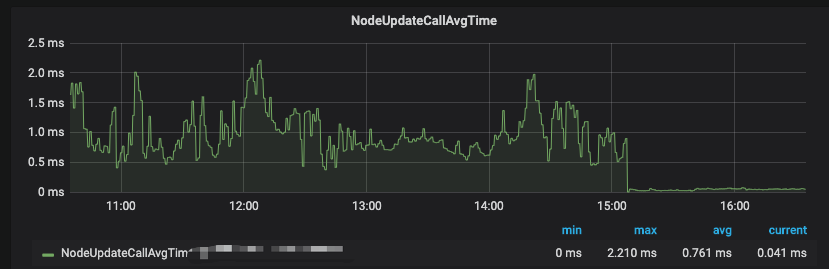
这轮优化 完毕 对比之前 调度性能提高了四倍样子 线上的积压问题得到有效解决
优化后nodeUpdate耗时对比如下
hadoop2.9.0之前的版本yarn RM fairScheduler调度性能优化的更多相关文章
- hadoop2.6.0高可靠及yarn 高可靠搭建
以前用hadoop2.2.0只搭建了hadoop的高可用,但在hadoop2.2.0中始终没有完成YARN HA的搭建,直接下载了hadoop最新稳定版本2.6.0完成了YARN HA及HADOOP ...
- Hadoop YARN:调度性能优化实践(转)
https://tech.meituan.com/2019/08/01/hadoop-yarn-scheduling-performance-optimization-practice.html 文章 ...
- Hadoop-2.2.0中国文档—— MapReduce 下一代 -- 公平调度
目的 此文档描写叙述了 FairScheduler, Hadoop 的一个可插入式的调度器,同意 YARN 应用在一个大集群中公平地共享资源. 简单介绍 公平调度是一种分配资源给应用的方法.以致到最后 ...
- Hadoop-2.2.0中文文档—— MapReduce 下一代--容量调度器
目的 这份文档描写叙述 CapacityScheduler,一个为Hadoop能同意多用户安全地共享一个大集群的插件式调度器,如他们的应用能适时被分配限制的容量. 概述 CapacitySchedul ...
- Hadoop2.2.0(yarn)编译部署手册
Created on 2014-3-30URL : http://www.cnblogs.com/zhxfl/p/3633919.html @author: zhxfl Hadoop-2.2编译 ...
- hadoop2.6.0实践:004 启动伪分布式hadoop的进程
[hadoop@LexiaofeiMaster hadoop-2.6.0]$ start-dfs.shStarting namenodes on [localhost]localhost: start ...
- CentOS6.4编译Hadoop-2.4.0
因为搭建Hadoop环境的时候,所用的系统镜像是emi-centos-6.4-x86_64,是64位的,而hadoop是默认是32的安装包.这导致我们很多操作都会遇到这个问题(Java HotSp ...
- Hadoop 新生报道(二) hadoop2.6.0 集群系统版本安装和启动配置
本次基于Hadoop2.6版本进行分布式配置,Linux系统是基于CentOS6.5 64位的版本.在此设置一个主节点和两个从节点. 准备3台虚拟机,分别为: 主机名 IP地址 master 192. ...
- Spark on YARN模式的安装(spark-1.6.1-bin-hadoop2.6.tgz + hadoop-2.6.0.tar.gz)(master、slave1和slave2)(博主推荐)
说白了 Spark on YARN模式的安装,它是非常的简单,只需要下载编译好Spark安装包,在一台带有Hadoop YARN客户端的的机器上运行即可. Spark on YARN简介与运行wor ...
随机推荐
- Vue中使用key的作用
key的作用是为了在diff算法执行时更快的找到对应的节点,提高diff速度 key具有唯一性 vue中循环需加 :key=“唯一标识” ,唯一标识可以使item里面id index 等,因为vue组 ...
- 【JAVA基础】JAVA基础语法
1.1 Java语言概述什么是Java语言Java语言是美国Sun公司(Stanford University Network),在1995年推出的高级的编程语言. Java语言发展历史1995年Su ...
- 基于 HTML5 的工控物联网的隧道监控实战
前言 监控隧道内的车道堵塞情况.隧道内的车祸现场,在隧道中显示当前车祸位置并在隧道口给与提示等等功能都是非常有必要的.这个隧道 Demo 的主要内容包括:照明.风机.车道指示灯.交通信号灯.情报板.消 ...
- selenium3与Python3实战 web自动化测试框架 ☝☝☝
selenium3与Python3实战 web自动化测试框架 selenium3与Python3实战 web自动化测试框架 学习 教程 一.环境搭建 1.selenium环境搭建 Client: py ...
- PHP get_object_vars 和 get_class_vars
<?php class Girl { public $id = 1; public $name = 'zhy'; } $girl = new Girl(); var_dump(get_class ...
- 关于seaJs合并压缩(gulp-seajs-combine )路径与文件ID匹配问题。
前段时间和有大家介绍过用 gulp-seajs-combine 来打包seaJs文件.大家会发现合并seaJs一个很奇怪的现象,那就是它的 ID和路径匹配原则.使得有些文件已经合并过去了,但还是会提示 ...
- [NOIp2017] luogu P3952 时间复杂度
跪着看评测很优秀. 题目描述 给你若干个程序,这些程序只有 For 循环,求这些程序的时间复杂度. Solution 大模拟.讲下细节. flag[i]flag[i]flag[i] 表示第 iii 位 ...
- [Luogu2323] [HNOI2006]公路修建问题
题目描述 输入输出格式 输入格式: 在实际评测时,将只会有m-1行公路 输出格式: 输入输出样例 输入样例#1: 复制 4 2 5 1 2 6 5 1 3 3 1 2 3 9 4 2 4 6 1 输出 ...
- 存储过程导出数据到csv
USE [database] GO SET ANSI_NULLS ON GO SET QUOTED_IDENTIFIER ON GO -- P_AutoInspect_LogToFilePath 'F ...
- asp.net core mvc中自定义ActionResult
在GitHub上有个项目,本来是作为自己研究学习.net core的Demo,没想到很多同学在看,还给了很多星,所以觉得应该升成3.0,整理一下,写成博分享给学习.net core的同学们. 项目名称 ...