Flink中TaskManager端执行用户逻辑过程(源码分析)
TaskManager接收到来自JobManager的jobGraph转换得到的TDD对象,启动了任务,在StreamInputProcessor类的processInput()方法中
通过一个while(true)中不停的拉取上游的数据,然后调用streamOperator.processElement(record)调用用户实现的方法去处理数据拉取的数据
首先先来看下这个operator对象

然后看看OneInputStreamOperator类的UML
这里所有的实现类没有全部列出,只列了一些代表
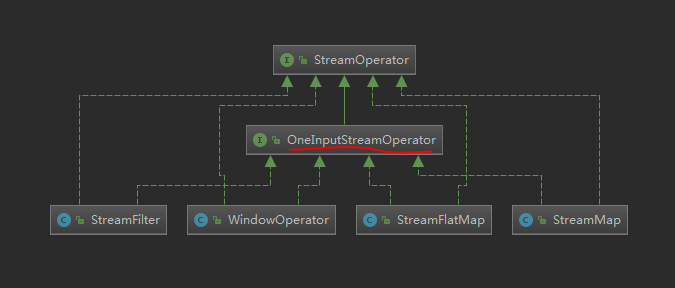
看到这里,写过Flink的streamAPI的同学,肯定感觉到很熟悉!!!!!!
这里!不就是我们常写flink代码的那些算子嘛
对没有错,我们程序中实现的那些算子逻辑,最后都会被封装成一个OneInputStreamOperator,这里具体看一个最熟悉的Fliter
来看一下StreamFilter的processElement方法
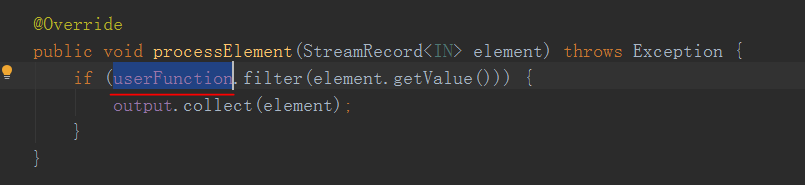
!!!这里传入一个数据后,这个userFunction调用了filter方法并且把数据放进去了
当返回true通过这个output.collect发送出去了
这不就对应了我们用户自己实现的filter算子嘛,没错这个方法其实就是客户端的filter方法,这个userFunction包含了用户实现filter算子的逻辑
(!!!!!就是说这个processElement方法会调用用户的逻辑)
(所以这个userFunction可以带上client的方法实现,这对我们很重要,特别是对flink源码修改,为clientApi添加新功能方法,运行时可以通过这里拿到)
继续
来看看这个output.collect()方法

然后

看到这个,等等等等
我不是从这个processElement()方法进来的吗,怎么又开始调processElement()方法了
难道递归了? 不对不对
这里operator不是上一个operator了,而是这个output对象的(这里是chainOutPut)
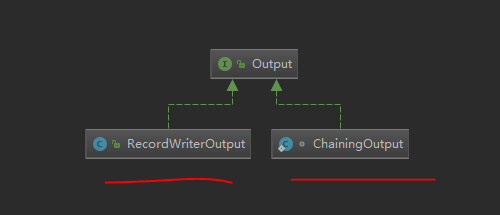
看下这个output对象

看下UML类图,也是只列举了重要的
先看chainingOutPut的属性
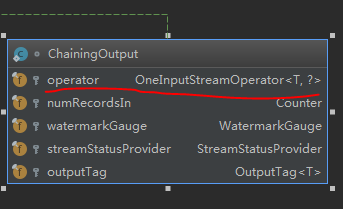
发现了又出现了OneInputStreamOperator对象
看到这个实现类的名字!chain联想起了什么
Flink会将可以chain在一起的算子在streamGraph转换成jobGraph的时候根据条件chain在一起
一惊!
来分别看一下ChainingOutPut和RecordWriterOutput的collect()方法有什么区别
在chain中

在RecordWriter中

这里chain的ouput,又继续调用了下一个operator的processElement方法,然后又在processElement方法中又调用output.collect( ),collect中又调用了下一个operator的processElement方法
整个过程就是个无限的循环,直到,某一个operator的ouput不为ChainingOutPut,当变为RecordWriterOutput时
上面看到RecordWriterOutput的processElement直接emit发送出去了这个数据,再也没有继续调用processElement方法了
这里也就对应了,flink中的责任链,chain在一起的算子会一个接着一个执行,直到无法chain,就会往下游发送emit了
来看一下UML类图帮助理解
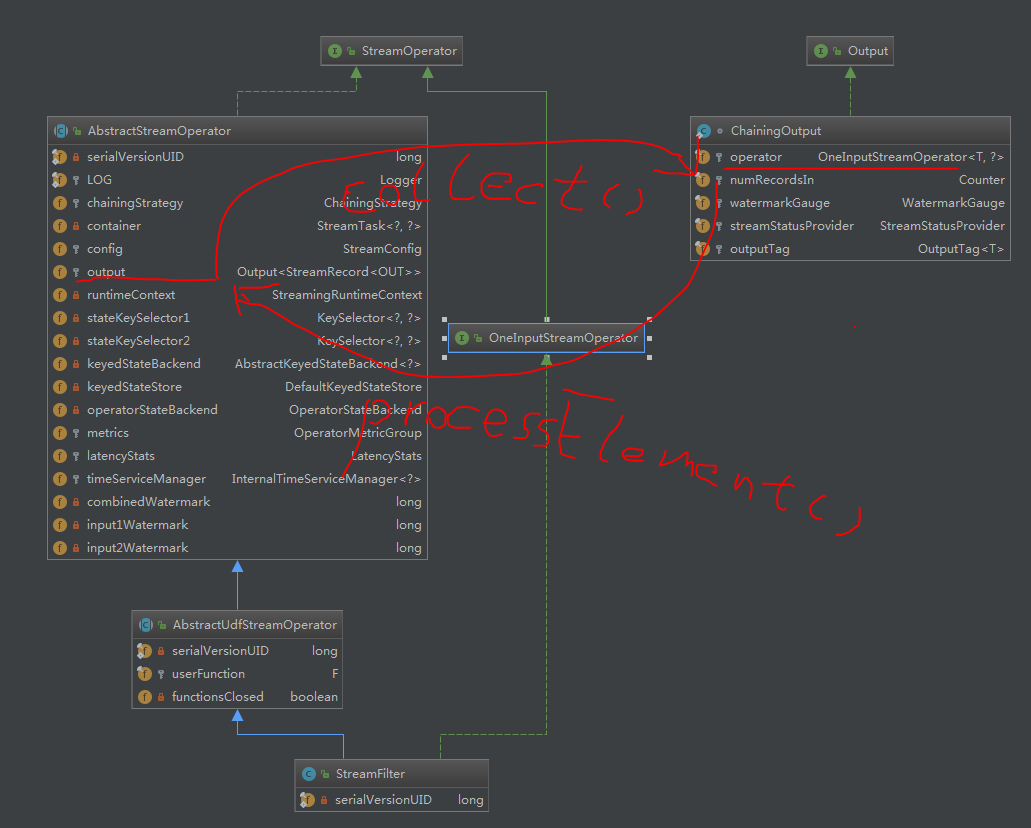
里中有我,我中有你,一直相互调用直到无法chain,然后emit往下游发送(这里肯定就有发送端的反压逻辑,以后随缘更新)
那这里的循环调用理解了就会想,那如何确定第一个operator调用,然后进入整个调用链呢
回到TaskManager接收到JobManager的TDD以后初始化整个任务的时候
StreamTask.java中invoke方法中

先是初始化了一个OperatorChain,里面其实就是一个数组StreamOperator

在他初始化的时候,其实就是为我们所有的streamOutputs设置了他的output以及会根据jobManager发送过来的TDD(包含信息)
设置成对应的ChainingOutPut还是RecordWriterOutput,chainOutput会设置他的的operator
然后获取了getHeadOperator()其实就是获取了他调用连中的第一个
然后在

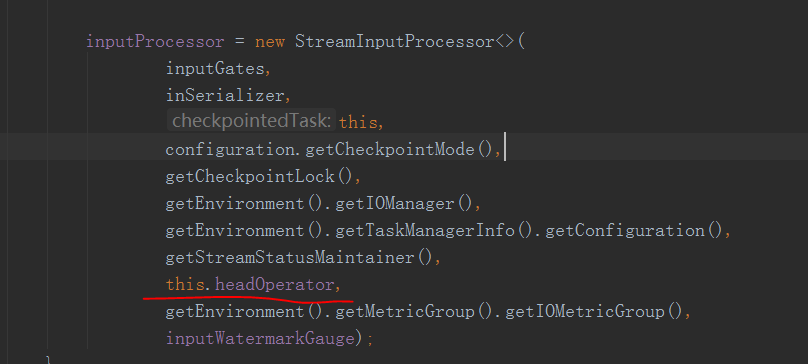
将这个第一个operator关联到了inputProcessor对象里面
后面就简单了在inputProcessor.processInput中就进入了while(true)循环拉取上游数据的逻辑
然后

在这里调用的第一个processElement方法就是我们的那个headOperator
这样整个调用责任链就开始从第一个Operator运行起来了
Flink中TaskManager端执行用户逻辑过程(源码分析)的更多相关文章
- Flink中接收端反压以及Credit机制 (源码分析)
先上一张图整体了解Flink中的反压 可以看到每个task都会有自己对应的IG(inputgate)对接上游发送过来的数据和RS(resultPatation)对接往下游发送数据, 整个反压机制通 ...
- (3.10)mysql基础深入——mysqld 服务器与客户端连接过程 源码分析【待写】
(3.10)mysql基础深入——mysqld 服务器与客户端连接过程 源码分析[待写]
- Netty源码分析 (七)----- read过程 源码分析
在上一篇文章中,我们分析了processSelectedKey这个方法中的accept过程,本文将分析一下work线程中的read过程. private static void processSele ...
- Servlet容器Tomcat中web.xml中url-pattern的配置详解[附带源码分析]
目录 前言 现象 源码分析 实战例子 总结 参考资料 前言 今天研究了一下tomcat上web.xml配置文件中url-pattern的问题. 这个问题其实毕业前就困扰着我,当时忙于找工作. 找到工作 ...
- 时间轮机制在Redisson分布式锁中的实际应用以及时间轮源码分析
本篇文章主要基于Redisson中实现的分布式锁机制继续进行展开,分析Redisson中的时间轮机制. 在前面分析的Redisson的分布式锁实现中,有一个Watch Dog机制来对锁键进行续约,代码 ...
- HashMap在JDK1.8中并发操作,代码测试以及源码分析
HashMap在JDK1.8中并发操作不会出现死循环,只会出现缺数据.测试如下: package JDKSource; import java.util.HashMap; import java.ut ...
- 从flink-example分析flink组件(3)WordCount 流式实战及源码分析
前面介绍了批量处理的WorkCount是如何执行的 <从flink-example分析flink组件(1)WordCount batch实战及源码分析> <从flink-exampl ...
- YARN(MapReduce 2)运行MapReduce的过程-源码分析
这是我的分析,当然查阅书籍和网络.如有什么不对的,请各位批评指正.以下的类有的并不完全,只列出重要的方法. 如要转载,请注上作者以及出处. 一.源码阅读环境 需要安装jdk1.7.0版本及其以上版本, ...
- 面试高频SpringMVC执行流程最优解(源码分析)
文章已托管到GitHub,大家可以去GitHub查看阅读,欢迎老板们前来Star! 搜索关注微信公众号 码出Offer 领取各种学习资料! SpringMVC执行流程 SpringMVC概述 Spri ...
随机推荐
- Angualr6表单提交验证并跳转
在Angular6中,使用NG-ZRROR作为前端开发框架,在进行表单开发时遇到了一些问题,最后解决了,在此记录. 1.表单构造: 引入forms: import { FormGroup, FormB ...
- The philosophy of ranking
In the book Decision Quality, one will be trained to have three decision making system; one of them ...
- 什么是Singleton?
Singleton:在Java中即指单例设计模式,它是软件开发中最常用的设计模式之一. 单:指唯一 例:指实例 单例设计模式,即某个类在整个系统中只能有一个实例对象可被获取和使用的代码模式. 要点: ...
- 防止sql注入:替换危险字符
在用户名或者密码框中输入“11‘ or ’1‘ = '1”时,生成的sql语句将为“selec * from userInfo where name = '11' or '1' = '1' and p ...
- Asp.Net Core WebAPI+PostgreSQL部署在Docker中
PostgreSQL是一个功能强大的开源数据库系统.它支持了大多数的SQL:2008标准的数据类型,包括整型.数值值.布尔型.字节型.字符型.日期型.时间间隔型和时间型,它也支持存储二进制的大对像, ...
- 章节十五、9-自定义Loggers
一.如何给不同的包设置不同的日志级别? 1.针对不同的包来记录不同级别的日志信息 2.在日志xml配置文件中加入配置信息(红色标注) <?xml version="1.0" ...
- 从0到1发布一个npm包
从0到1发布一个npm包 author: @TiffanysBear 最近在项目业务中有遇到一些问题,一些通用的方法或者封装的模块在PC.WAP甚至是APP中都需要使用,但是对于业务的PC.WAP.A ...
- unsqueeze 和 squeeze
squeeze压缩的意思 就是在第几维为1 去掉 unsqueeze 解缩 在第几维增加 变成*1 squeeze用法 c = b.view(1, 1, 1, 2, 3) c.squeeze(0) # ...
- Python模块——HashLib(摘要算法)与base64
摘要算法(hashlib) Python的hashlib提供了常见的摘要算法,如MD5,SHA1等等. 什么是摘要算法呢?摘要算法又称哈希算法.散列算法.它通过一个函数,把任意长度的数据转换为一个长度 ...
- 在CentOS 7 / RHEL 7安装PostgreSQL 10
CentOS 到了7.x版本, PostgreSQL也来到了10.x版本. 前些天MySQL都直接跨到了8.0版本. 本文是一篇在CentOS 7.4上安装安装PostgreSQL 10.3 的教程. ...