分布式任务队列--Celery的学习笔记
一、Celery简介
Celery是一个简单,灵活,可靠的分布式系统,用于处理大量消息,同时为操作提供维护此类系统所需的工具。它是一个任务队列,专注于实时处理,同时还支持任务调度。
所谓任务队列,是一个逻辑上的概念,可以将抽象中的任务发送到指定的执行任务的组件,任务队列可以跨线程或机器运行。
Celery是基于Python开发的分布式异步消息任务队列,通过它可以轻松的实现任务的异步处理, 如果你的业务场景中需要用到异步任务,就可以考虑使用celery。
二、Celery使用场景
1.高并发的请求任务,比如需要发送大量请求的网络爬虫,就可以使用Celery来加速爬取。
2.异步任务,将耗时的操作交给Celery来完成,比如发送/接收邮件、消息推送等等。
3.定时任务,需要定时运行的程序,比如每天定时执行爬虫爬取数据。
三、Celery架构
下图是我找到的一张表示Celery架构的图:
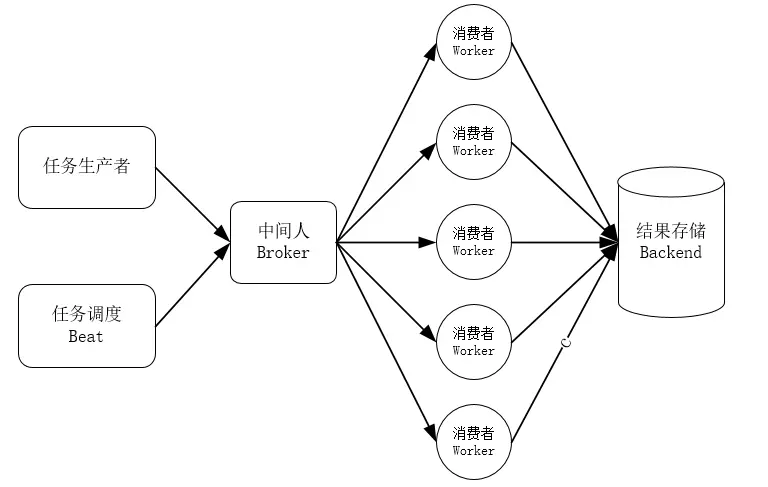
任务生产者:产生任务并且把任务提交到任务队列的就是任务生产者。
任务调度Beat:Celery会根据配置文件对任务进行调配,可以按一定时间间隔周期性地执行某些任务。
中间人Broker:Celery使用消息进行通信,需要中间人在客户端和Worker之间进行传递,接收客户端发送过来的任务,并将任务分配给Worker。
在Celery的文档中,可以找到官方给出的实现Broker的工具有:
| 名称 | 状态 | 监控 | 远程控制 |
| RabbitMQ | 稳定 | 是 | 是 |
| Redis | 稳定 | 是 | 是 |
| Amazon SQS | 稳定 | 否 | 否 |
| Zookeeper | 实验性 | 否 | 否 |
消费者Worker:Worker是执行任务的单元,在Celery任务队列中属于消费者。Worker会不断地监听队列,一旦有任务添加进来,就会将任务取出来进行执行。Worker还可以运行在多台机器上,只要它们都指向同一个Broker就可以。
结果存储Backend:结果存储Backend,顾名思义就是将Worker执行后得到的结果存储起来。Celery中有几个内置的结果存储可供选择,包括SQLAlchemy / Django ORM、Redis、RabbitMQ、Mamcached等。
四、Celery安装
Celery4.0版本是支持Python2.7的最后一个版本,所以如果你还在用py2的话,可能要选择安装Celery3或者更早的版本。我本人用的Python版本是Python3.7,然后安装的Celery版本是4.3。安装的话使用pip安装就好:
pip install celery
如果pip安装出错的话,可以去这个网址进行下载。在使用pip安装的时候会自动安装一些相关依赖,如果这些依赖安装出错的话,搜一下相应版本的Wheel文件下载安装即可。
中间件Broker我选择使用的是Redis,这里就不说Redis怎么安装了,上一篇博客中有Ubuntu下安装Redis的介绍。
五、Celery使用示例
1.应用
在使用Celery的时候,第一件事是要创建一个Celery实例,一般称之为应用,简称为app。创建一个test.py,其中代码如下:
from celery import Celery
app = Celery("test", broker="redis://127.0.0.1:6379", backend="redis://127.0.0.1:6379")
@app.task
def add(x, y):
return x + y
2.运行Celery服务器
在创建好应用之后,就可以使用Celery命令执行程序运行Worker了:
celery -A test worker -l info
运行后可以看到如下图:

有关可用命令行选项的完整列表,执行如下命令:
celery worker --help
3.调用任务
要调用任务,可以使用delay()方法。

该任务会返回一个AsyncResult实例,可用于查询任务状态、获取任务返回值等。此时查看前面运行的服务器,会看到有如下信息:
Received task: test.add[e7f01461-8c4d-4c29-ab6b-27be5084ecd9]
Task test.add[e7f01461-8c4d-4c29-ab6b-27be5084ecd9] succeeded in 0.006505205000166825s: 5
4.查看结果
在前面定义的时候,已经选择使用Redis作为结果后端了,所以任务执行后的结果会保存到Redis中。而且,在调用任务的时候,还可以进行如下操作:

其中ready()方法会返回该任务是否已经执行,get()方法则会获取任务返回的结果。
5.配置文件
由于Celery的配置信息比较多,因此一般会创建一个配置文件来保存这些配置信息,通常会命名为celeryconfig.py。在test.py所在文件夹下新建配置文件celeryconfig.py,其中的代码如下:
# broker(消息中间件来接收和发送任务消息)
BROKER_URL = 'redis://127.0.0.1:6379'
# backend(存储worker执行的结果)
CELERY_RESULT_BACKEND = 'redis://127.0.0.1:6379' # 设置时间参照,不设置默认使用的UTC时间
CELERY_TIMEZONE = 'Asia/Shanghai'
# 指定任务的序列化
CELERY_TASK_SERIALIZER = 'json'
# 指定执行结果的序列化
CELERY_RESULT_SERIALIZER = 'json'
然后修改下test.py中的代码:
from celery import Celery
app = Celery("test")
app.config_from_object("celerystudy.celeryconfig")
@app.task
def add(x, y):
return x + y
分布式任务队列--Celery的学习笔记的更多相关文章
- [源码解析] 并行分布式任务队列 Celery 之 多进程模型
[源码解析] 并行分布式任务队列 Celery 之 多进程模型 目录 [源码解析] 并行分布式任务队列 Celery 之 多进程模型 0x00 摘要 0x01 Consumer 组件 Pool boo ...
- [源码分析] 分布式任务队列 Celery 多线程模型 之 子进程
[源码分析] 分布式任务队列 Celery 多线程模型 之 子进程 目录 [源码分析] 分布式任务队列 Celery 多线程模型 之 子进程 0x00 摘要 0x01 前文回顾 1.1 基类作用 1. ...
- 分布式任务调度平台XXL-JOB学习笔记一
分布式任务调度平台XXL-JOB学习笔记一 XXL-JOB是一个轻量级分布式任务调度平台,其核心设计目标是开发迅速.学习简单.轻量级.易扩展.现已开放源代码并接入多家公司线上产品线,开箱即用.码云地址 ...
- 分布式任务队列 Celery —— Task对象
转载至 JmilkFan_范桂飓:http://blog.csdn.net/jmilk 目录 目录 前文列表 前言 Task 的实例化 任务的名字 任务的绑定 任务的重试 任务的请求上下文 任务的继 ...
- 分布式任务队列 Celery —— 深入 Task
目录 目录 前文列表 前言 Task 的实例化 任务的名字 任务的绑定 任务的重试 任务的请求上下文 任务的继承 前文列表 分布式任务队列 Celery 分布式任务队列 Celery -- 详解工作流 ...
- 分布式任务队列 Celery —— 应用基础
目录 目录 前文列表 前言 Celery 的周期定时任务 Celery 的同步调用 Celery 结果储存 Celery 的监控 Celery 的调试 前文列表 分布式任务队列 Celery 分布式任 ...
- 分布式任务队列 Celery —— 详解工作流
目录 目录 前文列表 前言 任务签名 signature 偏函数 回调函数 Celery 工作流 group 任务组 chain 任务链 chord 复合任务 chunks 任务块 mapstarma ...
- 分布式任务队列 Celery
目录 目录 前言 简介 Celery 的应用场景 架构组成 Celery 应用基础 前言 分布式任务队列 Celery,Python 开发者必备技能,结合之前的 RabbitMQ 系列,深入梳理一下 ...
- [源码解析] 分布式任务队列 Celery 之启动 Consumer
[源码解析] 分布式任务队列 Celery 之启动 Consumer 目录 [源码解析] 分布式任务队列 Celery 之启动 Consumer 0x00 摘要 0x01 综述 1.1 kombu.c ...
随机推荐
- 【NOIP2015】扫雷游戏-C++
描述 扫雷游戏是一款十分经典的单机小游戏.在 n 行 m 列的雷区中有一些格子含有地雷 (称之为地雷格),其他格子不含地雷(称之为非地雷格).玩家翻开一个非地雷格时, 该格将会出现一个数字--提示周围 ...
- [原创]lvs+ospf+nginx实现高可用大流量web架构
lvs+ospf+nginx实现高可用大流量web架构配置总概述 架构图: 配置如下: .quagga之zebra配置: # cat /etc/quagga/zebra.conf ! ! Zebra ...
- 【原创】一个shell脚本记录(实现rsync生产文件批量迁移功能)
#!/bin/bash #Date:2018-01-08 #Author:xxxxxx #Function:xxxxxx #Change:2018-01-17 # #设置忽略CTRL+C信号 trap ...
- 数据结构-二叉树(1)以及前序、中序、后序遍历(python实现)
上篇文章我们介绍了树的概念,今天我们来介绍一种特殊的树--二叉树,二叉树的应用很广,有很多特性.今天我们一一来为大家介绍. 二叉树 顾名思义,二叉树就是只有两个节点的树,两个节点分别为左节点和右节点, ...
- 洛谷P2055 [ZJOI2009]假期的宿舍 题解
题目链接: https://www.luogu.org/problemnew/show/P2055 分析: 这道题比较简单,二分图的练习题(当然最大流同理). 易得我们可以将人放在一侧,床放在一侧. ...
- canvas动画:气泡上升效果
HTML5中的canvas真是个很强大的东西呢! 这几天突发奇想想做一个气泡上升的动画,经过许久的思考和多次失败,终于做出了如下效果 由于是录制的gif图,看着会有点卡顿,实际演示是很自然的 想要做出 ...
- Excel催化剂开源第47波-Excel与PowerBIDeskTop互通互联之第一篇
当国外都在追求软件开源,并且在GitHub等平台上产生了大量优质的开源代码时,但在国内却在刮着一股收割小白智商税的知识付费热潮,实在可悲. 互联网的精神乃是分享,让分享带来更多人的受益. 在Power ...
- 个人永久性免费-Excel催化剂功能第60波-数据有效性验证增强版,补足Excel天生不足
Excel在数据处理.数据分析上已经是公认的最好用的软件之一,其易用性和强大性也吸引无数的初中高级用户每天都在使用Excel.但这些优点的同时,也带出了一些问题,正因为其不同于一般的专业软件,需要专业 ...
- C语言数据类型及变量整理
数据类型 获取int的字节数大小方法 printf("int bytes:%d",sizeof(int)); 列表整理 类型 字节数 取值范围 char 1 [-128,127]= ...
- Linux设备驱动程序学习----2.内核模块与应用程序的对比
内核模块与应用程序的对比 更多内容请参考Linux设备驱动程序学习----目录 1. 内核模块与应用程序的对比 内核模块和应用程序之间的不同之处: 大多数中小规模的应用程序是从头到尾执行单个任务,而模 ...