0 MapReduce实现Reduce Side Join操作
一.准备两张表以及对应的数据
(1)m_ys_lab_jointest_a(以下简称表A)
建表语句:
create table if not exists m_ys_lab_jointest_a (
id bigint,
name string
)
row format delimited
fields terminated by ''
lines terminated by ''
stored as textfile;
id name |
create table if not exists m_ys_lab_jointest_b (
id bigint,
statyear bigint,
num bigint
)
row format delimited
fields terminated by ''
lines terminated by ''
stored as textfile;
id statyear num |
我们的目的是,以id为key做join操作,得到以下表:m_ys_lab_jointest_ab
| id name statyear num 1 北京 2011 2019 1 北京 2010 1962 2 天津 2011 1355 2 天津 2010 1299 4 山西 2011 3593 4 山西 2010 3574 |
二.计算模型
整个计算过程是:
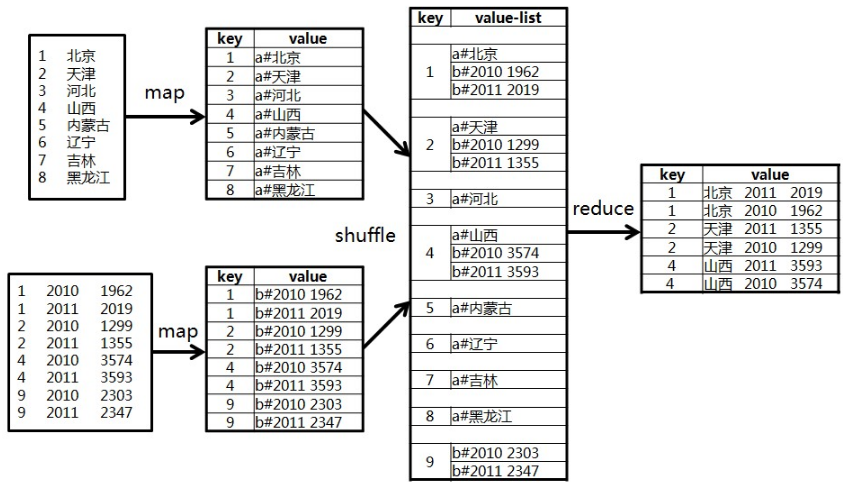
上代码:
import java.io.IOException;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List; import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.FileSplit;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapred.Mapper;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reducer;
import org.apache.hadoop.mapred.Reporter; /**
* MapReduce实现Join操作
*/
public class MapRedJoin {
public static final String DELIMITER = "\u0009"; // 字段分隔符 // map过程
public static class MapClass extends MapReduceBase implements Mapper<LongWritable, Text, Text, Text> {
public void configure(JobConf job) {
super.configure(job);
} public void map(LongWritable key, Text value, OutputCollector<Text, Text> output, Reporter reporter) throws IOException, ClassCastException {
// 获取输入文件的全路径和名称
String filePath = ((FileSplit)reporter.getInputSplit()).getPath().toString();
// 获取记录字符串
String line = value.toString();
// 抛弃空记录
if (line == null || line.equals("")){
return;
}
// 处理来自表A的记录
if (filePath.contains("m_ys_lab_jointest_a")) {
String[] values = line.split(DELIMITER); // 按分隔符分割出字段
if (values.length < 2){
return;
}
String id = values[0]; // id
String name = values[1]; // name
output.collect(new Text(id), new Text("a#"+name));
} else if (filePath.contains("m_ys_lab_jointest_b")) {// 处理来自表B的记录
String[] values = line.split(DELIMITER); // 按分隔符分割出字段
if (values.length < 3){
return;
}
String id = values[0]; // id
String statyear = values[1]; // statyear
String num = values[2]; //num
output.collect(new Text(id), new Text("b#"+statyear+DELIMITER+num));
}
}
} // reduce过程
public static class Reduce extends MapReduceBase implements Reducer<Text, Text, Text, Text> {
public void reduce(Text key, Iterator<Text> values, OutputCollector<Text, Text> output, Reporter reporter) throws IOException {
List<String> listA = new ArrayList<String>(); // 存放来自表A的值
List<String> listB = new ArrayList<String>(); // 存放来自表B的值
while (values.hasNext()) {
String value = values.next().toString();
if (value.startsWith("a#")) {
listA.add(value.substring(2));
} else if (value.startsWith("b#")) {
listB.add(value.substring(2));
}
}
int sizeA = listA.size();
int sizeB = listB.size();
// 遍历两个向量
int i, j;
for (i = 0; i < sizeA; i ++) {
for (j = 0; j < sizeB; j ++) {
output.collect(key, new Text(listA.get(i) + DELIMITER +listB.get(j)));
}
}
}
} protected void configJob(JobConf conf) {
conf.setMapOutputKeyClass(Text.class);
conf.setMapOutputValueClass(Text.class);
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(Text.class);
conf.setOutputFormat(ReportOutFormat.class);
}
}
三.技术细节
0 MapReduce实现Reduce Side Join操作的更多相关文章
- MapReduce的Reduce side Join
1. 简单介绍 reduce side join是全部join中用时最长的一种join,可是这样的方法可以适用内连接.left外连接.right外连接.full外连接和反连接等全部的join方式.r ...
- 使用MapReduce实现join操作
在关系型数据库中,要实现join操作是非常方便的,通过sql定义的join原语就可以实现.在hdfs存储的海量数据中,要实现join操作,可以通过HiveQL很方便地实现.不过HiveQL也是转化成 ...
- MapReduce 实现数据join操作
前段时间有一个业务需求,要在外网商品(TOPB2C)信息中加入 联营自营 识别的字段.但存在的一个问题是,商品信息 和 自营联营标示数据是 两份数据:商品信息较大,是存放在hbase中.他们之前唯一的 ...
- Hadoop基础-MapReduce的Join操作
Hadoop基础-MapReduce的Join操作 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.连接操作Map端Join(适合处理小表+大表的情况) no001 no002 ...
- Hadoop学习之路(二十一)MapReduce实现Reduce Join(多个文件联合查询)
MapReduce Join 对两份数据data1和data2进行关键词连接是一个很通用的问题,如果数据量比较小,可以在内存中完成连接. 如果数据量比较大,在内存进行连接操会发生OOM.mapredu ...
- 案例-使用MapReduce实现join操作
哈喽-各位小伙伴们中秋快乐,好久没更新新的文章啦,今天分享如何使用mapreduce进行join操作. 在离线计算中,我们常常不只是会对单一一个文件进行操作,进行需要进行两个或多个文件关联出更多数据, ...
- mapreduce join操作
上次和朋友讨论到mapreduce,join应该发生在map端,理由太想当然到sql里面的执行过程了 wheremap端 join在map之前(笛卡尔积),但实际上网上看了,mapreduce的笛卡尔 ...
- Mapreduce中的join操作
一.背景 MapReduce提供了表连接操作其中包括Map端join.Reduce端join还有半连接,现在我们要讨论的是Map端join,Map端join是指数据到达map处理函数之前进行合并的,效 ...
- [MapReduce_add_4] MapReduce 的 join 操作
0. 说明 Map 端 join && Reduce 端 join 1. Map 端 join Map 端 join:大表+小表 => 将小表加入到内存,迭代大表每一行,与之进行 ...
随机推荐
- 章节十四、8-javaScript弹框处理
一.javaScript弹框没有id.也没有xpath,在F12开发者选项中无法直接通过鼠标去选择弹窗来确定元素在代码中的位置. 弹窗有两种,一种实只有"确定"按钮的alert类型 ...
- Binary classification - 聊聊评价指标的那些事儿【回忆篇】
在解决分类问题的时候,可以选择的评价指标简直不要太多.但基本可以分成两2大类,我们今分别来说道说道 基于一个概率阈值判断在该阈值下预测的准确率 衡量模型整体表现(在各个阈值下)的评价指标 在说指标之前 ...
- Jmeter 如何把数据库的数据依次获取作为参数传入下一个请求?附栗子
某一天碰到一个问题,觉得很有必要整理一篇文章出来~ 因为项目的原因,假设我们要实现如下要求: 从数据库的用户表里获取用户信息,并作为参数全部传递给登录请求,分别完成登录操作. 一.jmeter连接数据 ...
- kuangbin专题专题四 Frogger POJ - 2253
题目链接:https://vjudge.net/problem/POJ-2253 思路: 从一号到二号石头的所有路线中,每条路线中都个子选出该路线中两点通路的最长距离,并在这些选出的最长距离选出最短路 ...
- signed char类型取值范围计算
在C语言程序中,给定一个类型,如何计算这个类型变量的取值范围呢?比如有一个字符型变量定义如下: signed char c: 这个字符变量c的取值范围是[-128,127],是计算出来的呢? 假设字符 ...
- asp core 配置用户密码验证
using System; using System.Collections.Generic; using System.Linq; using System.Threading.Tasks; usi ...
- linux 安装命令 nginx 部署
[TOC] # 安装anocanda wget https://repo.anaconda.com/archive/Anaconda3-2019.03-Linux-x86_64.sh安装:bash A ...
- 理解 Spring 定时任务的 fixedRate 和 fixedDelay 的区别
用过 Spring 的 @EnableScheduling 的都知道,有三种方式,即 @Scheduled 注解的 fixedRate(fixedRateString), fixedDelay(fix ...
- Android总结之打开手机相册获取图片
上一篇,总结了如何打开照相机获取图片,详情请看>>>> 这篇将总结如何打开手机存储(相册)来获取手机上的图片. 打开相册 在需要这个功能的类中,我们可以自定义一个方法openA ...
- NPOI 日期类型的判断
NPOI目前我用到有两套类,一套是为了读写XLS:一套是读写XLSX 在读取文件时大都会判断单元格类型,方式大同小异,只有日期类型不同. 默认日期类型的单元格在NPOI都认为是数值类型(CellTyp ...