Linux下,非Docker启动Elasticsearch 6.3.0,安装ik分词器插件,以及使用Kibana测试Elasticsearch,
Linux下,非Docker启动Elasticsearch 6.3.0
查看java版本,需要1.8版本
java -version yum -y install java 创建用户,因为elasticsearch不能root操作
useradd panfeng 设置密码
passwd panfeng 输入123456,上面说无效小于8字符,又让输入一次,再输入123456 切换用户,带有-参数是把当前环境也切换过去
su - panfeng 这时候用ftp把elasticsearch-6.3.0.tar.gz放到/home/panfeng 退出用户
exit 进入目录
cd /home/panfeng 查看详情
ll
总用量 89284
-rw-r--r--. 1 root root 91423553 7月 4 22:33 elasticsearch-6.3.0.tar.gz 把权限乐优
chown panfeng:panfeng elasticsearch-6.3.0.tar.gz 再查看详情
ll
总用量 89284
-rw-r--r--. 1 panfeng panfeng 91423553 7月 4 22:33 elasticsearch-6.3.0.tar.gz 修改文件权限
chmod 755 elasticsearch-6.3.0.tar.gz 再次查看详情,这时的elasticsearch-6.3.0.tar.gz就会变为绿色
ll
总用量 89284
-rwxr-xr-x. 1 panfeng panfeng 91423553 7月 4 22:33 elasticsearch-6.3.0.tar.gz 切换用户
su - panfeng 解压文件
tar -zxvf elasticsearch-6.3.0.tar.gz 修改解压后的文件夹名称为elasticsearch
mv elasticsearch-6.3.0 elasticsearch 进入目录
cd elasticsearch 查看详:bin执行的脚本,config配置,lib依赖,logs日志,modules模块,plugins插件
ll 进入目录
cd config 查看详情,elasticsearch.yml是elasticsearch的核心配置文件,jvm.options是Java虚拟机参数
ll 编辑Java虚拟机参数
vim jvm.options 把22和23行的1g改为512m 输入 I 插入进行编辑,编辑好之后按 Esc 输入:wq 保存并退出 编辑elasticsearch核心配置文件elasticsearch.yml
vim elasticsearch.yml 把33行 数据目录位置改为 path.data: /home/panfeng/elasticsearch/data
把37行 日志目录位置改为 path.logs: /home/panfeng/elasticsearch/logs
把55行 修改绑定的ip,默认只允许本机访问,修改为0.0.0.0后则可以远程访问,改为 network.host: 0.0.0.0
Elasticsearch的插件要求至少3.5以上版本,这里最好禁用这个插件,修改elasticsearch.yml文件,在最下面添加如下配置:在文件最下面另起一行 添加 bootstrap.system_call_filter: false
输入 I 插入进行编辑,编辑好之后按 Esc 输入:wq 保存并退出 退出用户
exit 修改文件权限
vim /etc/security/limits.conf 在# End of file上面添加下面四行数据 * soft nofile 65536 * hard nofile 131072 * soft nproc 4096 * hard nproc 4096 输入 I 插入进行编辑,编辑好之后按 Esc 输入:wq 保存并退出 修改线程数
vim /etc/security/limits.d/90-nproc.conf * soft nproc 4096
root soft nproc unlimited 如果有和两行代码直接把*对应的改为4096就行了,如果没有就直接添加
输入 I 插入进行编辑,编辑好之后按 Esc 输入:wq 保存并退出 修改虚拟内存
vim /etc/sysctl.conf 添加vm.max_map_count=655360 如果有就修改
输入 I 插入进行编辑,编辑好之后按 Esc 输入:wq 保存并退出 修改虚拟内存生效
sysctl -p 如果显示 vm.max_map_count = 655360 就修改成功了~ 进入目录
cd /home/panfeng/elasticsearch 创建data目录,logs目录已经存在就不用创建了
mkdir data 进入目录
cd /home/panfeng/elasticsearch/bin/ 运行elasticsearch
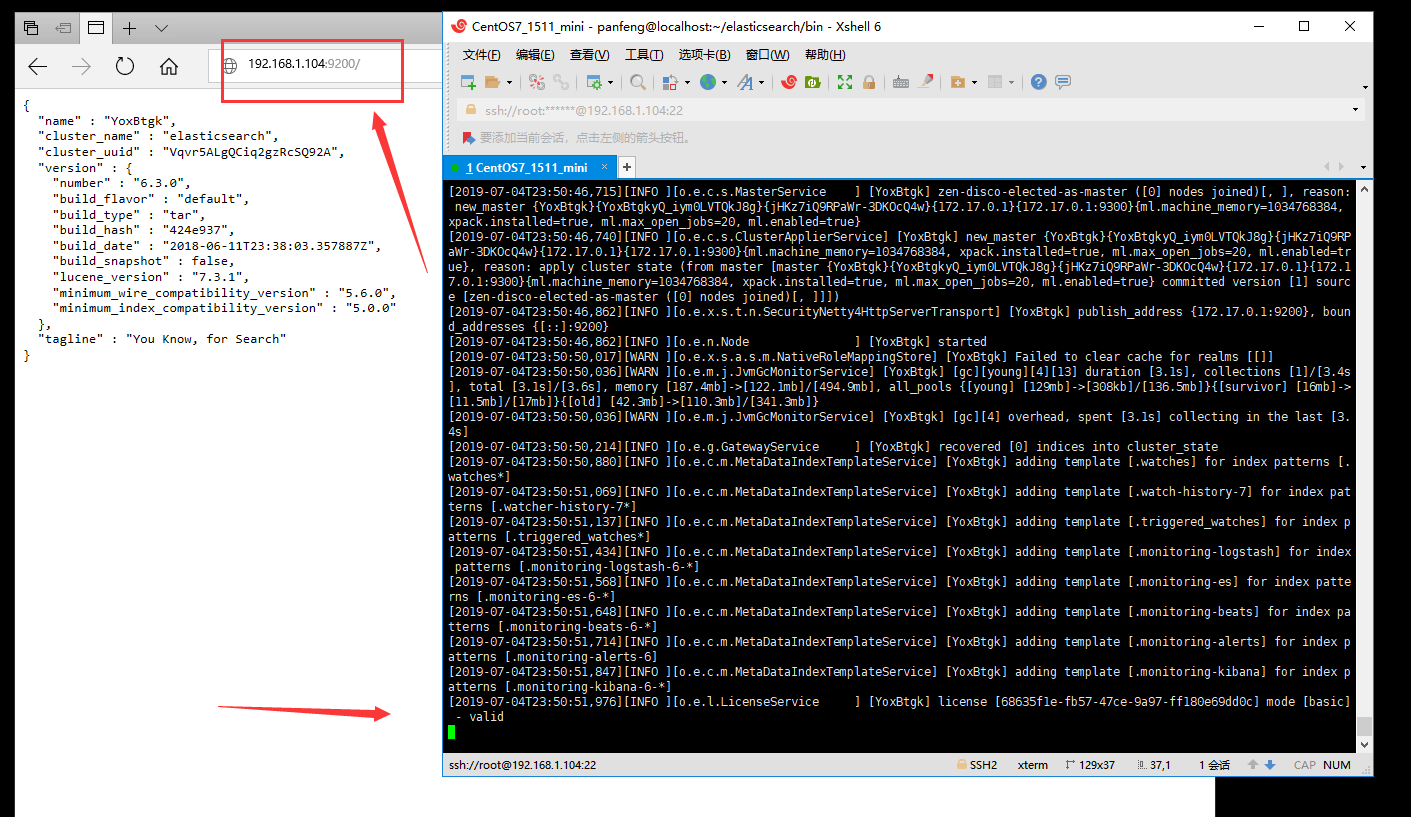
./elasticsearch 这时候在Windows浏览器输入 虚拟机ip:9200 来访问是否启动成功
Linux下,非Docker启动Elasticsearch 6.3.0,操作过程
安装ik分词器插件,以及使用Kibana测试Elasticsearch
用ftp上传elasticsearch-analysis-ik-6.3.0.zip到/home/panfeng/elasticsearch/plugins/ 进入目录
cd /home/panfeng/elasticsearch/plugins/ 使用unzip解压ik分词器
unzip elasticsearch-analysis-ik-6.3.0.zip -d ik-analyzer 删除elasticsearch-analysis-ik-6.3.0.zip,因为这个是插件目录,这个zip文件会解析错误
rm -f elasticsearch-analysis-ik-6.3.0.zip Windows下解压kibana
kibana-6.3.0-windows-x86_64.zip 解压后,进入安装目录下的config目录,修改kibana.yml文件
我的虚拟机地址192.168.1.104,所以第28行修改为 elasticsearch.url: "http://192.168.1.104:9200" 进入安装目录下的bin目录,双击运行kibana.bat,第一次运行慢,等待一会,如果几分钟还是不行的话,就再关闭窗口,再重新双击运行kibana.bat
安装ik分词器插件,以及使用Kibana测试Elasticsearch
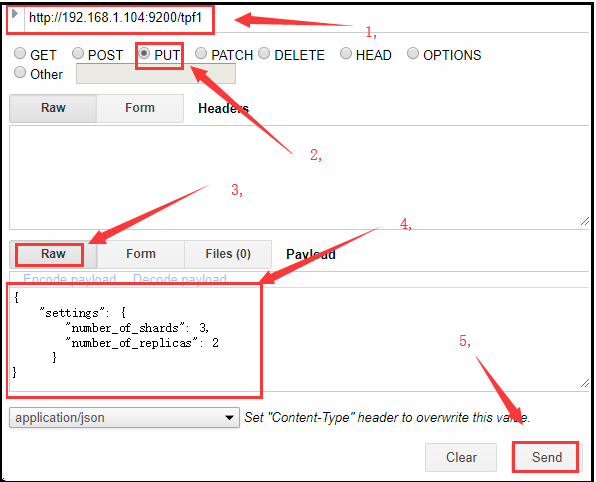
先用RestClient测试
请求方式:PUT
请求路径:/索引库名
请求参数:json格式 {
"settings": {
"number_of_shards": 3,
"number_of_replicas": 2
}
} settings:索引库的设置
number_of_shards:分片数量
number_of_replicas:副本数量- 发送
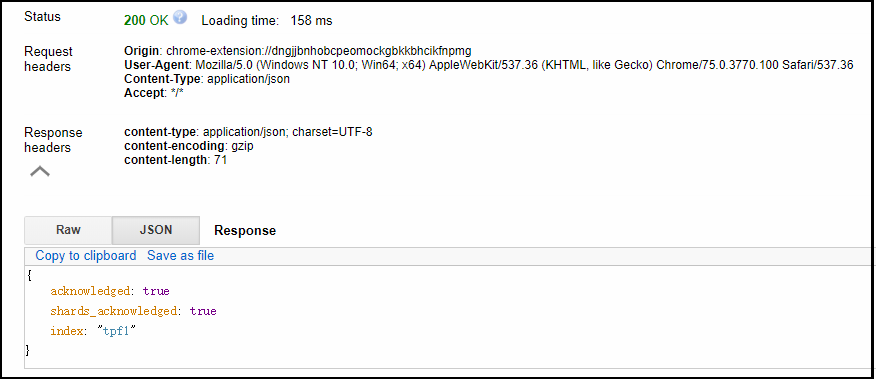
- 响应
Kibana操作Elasticsearch
操作索引
创建索引

查看索引设置
查看指定索引
GET /索引库名 查看所有所有
GET *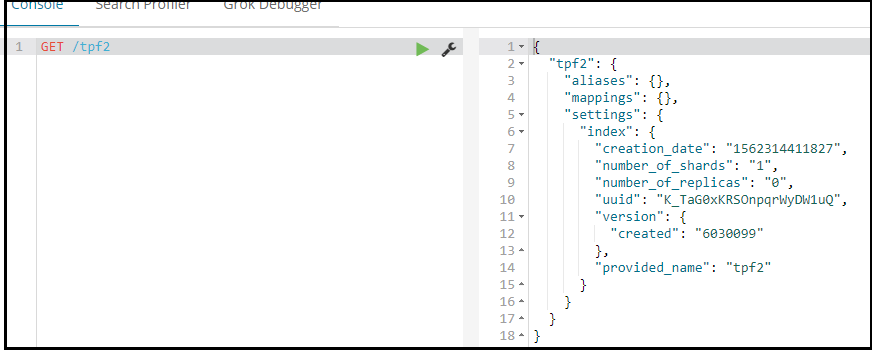
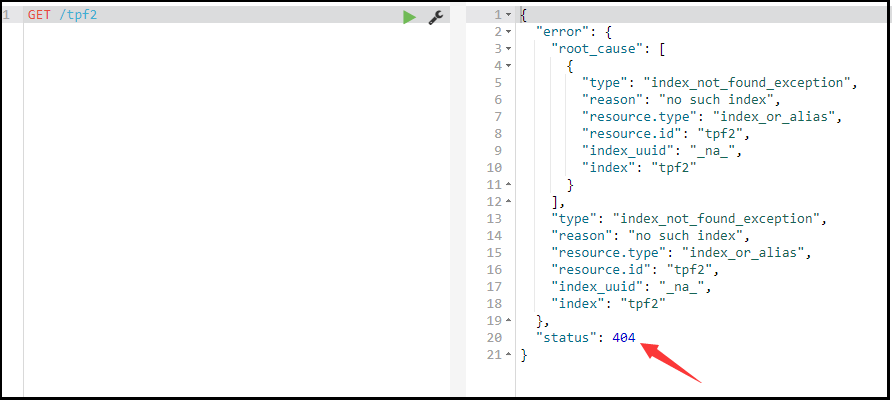
删除索引
DELETE /索引库名

映射配置
创建映射字段
PUT /索引库名/_mapping/类型名称
{
"properties": {
"字段名": {
"type": "类型",
"index": true,
"store": true,
"analyzer": "分词器"
}
}
} 类型名称:就是前面将的type的概念,类似于数据库中的不同表
字段名:任意填写,可以指定许多属性,例如:
type:类型,可以是text,long,short,date,integer,object等,String的text可以分词,String的keyword不可以分词
index:是否索引,默认为true
store:是否存储,默认为false,默认保存到_source
analyzer:分词器,这里的`ik_max_word`即使用ik分词器,固定写法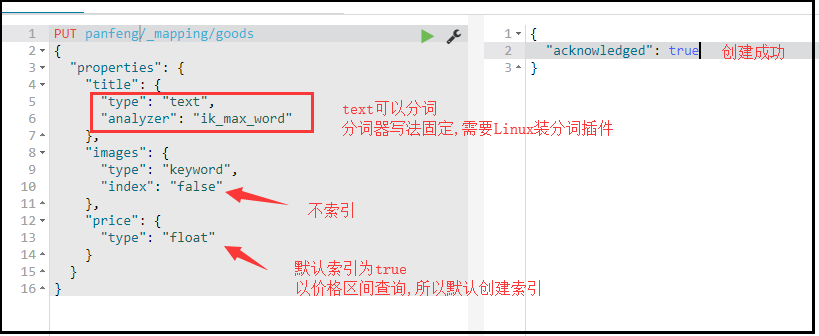
查看映射信息
GET /索引库名/_mapping
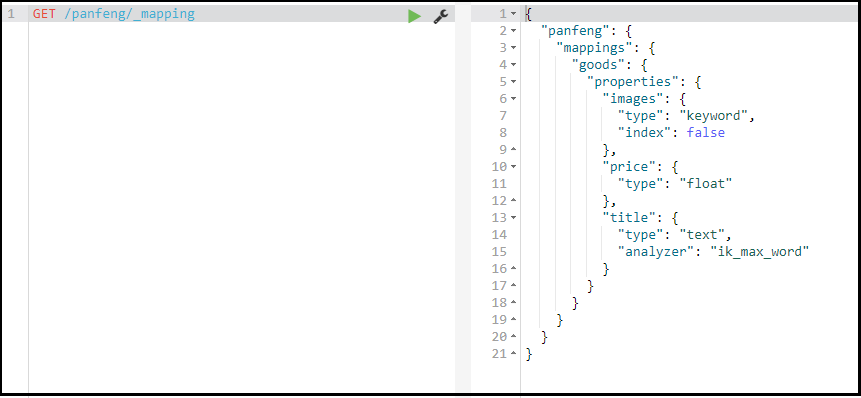
字段属性详解
- type
- String类型,又分两种:
- text:可分词,不可参与聚合
- keyword:不可分词,数据会作为完整字段进行匹配,可以参与聚合 - Numerical:数值类型,分两类
- 基本数据类型(一般使用long,interger):long、interger、short、byte、double、float、half_float
- 浮点数的高精度类型:scaled_float
- 需要指定一个精度因子,比如10或100。elasticsearch会把真实值乘以这个因子后存储,取出时再还原。 - Date:日期类型
elasticsearch可以对日期格式化为字符串存储,但是建议我们存储为毫秒值,存储为long,节省空间。 - index
index影响字段的索引情况。
- true:字段会被索引,则可以用来进行搜索。默认值就是true
- false:字段不会被索引,不能用来搜索 index的默认值就是true,也就是说你不进行任何配置,所有字段都会被索引。
但是有些字段是我们不希望被索引的,比如商品的图片信息,就需要手动设置index为false。 - store
是否将数据进行额外存储。 在学习lucene和solr时,我们知道如果一个字段的store设置为false,那么在文档列表中就不会有这个字段的值,用户的搜索结果中不会显示出来。 但是在Elasticsearch中,即便store设置为false,也可以搜索到结果。
原因是Elasticsearch在创建文档索引时,会将文档中的原始数据备份,保存到一个叫做`_source`的属性中。而且我们可以通过过滤`_source`来选择哪些要显示,哪些不显示。
而如果设置store为true,就会在`_source`以外额外存储一份数据,多余,因此一般我们都会将store设置为false,事实上,**store的默认值就是false。**
- type
新增数据
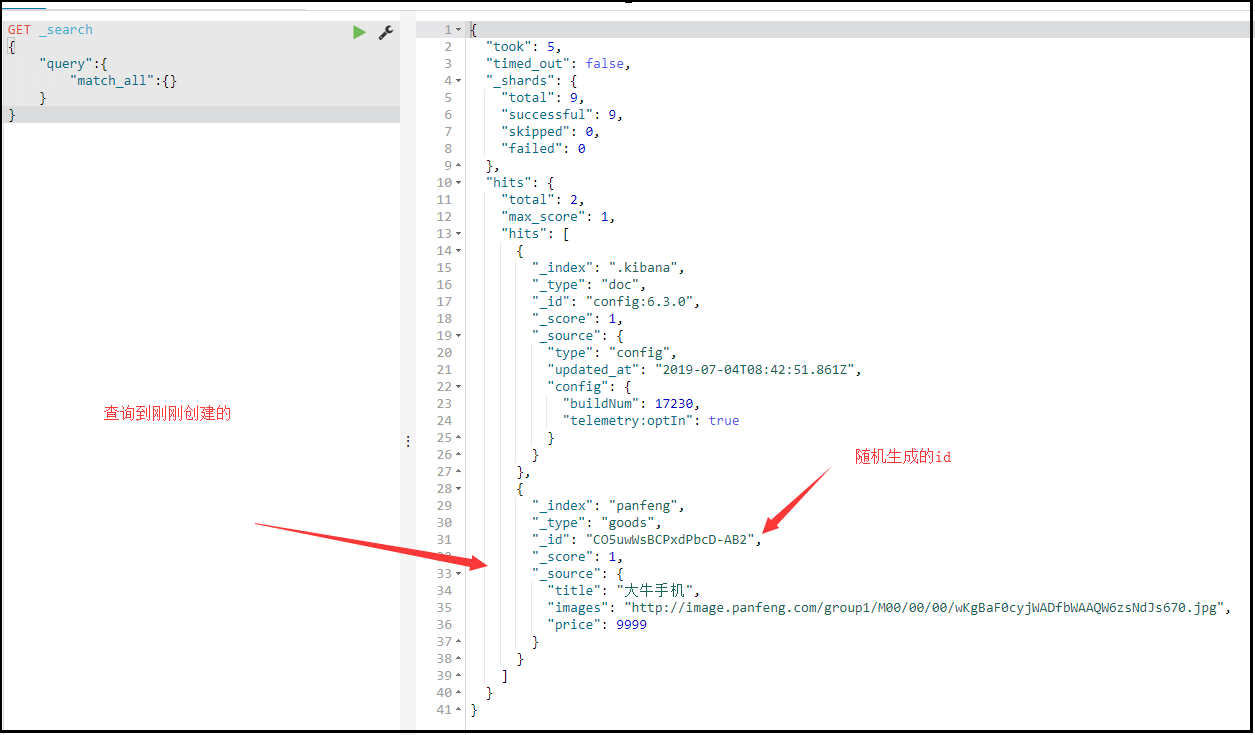
随机生成id
POST /索引库名/类型名
{
"key":"value"
}_source:源文档信息,所有的数据都在里面。
_id:这条文档的唯一标示,与文档自己的id字段没有关联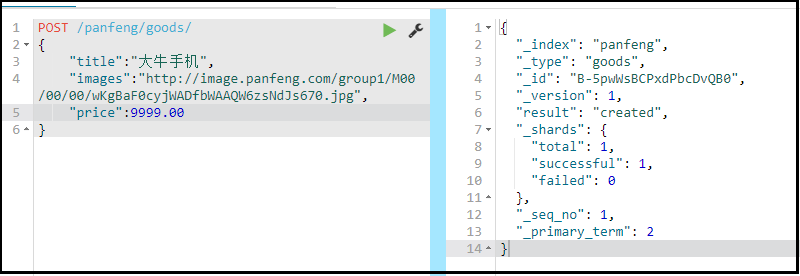
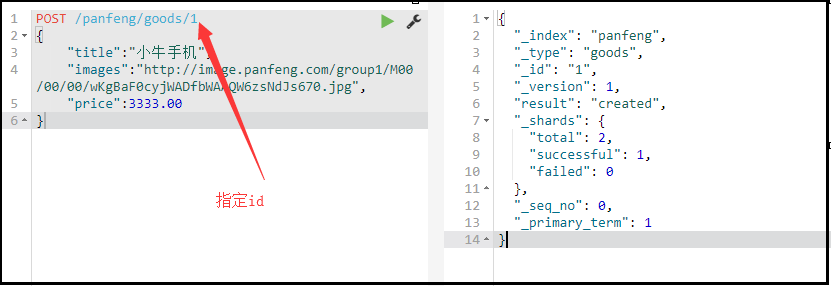
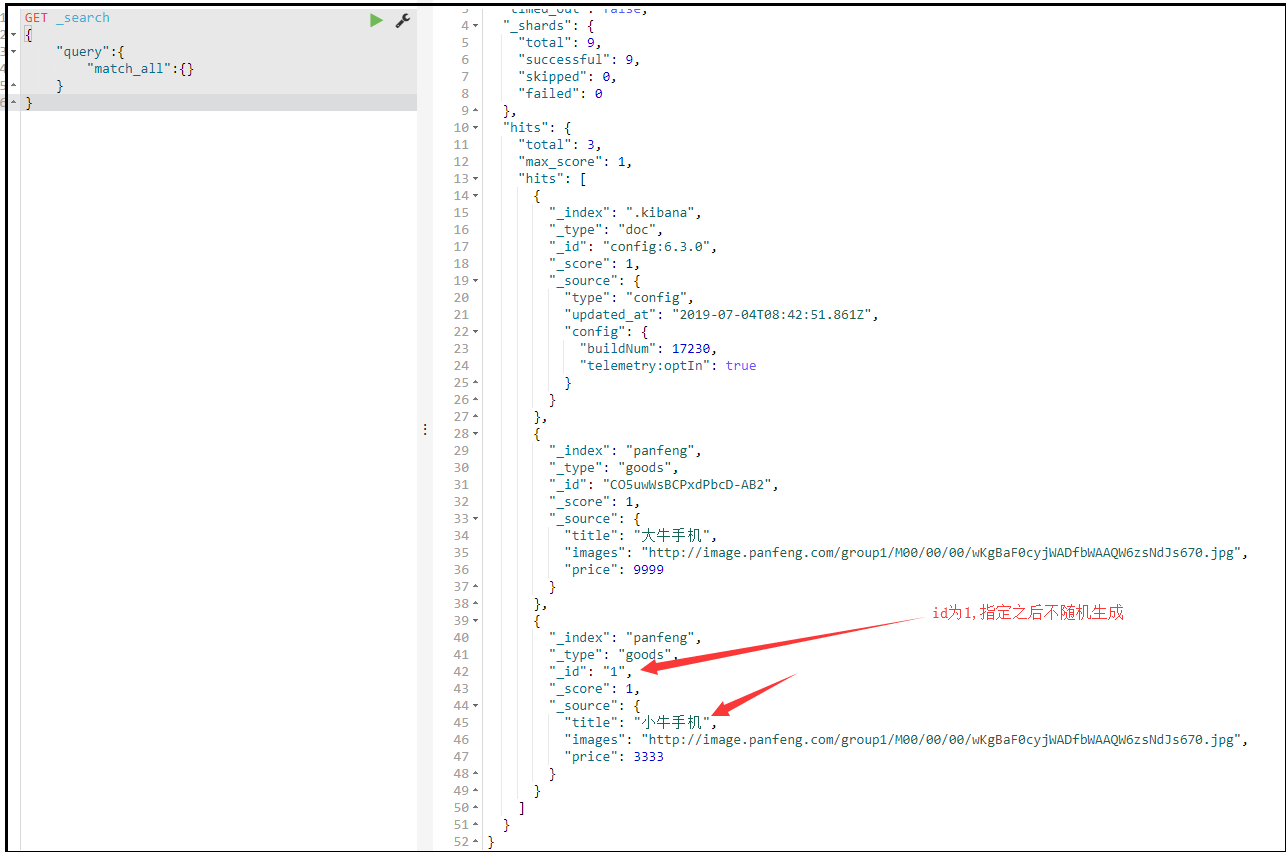
自定义id
POST /索引库名/类型/id值
{
...
}
添加字段,修改数据
修改必须指定id, - id对应文档存在,则修改
- id对应文档不存在,则新增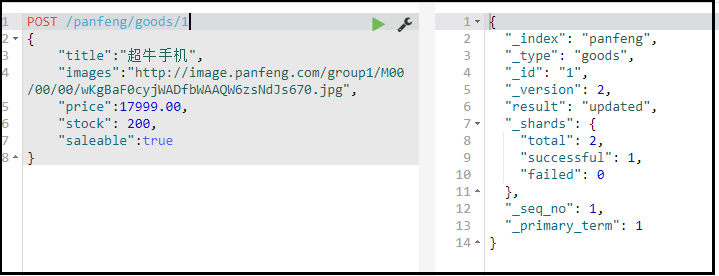
删除数据
DELETE /索引库名/类型名/id值

*查询
基本查询
基本语法
GET /索引库名/_search
{
"query":{
"查询类型":{
"查询条件":"查询条件值"
}
}
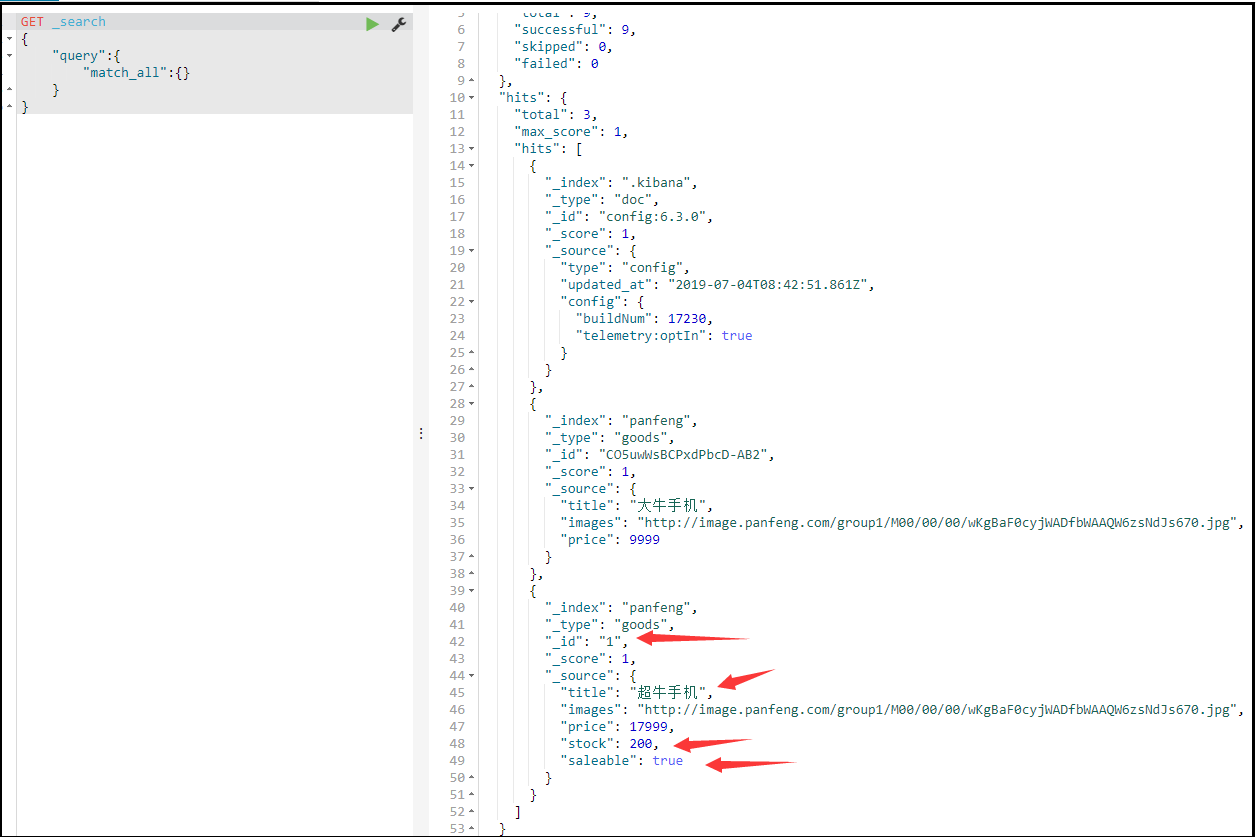
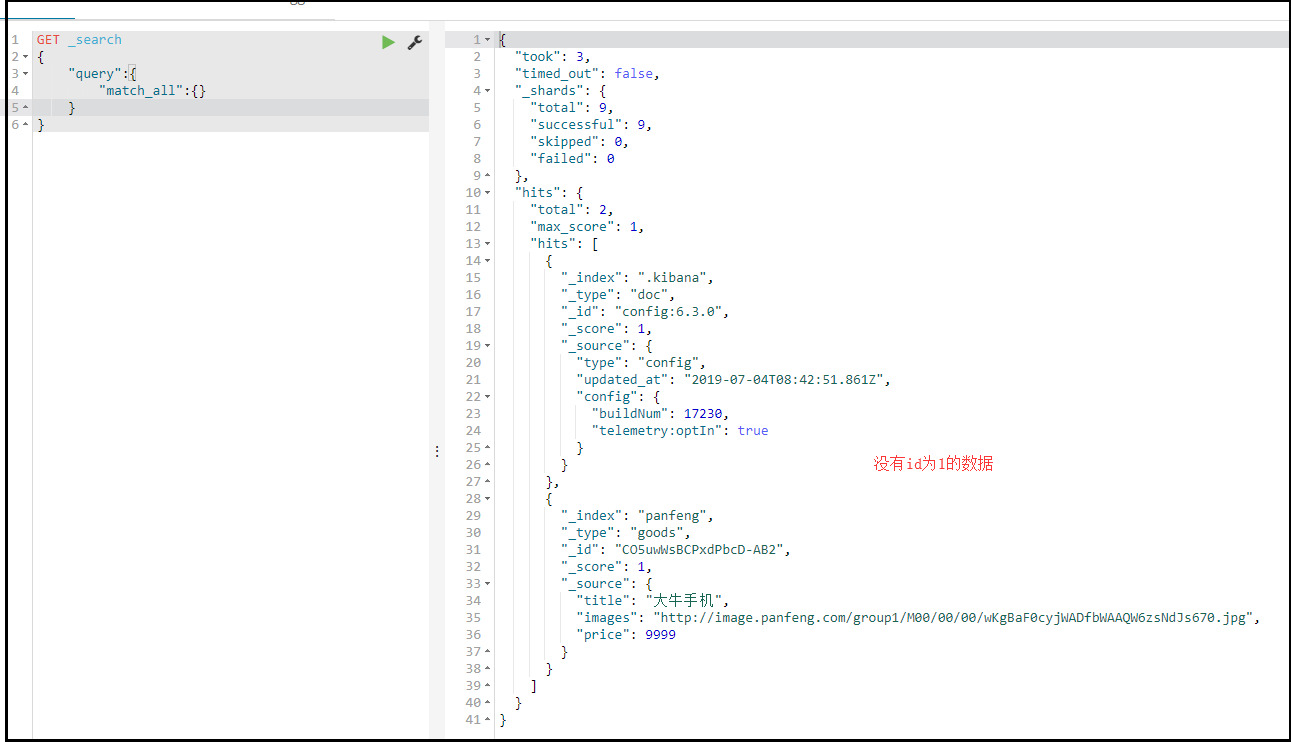
} 查询类型为 match_all , match , multi_match , term , terms查询所有 match_all
GET /heima/_search
{
"query":{
"match_all": {}
}
}query:代表查询对象
match_all:代表查询所有
匹配查询 match
查询"title"内容有"大牛"的数据
GET /panfeng/_search
{
"query":{
"match": {
"title": "大牛"
}
}
} or关系,查询"title"内容有"大牛"或"手机"的数据,因为分词器会分词
GET /panfeng/_search
{
"query":{
"match": {
"title": "大牛手机"
}
}
} and关系,查询"title"内容有"大牛"并且也含有"手机"的数据,因为分词器会分词
GET /panfeng/_search
{
"query":{
"match": {
"title": {
"query": "大牛手机",
"operator": "and"
}
}
}
} "大牛手机"可以分词"大牛","手机"两个词,匹配任何一个都可以,如果把1改为3不匹配任何
GET /panfeng/_search
{
"query":{
"match":{
"title":{
"query":"大牛手机",
"minimum_should_match": 1
}
}
}
} "大牛智能手机"可以分词"大牛","智能","手机"三个词
最小匹配3x0.66=1.98,因为1.98<2,所以能匹配三个当中任何一个词都可以
GET /panfeng/_search
{
"query":{
"match":{
"title":{
"query":"大牛智能手机",
"minimum_should_match": "66%"
}
}
}
} "大牛智能手机"可以分词"大牛","智能","手机"三个词
最小匹配3x0.67=2.01,因为2.01>2,所以能匹配三个当中任何两个词都可以
GET /panfeng/_search
{
"query":{
"match":{
"title":{
"query":"大牛智能手机",
"minimum_should_match": "67%"
}
}
}
}匹配查询 match
多字段查询 multi_match
可以匹配字段"title"或"name" 内容为"大牛"的数据
GET /panfeng/_search
{
"query":{
"multi_match": {
"query": "大牛",
"fields": [ "title", "name" ]
}
}
}多字段查询 multi_match
词条查询 term
在"title"中,可以匹配到词为"大牛"的数据
GET /panfeng/_search
{
"query":{
"term":{
"title": {
"value": "大牛"
}
}
}
} 因为"大牛手机"不是一个词,所以也无法匹配到title中含有"大牛手机"的数据
因为"快快乐乐"是一个词,所以可以匹配到title中含有"快快乐乐"的数据
GET /panfeng/_search
{
"query":{
"term":{
"title": {
"value": "大牛手机"
}
}
}
}词条查询 term
多词条精确查询 terms
只能匹配到title中含有"大牛"的数据,因为"大牛"是一个词,而"二蛋"不是一个词
如果换成"title": ["大牛","牛牛"],则就可以匹配到title中含有"大牛"或"牛牛"的数据
GET /panfeng/_search
{
"query":{
"terms":{
"title": ["大牛","二蛋"]
}
}
}多词条精确查询 terms
_source过滤
直接指定字段
在查询结果的_source中只显示字段"title","price"
GET /panfeng/_search
{
"_source": ["title","price"],
"query": {
"term": {
"title": {
"value": "大牛"
}
}
}
}直接指定字段
指定includes和excludes
includes:来指定想要显示的字段
GET /panfeng/_search
{
"_source": {
"includes":["title","price"]
},
"query": {
"term": {
"title": "大牛"
}
}
} excludes:来指定不想要显示的字段
GET /panfeng/_search
{
"_source": {
"excludes":["title","price"]
},
"query": {
"term": {
"title": "大牛"
}
}
}指定includes和excludes
结果过滤
布尔组合 bool
查询title为手机,price为2222或者3333的数据
GET panfeng/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"title": "手机"
}
},
{
"terms": {
"price": ["2222","3333"]
}
}
]
}
}
} title不为大牛并且价格不为2222或3333的数据
GET panfeng/_search
{
"query": {
"bool": {
"must_not": [
{
"match": {
"title": "大牛"
}
},
{
"terms": {
"price": ["2222","3333"]
}
}
]
}
}
} title为大牛或者price为2222或3333的数据
GET panfeng/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"title": "大牛"
}
},
{
"terms": {
"price": ["2222","3333"]
}
}
]
}
}
}"bool"把各种其它查询通过"must"与,"must_not"非,"should"或 的方式进行组合
范围查询
在range中 gt:大于 gte:大于等于 lt:小于 lte:小于等于
大于 greater than
小于 less than
等于 equal 查询价格大于等于3.01小于5.01的数据,不可以匹配3,可以匹配3.01,可以匹配5,不可以匹配5.01
GET /panfeng/_search
{
"query":{
"range": {
"price": {
"gte": 3.01,
"lt": 5.01
}
}
}
}在range中 gt:大于 gte:大于等于 lt:小于 lte:小于等于
模糊查询
高级查询
排序
1
1
1
1
1
1
1
1
1
1
1
1
1
1
Linux下,非Docker启动Elasticsearch 6.3.0,安装ik分词器插件,以及使用Kibana测试Elasticsearch,的更多相关文章
- Elasticsearch入门之从零开始安装ik分词器
起因 需要在ES中使用聚合进行统计分析,但是聚合字段值为中文,ES的默认分词器对于中文支持非常不友好:会把完整的中文词语拆分为一系列独立的汉字进行聚合,显然这并不是我的初衷.我们来看个实例: POST ...
- 通过docker安装elasticsearch和安装ik分词器插件及安装kibana
前提: 已经安装好docker运行环境: 步骤: 1.安装elasticsearch 6.2.2版本,目前最新版是7.2.0,这里之所以选择6.2.2是因为最新的SpringBoot2.1.6默认支持 ...
- Elasticsearch 7.1.1 安装 pinyin 分词器插件
1.安装maven 安装插件前,需要用 maven 进行编译生成插件包,第一步先安装 maven yum install -y maven mvn -version Apache Maven (Red ...
- Linux使用Docker启动Elasticsearch并配合Kibana使用,安装ik分词器
注意事项 这里我的Linux虚拟机的IP地址是192.168.1.3 Docker运行Elasticsearch容器之后不会立即有反应,要等一会,等待容器内部启动Elasticsearch,才可以访问 ...
- windows下elasticsearch安装ik分词器后无法启动
windows下elasticsearch安装ik分词器后启动报如下图错误: 然后百度说是elasticsearch路径有空格,一看果然我的路径有空格,然后重新换个路径就好了.
- 【ELK】【docker】【elasticsearch】1. 使用Docker和Elasticsearch+ kibana 5.6.9 搭建全文本搜索引擎应用 集群,安装ik分词器
系列文章:[建议从第二章开始] [ELK][docker][elasticsearch]1. 使用Docker和Elasticsearch+ kibana 5.6.9 搭建全文本搜索引擎应用 集群,安 ...
- docker上安装elasticsearch和ik分词器插件和header,实现分词功能
docker run -di --name=tensquare_es -p 9200: -p 9300:9300 elasticsearch:5.6.8 创建elasticsearch容器(如果版本不 ...
- Elasticsearch下安装ik分词器
安装ik分词器(必须安装maven) 上传相应jar包 解压到相应目录 unzip elasticsearch-analysis-ik-master.zip(zip包) cp -r elasticse ...
- elasticsearch安装ik分词器(极速版)
简介:下面讲有我已经打包并且编辑过的zip包,你可以在下面下载即可. 1.下载zip包.elasticsearch-analysis-ik-1.8.0.jar下面有附件链接[ik-安装包.zip],下 ...
随机推荐
- C#获取windows 10的下载文件夹路径
Windows没有为“下载”文件夹定义CSIDL,并且通过Environment.SpecialFolder枚举无法使用它. 但是,新的Vista 知名文件夹 API确实使用ID定义它FOLDERID ...
- Qt5.4.1在windows7配置Android开发环境(阳光柠檬_)
网上的说法有些时间比较久远,软件更新又快,配置路上总有一些坎坷. 自己亲自尝试了一遍,记录下来. 所需的软件: 1. qt-opensource-windows-x86-android-5.4.1.e ...
- 新浪微博Python3客户端接口OAuth2
Keyword: Python3 Oauth2 新浪微博 本接口基于廖雪峰的weibo python SDK修改完成,其sdk为新浪官方所推荐,原作者是用python2写的 经过一些修改,这里提供基于 ...
- ubuntu12.04单卡server(mentohust认证)再加上交换机做路由软件共享上网
最近成立了实验室的网络环境中,通过交换机连接的所有主机实验室.想要一个通过该server(单卡)做网关,使用mentohust认证外网,然后内网中的其它主机通过此网关来连接外网. 1.首先在serve ...
- c# 守护进程,WPF程序自守护
原文:c# 守护进程,WPF程序自守护 版权声明:本文为博主原创文章,转载请注明出处. https://blog.csdn.net/lwwl12/article/details/79035246 如何 ...
- Entity framework 更改模型,新增表
在Package Manager Console 中运行命令Enable-Migrations 再次运行可以更新 抄袭 在实体类中增加一个属性以后,执行 Update-Database 命令 ,可以更 ...
- 潜移默化学会WPF(绚丽篇)--热烈欢迎RadioButton,改造成功,改造成ImageButton,新版导航
原文:潜移默化学会WPF(绚丽篇)--热烈欢迎RadioButton,改造成功,改造成ImageButton,新版导航 本样式 含有 触发器 和 动画 模板 ,多条件触发器,还有布局 本人博 ...
- JS 密码弱中强显示
<!DOCTYPE html><html><head> <meta http-equiv="Content-Type" conten ...
- 数据绑定(五)使用集合对象作为列表控件的ItemsSource
原文:数据绑定(五)使用集合对象作为列表控件的ItemsSource ItemsSource属性可以接收一个IEnumerable接口派生类的实例作为自己的值,ItemsSource里存放的是一条一条 ...
- sql server 定时备份数据库
CREATE PROCEDURE [dbo].[SP_DBBackup_EveryNight_Local] @cycle INT, ---保存周期 @IsLocal INT, ---是否为本地 0表示 ...