Hadoop —— 单机环境搭建
一、前置条件
Hadoop的运行依赖JDK,需要预先安装,安装步骤见:
二、配置免密登录
Hadoop组件之间需要基于SSH进行通讯。
2.1 配置映射
配置ip地址和主机名映射:
vim /etc/hosts
# 文件末尾增加
192.168.43.202 hadoop001
2.2 生成公私钥
执行下面命令行生成公匙和私匙:
ssh-keygen -t rsa
3.3 授权
进入~/.ssh目录下,查看生成的公匙和私匙,并将公匙写入到授权文件:
[root@@hadoop001 sbin]# cd ~/.ssh
[root@@hadoop001 .ssh]# ll
-rw-------. 1 root root 1675 3月 15 09:48 id_rsa
-rw-r--r--. 1 root root 388 3月 15 09:48 id_rsa.pub
# 写入公匙到授权文件
[root@hadoop001 .ssh]# cat id_rsa.pub >> authorized_keys
[root@hadoop001 .ssh]# chmod 600 authorized_keys
三、Hadoop(HDFS)环境搭建
3.1 下载并解压
下载Hadoop安装包,这里我下载的是CDH版本的,下载地址为:http://archive.cloudera.com/cdh5/cdh/5/
# 解压
tar -zvxf hadoop-2.6.0-cdh5.15.2.tar.gz
3.2 配置环境变量
# vi /etc/profile
配置环境变量:
export HADOOP_HOME=/usr/app/hadoop-2.6.0-cdh5.15.2
export PATH=${HADOOP_HOME}/bin:$PATH
执行source命令,使得配置的环境变量立即生效:
# source /etc/profile
3.3 修改Hadoop配置
进入${HADOOP_HOME}/etc/hadoop/目录下,修改以下配置:
1. hadoop-env.sh
# JDK安装路径
export JAVA_HOME=/usr/java/jdk1.8.0_201/
2. core-site.xml
<configuration>
<property>
<!--指定namenode的hdfs协议文件系统的通信地址-->
<name>fs.defaultFS</name>
<value>hdfs://hadoop001:8020</value>
</property>
<property>
<!--指定hadoop存储临时文件的目录-->
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/tmp</value>
</property>
</configuration>
3. hdfs-site.xml
指定副本系数和临时文件存储位置:
<configuration>
<property>
<!--由于我们这里搭建是单机版本,所以指定dfs的副本系数为1-->
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
4. slaves
配置所有从属节点的主机名或IP地址,由于是单机版本,所以指定本机即可:
hadoop001
3.4 关闭防火墙
不关闭防火墙可能导致无法访问Hadoop的Web UI界面:
# 查看防火墙状态
sudo firewall-cmd --state
# 关闭防火墙:
sudo systemctl stop firewalld.service
3.5 初始化
第一次启动Hadoop时需要进行初始化,进入${HADOOP_HOME}/bin/目录下,执行以下命令:
[root@hadoop001 bin]# ./hdfs namenode -format
3.6 启动HDFS
进入${HADOOP_HOME}/sbin/目录下,启动HDFS:
[root@hadoop001 sbin]# ./start-dfs.sh
3.7 验证是否启动成功
方式一:执行jps查看NameNode和DataNode服务是否已经启动:
[root@hadoop001 hadoop-2.6.0-cdh5.15.2]# jps
9137 DataNode
9026 NameNode
9390 SecondaryNameNode
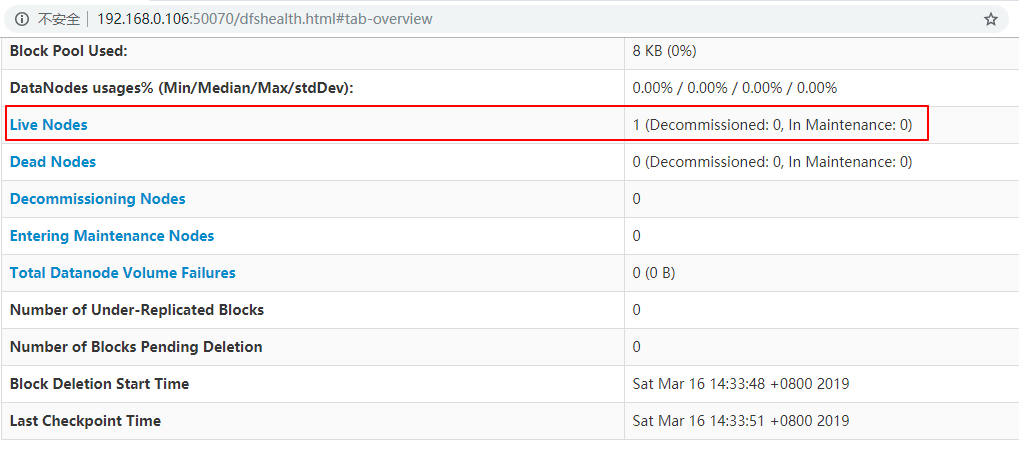
方式二:查看Web UI界面,端口为50070:
四、Hadoop(YARN)环境搭建
4.1 修改配置
进入${HADOOP_HOME}/etc/hadoop/目录下,修改以下配置:
1. mapred-site.xml
# 如果没有mapred-site.xml,则拷贝一份样例文件后再修改
cp mapred-site.xml.template mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
2. yarn-site.xml
<configuration>
<property>
<!--配置NodeManager上运行的附属服务。需要配置成mapreduce_shuffle后才可以在Yarn上运行MapReduce程序。-->
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
4.2 启动服务
进入${HADOOP_HOME}/sbin/目录下,启动YARN:
./start-yarn.sh
4.3 验证是否启动成功
方式一:执行jps命令查看NodeManager和ResourceManager服务是否已经启动:
[root@hadoop001 hadoop-2.6.0-cdh5.15.2]# jps
9137 DataNode
9026 NameNode
12294 NodeManager
12185 ResourceManager
9390 SecondaryNameNode
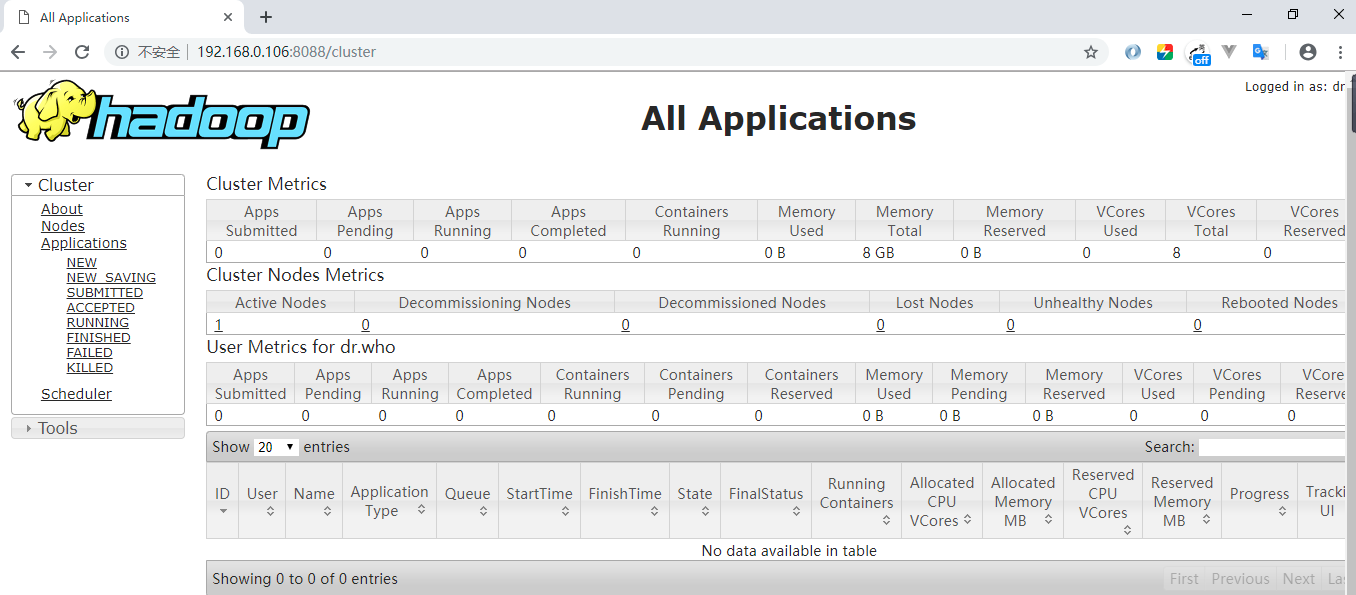
方式二:查看Web UI界面,端口号为8088:
更多大数据系列文章可以参见个人 GitHub 开源项目: 程序员大数据入门指南
一、前置条件
Hadoop的运行依赖JDK,需要预先安装,安装步骤见:
二、配置免密登录
Hadoop组件之间需要基于SSH进行通讯。
2.1 配置映射
配置ip地址和主机名映射:
vim /etc/hosts
# 文件末尾增加
192.168.43.202 hadoop001
2.2 生成公私钥
执行下面命令行生成公匙和私匙:
ssh-keygen -t rsa
3.3 授权
进入~/.ssh目录下,查看生成的公匙和私匙,并将公匙写入到授权文件:
[root@@hadoop001 sbin]# cd ~/.ssh
[root@@hadoop001 .ssh]# ll
-rw-------. 1 root root 1675 3月 15 09:48 id_rsa
-rw-r--r--. 1 root root 388 3月 15 09:48 id_rsa.pub
# 写入公匙到授权文件
[root@hadoop001 .ssh]# cat id_rsa.pub >> authorized_keys
[root@hadoop001 .ssh]# chmod 600 authorized_keys
三、Hadoop(HDFS)环境搭建
3.1 下载并解压
下载Hadoop安装包,这里我下载的是CDH版本的,下载地址为:http://archive.cloudera.com/cdh5/cdh/5/
# 解压
tar -zvxf hadoop-2.6.0-cdh5.15.2.tar.gz
3.2 配置环境变量
# vi /etc/profile
配置环境变量:
export HADOOP_HOME=/usr/app/hadoop-2.6.0-cdh5.15.2
export PATH=${HADOOP_HOME}/bin:$PATH
执行source命令,使得配置的环境变量立即生效:
# source /etc/profile
3.3 修改Hadoop配置
进入${HADOOP_HOME}/etc/hadoop/目录下,修改以下配置:
1. hadoop-env.sh
# JDK安装路径
export JAVA_HOME=/usr/java/jdk1.8.0_201/
2. core-site.xml
<configuration>
<property>
<!--指定namenode的hdfs协议文件系统的通信地址-->
<name>fs.defaultFS</name>
<value>hdfs://hadoop001:8020</value>
</property>
<property>
<!--指定hadoop存储临时文件的目录-->
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/tmp</value>
</property>
</configuration>
3. hdfs-site.xml
指定副本系数和临时文件存储位置:
<configuration>
<property>
<!--由于我们这里搭建是单机版本,所以指定dfs的副本系数为1-->
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
4. slaves
配置所有从属节点的主机名或IP地址,由于是单机版本,所以指定本机即可:
hadoop001
3.4 关闭防火墙
不关闭防火墙可能导致无法访问Hadoop的Web UI界面:
# 查看防火墙状态
sudo firewall-cmd --state
# 关闭防火墙:
sudo systemctl stop firewalld.service
3.5 初始化
第一次启动Hadoop时需要进行初始化,进入${HADOOP_HOME}/bin/目录下,执行以下命令:
[root@hadoop001 bin]# ./hdfs namenode -format
3.6 启动HDFS
进入${HADOOP_HOME}/sbin/目录下,启动HDFS:
[root@hadoop001 sbin]# ./start-dfs.sh
3.7 验证是否启动成功
方式一:执行jps查看NameNode和DataNode服务是否已经启动:
[root@hadoop001 hadoop-2.6.0-cdh5.15.2]# jps
9137 DataNode
9026 NameNode
9390 SecondaryNameNode
方式二:查看Web UI界面,端口为50070:
四、Hadoop(YARN)环境搭建
4.1 修改配置
进入${HADOOP_HOME}/etc/hadoop/目录下,修改以下配置:
1. mapred-site.xml
# 如果没有mapred-site.xml,则拷贝一份样例文件后再修改
cp mapred-site.xml.template mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
2. yarn-site.xml
<configuration>
<property>
<!--配置NodeManager上运行的附属服务。需要配置成mapreduce_shuffle后才可以在Yarn上运行MapReduce程序。-->
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
4.2 启动服务
进入${HADOOP_HOME}/sbin/目录下,启动YARN:
./start-yarn.sh
4.3 验证是否启动成功
方式一:执行jps命令查看NodeManager和ResourceManager服务是否已经启动:
[root@hadoop001 hadoop-2.6.0-cdh5.15.2]# jps
9137 DataNode
9026 NameNode
12294 NodeManager
12185 ResourceManager
9390 SecondaryNameNode
方式二:查看Web UI界面,端口号为8088:
更多大数据系列文章可以参见个人 GitHub 开源项目: 程序员大数据入门指南
Hadoop —— 单机环境搭建的更多相关文章
- hadoop单机环境搭建
[在此处输入文章标题] Hadoop单机搭建 1. 工具准备 1) Hadoop Linux安装包 2) VMware虚拟机 3) Java Linux安装包 4) Window 电脑一台 2. 开始 ...
- 攻城狮在路上(陆)-- hadoop单机环境搭建(一)
一.环境说明: 操作系统:Centos6.5 Linux node1 2.6.32-431.el6.x86_64 #1 SMP Fri Nov 22 03:15:09 UTC 2013 x86 ...
- Hadoop单机环境搭建整体流程
1. Ubuntu环境安装和基本配置 本例程中在MAC上安装使用的虚拟机Ubuntu系统(64位,desktop): 基本配置 考虑到以后涉及到hadoop的应用便于权限的管理,特别地创建一个ha ...
- [转载] Hadoop和Hive单机环境搭建
转载自http://blog.csdn.net/yfkiss/article/details/7715476和http://blog.csdn.net/yfkiss/article/details/7 ...
- 【HADOOP】| 环境搭建:从零开始搭建hadoop大数据平台(单机/伪分布式)-下
因篇幅过长,故分为两节,上节主要说明hadoop运行环境和必须的基础软件,包括VMware虚拟机软件的说明安装.Xmanager5管理软件以及CentOS操作系统的安装和基本网络配置.具体请参看: [ ...
- Hadoop单机Hadoop测试环境搭建
Hadoop单机Hadoop测试环境搭建: 1. 安装jdk,并配置环境变量,配置ssh免密码登录 2. 下载安装包hadoop-2.7.3.tar.gz 3. 配置/etc/hosts 127.0. ...
- Hadoop之环境搭建
初学Hadoop之环境搭建 阅读目录 1.安装CentOS7 2.安装JDK1.7.0 3.安装Hadoop2.6.0 4.SSH无密码登陆 本文仅作为学习笔记,供大家初学Hadoop时学习参考. ...
- Hadoop生产环境搭建(含HA、Federation)
Hadoop生产环境搭建 1. 将安装包hadoop-2.x.x.tar.gz存放到某一目录下,并解压. 2. 修改解压后的目录中的文件夹etc/hadoop下的配置文件(若文件不存在,自己创建.) ...
- Hadoop 系列(四)—— Hadoop 开发环境搭建
一.前置条件 Hadoop 的运行依赖 JDK,需要预先安装,安装步骤见: Linux 下 JDK 的安装 二.配置免密登录 Hadoop 组件之间需要基于 SSH 进行通讯. 2.1 配置映射 配置 ...
随机推荐
- Android中集成支付宝
手机的在线支付,被认为是2012年最看好的功能,我个人认为这也是移动互联网较传统互联网将会大放光彩的一个功能. 人人有手机,人人携带手机,花钱买东西,不再需要取钱付现,不再需要回家上网银,想买什么,扫 ...
- 【转】mybatis 一对一与一对多collection和association的使用
转自:https://www.cnblogs.com/yansum/p/5819973.html (有修改和补充,红色字体部分) 在mybatis如何进行一对一.一对多的多表查询呢?这里用一个简单 ...
- [WebGL入门]十一,着色器编译器和连接器
注意:文章翻译http://wgld.org/,原作者杉本雅広(doxas).文章中假设有我的额外说明.我会加上[lufy:].另外.鄙人webgl研究还不够深入.一些专业词语,假设翻译有误.欢迎大家 ...
- 开源库(要不要重新制造轮子)—— C/C++、Java、Python
谷歌近期开源的SLAM方案:Cartographer Boost:准标准的C++库. Eigen3: 准标准的线性代数库. Lua:非常轻量的脚本语言,主要用来做Configuration Ceres ...
- Matlab随笔之指派问题的整数规划
原文:Matlab随笔之指派问题的整数规划 注:除了指派问题外,一般的整数规划问题无法直接利用Matlab函数,必须Matlab编程实现分支定界法和割平面解法. 常用Lingo等专用软件求解整数规划问 ...
- asp .net core 使用spa
要求 .net core 2.1 引用包 Microsoft.AspNetCore.SpaServices 先在angular目录下执行 npm i npm run build 关键代码 servic ...
- 2018年Unity结合Android SDK下载安装及配置教程
原文:2018年Unity结合Android SDK下载安装及配置教程 首先声明: Unity版本2017.1f3 最近试着在Unity中利用网易做AR开发时,发布项目文件需要发布到An ...
- teamcity build web project arguments
/p:Configuration=%system.Configuration% => Release /p:DeployOnBuild=%system.DeployOnBuild% => ...
- CSS visibility 属性 使元素占位,但不可见
CSS visibility 属性 使元素占位,但不可见 h2 { visibility:hidden; } 浏览器支持 所有主流浏览器都支持 visibility 属性. 注释:任何的版本的 Int ...
- SQLServer2005数据库快照的简单使用
原文:SQLServer2005数据库快照的简单使用 SQLServer2005数据库快照的简单使用 ...