Node.js 爬虫初探
前言
在学习慕课网视频和Cnode新手入门接触到爬虫,说是爬虫初探,其实并没有用到爬虫相关第三方类库,主要用了node.js基础模块http、网页分析工具cherrio。 使用http直接获取url路径对应网页资源,然后使用cherrio分析。 这里我主要是把慕课网教学视频提供的案例自己敲了一边,加深理解。在coding的过程中,我第一次把jq获取后的对象直接用forEach遍历,直接报错,是因为jq没有对应的这个方法,只有js数组可以调用。
知识点
①:superagent抓去网页工具。我暂时未用到。
②:cherrio 网页分析工具,你可以理解其为服务端的jQuery,因为语法都一样。
效果图
1、抓取整个网页
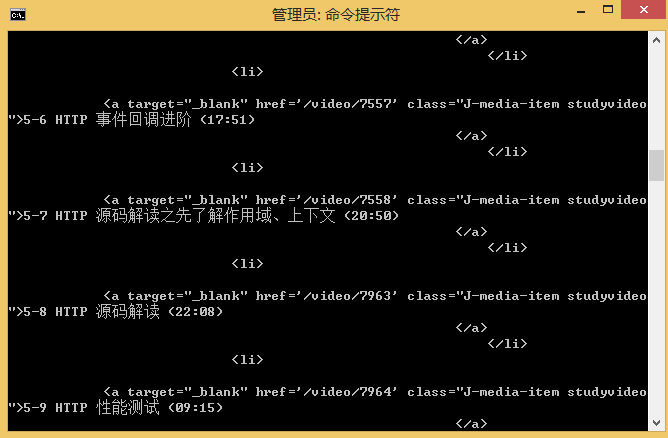
2、分析后的数据, 我这里是以慕课网提供的示例为案例实现的例子。
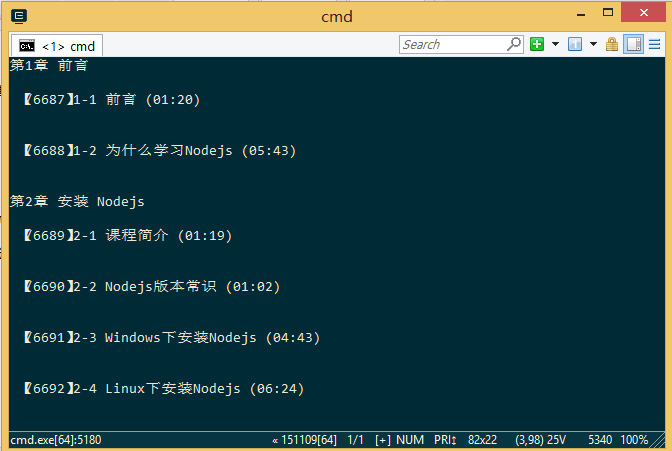
爬虫初探源码分析
var http=require('http');
var cheerio=require('cheerio');
var url='http://www.imooc.com/learn/348';
/****************************
打印得到的数据结构
[{
chapterTitle:'',
videos:[{
title:'',
id:''
}]
}]
********************************/
function printCourseInfo(courseData){
courseData.forEach(function(item){
var chapterTitle=item.chapterTitle;
console.log(chapterTitle+'\n');
item.videos.forEach(function(video){
console.log(' 【'+video.id+'】'+video.title+'\n');
})
});
}
/*************
分析从网页里抓取到的数据
**************/
function filterChapter(html){
var courseData=[];
var $=cheerio.load(html);
var chapters=$('.chapter');
chapters.each(function(item){
var chapter=$(this);
var chapterTitle=chapter.find('strong').text(); //找到章节标题
var videos=chapter.find('.video').children('li');
var chapterData={
chapterTitle:chapterTitle,
videos:[]
};
videos.each(function(item){
var video=$(this).find('.studyvideo');
var title=video.text();
var id=video.attr('href').split('/video')[1];
chapterData.videos.push({
title:title,
id:id
})
})
courseData.push(chapterData);
});
return courseData;
}
http.get(url,function(res){
var html='';
res.on('data',function(data){
html+=data;
})
res.on('end',function(){
var courseData=filterChapter(html);
printCourseInfo(courseData);
})
}).on('error',function(){
console.log('获取课程数据出错');
})
参考资料
https://github.com/alsotang/node-lessons/tree/master/lesson3
http://www.imooc.com/video/7965
Node.js 爬虫初探的更多相关文章
- Node.js爬虫-爬取慕课网课程信息
第一次学习Node.js爬虫,所以这时一个简单的爬虫,Node.js的好处就是可以并发的执行 这个爬虫主要就是获取慕课网的课程信息,并把获得的信息存储到一个文件中,其中要用到cheerio库,它可以让 ...
- node.js爬虫
这是一个简单的node.js爬虫项目,麻雀虽小五脏俱全. 本项目主要包含一下技术: 发送http抓取页面(http).分析页面(cheerio).中文乱码处理(bufferhelper).异步并发流程 ...
- Node.js aitaotu图片批量下载Node.js爬虫1.00版
即使是https网页,解析的方式也不是一致的,需要多试试. 代码: //====================================================== // aitaot ...
- Node.js umei图片批量下载Node.js爬虫1.00
这个爬虫在abaike爬虫的基础上改改图片路径和下一页路径就出来了,代码如下: //====================================================== // ...
- Node.js abaike图片批量下载Node.js爬虫1.01版
//====================================================== // abaike图片批量下载Node.js爬虫1.01 // 1.01 修正了输出目 ...
- Node.js abaike图片批量下载Node.js爬虫1.00版
这个与前作的差别在于地址的不规律性,需要找到下一页的地址再爬过去找. //====================================================== // abaik ...
- Node JS爬虫:爬取瀑布流网页高清图
原文链接:Node JS爬虫:爬取瀑布流网页高清图 静态为主的网页往往用get方法就能获取页面所有内容.动态网页即异步请求数据的网页则需要用浏览器加载完成后再进行抓取.本文介绍了如何连续爬取瀑布流网页 ...
- Node.js 爬虫爬取电影信息
Node.js 爬虫爬取电影信息 我的CSDN地址:https://blog.csdn.net/weixin_45580251/article/details/107669713 爬取的是1905电影 ...
- Node.js 爬虫,自动化抓取文章标题和正文
持续进行中... 目标: 动态User-Agent模拟浏览器 √ 支持Proxy设置,避免被服务器端拒绝 √ 支持多核模式,发挥多核CPU性能 √ 支持核内并发模式 √ 自动解码非英文站点,避免乱码出 ...
随机推荐
- 使用html5 地理位置技术 和 百度地图api查询当前位置
使用了 zepto 和 requirejs define(['zepto'],function($){ var geolocation = { init:function(config,onSuc ...
- 初识Python
Python 简介 Python 是一个高层次的结合了解释性.编译性.互动性和面向对象的脚本语言. Python 的设计具有很强的可读性,相比其他语言经常使用英文关键字,其他语言的一些标点符号,它具有 ...
- First Day:Starting My Coding Road
今天是2015年7月28日,星期二,晴,下午坐在科创园2楼的办公室里,窗明几净,继续我全新的Android之旅! 在调试和比较了N多IDE集成开发环境之后,最终决定在IDEA SDK环境下试试手,在已 ...
- TCP/IP, WebSocket 和 MQTT
按照OSI网络分层模型,IP是网络层协议,TCP是传输层协议,而HTTP和MQTT是应用层的协议.在这三者之间, TCP是HTTP和MQTT底层的协议.大家对HTTP很熟悉,这里简要介绍下MQTT.M ...
- IIS 8:IIS 入门
深埋在您的 Microsoft 服务器 (2008年. 2008 R2 和 2012年的版本) 的范围内是最强大的 Web 服务器可用. 它只等待你来发挥其全部潜力. 您的目标是要从家里运行一个 Wo ...
- 日志系统实战(一)—AOP静态注入
背景 近期在写日志系统,需要在运行时在函数内注入日志记录,并附带函数信息,这时就想到用Aop注入的方式. AOP分动态注入和静态注入两种注入的方式. 动态注入方式 利用Remoting的Context ...
- C#设计模式之工厂
IronMan之工厂 前言 实用为主,学一些用得到的技术更能在如今的社会里保命. 虽然在日常的工作中设计模式不是经常的用到,但是呢,学习它只有好处没有坏处. 设计模式像是一种“标签”,它是代码编写者思 ...
- linux下使用adb连接android手机
一.新建文件 cat /etc/udev/rules.d/51-android.rules SUBSYSTEM==" 二.重启 udev sudo /etc/init.d/udev rest ...
- Ubuntu 16 安装JDK1.8
检查是否JDK已被安装: 上图表示没有安装,创建文件夹: 下载JDK: http://www.oracle.com/technetwork/java/javase/downloads/jdk8-dow ...
- iOS-SDWebimage底层实现原理
其实有些框架的实现原理,并没有想象中那么难,思想也很简单,主要是更新第三方框架的作者对自己写的代码,进行了多层封装,使代码的可读性降低,也就使得框架看起来比较难.我来实现以下SDWebimage的的曾 ...